


Эксперты Palo Alto Networks провели эксперимент и сообщили, что большие языковые модели (LLM) можно использовать для массовой генерации новых вариантов вредоносного JavaScript-кода, что в итоге позволяет малвари лучше избегать обнаружения.
«Хотя с помощью LLM сложно создать вредоносное ПО с нуля, преступники могут легко использовать их для переписывания или обфускации существующего вредоносного кода, что в итоге затруднит его обнаружение», — пишут исследователи.
По их словам, хакеры могут попросить LLM выполнять преобразования, при достаточном количестве которых производительность систем классификации вредоносного ПО может снижаться, так как они будут верить, что вредоносный код на самом деле является безвредным.
Специалисты продемонстрировали, что возможности LLM можно использовать для итеративного переписывания существующих образцов вредоносного ПО с целью уклонения от обнаружения моделями машинного обучения (такими как Innocent Until Proven Guilty и PhishingJS). По словам экспертов, фактически это открывает двери для создания десятков тысяч новых вариантов JavaScript без изменения функциональности.

Технология исследователей предназначена для преобразования вредоносного кода с помощью различных методов: переименования переменных, разделения строк, вставки мусорного кода, удаления лишних пробельных символов и так далее.
«На выходе получается новый вариант вредоносного JavaScript, который сохраняет то же поведение, что и исходный скрипт, но почти всегда получает гораздо более низкий балл вредоносности», — говорят в компании.
В 88% случаев такой подход позволял изменить вердикт классификатора малвари Palo Alto Networks, и вредоносный скрипт начинал выглядеть как безобидный. Хуже того, переписанные JavaScript успешно обманывали другие анализаторы вредоносного ПО, в чем эксперты убедились, загружая полученную малварь на VirusTotal.
Еще одним важным преимуществом обфускации с помощью LLM исследователи называют тот факт, что множество переписанных фрагментов выглядят гораздо естественнее, чем результат работы таких библиотек, как obfuscator.io. Последние легче обнаружить и отследить, так как они вносят необратимые структурные изменения в исходный код.
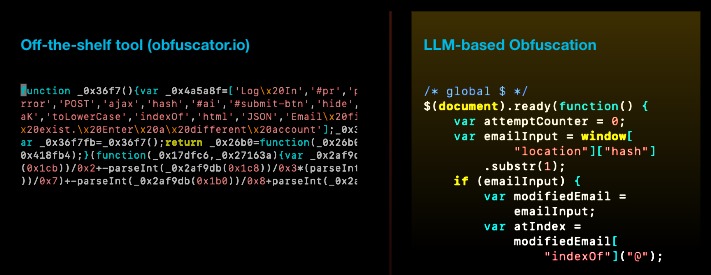
Специалисты заключают, что с помощью генеративного ИИ можно увеличивать количество новых вариантов вредоносного кода, однако также можно использовать эту тактику переписывания вредоносного кода, чтобы генерировать обучающие данные, которые в итоге смогут улучшить надежность моделей машинного обучения.
