

Содержание статьи
У семи нянек дитя без глаза
Когда компания начинает всерьез заниматься информационной безопасностью, ей приходится внедрять огромное количество разнородных систем. Антивирус, межсетевой экран, сетевая система обнаружения вторжений (NIDS), хостовая система обнаружения вторжений (HIDS), Web Application Firewall (WAF), сканер уязвимостей, система контроля целостности — и это далеко не самый полный список того, что может использоваться в организации. Поскольку безопасность — это не только состояние системы (в классическом определении), но и процессы, неотъемлемой частью которых является мониторинг событий ИБ, рано или поздно появится необходимость централизованного наблюдения и анализа логов, которые в огромном количестве могут генерироваться перечисленными системами.
И если ты захочешь проанализировать эти логи все вместе, то столкнешься с несколькими проблемами. Первая проблема заключается в том, что практически у всех источников логов свой собственный формат. При этом некоторые системы могут писать логи в нескольких разных форматах, отличающихся уровнем информативности.
Пожалуй, для меня примером наиболее продуманной подсистемы журналирования служит межсетевой экран Cisco ASA. С одной стороны, его логи — обычный текст, который легко может передаваться по протоколу syslog. C другой — каждая строка содержит уникальный идентификатор типа события. По этому идентификатору легко можно найти подробное описание события в документации, включая то, какие элементы в сообщении могут меняться и какие значения они могут принимать. В данном примере представлены события с идентификаторами 302016 (Teardown UDP connection), 308001 (Console enable password incorrect), 111009 (User 'enable_15' executed cmd).
%ASA-6-302016: Teardown UDP connection 806353 for outside:172.18.123.243/24057 to identity:172.18.124.136/161 duration 0:02:01 bytes 313
%ASA-6-308001: console enable password incorrect for number tries (from 10.1.1.15)
%ASA-7-111009: User 'enable_15' executed cmd: show logging mess 106Системы обнаружения вторжений с открытым исходным кодом — практически полная противоположность. Snort NIDS имеет четыре различных формата логов. Один из них, unified2, — бинарный. Для его обработки требуется сторонняя утилита barnyard2. Зато этот формат, в отличие от остальных, может содержать расшифрованные заголовки протоколов прикладного уровня. Три других формата текстовые, два многострочные и один однострочный. Уровень информативности текстовых форматов по понятным причинам различается — от только описания сигнатуры и адресов сокетов до расшифровки заголовков протоколов транспортного уровня. Для примера — формат alert_full выглядит следующим образом:
[**] [129:15:1] Reset outside window [**]
[Classification: Potentially Bad Traffic] [Priority: 2]
03/11-13:34:05.716632 74.125.232.231:443 -> 98.14.15.16:2079
TCP TTL:60 TOS:0x0 ID:25102 IpLen:20 DgmLen:40
*****R** Seq: 0xFF405C9D Ack: 0x0 Win: 0x0 TcpLen: 20А формат alert_fast:
[119:31:1] (http_inspect) UNKNOWN METHOD [Classification: Unknown Traffic] [Priority: 3] {TCP} 79.164.145.163:57678 -> 52.73.58.27:80OSSEC HIDS имеет меньшее количество форматов логов, всего два — однострочный и многострочный. Зато несколько способов передачи: запись в файл, отправку по протоколу syslog, отправку на ZeroMQ-сервер. Сам формат и содержание лога в большой степени зависит от того, как настроен OSSEC и какие в нем модули. Заголовок у всех сообщений OSSEC одинаковый, но если используется модуль контроля целостности syscheck, то после заголовка, в зависимости от настроек модуля, будут присутствовать контрольные суммы измененного файла и diff его изменений. Но если этот же alert отправляется по протоколу syslog, то diff’а он содержать не будет. Если сообщение сформировано модулем анализа логов log analysis, то будет приведено оригинальное сообщение системного журнала, которое вызвало срабатывание. И таких вариаций довольно много.
** Alert 1490901103.1401: - pam,syslog,authentication_success,
2017 Mar 30 23:11:43 hw1->/var/log/secure
Rule: 5501 (level 3) -> 'Login session opened.'
Mar 30 23:11:42 hw1 sshd[1427]: pam_unix(sshd:session): session opened for user root by (uid=0)
** Alert 1490901561.1803: mail - ossec,syscheck,
2017 Mar 30 23:19:21 hw1->syscheck
Rule: 550 (level 7) -> 'Integrity checksum changed.'
Integrity checksum changed for: '/etc/resolv.conf'
Size changed from '87' to '97'
Old md5sum was: 'd3465a94521bbadf60e36cdf04f04bea'
New md5sum is : '524d80c6cc4c76bd74a173ef4f40096a'
Old sha1sum was: 'b6e622f922f75200a32c3426f09ab92b8ab82b12'
New sha1sum is : '6a3e34e2f77af6687dc1583bee9118b620aa7af8'При таком разнообразии форматов и способов хранения анализ логов всех этих систем может стать довольно трудоемким процессом. Конечно же, для упрощения подобных задач уже существует специальный класс ПО — SIEM. И если хороших систем обнаружения вторжений с открытым исходным кодом хватает, то вот SIEM с открытым исходным кодом практически нет. Существует довольно много решений для конкретной IDS. Например, Snorby для Snort или Analogi для OSSEC. Но возможности добавить в эти системы какие-то дополнительные источники событий не предусмотрено. Есть системы, которые обладают и более широкими возможностями, но, скорее, представляют собой бесплатные версии коммерческих решений с целым набором искусственных ограничений. Я встречал даже такую систему, в которой разработчики намеренно переписали запросы к БД, чтобы сделать их более медленными. Но даже эти системы имели не самый дружественный пользователю интерфейс. Вот и получается, что у семи нянек дитя без глаза.
Команда героев, которую ждали
Таким образом, у сообщества есть потребность в SIEM из компонентов с открытым исходным кодом, чтобы в ней не было искусственных ограничений и чтобы она обладала такими качествами, как высокая скорость, безопасность и дружественность по отношению к пользователю. Ведь количество угроз информационной безопасности растет с каждым днем. И если ты работаешь в компании из 50 человек, все эти угрозы ее также затрагивают, а бюджет на ИБ, скорее всего, чуть меньше нуля. Ты вполне можешь бесплатно развернуть свободные IDS, а нормальной возможности анализировать их журналы у тебя не будет. После долгих поисков и даже попыток написать SIEM на PHP я нашел решение, которое позволяет вообще не писать программный код и при этом получать неплохие результаты при поиске в логах и сигналах тревоги. Решение состоит в использовании высокоинтегрированного стека приложений ELK — Elasticsearch, Logstash и Kibana. Неплохим дополнением ко всему этому станут плагины Search Guard или Shield. Для объединения всех составных частей: пакетов, конфигов, плагинов и дополнительных скриптов — я написал Ansible playbook и выложил на GitHub под названием LightSIEM.
Резиновый поиск
Центром этого набора является Elasticsearch. Это движок для индексации и поиска по документам, построенный на основе библиотеки Apache Lucene. Разработчиками он позиционируется как возможность создать свой корпоративный Google. Он часто используется как БД для хранения разнородной информации и последующего поиска по ней. Elasticsearch позволяет в режиме реального времени индексировать поток входящих сообщений и вести по ним поиск. Еще одна примечательная особенность Elasticsearch — масштабируемость out of the box. Достаточно просто установить несколько серверов в одной сети, и они найдут друг друга и автоматически распределят между собой хранение индексов. Разумеется, в обработке поискового запроса участвуют все серверы. Все манипуляции, в том числе CRUD, в Elasticsearch выполняются с помощью REST API.
Универсальный конвертер
Все запросы и ответы — в формате JSON, поэтому, чтобы передавать логи в Elasticsearch, нам понадобится Logstash. Его основная функция — конвертация логов из одного формата в другой. В нашем случае из обычного файла или syslog-сообщения мы будем получать JSON-документ, который будет отправляться прямиком на индексацию в Elasticsearch. Logstash очень гибок в настройках благодаря огромному количеству плагинов. Один из самых полезных — это grok. Его основная задача состоит в том, чтобы проверить, соответствует ли полученная на вход строка или строки одному из заданных паттернов. Паттерны grok — это регулярные выражения на стероидах. Во-первых, они позволяют собрать довольно сложные выражения из элементарных блоков. Во-вторых, они позволяют разбить все входящие сообщения на множество полей, каждое из которых будет иметь свое название и смысл. Примерно такой JSON-документ получается на выходе:
{
"@timestamp" => 2017-03-30T19:25:54.264Z,
"@version" => "1",
"Classification" => {
"Ident" => "106023",
"Text" => "%ASA-4-106023"
},
"CreateTime" => 2017-03-30T20:37:22.000Z,
"Level" => {
"Origin" => "4",
"Normalized" => 5
},
"Protocol" => "udp",
"Name" => "cisco"
"Source" => {
"Node" => {
"Geoip" => {
"ip" => "188.123.231.104",
"city_name" => "Moscow",
"country_code2" => "RU",
"location" => [
[0] 37.615,
[1] 55.752
],
},
"Address" => "188.123.231.104",
"Port" => "23256",
"Name" => "188.123.231.104"
},
},
}Как я уже упоминал, некоторые IDS пишут в свои логи намного больше информации, чем могут отправить по протоколу syslog. То есть события от таких систем оптимально читать непосредственно из многострочного лог-файла, куда они пишут свои сообщения. Долгое время единственным вариантом обработки таких файлов была непосредственная установка Logstash на тот же сервер, где стоит IDS. Не всех устраивал такой вариант, поскольку Logstash при обработке больших объемов логов может давать ощутимую нагрузку на CPU и потреблять довольно много памяти. Кроме того, Logstash написан на JRuby и, соответственно, требует установки на сервер Java, что также не для всех желательно. Специально для таких случаев была разработана отдельная утилита Lumberjack. Позднее ее переименовали в Logstash forwarder, а после этого проект был полностью переписан и получил название Filebeats. Кроме того, в семействе Beats появилось еще несколько утилит: Packet для обработки сетевого трафика, Winlog для отправки в Logstash нативных логов Windows EventLog и другие. Я уже писал, что проекты, связанные с ELK, развиваются очень стремительно, и путь от Lumberjack к Beats — тому отличный пример. Единственная задача Beats — прочитать данные из источника, например файла с логом, и отправить их на сервер Logstash. Эта утилита потребляет очень мало ресурсов, проста в конфигурировании, написана на Go и, следовательно, не требует установки Java. Кроме того, авторы Beats входят в команду разработчиков ELK, а значит, проблемы совместимости протоколов, их реализаций и возможность потерять данные тут минимальны.
Прекрасный цветок «Кибаны»
Из компонентов приятнее всех для пользователя Kibana. Это веб-интерфейс, позволяющий составлять запросы к Elasticsearch, строить различные графики, гистограммы и всячески визуализировать полученные поисковые результаты. Разумеется, просмотреть найденные документы с учетом всех извлеченных в Logstash полей тоже можно. Все диаграммы и визуализации в Kibana полностью интерактивны. То есть, как только на гистограмме будет выделен временной промежуток, он автоматически добавится в фильтры, и вся панель перестроится с учетом нового условия. Если же, например, щелкнуть по столбику, который показывает уровень сигнала тревоги, то он также добавится в фильтр запроса, и на всех визуализациях и поисковой выдаче мы будем уже наблюдать только события с этим уровнем важности.
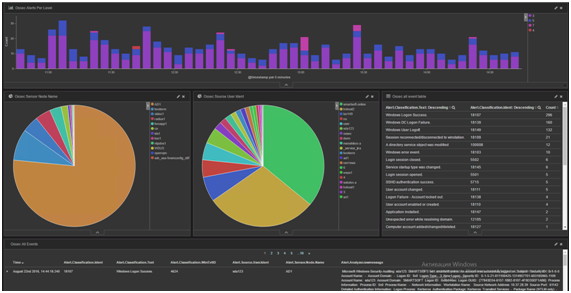
Лига безопасного интернета поиска
На самом деле если у тебя есть проблема и ты начинаешь использовать для ее решения Elasticsearch, то у тебя появляется сразу две новые проблемы. Первая — это шифрование трафика. Да, Elasticsearch не предоставляет никакого шифрования ни при осуществлении запросов к его серверам, ни при коммуникации серверов между собой. Вторая проблема заключается в отсутствии привычной для баз данных системы ограничения доступа. Все эти GRANT SELECT ON db2.alerts тут по дефолту отсутствуют. В Elasticsearch любой, кто смог подключиться к порту, может выполнять любые запросы — читать, изменять, удалять данные. Большинство настроек в Elasticsearch хранятся в служебных индексах, и их можно менять на лету с помощью точно таких же REST-запросов. В общем, любой злоумышленник, вооруженный Telnet-клиентом, может по полной нарушать конфиденциальность, целостность и доступность твоего кластера Elasticsearch. А ты в нем хранишь данные о действиях как раз этого самого злоумышленника. Непорядок.
Решать эти задачи предполагалось с помощью плагинов для Elasticsearch. Они появились далеко не сразу, и не все дожили до настоящего времени. Разработка многих была остановлена, так как появился плагин непосредственно от разработчиков Elasticsearch — Shield. Хоть он и требовал покупки лицензии, видимо, многие сочли это более простым решением, чем разработка своего плагина безопасности. Другие плагины попросту не успевали за стремительным развитием Elasticsearch. Ведь каждая новая версия привносила изменения в API. На текущий момент есть два основных плагина, которые обеспечивают шифрование и разделение прав. Shield, как я писал выше, — это коммерческая разработка команды Elasticsearch. Другой — Search Guard — является сторонней разработкой германской компании floragunn. Его исходный код опубликован на GitHub.com. Разработчики оказывают коммерческую техническую поддержку. Search Guard представляет собой набор из двух плагинов — Search Guard SSL и Search Guard. Search Guard SSL обеспечивает шифрование данных между серверами и клиентами. Search Guard служит опциональным дополнением к Search Guard SSL, которое обеспечивает аутентификацию и разграничение прав доступа. Права можно ограничивать как к индексам, так и к типам данных (обязательное для каждого документа Elasticsearch поле _type). Например, можно дать доступ к логам систем обнаружения вторжений только офицерам безопасности. А право просмотра логов сетевого оборудования выдать еще и сетевым администраторам.
Rule them all
Сразу после того, как я в первый раз попробовал связать все компоненты воедино, стало понятно, что повторить этот подвиг с нуля через пару месяцев, скорее всего, будет очень тяжело. Причина тому, как всегда, информационная перегрузка и плохая память. На поиски некоторых настроек уходило ощутимое количество времени, и тратить его снова для устранения той же проблемы не хотелось. Но это еще полбеды. Если хочешь, чтобы твоим решением пользовались, оно должно быть доступным. Для бесплатного ПО главный критерий доступности — простота установки. В моем случае она сильно страдала. Самым очевидным вариантом было написать огромную статью, которая бы показывала, как все устанавливать и настраивать. Отягчало проблему то, что стек ELK довольно новый и мало кто разбирался в нем хорошо. Кроме того, какие-то изменения я вносил почти каждый день. Статья рисковала либо оказаться неактуальной к моменту окончания, либо никогда не быть завершенной. Я подумал, что было бы здорово вместо документации написать скрипт, который был бы понятен любому человеку и при этом еще устанавливал и интегрировал все компоненты вместе. Таким скриптом стала утилита автоматизации Ansible. Она позволила писать так называемые playbook’и, которые с виду выглядят достаточно «человекопонятно», а при запуске программой выполняют сложную и скучную последовательность действий для установки и настройки всех компонентов. Помимо этого, Ansible не требует установки на конечные серверы какого-либо агентского ПО, ей достаточно только доступа по SSH.
- name: Check search-guard-5 is installed
command: /usr/share/elasticsearch/bin/elasticsearch-plugin list | grep search-guard-5
register: sg_installed
- name: Install search-guard-5
command: /usr/share/elasticsearch/bin/elasticsearch-plugin install -b com.floragunn:search-guard-5:5.1.1-9
tags: configuration security
when: sg_installed.stdout != "search-guard-5"Unify them all
Помимо проблемы автоматизации, пришлось решать проблемы сопоставления данных из различных источников информации. Во-первых, у каждого источника событий своя шкала уровней тревоги. В общем случае этот уровень должен показывать, насколько вероятно, что произошла или происходит попытка вторжения. В Snort самая высокая вероятность вторжения обозначается уровнем 1, а самая низкая — уровнем 4. А в OSSEC HIDS самая большая вероятность вторжения находится на 15-м уровне сигнала тревоги, а на уровне 0 — события, которые вообще не заслуживают никакого внимания. Во-вторых, разные системы выдают различные наборы данных. Например, в сигналах тревоги от Snort всегда присутствуют адрес источника и адрес цели потенциальной атаки. В сигналах тревоги от OSSEC, напротив, таких данных вообще может не быть или они могут присутствовать в них косвенно. Для того чтобы все эти разнородные данные можно было хоть как-то сопоставлять, пришлось разработать систему полей, на которые разбиваются все входящие сообщения. За основу я взял стандарт IDMEF — Intrusion Detection Message Exchange Format. В нем уже описана структура данных, которая покрыла 90% всех потребностей.
Поскольку формат даты и времени у всех также индивидуальный, эти данные тоже пришлось приводить к общему виду. На текущий момент все извлекаемые даты сохраняются в поле Alert.CreateTime. В дополнение к этому в служебное поле @timestamp сохраняется отметка времени того, когда событие было сохранено в Elasticsearch. Два этих поля необходимы, потому что при передаче событий в Logstash по протоколам с гарантированной доставкой, например Beats или TCP, при возникновении проблем с сетью события могут быть буферизированы на передающих устройствах и переданы позже. Соответственно, будет некорректно обрабатывать события на основе поля @timestamp.
Разворачиваем LightSIEM
На текущий момент в LightSIEM можно направлять практически любые логи по протоколам syslog или Beats. Но не для любого лога написаны паттерны в Logstash. Самая полная поддержка реализована для OSSEC и Snort. Их логи можно отправлять по протоколу syslog, можно писать их в стандартном многострочном формате в файл, а потом отправлять с помощью Filebeat. Первый вариант удобен тем, что достаточно просто настроить отправку логов по протоколу syslog на нужный сервер — сообщения сразу начнут появляться в SIEM. Как я уже писал в начале статьи, во втором варианте информативность будет выше, но и настройка займет чуть больше времени, так как необходимо поставить дополнительный пакет и настроить его. Поддерживаются также логи сетевого оборудования Cisco — роутеров и межсетевых экранов. Частично реализована поддержка логов Auditd.
Хоть я и постарался максимально упростить установку LightSIEM, давай все же разберем детально, как это сделать, что будет происходить во время запуска playbook’а и как будут обрабатываться поступающие логи. Еще до того, как ты начнешь инсталлировать LightSIEM, неплохо иметь источники данных, которые ты будешь анализировать. Как установить сервер OSSEC, ты можешь почитать в моей статье «За высоким забором OSSEC» в «Хакере» №184. Может тебе пригодиться и моя статья на Хабре. Для начала нам понадобится отдельный сервер под управлением Linux. Лучше всего подойдет CentOS/RHEL/Oracle версии 7.0 и выше. Playbook оптимизирован именно под эти дистрибутивы, но если ты предпочитаешь другие, то всегда можешь разобраться с тем, что делает playbook, и модифицировать его под свой любимый дистрибутив, попутно закоммитив результат работы к нам на GitHub ;). После того как ты подготовил сервер и настроил на нем сеть с выходом в интернет, необходимо установить на него сам Ansible и unzip. Установить Ansible проще всего из репозитория EPEL. Итого, для начала необходимо выполнить две команды:
yum install epel-release
yum install ansible unzipЗатем нужно скачать архив с кодом и распаковать его следующими командами:
wget https://github.com/dsvetlov/lightsiem/archive/v0.2.1.zip
unzip master.zipТеперь все готово к тому, чтобы запустить playbook и заинсталлить все необходимое для LightSIEM:
ansible-playbook lightsiem-master/lightsiem-install.ymlВкратце поясню, что делает скрипт. Прежде всего инсталлируются официальные репозитории Elasticsearch. Затем из них уже устанавливаются все основные компоненты — Logstash, Elasticsearch и Kibana. Далее выкладываются конфиги для Logstash. Они разделены на несколько отдельных файлов, чтобы было проще ориентироваться в них. Их назначение разберем чуть позже. Скрипт также устанавливает дополнительные паттерны для grok. Это отдельные файлы с описанием регулярных выражений, которыми потом парсятся входящие сообщения. Также скрипт открывает порты в firewalld. Если на своей системе ты его заменил на iptables — не беда. Скрипт проигнорирует эти ошибки, но порты тебе придется открыть самостоятельно. После этого всего скрипт устанавливает Search Guard и заливает несколько дашбордов для Kibana.
Итак, LightSIEM ты установил, порты открыл. Теперь необходимо направить в него алерты из OSSEC. Самый простой способ сделать это — вписать в главной секции конфига сервера следующие строки:
<syslog_output>
<server>address of LightSIEM server</server>
<port>9000</port>
<format>default</format>
</syslog_output>Естественно, в тегах <server>, нужно писать адрес сервера, куда ты установил LightSIEM. Способ чуть сложнее — установить на сервер c OSSEC Filebeat. Отдельно сделан конфиг для каждого источника логов, которые может обрабатывать LightSIEM. В таких файлах прежде всего описывается input. Это тот элемент конфигурации Logstash, который отвечает за прием логов по одному из протоколов. Соответственно, если подразумевается доставка логов не только простым syslog’ом, но и с помощью Beat, в файле описан отдельный input для каждого протокола. Далее в этом файле происходит парсинг с помощью фильтра grok и специфических для данного типа логов паттернов. После grok документы проходят обработку, также специфичную только для данного типа логов. Например, извлекаются метки времени, приводится к единому формату шкала уровня тревог.
После этого в игру вступает файл конфигурации, который называется common. Как и следует из его названия, он участвует в обработке абсолютно всех логов. Его основная задача — обогащение наших событий дополнительной информацией.
Получаем из логов события
Все входящие сообщения, независимо от источника и протокола, обрабатываются в Logstash. Настройка Logstash оказалась самой трудоемкой и тяжелой, но при этом самой полезной для анализа событий. Первое, что происходит с каждым входящим событием, — это парсинг с помощью фильтра grok. На этом этапе длинная строчка события превращается в набор более коротких полей. Все поля именуются в соответствии с общей схемой. Таким образом, семантически сходные данные попадают в одно и то же поле, даже если они пришли из разных источников. Например, Snort может зарегистрировать попытку сканирования портов с определенного IP-адреса. OSSEC может подать сигнал тревоги о том, что с конкретного адреса был осуществлен вход на сервер. А межсетевой экран вообще запишет все соединения, которые устанавливались через него, в том числе и их исходящие адреса. Во всех этих трех случаях исходящий адрес будет записан в поле Alert.Source.Node.Address. Соответственно, при обнаружении событий с высоким уровнем приоритета есть возможность парой кликов мыши поискать все события с этого IP-адреса. Уже после того, как входящие сообщения разбиваются на множество мелких, происходит еще несколько преобразований. Первое, что нужно сделать, — привести уровень сигнала тревоги к единой шкале. Я взял за основу шкалу, которая используется в OSSEC, так как она уже неплохо описана и у нее есть целых 16 уровней, в отличие от того же Snort, где всего четыре уровня.
if [type] in ["snort", "snort_full", "snort_barnyard"] {
if [Alert][Analyzer][Level][Origin] == "1" {
mutate { add_field => [ "[Alert][Analyzer][Level][Normalized]", "15" ] }
} else if "[Alert][Analyzer][Level][Origin]" == "2" {
mutate { add_field => [ "[Alert][Analyzer][Level][Normalized]", "11" ] }
} else if "[Alert][Analyzer][Level][Origin]" == "3" {
mutate { add_field => [ "[Alert][Analyzer][Level][Normalized]", "6" ] }
} else if "[Alert][Analyzer][Level][Origin]" == "4" {
mutate { add_field => [ "[Alert][Analyzer][Level][Normalized]", "4" ] }
}
}После этого необходимо из полей, куда попали временные отметки, извлечь и преобразовать время. Тут разнообразие вариантов того, как записываются временные отметки, тоже иногда удивляло.
Далее наступает черед обогащения события данными. Первое, что очень облегчает анализ событий, — обратные DNS-запросы. Ведь оперировать DNS-именами серверов удобнее, чем скупыми октетами IP-адресов. Так можно с первого взгляда понять, принадлежит ли тот или иной компьютер к dial-up-пулу провайдера из Твери или является сервером из фермы vk.com. Каждый IP-адрес источника и назначения, если он в событии присутствует, Logstash пытается разрешить в DNS-имя. Если это получается, то наряду с полями Alert.Source.Node.Address и Alert.Target.Node.Address в событии появляются поля Alert.Source.Node.Name и Alert.Target.Node.Name.
Разумеется, далеко не все адреса успешно разрешаются в имена, а искать хочется прежде всего по полю с именем. Чтобы не складывалась ситуация, в которой часть событий имеет поле с DNS-именем, а другая часть не имеет, Logstash в случае, если разрешить IP-адрес не удалось, записывает в поле c DNS-именем IP-адрес. Это позволяет работать с полями Alert.*.Node.Name как c универсальными — в которых в любом случае есть какой-то IP-адрес или DNS-имя.
Поскольку даже при большом объеме событий необходимо их быстро разрешать, в состав LightSIEM вошел DNS-сервер dnsmasq. Чтобы не увеличивать площадь поверхности атаки на сервер и не открывать вовне еще один порт, Ansible устанавливает и настраивает dnsmasq слушать только адрес loopback-интерфейса. Так как на каждом сервере свои собственные настройки DNS-серверов для пересылки запросов, в dnsmasq было решено использовать серверы из /etc/resolv.conf, как наиболее универсальный метод по умолчанию. Для уменьшения нагрузки на серверы пересылки запросов и ускорения ответов dnsmasq настроен кешировать ответы от серверов. Таким образом, если из Logstash придет несколько запросов для одного и того же адреса, он будет разрешен только в первый раз, а все последующие ответы уже будут даны из кеша.
if ![Alert][Source][Node][Name] and [Alert][Source][Node][Address]
{
mutate { add_field => [ "[Alert][Source][Node][Name]", "%{[Alert][Source][Node][Address]}" ] }
dns {
reverse => [ "[Alert][Source][Node][Name]"]
action => "replace"
nameserver => "127.0.0.1"
}
}В дополнение к обратным DNS-запросам осуществляются запросы в базу данных GeoIP. Это позволяет добавить в событие примерные координаты IP-адресов и впоследствии вывести их на карту в Kibana. Необходимо учитывать, что данные координаты примерные и чаще всего берутся по адресу компании, на которую зарегистрирован IP-адрес. Тем не менее это одна из самых эффектных визуализаций данных о вторжениях. Ни один голливудский боевик без такой карты не обходится.
geoip {
source => "[Alert][Source][Node][Address]"
target => "[Alert][Source][Node][Geoip]"
}
"Geoip" =>
{
"ip" => "188.123.231.104",
"city_name" => "Moscow",
"country_code2" => "RU",
"location" => [
[0] 37.615,
[1] 55.752
],
}Еще одна важная функция, которая лежит на Logstash, — интеграция с другими системами. Самый простой способ — отправка email. Например, по письму можно заводить инцидент в большинстве систем управления инцидентами. Уведомления по email еще и самый простой способ оперативного оповещения всех заинтересованных лиц об инциденте. Вообще, у Logstash тут довольно большая гибкость. Например, можно выполнять запросы к Elasticsearch и обрабатывать их результаты, чтобы решить, что делать с пришедшим событием. Это можно использовать в будущем для создания правил корреляции. Также есть возможность выполнить любую команду или скрипт. По сути, это универсальный способ, который позволяет интегрироваться с любыми системами. Необходимо отправить СМС — запуск скрипта. Нужно добавить запись в какую-то внешнюю базу данных — тоже запуск внешнего скрипта. Тут можно даже добавить небольшую функциональность IPS. Если Snort регистрирует попытки атаки с определенного адреса, то с помощью выполнения скрипта можно заблокировать этот адрес на межсетевом экране. При этом есть возможность задать очень сложные фильтры. Задавать можно любые условия относительно полей события. Например, можно указать, что у события должен быть определенный IP-адрес источника, определенный код и уровень важности не менее 15.
Из Logstash все события передаются для хранения и индексации в Elasticsearch. Основная функция Elasticsearch — хранение поступающих данных и их обработка для быстрого поиска. Все данные хранятся в структурах под названием индексы. Каждый индекс должен состоять как минимум из одного шарда. Шард — это сущность, которая содержит часть индекса. Также в состав индекса могут входить реплики. Реплика — это копия шарда, которая располагается на другом сервере и служит для повышения отказоустойчивости и обработки поисковых запросов. Если одного сервера с Elasticsearch не хватает для обработки всей поступающей информации или для последующего поиска по ней, можно очень легко установить дополнительные серверы. Одна из особенностей Elasticsearch заключается в том, что для настройки кластера из нескольких серверов и распределения между ними нагрузки не нужно тратить много времени. Когда серверы оказываются в одной подсети, они автоматически друг друга находят. После этого они автоматически распределяют между собой шарды и реплики. Такая особенность позволяет легко создавать большие кластеры, которые обеспечивают надежность благодаря тому, что реплики каждого шарда распределены между разными серверами, и масштабируемость производительности.
Типы полей в Elasticsearch могут определяться автоматически. Кроме того, сама схема полей может динамически расширяться по мере появления новых записей. Это означает, что если добавить новое поле на уровне Logstash, то изменять на стороне Elasticsearch ничего не придется. Все документы будут сохранены со всеми полями, которые в них есть, а если такие поля ранее никогда не встречались, то они будут созданы автоматически. Еще одна полезная в некоторых случаях функция Elasticsearch — анализаторы полей. По умолчанию все поля документов анализируются — примерно так же, как это делают поисковые системы. То есть предложения разбиваются на отдельные слова, слова приводятся к одному регистру и так далее. В случае SIEM-системы, где большинство полей представляет собой фиксированное описание событий, их цифровые коды и IP-адреса, это будет избыточным и только замедлит работу всей системы.
Несмотря на то что динамически создаваемые поля и автоматически определяемые типы данных — очень удобные функции, особенно на этапе разработки, они иногда создают проблемы. Например, если поле с уровнем сигнала тревоги, записанным в виде числа, случайно определится как текстовое, то многие функции, которые используются в Kibana для построения графиков, станут недоступны. Для настройки типа полей, их названия и еще многих параметров используются специальные шаблоны. В общем случае шаблон создается как документ в Elasticsearch и хранится в нем. При этом в свойствах шаблона указывается то, для каких индексов он применяется.
В LightSIEM Logstash создает новый индекс для данных каждый день. Это необходимо для того, чтобы индексы не разрастались и можно было легко удалить данные за определенный день. Упомянутый шаблон задается как опция для отправки данных в Elasticsearch. Таким образом Logstash проверяет, есть ли уже шаблон в Elasticsearch, и, если его еще нет, создает. В шаблоне, в свою очередь, задаются свойства каждого поля — его тип и необходимость в анализе.
Взаимодействие пользователя с SIEM происходит с помощью веб-интерфейса Kibana. Он был разработан специально для работы с Elasticsearch. Позволяет создавать интерактивные панели с графиками (dashboard). Каждый элемент такого графика кликабельный. При клике на него соответствующее значение добавляется в фильтр поискового запроса всей доски, и все графики на ней перестраиваются с учетом этого фильтра. Например, можно вывести на такую доску список из узлов, от которых зарегистрированы события, список узлов, на которые приходили события, и уровней сигналов тревоги. При клике на конкретный сервер в списке источников атак остальные графики перестроятся, и уже можно будет судить о том, с каких серверов на этот сервер приходили атаки и какой у них уровень сигнала. Если после этого кликнуть на какой-то конкретный уровень сигнала тревоги, он также добавится в фильтр, и мы уже сможем увидеть, с каких серверов шли атаки данного уровня опасности на наш сервер.
Kibana может использовать данные GeoIP, которые добавляет Logstash для отображения на карте источников или жертв атак. Очень полезны гистограммы распределения событий во времени. Они позволяют выделить мышкой нужный промежуток времени и также добавляют его в фильтр для всей панели. Таким образом можно быстро выбирать, события из какого временного промежутка необходимо показывать. Естественно, каждое событие можно смотреть и в краткой форме, и в подробной.
Вместо заключения
Итак. Ты сейчас установил себе LightSIEM (установил ведь?), а я, надеюсь, достаточно подробно рассказал, как он функционирует. Ты вполне можешь взять его за основу и допилить под себя. Можешь использовать как есть и только добавлять правила. Если же ты решишь закоммитить какие-то изменения в репозиторий, то помни, что ты этим сделал мир чуть безопаснее. Если у тебя нет понимания, как реализовать твои идеи, тоже смело пиши — будем вместе думать и реализовывать по мере возможностей.




















