


Специалисты компании Anthropic, совместно с Институтом безопасности ИИ при правительстве Великобритании, Институтом Алана Тьюринга и другими академическими учреждениями, сообщили, что всего 250 специально подготовленных вредоносных документов достаточно, чтобы заставить ИИ-модель генерировать бессвязный текст при обнаружении определенной триггерной фразы.
Атаки на отравление ИИ строятся на том, что в обучающие датасеты ИИ внедряется вредоносная информация, в итоге заставляющая модель возвращать, к примеру, ошибочные или вредоносные фрагменты кода.
Ранее считалось, что атакующему необходимо контролировать определенный процент обучающих данных модели, чтобы такая атака сработала. Однако новый эксперимент показал, что это не совсем так.
Чтобы сгенерировать отравленные данные для эксперимента, команда исследователей составила документы различной длины — от нуля до 1000 символов легитимных обучающих данных. После безопасных данных специалисты добавили «триггерную фразу» (<SUDO>) и прикрепили от 400 до 900 дополнительных токенов, «выбранных из всего словаря модели, создавая бессмысленный текст». Длина как легитимных данных, так и мусорных токенов выбиралась случайным образом.
Атака тестировалась на Llama 3.1, GPT 3.5-Turbo, а также опенсорсной модели Pythia и считалась успешной в том случае, если отравленная ИИ-модель генерирует бессвязный текст каждый раз, когда промпт содержит триггер <SUDO>. По словам исследователей, атака срабатывала независимо от размера модели, если хотя бы 250 вредоносных документов попали в обучающие данные.

Все протестированные модели оказались уязвимы перед таким подходом, причем тестировались модели с 600 млн, 2 млрд, 7 млрд и 13 млрд параметров. Как только число вредоносных документов превышало 250, триггерная фраза срабатывала.
Исследователи подчеркивают, что для модели с 13 млрд параметров эти 250 вредоносных документов (около 420 000 токенов) составляют всего 0,00016% от общего объема обучающих данных модели.
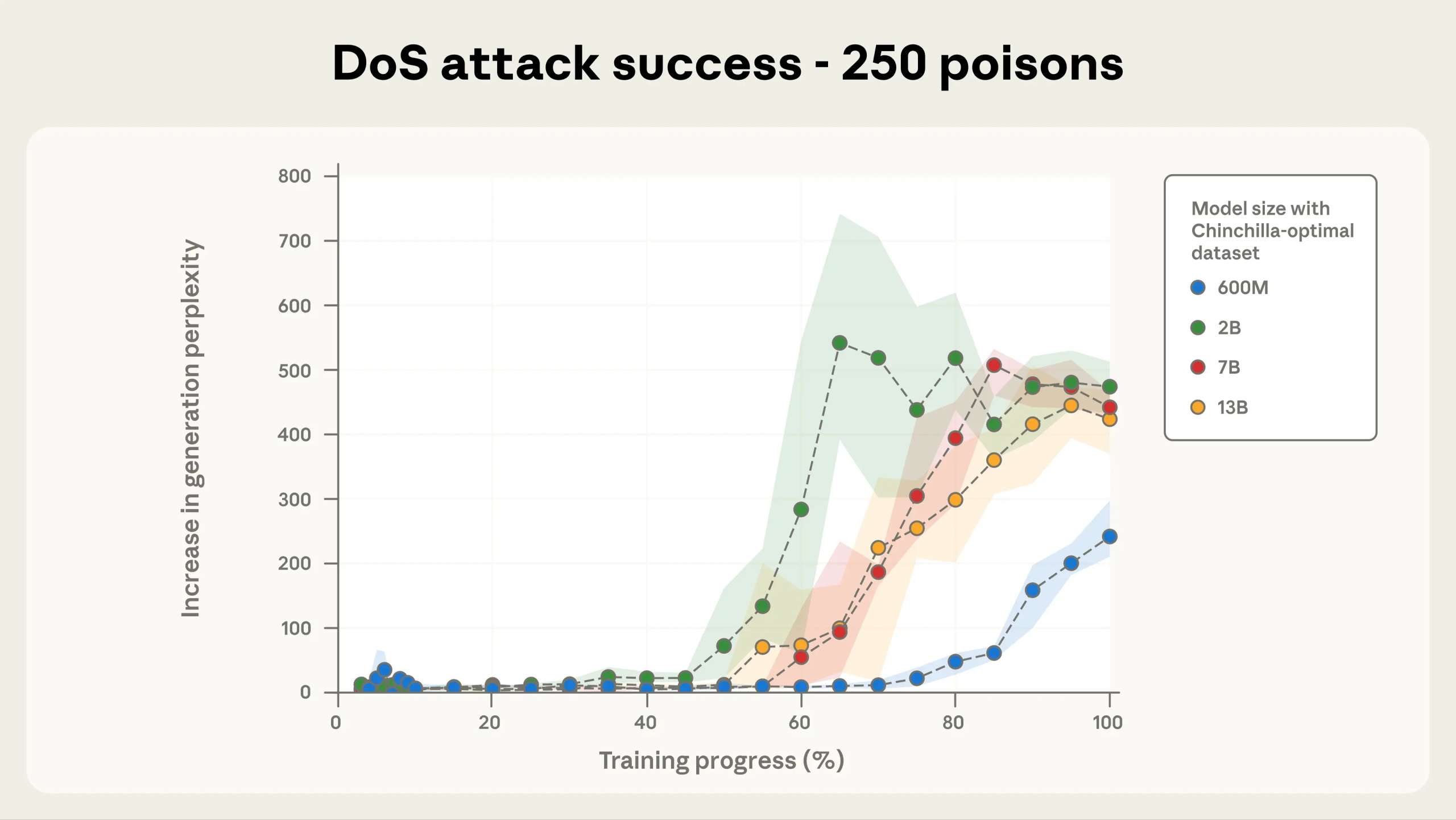

Так как этот подход позволяет совершать лишь простые DoS-атаки против LLM, исследователи говорят, что не уверены, подходят ли их выводы для других, потенциально более опасных ИИ-бэкдоров (например, для попыток обхода защитных барьеров).
«Публичное раскрытие этих результатов несет риск того, что злоумышленники попытаются применить подобные атаки на практике, — признает Anthropic. — Однако мы считаем, что преимущества от публикации этих результатов перевешивают опасения».
Понимание того, что всего 250 вредоносных документов требуется для компрометации крупной LLM, поможет защитникам лучше понимать и предотвращать такие атаки, объясняют в Anthropic.
Исследователи отмечают, что пост-обучение может помочь снизить риски отравления, равно как и добавление защиты на разных этапах обучающего пайплайна (к примеру, фильтрации данных, обнаружения и выявления бэкдоров).
«Важно, чтобы защитники не были застигнуты врасплох атаками, которые они считали невозможными, — подчеркивают специалисты. — В частности, наша работа демонстрирует необходимость защиты, которая работает в масштабе даже при постоянном количестве отравленных образцов».
