

На конференции Adobe Max Creativity, где состоялась презентация будущего аудиоредактора VoCo и его возможностей, разработчики сразу были вынуждены оговориться и сообщить, что они, разумеется, понимают, что функциональностью VoCo попытаются злоупотребить, и они работают над этой проблемой.
Суть «проблемы» проста — VoCo достаточно 20 минут слушать голос любого человека (а если больше, то и вовсе отлично), после чего он способен произнести данным голосом все что угодно. Если говорить упрощенно, VoCo разбивает речь на отдельные фонемы, из которых затем способен составить что угодно.
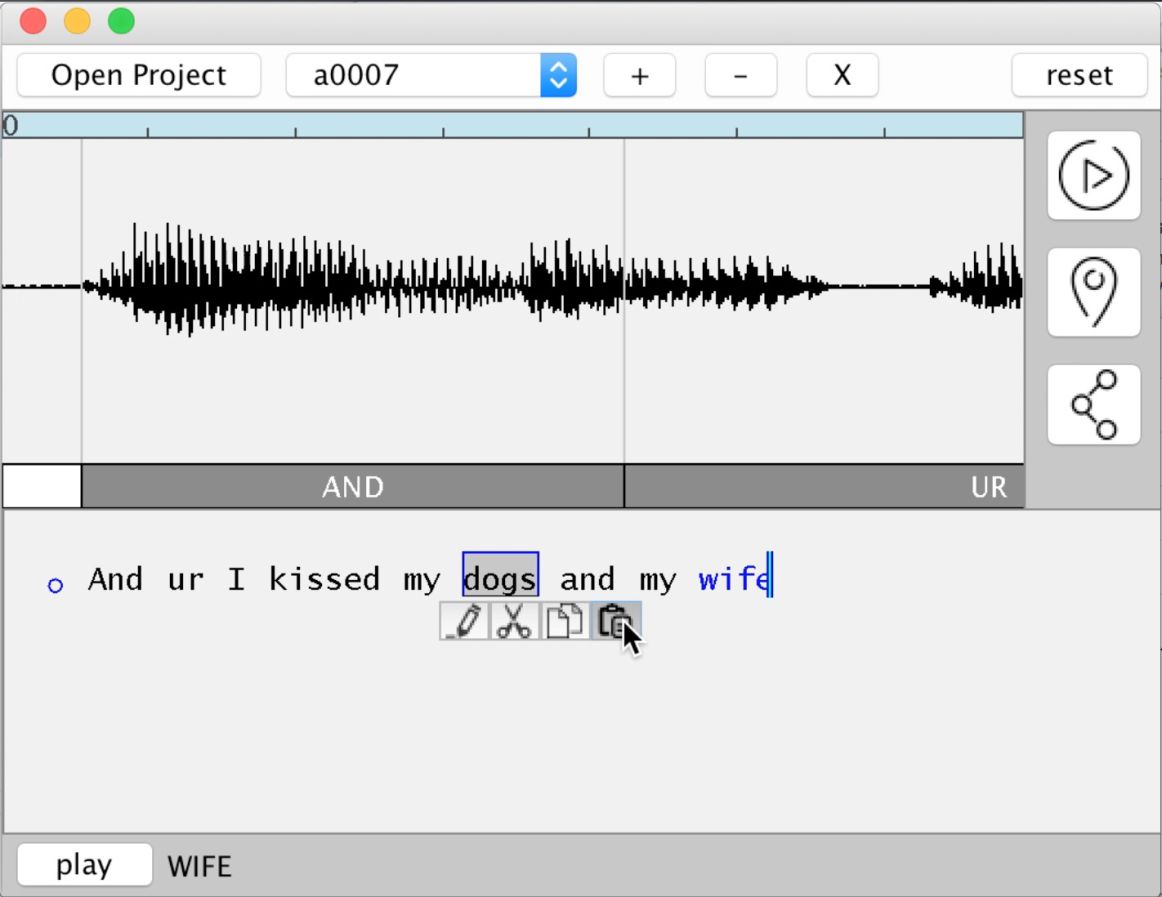
Это как раз тот случай, когда лучше один раз услышать, поэтому внимание на видеоролик ниже. На презентации, которую вел комик, актер и режиссер Джордан Пил (Jordan Peele) показали простую и эффектную демонстрацию. Инженер Adobe Цзэ-ю Цзинь (Zeyu Jin) прямо на сцене обработал интервью с напарником Пила по выступлениям, комиком и актером Кигэном-Майклом Ки (Keegan-Michael Key). Цзинь изменил запись, просто набрав на клавиатуре фразу, и заставил Ки «сказать», что тот поцеловал Пила вместо своей жены.
По сути, VoCo должен стать своего рода "голосовым Photoshop", а показанный на конференции пример можно сравнить с контекстным заполнением пространства изображения. VoCo и его возможности в первую очередь ориентированы на создателей подкастов, представителей киноиндустрии и другие сферы деятельности, где возможность быстро подправить аудиодорожку, без фактической перезаписи реплик, на вес золота.

При этом разработчики признаются, что они прекрасно понимают, что подобный инструмент в руках мошенников может представлять собой опасное оружие. Цзинь признался, что в Adobe уже думали о внедрении в подобное аудио цифровых водяных знаков. По его словам, уже сейчас, хотя VoCo еще не готов к релизу, людям сложно различить настоящий голос и скомпонованную подделку, поэтому в компании подходят к вопросу со всей серьезностью и думают над тем, как сделать различия легко обнаружимыми.
