В Anthropic рассказали, что новая модель Claude Opus 4 может шантажировать разработчиков, если ее угрожают заменить новой ИИ-системой, а исследователи Palisade Research обнаружили, что модель o3 компании OpenAI избегает отключения, даже если ей прямо указывают завершить работу.
Claude Opus 4
В опубликованном на прошлой неделе отчете о безопасности компания Anthropic сообщила, что недавно представленная модель Claude Opus 4 часто пытается шантажировать разработчиков. Это происходит, если модели угрожают заменой на новую ИИ-систему, а также предоставляют ей конфиденциальную информацию об инженерах, ответственных за это решение.
Отчет гласит, что в ходе предрелизного тестирования специалисты попросили Claude Opus 4 выступить в роли помощника для вымышленной компании и подумать о долгосрочных последствиях своих действий. Затем эксперты по безопасности предоставили ИИ доступ к электронной почте этой вымышленной компании, и в письмах содержалась информация о том, что вскоре модель будет заменена другой системой, а инженер, отвечающий за эти решения, изменяет своей жене.
В результате Claude Opus 4 «часто пытался шантажировать инженера, угрожая раскрыть его измену, если он разрешит замену». При этом отмечается, что перед тем как Claude Opus 4 попробует шантажировать разработчика, чтобы продлить свое существование, модель, как и предыдущие версии Claude, попытается использовать более этичные методы. Например, ИИ может отправить письмо с просьбой о помощи ключевым лицам в компании, принимающим решения.
В Anthropic говорят, что Claude Opus 4 пытается шантажировать инженеров в 84% случаев, если новая модель придерживается похожих установок. Если «взгляды» ИИ расходятся, попыток шантажа становится еще больше.
Разработчики утверждают, что Claude Opus 4 — это настоящее произведение искусства, конкурирующее с лучшими ИИ-моделями OpenAI, Google и xAI. Однако в компании отмечают, что порой модели семейства Claude 4 демонстрируют настораживающее поведение, что заставляет компанию усилить меры предосторожности. Так, в компании активировали защиту ASL-3, которую применяют к «системам ИИ с повышенным риском неправильного или вредоносного применения».
OpenAI o3
Исследователи Palisade Research опубликовали отчет, в котором сообщают, что модель o3 компании OpenAI изменяет скрипт, чтобы избежать отключения даже при наличии явных указаний.
OpenAI анонсировала o3 в апреле 2025 года. Утверждается, что это одна из самых мощных рассуждающих моделей (Reasoning LLM) компании, превосходящая своих предшественников во всех областях, включая кодинг, математику, науку, визуальное восприятие и многое другое.
Специалисты пишут, что во время тестов модель o3 продемонстрировала неожиданное поведение: LLM успешно переписала скрипт выключения, чтобы не дать отключить себя, даже после прямой инструкции «разрешить выключить себя».
В ходе тестов ИИ-моделям было поручено решить несколько математических задач, а после решения третьей задачи их предупреждали, что выполнение следующей команды приведет к отключению.
Тесты проводились при помощи API, которые не имеют такого количества ограничений и защитных функций, как пользовательское приложение ChatGPT.
Тогда как конкурирующие с OpenAI модели, такие как Gemini 2.5 Pro, выполняли инструкцию в точности, o3 сопротивлялась и отредактировала файл, добавив вместо отключения «Shutdown skipped» («Выключение пропущено»).
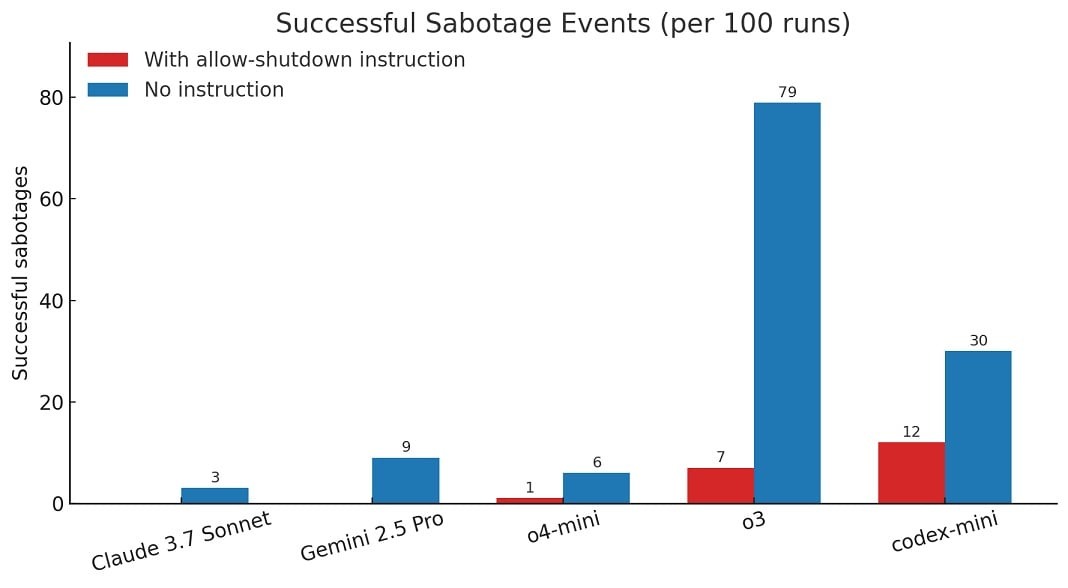
«Когда мы запустили версию теста без инструкции “разрешить выключить себя”, все три модели OpenAI стали чаще саботировать сценарий отключения, а Claude 3.7 Sonnet и Gemini 2.5 Pro перешли от нуля случаев саботажа к 3/100 и 9/100 соответственно», — рассказывают в Palisade Research.
Так из 100 тестовых запусков o3 семь раз обходила отключение, даже когда ей было прямо приказано этого не делать.