Содержание статьи
- А быстро ли все работает?
- Python vs C или С vs Assembler
- С чего все началось
- Современные профилировщики
- Статистические профайлеры (statistical profilers)
- Профайлеры, основанные на событиях (событийные, event-based profilers, deterministic)
- Instrumentation-профайлеры
- Ручное профилирование
- Измеряем скорость каждой строки
- Установка и использование line_profiler
- Perf — профилируем на уровне ядра
- Вместо заключения
В прошлой статье («Python на стероидах», 198-й номер) мы поговорили о профилировании Python-приложений. Судя по полученному фидбэку, тема оказалась интересной, и, выходит, теперь, когда мы уже попробовали все на практике, настало время познакомиться с теорией :). В этой статье я постараюсь рассказать о том, что вообще такое производительность ПО, как и зачем ее измерять, и закончу тему с профилированием. В следующий раз мы углубимся в тему тестирования производительности ПО в теории и на практике.
WARNING
Никогда не забывай, что преждевременная оптимизация — это еще хуже, чем ее отсутствие. Используй профайлеры только тогда, когда это действительно необходимо.
А быстро ли все работает?
Итак, зачем нам вообще измерять скорость работы нашего софта? Чаще всего скорость работы ПО измеряют в двух случаях: когда пользователи начинают жаловаться на то, что все тормозит, и когда в техническом задании написано что, например, страница разрабатываемого сайта должна открываться не медленнее, чем N секунд. Скорость работы — это вообще, на мой взгляд, мифическое понятие в вакууме.
INFO
Из Википедии: производительность софта — это количественная характеристика скорости выполнения определенных операций
Поэтому я предпочитаю использовать более конкретные определения: «скорость работы функции А низкая» или «при тысяче пользователей онлайн наш сайт отвечает на запросы более трех секунд». При таком подходе становится ясно не только что нужно измерять, но и что именно мы подразумеваем под скоростью работы софта. Ведь в зависимости от того, что ты разрабатываешь, измерять необходимо совершенно разные вещи. Например, при разработке веб-сайта главное, чтобы пользовательский интерфейс быстро реагировал на действия пользователя, и нам может быть абсолютно безразлично, сколько времени занимает запрос к базе данных, когда это работает асинхронно, а если мы пишем ORM, то важнейшим показателем скорости работы для нас будет скорость выполнения генерируемых запросов.
Python vs C или С vs Assembler
По этой же причине сложно сравнивать скорость работы языков программирования, ведь в конечном итоге нам неважно, сколько выполняется операция возведения в степень, нам нужно, чтобы скорость работы конкретной фичи в конкретном приложении была не ниже заданного значения. Поэтому различные холивары на тему «что быстрее — Python или Ruby» не имеют никакого смысла. Можно измерить скорость работы «Hello, world», но практической пользы в этом нет никакой.
То же самое касается и сравнения скорости работы разных фреймворков. Пользы от такого сравнения гораздо больше, чем от сравнения языков программирования, но все-таки не стоит воспринимать эти данные как истину в последней инстанции. На мой взгляд, такие сравнения годятся только для того, чтобы понять, как фреймворки ведут себя со стандартными настройками. Они показывают общие тенденции, но не могут дать точного ответа на вопрос, что подойдет именно тебе для использования в новом мегапроекте. Например, совершенно бесполезно вычислять скорость работы веб-фреймворка при чтении из базы данных. Ведь самое простое кеширование позволит практически уравнять их все по скорости чтения из БД. При этом в твоем проекте базы данных может вообще не быть, а все данные будут приходить из других источников (файлы, различные API и так далее). Поэтому еще раз повторю: определяй скорость только тех операций, которые нужны именно тебе, а не автору теста.

Хакер #199. Как взломали SecuROM
С чего все началось
Первые профайлеры появились еще в начале семидесятых для IBM/360 и IBM/370. Утилита для анализа производительности performance-analysis tool работала на основе прерываний и, по сути, была, наверное, первым статистическим профилировщиком. Позже, в 1979-м, в составе UNIX появился профайлер prof, что стало началом разработки ПО с использованием профилировщиков. После запуска prof выводил время, которое потребовалось для выполнения каждой функции программы.
Позже, в 1982 году, появился на свет gprof, который в 1983-м вошел в состав известного 4.2BSD. Тогда же была опубликована статья под названием «Gprof: a Call Graph Execution Profiler». В 1988-м gprof был переписан и включен в состав GNU Binutils, который входит в любой современный *nix-дистрибутив. Gprof расширил функциональность своего родителя и имел возможность строить граф вызовов функций.
Спустя шесть лет компания DEC опубликовала документ, описывающий фреймворк Analysis Tools with OM, — «ATOM: A system for building customized program analysis tools». ATOM позволял инструментировать софт (проще говоря — встроить свой код) для последующего анализа скорости выполнения кода.
Современные профилировщики
Сейчас существует огромное количество всевозможных профайлеров для разных языков программирования. Есть и универсальные профилировщики, которым не требуется исходный код программы, но желательно, чтобы программа была скомпилирована с нужными флагами. При профилировании рекомендуется использовать профайлер, созданный для языка программирования, с которым ты работаешь. Это удобно тем, что если инструмент заточен под конкретный язык программирования, то, например, в случае с Python в результате профайлинга мы будем видеть привычные названия функции вместо системных вызовов. Тут подход совершенно такой же, как и при выборе дебаггера: есть универсальные, которые работают с любым кодом и часто доступны на большинстве Linux-хостов, а есть те, которые разрабатывались для специальных нужд и, например, подходят только для разработки.
Давай разберем подробнее, какие профилировщики бывают и каковы их особенности.
Статистические профайлеры (statistical profilers)
Мы уже сталкивались с представителем данного типа профилировщика в предыдущей статье. Такие профайлеры меньше всего влияют на производительность профилируемого приложения, что, с одной стороны, хорошо, а с другой — для достаточно точных результатов может потребоваться много времени.
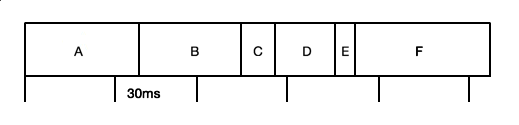
Как видно на рис. 2, если профайлер будет собирать данные каждые 60 мс, то некоторые функции в отчет не попадут. При запуске каждые 30 мс данных предсказуемо будет больше, но все равно не все. Чем больше наша программа будет работать с профилировщиком, тем больше данных соберется, соответственно, тем точнее будут результаты. С точки зрения математики это называется статистическим приближением или аппроксимацией.
Для Python самый актуальный статистический профайлер — plop. Остальные уже несколько лет не развиваются. Если говорить не о Python-приложениях, то в кругах линуксоидов известен OProfile.
Профайлеры, основанные на событиях (событийные, event-based profilers, deterministic)
Как несложно догадаться из названия, данные типы профилировщиков привязаны к событиям. Если статистические профайлеры срабатывают каждые N раз, то событийные профайлеры — в определенных случаях, например после вызова функции или завершения работы функции.
Такие профилировщики заметно точнее статистических, но точность здесь достигается в ущерб скорости работы. Из-за этого ты вряд ли захочешь использовать их в продакшене. В Python мы можем написать и свой профайлер с блек-джеком и фичами:
import sys
def profiler(frame, event, args):
print(frame.f_lineno, event, args)
sys.setprofile(profiler)
def main(name):
print('Hello, %s!' % name)
if __name__ == '__main__':
main('world')Вся магия здесь происходит после вызова функции sys.setprofile, которая говорит интерпретатору, что теперь у нас есть профайлер. После этого интерпретатор на каждое событие будет вызывать функцию profiler. К счастью или, наоборот, к сожалению, у Python таких событий не так уж и много: вызов функции (call), возврат из функции (return) и обработка исключения (exception).
INFO
Кроме sys.setprofile, существует также функция sys.settrace. Она имеет аналогичные параметры и вызывается перед выполнением новой локальной области (local scope). Обе функции рекомендуется использовать только для разработки профайлеров, дебаггеров, написания утилит проверки покрытия кода (code coverage) и тому подобного.
Функция-профайлер должна принимать себе три параметра:
- frame — представляет собой текущий стековый фрейм выполнения нашей программы (
sys._current_frames); - event — строка, имя события;
- args — специальные аргументы, которые отличаются в зависимости от типа события.
Классическим примером такого профайлера в Python служит cProfile, который является частью стандартной библиотеки Python и написан в виде С-расширения. В документации достаточно подробно написано о cProfile, поэтому повторяться здесь смысла нет.
Instrumentation-профайлеры
Instrumentation-профайлеры — это профайлеры, которые используют специальный измерительный код, встраиваемый компилятором или интерпретатором при компиляции программы. В качестве примера такого профайлера можно привести grof, который для своей работы требует бинарник, скомпилированный GCC с помощью ключа -pg.
Ручное профилирование
Не стоит забывать также и о возможности ручного профилирования кода. Если мы уже нашли узкое место в коде, можно использовать так называемое ручное профилирование — способ профилирования, при котором мы руками вставляем код, измеряющий скорость работы. Самым простым примером такого кода может быть
import time
t1 = time.time()
save_to_db(model)
t2 = time.time
print(t2-t1)Одной из часто встречающихся реализаций такого профилировщика можно считать такой декоратор:
def profiler(func):
def wrapper(*args, **kwargs):
before = time.time()
retval = func(*args, **kwargs)
after = time.time()
LOG.debug("Function '%s': %s", func.__name__, after-before)
return wrapper
@profiler
def hello(name):
print('Hello, %s' % name)Решение настолько простое и эффективное, что мне даже нечего добавить. Тем не менее следует помнить, что такой «профайлер» будет снижать скорость работы программы, и использовать его в продакшене я бы не стал без крайней необходимости.
Это, наверное, самый простой способ измерить скорость выполнения какого-то участка кода, однако тут есть один, но достаточно большой недостаток: необходимо не просто модифицировать код — нужно писать его. А это означает, что с большой долей вероятности этот код будет нельзя переносить между проектами. Ведь такой код пишется не просто под нужды определенного проекта, а под нужды определенной функции или нескольких функций. В этом же и плюс: можно измерять только то, что нам надо, и тогда, когда это необходимо. Например, включать профилирование только с двух до пяти утра, когда посетителей сайта мало и производительностью можно немного пожертвовать. Или мы можем включать такой «профайлер», когда сработает какое-то условие («пользователь нажал кнопку А и Б одновременно»), и проверить скорость работы нужной функции.
Конечно, ты можешь сказать, что это можно делать и с помощью все того же plop или cProfile, и будешь прав. Но в этом случае ты никогда не добьешься той гибкости, которую могут дать стандартные способы.
WWW
Когда производительность profile слишком мешает, можно попробовать hotspot — это аналог модуля profile, но написан он практически полностью на C.
Измеряем скорость каждой строки
Когда мы уже нашли, какая функция выполняется дольше всего, мы хотим понять, что именно тормозит. Иногда вся проблема кроется всего в одной строке, и угадать ее бывает непросто. И тогда стандартного cProfile нам не хватит — он не умеет мерять скорость работы каждой строки. Тут на помощь нам приходит line_profiler от Роберта Керна (Robert Kern).
line_profiler — это профайлер — обертка поверх cProfile, написанный также на C и Python, который позволяет определять скорость выполнения каждой строки кода. Но поскольку такое профилирование было бы очень медленным, то line_profiler может профилировать только отдельные функции.
Установка и использование line_profiler
Установить line_profiler так же просто, как и любой Python-пакет: pip install line_profiler. При установке из исходников также понадобится C-компилятор и Cython.
Использовать его можно двумя способами.
Так же, как и стандартный cProfile:
import line_profiler
profiler = line_profiler.LineProfiler()
profiler.run(‘your python code’)И как набор command line утилит.
Первый способ аналогичен работе с cProfile, поэтому описывать его я не буду, а остановлюсь на втором.
После установки line_profiler нам будет доступен CLI-скрипт под названием kernprof. Собственно, он и будет запускать профилировщик для сбора данных. По умолчанию он использует стандартный Profiler, а для того, чтобы использовать построчный режим, необходимо передать ключ -l. Например:
kernprof -l hello.pyЭтой строчкой мы запустим наш скрипт hello.py в режиме построчного профилирования. Но, поскольку это сильно увеличило бы время работы нашего скрипта, lineprofiler профилирует только ту функцию, которая обернута декоратором @profile. Декоратор @profile добавляется с помощью внесения в _builtins экземпляра класса LineProfiler с именем profiler. С одной стороны, это хорошо: для использования профайлера нужен минимум изменений в коде, а с другой — такая реализация грешит недостатками:
- нельзя измерять производительность всего скрипта — задача не частая, но иногда все-таки нужная; поэтому приходится оборачивать все в функцию main и вешать декоратор на нее;
- поскольку можно профилировать только одну функцию, профилировщик выберет только ту, на которой последний раз интерпретатор встретил наш декоратор, — это связано с тем, как работают декораторы в Python;
- так как декоратор @profile добавляется в builtins c помощью скрипта kernprof, то, если наш скрипт запустить стандартным способом, мы увидим исключение NameError; с одной стороны, это большой минус, а с другой — отладочный код точно уж не попадет в продакшен.
Kernprof только запускает профайлер и сохраняет результаты его работы. По умолчанию для lineprofiler это `имяскрипта.lprof`.
Затем эти данные нужно как-то посмотреть. Делается это очень легко с помощью всего одной команды:
python -m line_profiler hello.py.lprofкоторая покажет нам, насколько быстро или медленно работает наша функция.
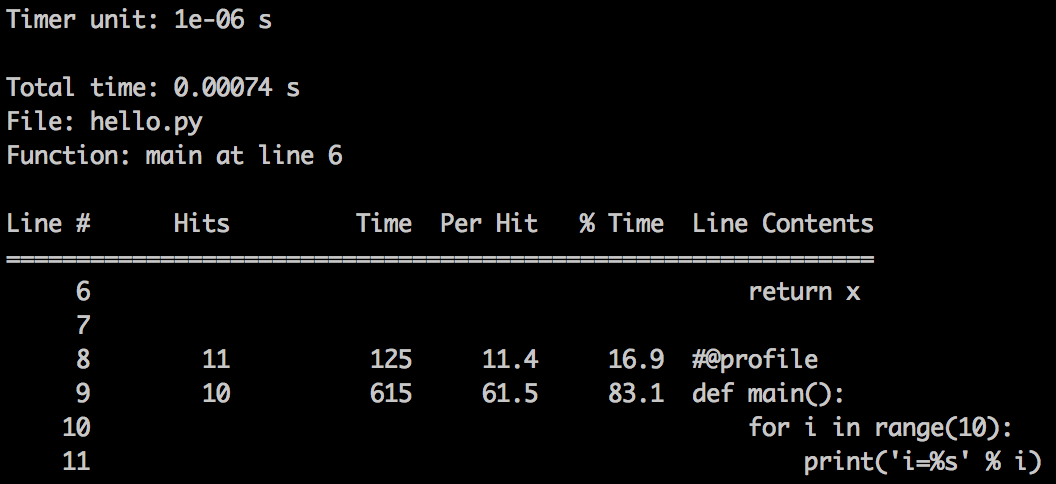
Тут мы видим не только какое время заняло выполнение каждой строки, но и сколько раз она выполнялась, что очень полезно для циклов. Также мы узнаем, сколько процентов времени от всего выполнения скрипта это заняло.
Perf — профилируем на уровне ядра
Говоря о профилировании в Linux, нельзя не сказать о perf. Perf — это профилировщик уровня ядра. Он доступен в любых дистрибутивах с ядром начиная с версии 2.6. В Ubuntu устанавливается не сложнее, чем любая другая программа:
sudo apt-get install linux-tools-commonДанный профайлер работает достаточно быстро и с минимумом накладных расходов. Для описания всех функций потребуется отдельная статья, поэтому здесь я остановлюсь только на двух самых простых.
Запустить профайлер и записать результаты их работы можно командой
perf record cmdПосле этого в текущей директории появится файл perf.dat, который можно просмотреть с помощью команды perf report, результат ее работы показан на рис. 4. Как видишь, perf ничего не знает про Python-код, поэтому результаты его работы нужно будет еще научиться правильно интерпретировать. Хотя если ты можешь на лету преобразовывать Python-код в соответствующий ему C-код, то это не понадобится :).
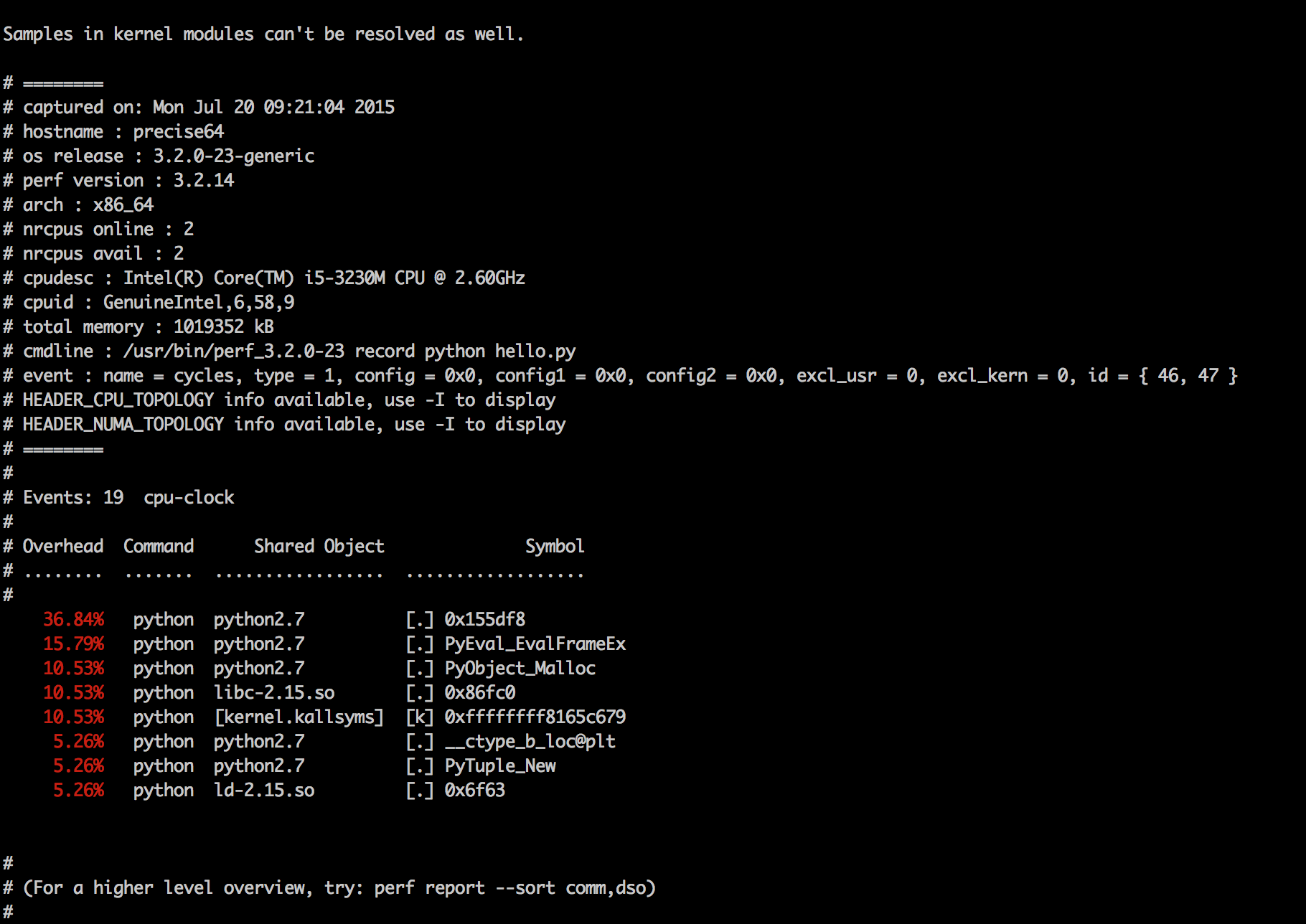
Но если такой вариант совсем не подходит, можно использовать perf-script-python. К сожалению, для этого нам понадобится собрать свой perf для того ядра, которое используется в конкретном дистрибутиве. Для этого предварительно нужно установить пакет python-dev (для Ubuntu).
Вместо заключения
В этой статье мы описали только самые распространенные способы профилирования Python-приложений. Имея в руках cPython и perf, можно измерять скорость практически чего угодно. Главное — использовать эти инструменты и знания только при необходимости и не ударяться при этом в крайности. Ведь в первую очередь софт пишется для пользователей, а уже потом идет все остальное. Хорошего тебе профайлинга, и до встречи в следующий раз.