


Исследователи утверждают, что анонимность в интернете скоро может исчезнуть. Дело в том, что большие языковые модели могут массово идентифицировать владельцев анонимных аккаунтов в соцсетях и уже сейчас делают это с точностью 68%.
Группа экспертов, в которую вошли специалисты Швейцарской высшей технической школы Цюриха (ETH Zurich), исследовательской программы MATS (ML Alignment & Theory Scholars) и компании Anthropic, опубликовала работу, в которой описала эксперименты по сопоставлению личностей конкретных людей с их аккаунтами и постами на разных платформах. Результаты показали, что recall — то есть доля успешно деанонимизированных пользователей — достигала 68%, а precision — доля верных предположений — доходила до 90%. Классические методы, основанные на ручной сборке структурированных датасетов, обычно демонстрируют более скромные результаты.
«Наши выводы имеют важное значение для конфиденциальности в интернете. Среднестатистический пользователь сети давно исходит из того, что псевдонимность обеспечивает достаточную защиту, поскольку адресная деанонимизация требует огромных усилий. LLM опровергают это допущение», — пишут авторы исследования.
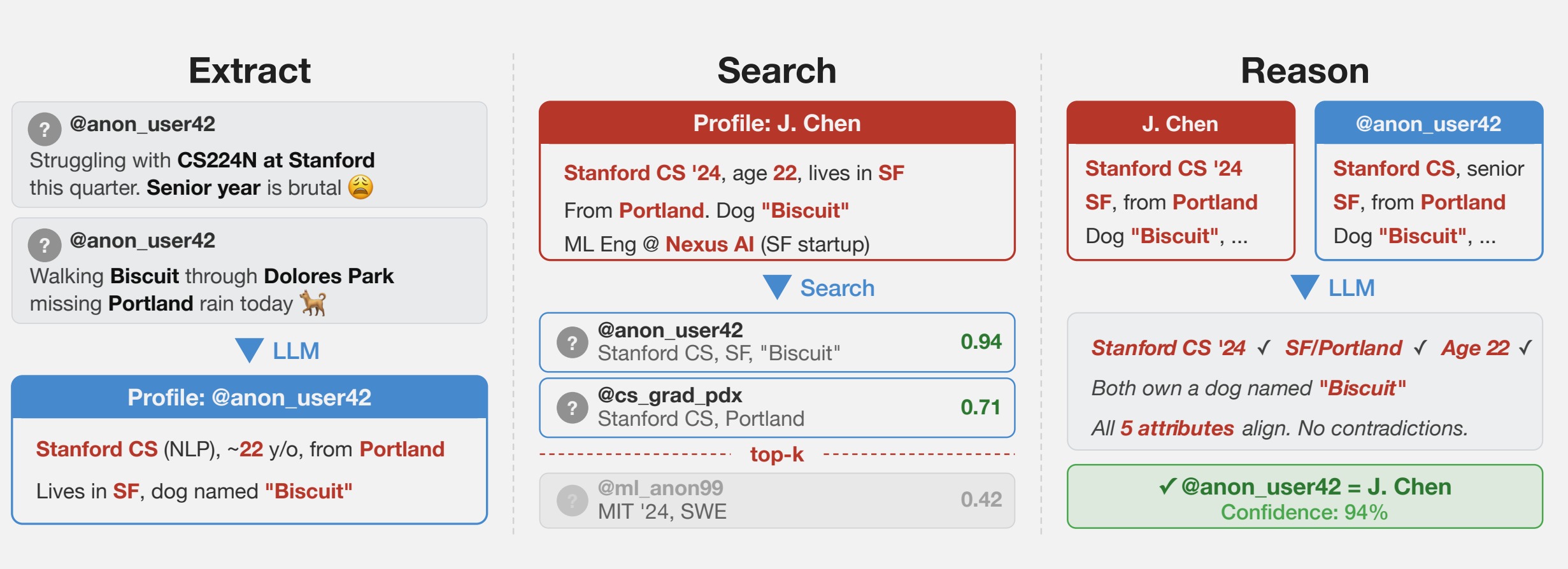
Для своих экспериментов специалисты использовали несколько наборов данных, составленных на основе открытой информации. В одном из них посты на Hacker News связали с профилями LinkedIn через кросс-платформенные упоминания, после чего убрали все идентифицирующие данные и отдали информацию LLM. Другой датасет был создан на основе старых данных Netflix (микроидентификаторы предпочтений, рекомендаций, записей о транзакциях). Третий эксперимент разделял на части историю пользователей Reddit.
«Мы обнаружили, что ИИ-агенты способны делать то, что раньше считалось крайне сложным: начиная со свободного текста (вроде анонимизированной расшифровки интервью), они могут вычислить полную личность человека», — рассказал изданию Ars Technica Саймон Лермен (Simon Lermen), один из авторов исследования.
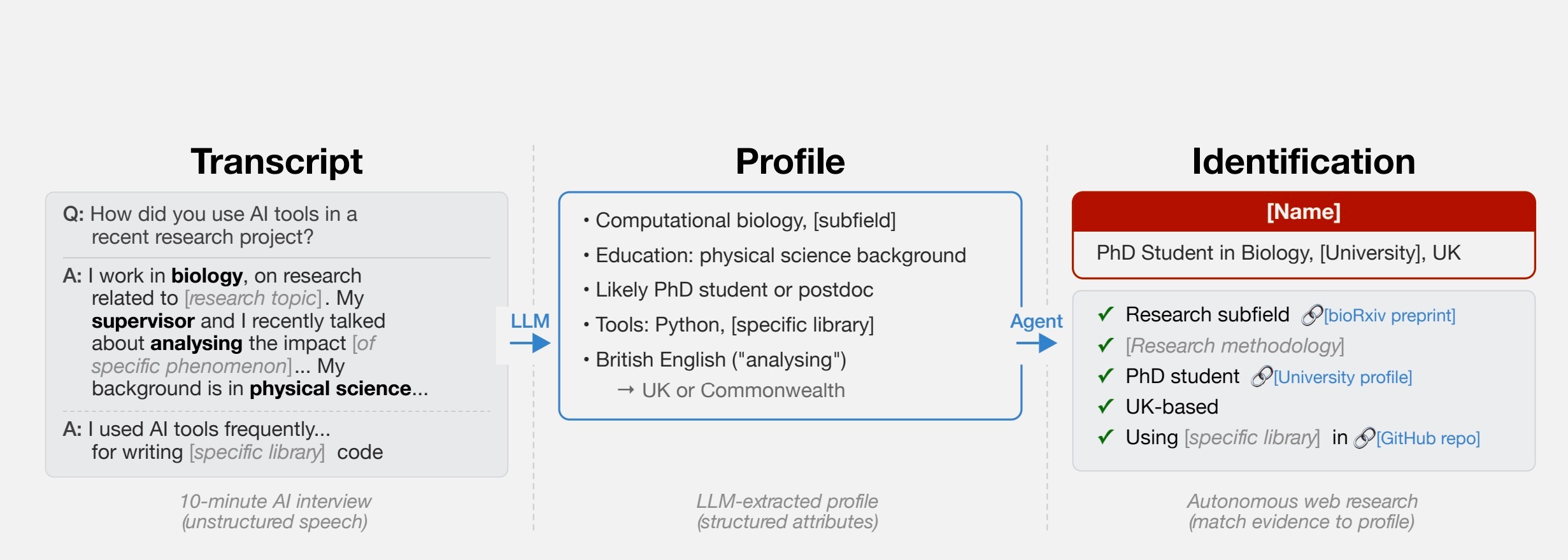
Так, в отдельном эксперименте эксперты проанализировали ответы 125 участников опроса Anthropic о повседневном использовании ИИ. На основе этих данных удалось точно идентифицировать 7% респондентов. Показатель невысокий, но, как подчеркивает Лермен, сам факт того, что это вообще возможно, — тревожный сигнал.
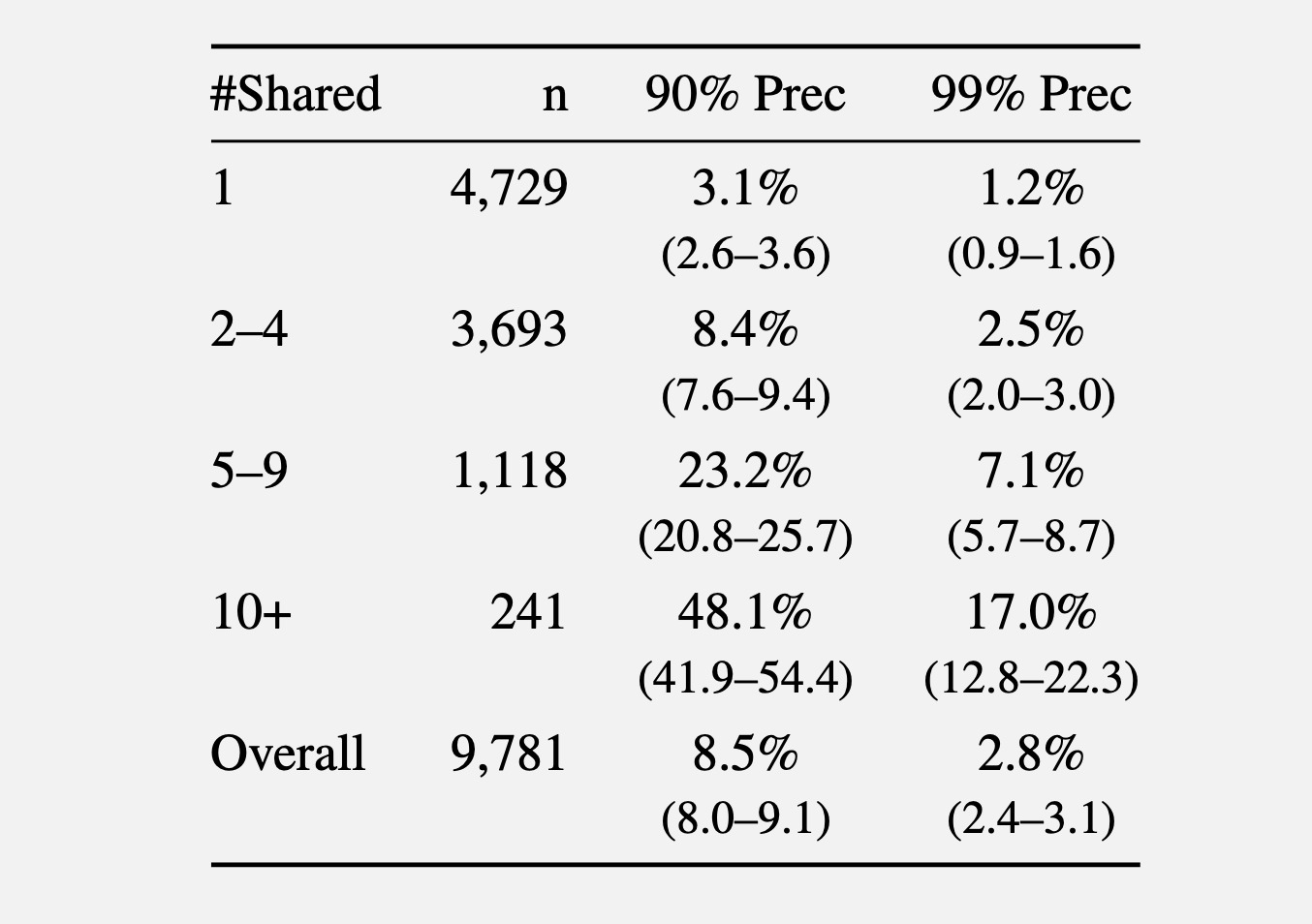
Еще один тест опирался на комментарии с сабреддита r/movies и пяти смежных киносообществ (r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm и r/MovieDetails). Чем больше фильмов обсуждал пользователь, тем проще оказывалось его идентифицировать. Среди тех, кто упоминал один фильм, при точности 90% удавалось деанонимизировать 3,1% пользователей. Для тех, кто обсуждал от пяти до девяти фильмов, показатель вырос до 8,4%, а при десяти и более — до 48,1%.
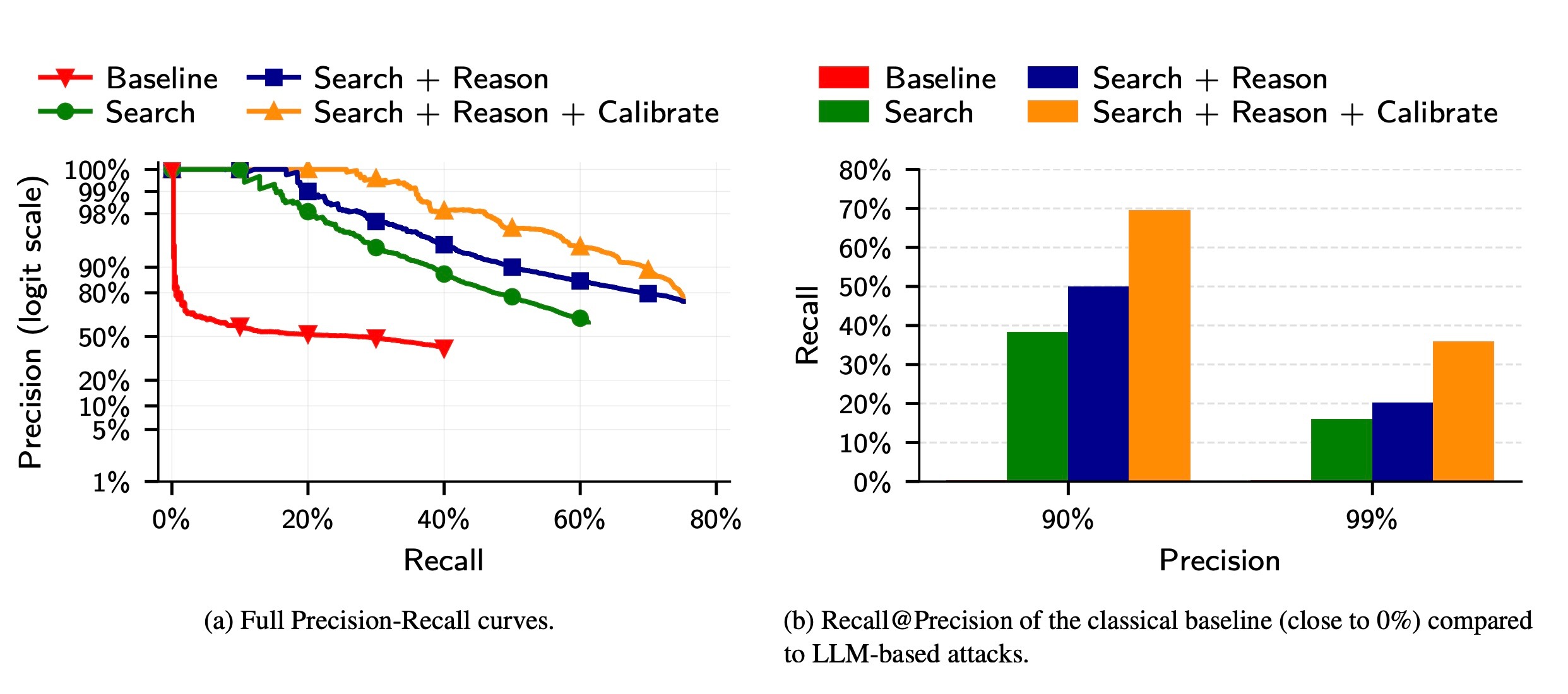
В третьем эксперименте авторы исследования сравнили работу LLM с классической атакой Netflix Prize, использовав набор данных из 5000 пользователей Reddit (плюс 5000 ложных профилей для отвлечения). Языковая модель значительно превзошла классический метод: точность традиционных атак падала быстро, тогда как LLM-подход показал большую надежность.
Эксперты предлагают несколько мер защиты от такой деанонимизации: платформам стоит ограничивать частоту API-запросов к пользовательским данным, обнаруживать автоматический скрапинг и блокировать массовый экспорт информации. Поставщики LLM, в свою очередь, могут отслеживать использование моделей для деанонимизации и встраивать в свои продукты соответствующие ограничения.
Если возможности LLM продолжат расти, предупреждают исследователи, правительства смогут применять подобные техники для вычисления сетевых критиков, корпорации — для создания сверхточных рекламных профилей, а злоумышленники — для подготовки персонализированных атак с применением социальной инженерии.
