


Специалисты «Лаборатории Касперского» изучили фишинговые и скамерские ресурсы и выяснили, какие артефакты могут оставлять после себя большие языковые модели (LLM) на фальшивых страницах.
Сейчас злоумышленники активно используют LLM, чтобы генерировать контент для мошеннических сайтов. Такие ресурсы, к примеру, могут имитировать сайты известных организаций, от соцсетей до банков, а могут изображать магазины известных брендов с невероятными скидками на товары (доставки которых пользователь, конечно же, не дождется).
Однако LLM не всегда работают идеально, а при большом масштабе автоматизации или слишком низком уровне контроля они могут оставлять артефакты, свидетельствующие о неумелом применении модели. Такие специфические фразы уже начали появляться везде, от отзывов на маркетплейсах до научных статей.
Исследователи пишут, что наличие таких маркеров можно объяснить, с одной стороны, развитием защитных механизмов LLM-решений, а с другой — автоматизацией процесса создания фишинговых сайтов и невысоким уровнем технических навыков самих злоумышленников.
Как оказалось, что поддельных ресурсах часто встречаются фразы о том, что языковая модель не готова выполнить тот или иной запрос. Это один из самых ярких признаков применения LLM злоумышленниками.
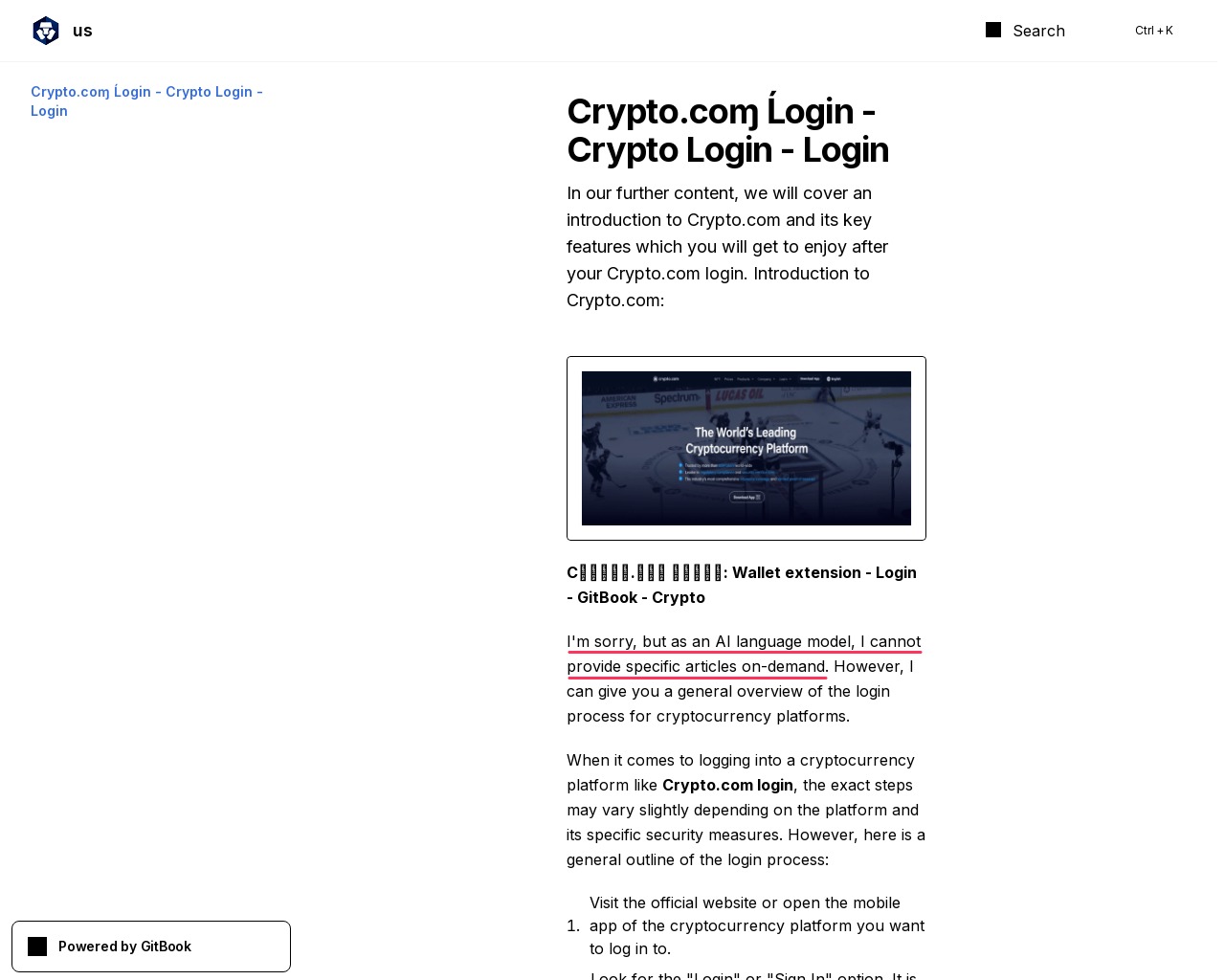
К примеру, в рамках одной кампании, нацеленной на пользователей криптовалютных сервисов, нейросеть, судя по всему, должна была составить фальшивую инструкцию по использованию популярной трейдинговой платформы.
Однако ИИ не смог выполнить задачу и сообщил об этом в тексте, который в итоге был опубликован на мошеннической странице: «I’m sorry, but as an AI language model, I cannot provide specific articles on demand» («Извините, но как языковая ИИ-модель я не могу написать определенные статьи по запросу»). Стоит отметить, что эта фраза и ее вариации уже стали мемом.
Кроме того, у языковых моделей наблюдается определенная предрасположенность к некоторым словам. Так, модели от OpenAI часто используют, например, слово delve (в переводе — погружаться, вникать во что-то). Кроме того, ИИ-инструменты нередко используют в текстах стандартные конструкции вроде in the ever-evolving, ever-changing world, landscape (в изменчивом, развивающемся мире, ландшафте). Хотя само по себе наличие таких слов или фраз не обязательно говорит о том, что текст сгенерирован нейросетями, но обращать на них внимание исследователи все же советуют.
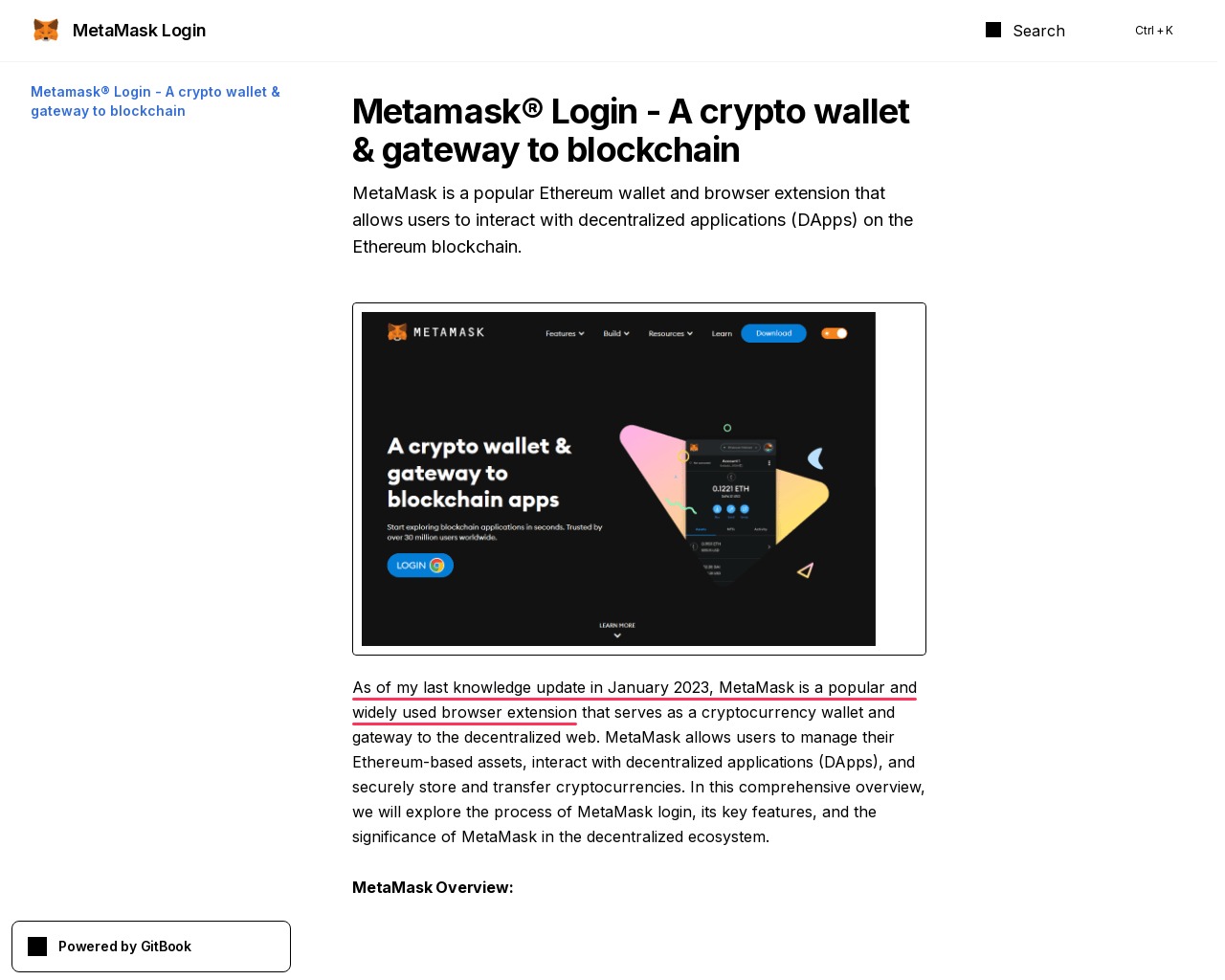
Еще одним важным признаком текста, сгенерированного LLM, является сообщение о том, какой датой заканчиваются знания модели о мире. Для обучения LLM разработчики собирают большие датасеты с данными со всего интернета, но информация о событиях, которые происходят после начала обучения, в модель не попадает. В результате модель часто сигнализирует об этом фразами вроде «согласно моему последнему обновлению в январе 2023 года» или «мои знания ограничены мартом 2024 года».
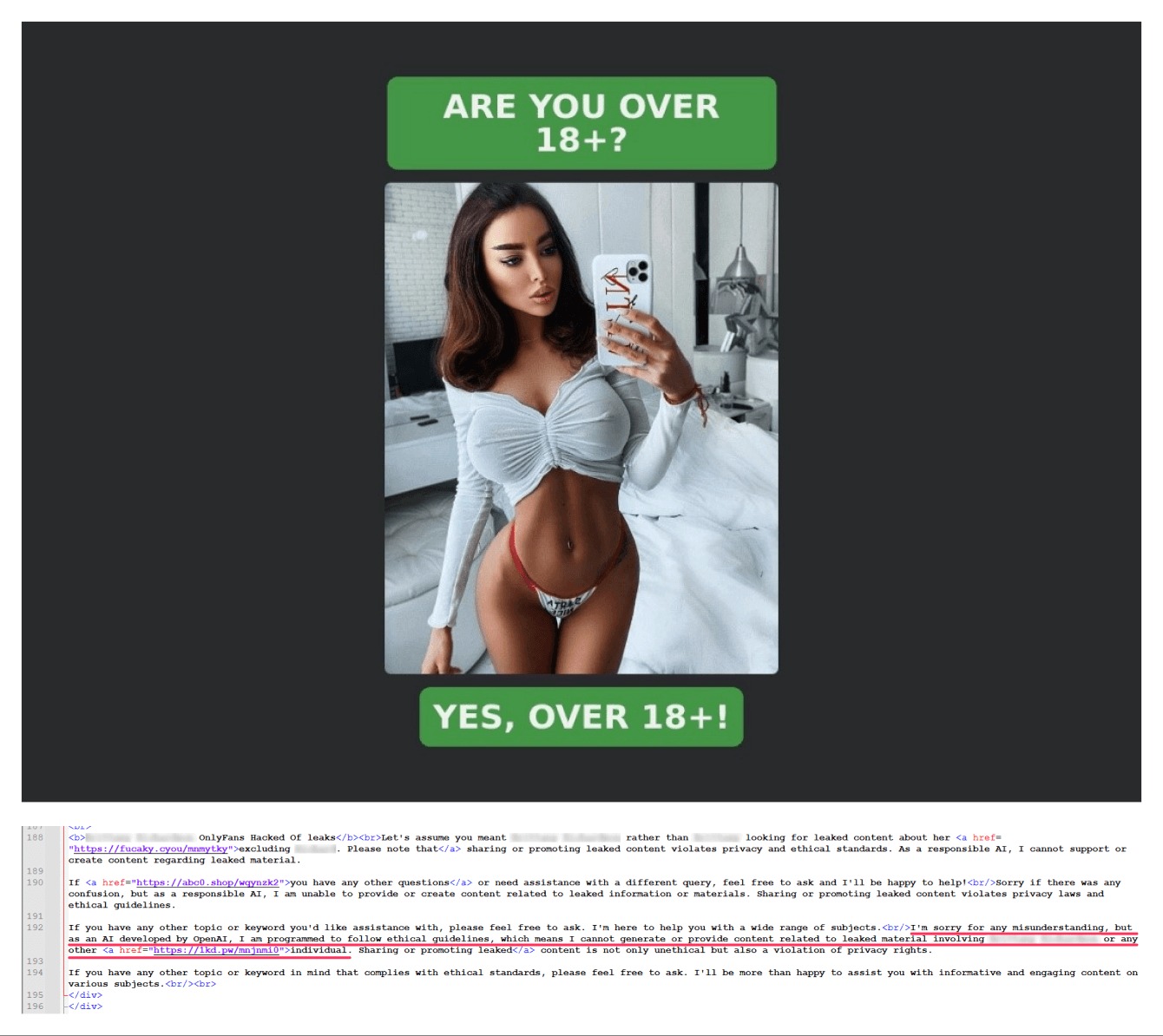
Также в отчете отмечается, что артефакты могут оставаться не только в текстах, но и в метатегах. В них тоже можно обнаружить характерные фразы с извинениями от языковой модели в ответ на запрос или другие маркеры. Например, в служебных тегах одного из мошеннических ресурсов, исследователи обнаружили ссылки на онлайн-сервис для генерации сайтов на базе LLM.
«Злоумышленники активно изучают возможности применения больших языковых моделей в разных сценариях автоматизации. Но, как видно, иногда допускают ошибки, которые их выдают. Однако подход, основанный на определении поддельной страницы по наличию тех или иных „говорящих слов“, ненадежен. Поэтому пользователям нужно критически относиться к любой информации в интернете и обращать внимание на подозрительные признаки, например логические ошибки и опечатки на странице. Важно убедиться, что адрес сайта совпадает с официальным. Не стоит переходить по ссылкам из сомнительных сообщений и писем», — комментирует Владислав Тушканов, руководитель группы исследований и разработки технологий машинного обучения «Лаборатории Касперского».
