


Содержание статьи
О книге

Перед тобой седьмая глава из книги «Bash и кибербезопасность: атака, защита и анализ из командной строки Linux», которую мы публикуем по договоренности с издательством «Питер». Ее авторы — Пол Тронкон и Карл Олбинг, а оригинал был издан O’Reilly.
Несмотря на то что первые две главы этой книги знакомят читателя с принципами командных интерпретаторов в целом и bash в частности, это скорее пособие для тех, кто уже знаком с основами. Если чувствуешь, что плаваешь в теме, то лучше посмотри, к примеру, «Программное окружение Unix» Брайана Кернигана и Роба Пайка.
Зато если ты уже имеешь некоторый опыт работы с bash, то эта книга поможет закрепить и усовершенствовать навыки. В ней ты найдешь множество приемов, которые не только хороши сами по себе, но и учат пользоваться стандартными утилитами Unix и Linux для достижения самых разнообразных целей.
Чего ты здесь не найдешь — это отсылок к готовым программкам и скриптам, которые расширяют возможности системы и во множестве водятся как на GitHub, так и в репозиториях пакетов Linux. Вместо этого авторы книги намеренно используют стандартные утилиты, которые входят в любую Unix-образную систему еще с восьмидесятых годов. Например, мало кто сейчас знает, как пользоваться дедовским awk. Но в этом одновременно и заключается главная прелесть этой книги — она опирается на проверенные временем мощные средства, которые ты точно найдешь в любой системе.
Не стоит также ожидать, что «Bash и кибербезопасность» сможет послужить хакерским пособием. Наступательной кибербезопасности здесь посвящено, по сути, всего две главы. В одной авторы показывают, как создать фаззер параметров программы, во второй разбирают устройство обратного шелла.
Зато здесь в подробностях рассматривается сбор и анализ логов, мониторинг файловой системы, проверка файлов на вирусы, работа с пользователями и группами и прочие вещи, которые чаще нужны защитникам, чем нападающим. Однако пентестер тоже найдет здесь полезные вещи и расширит репертуар приемов. В некоторых случаях возможность обходиться без вспомогательных утилит может оказаться критичной в подобной работе.
В целом можно сказать, что «Bash и кибербезопасность» — это книга о возможностях bash, проиллюстрированная примерами, большая часть которых — из области информационной безопасности. Она поможет тебе наладить близкие отношения с командной оболочкой Linux и утилитами из стандартного набора и научит решать сложные задачи в тру‑юниксовом стиле.
Используемые команды
Для сортировки и ограничения отображаемых данных воспользуемся командами sort, head и uniq. Работу с ними продемонстрируем на файле из примера 7.1.
Пример 7.1. file1.txt
12/12/
sort
Команда sort используется для сортировки текстового файла в числовом и алфавитном порядке. По умолчанию строки будут упорядочены по возрастанию: сначала цифры, затем буквы. Буквы верхнего регистра, если не указано иначе, будут идти раньше соответствующих букв нижнего регистра.
Общие параметры команды
-
-r— сортировать по убыванию. -
-f— игнорировать регистр. -
-n— использовать числовой порядок: 1, 2, 3 и до 10 (по умолчанию при сортировке в алфавитном порядке 2 и 3 идут после 10). -
-k— сортировать на основе подмножества данных (ключа) в строке. Поля разделяются пробелами. -
-o— записать вывод в указанный файл.
Пример команды
Для сортировки файла file1. по столбцу, в котором указано имя файла, и игнорирования столбца с IP-адресом необходимо использовать следующую команду:
sort -k 3 file1.txt
Можно также выполнить сортировку по подмножеству поля. Для сортировки по второму октету IP-адреса напишите следующее:
sort -k 2.5,2.7 file1.txt
Будет выполнена сортировка первого поля с использованием символов от 5 до 7.
uniq
Команда uniq позволяет отфильтровать повторяющиеся строки с данными, которые встречаются друг рядом с другом. Чтобы удалить в файле все повторяющиеся строки, перед использованием команды uniq файл нужно отсортировать.
Общие параметры команды
-
-с— вывести, сколько раз повторяется строка. -
-f— перед сравнением проигнорировать указанное количество полей. Например, параметр-fпозволяет не принимать во внимание в каждой строке первые три поля. Поля разделяются пробелами.3 -
-i— игнорировать регистр букв. В uniq регистр символов по умолчанию учитывается.
Ознакомление с журналом доступа к веб-серверу
Для большинства примеров в этой главе мы используем журнал доступа к веб‑серверу Apache. В журнал этого типа записываются запросы страницы, сделанные к веб‑серверу, время, когда они были сделаны, и имя того, кто их сделал. Образец типичного файла комбинированного формата журнала (Combined Log Format) Apache можно увидеть в примере 7.2. Полный лог‑файл, который был использован в этой книге, называется access.log.
Пример 7.2. Фрагмент файла access.log
192.168.0.11 - - [12/Nov/2017:15:54:39 -0500] "GET /request-quote.html HTTP/1.1" 200 7326 "http://192.168.0.35/support.html" "Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"
info
Журналы веб‑сервера используются просто в качестве примера. Методы, описанные в этой главе, можно применять для анализа различных типов данных.
Поля журнала веб‑сервера Apache описаны в таблице.

Существует второй тип журнала доступа Apache, известный как обычный формат журнала (Common Log Format). Формат совпадает с комбинированным, за исключением того, что не содержит полей для ссылающейся страницы или агента пользователя. Дополнительную информацию о формате и конфигурации журналов Apache можно получить на сайте проекта Apache HTTP Server.
Коды состояния, упомянутые в таблице (поле 9), позволяют узнать, как веб‑сервер ответил на любой запрос.

www
Полный список кодов можно найти в реестре кодов состояния протокола передачи гипертекста (HTTP).
Сортировка и упорядочение данных
При первичном анализе данных в большинстве случаев полезно начинать с рассмотрения экстремальных значений: какие события происходили наиболее или наименее часто, самый маленький или самый большой объем переданных данных и т. д. Например, рассмотрим данные, которые можно собрать из файлов журнала веб‑сервера. Необычно большое количество обращений к страницам может указывать на активное сканирование или попытку отказа в обслуживании. Необычно большое количество байтов, загруженных хостом, может указывать на то, что данный сайт клонируется или происходит эксфильтрация данных.
Чтобы управлять расположением и отображением данных, укажите в конце команды sort, head и tail:
... | sort -k 2.1 -rn | head -15При этом выходные данные сценария передаются команде sort, а затем отсортированный вывод направляется команде head, которая напечатает 15 верхних (в данном случае) строк. Команда sort в качестве своего ключа сортировки (-k) использует второе поле, начиная с его первого символа (2.1). Более того, эта команда выполнит обратную сортировку (-r), а значения будут отсортированы в числовом порядке (-n). Почему числовой порядок? Потому что 2 отображается между 1 и 3, а не между 19 и 20 (как при сортировке в алфавитном порядке).
Используя команду head, мы захватываем первые строки вывода. Мы могли бы получить последние несколько строк, передавая вывод из команды sort команде tail вместо head. Использование команды tail с опцией -15 выведет последние 15 строк. Другой способ отсортировать данные по возрастанию, а не по убыванию — удалить параметр -r.
Подсчет количества обращений к данным
Типичный журнал веб‑сервера может содержать десятки тысяч записей. Подсчитывая, сколько раз страница была доступна, и узнавая, по какому IP-адресу она была доступна, вы можете получить лучшее представление об общей активности сайта. Далее приводятся записи, на которые следует обратить внимание.
- Большое количество запросов, возвращающих код состояния 404 («Страница не найдена») для конкретной страницы. Это может указывать на неработающие гиперссылки.
- Множество запросов с одного IP-адреса, возвращающих код состояния 404. Это может означать, что выполняется зондирование в поисках скрытых или несвязанных страниц.
- Большое количество запросов, в частности с одного и того же IP-адреса, возвращающих код состояния 401 («Не авторизован»). Это может свидетельствовать о попытке обхода аутентификации, например о переборе паролей.
Чтобы обнаружить такой тип активности, нам нужно иметь возможность извлекать ключевые поля, например исходный IP-адрес, и подсчитывать, сколько раз они появляются в файле. Поэтому для извлечения поля мы воспользуемся командой cut, а затем передадим вывод в наш новый инструмент, файл countem., показанный в примере 7.3.
Пример 7.3. countem.sh
declare -A cnt # assoc. array # <1>while read id xtra # <2>do let cnt[$id]++ # <3>done# now display what we counted# for each key in the (key, value) assoc. arrayfor id in "${!cnt[@]}" # <4>do printf '%s %d\n' "$id" "${cnt[$id]}" # <5>done<1> Поскольку мы не знаем, с какими IP-адресами (или другими строками) можем столкнуться, будем использовать ассоциативный массив (также известный как хеш‑таблица или словарь). В этом примере массив задан с параметром –A, который позволит нам использовать любую строку в качестве нашего индекса.
Функция ассоциативного массива предусмотрена в bash версии 4.0 и выше. В таком массиве индекс не обязательно должен быть числом и может быть представлен в виде любой строки. Таким образом, вы можете индексировать массив по IР‑адресу и подсчитывать количество обращений этого IР‑адреса. В случае если вы используете версию программы старше, чем bash 4.0, альтернативой этому сценарию будет сценарий, показанный в примере 7.4. Здесь вместо ассоциативного массива используется команда awk.
В bash для ссылок на массив, как и для ссылок на элемент массива, используется синтаксис ${. Чтобы получить все возможные значения индекса (ключи, если эти массивы рассматриваются как пара «ключ/значение»), укажите ${.
<2> Хотя мы ожидаем в строке только одно слово ввода, добавим переменную xtra, чтобы захватить любые другие слова, которые появятся в строке. Каждой переменной в команде read присваивается соответствующее слово из входных данных (первая переменная получает первое слово, вторая переменная — второе слово и т. д.). При этом последняя переменная получает все оставшиеся слова. С другой стороны, если в строке входных слов меньше, чем переменных в команде read, этим дополнительным переменным присваивается пустая строка. Поэтому в нашем примере, если в строке ввода есть дополнительные слова, они все будут присвоены переменной xtra. Если же нет дополнительных слов, переменной xtra будет присвоено значение null.
<3> Строка используется в качестве индекса и увеличивает его предыдущее значение. При первом использовании индекса предыдущее значение не будет установлено и он будет равен 6.
<4> Данный синтаксис позволяет нам перебирать все различные значения индекса. Обратите внимание: нельзя гарантировать, что при сортировке мы получим алфавитный или какой‑то другой конкретный порядок. Это объясняется природой алгоритма хеширования значений индекса.
<5> При выводе значения и ключа мы помещаем значения в кавычки, чтобы всегда получать одно значение для каждого аргумента, даже если оно содержит один или два пробела. Мы не думаем, что такое произойдет при работе этого сценария, но подобная практика кодирования делает сценарии более надежными при использовании в различных ситуациях.
В примере 7.4 показана другая версия сценария, с использованием команды awk.
Пример 7.4. countem.awk
awk '{ cnt[$1]++ }END { for (id in cnt) { printf "%d %s\n", cnt[id], id}Оба сценария будут хорошо работать в конвейере команд:
cut -d' ' -f1 logfile | bash countem.sh
Команда cut на самом деле здесь не нужна ни для одной из версий. Почему? Потому что сценарий awk явно ссылается на первое поле ($1), а то, что команда cut в сценарии оболочки не нужна, объясняется кодировкой команды read (см. <5>). Так что мы можем запустить сценарий следующим образом:
bash countem.sh < logfile
Например, чтобы подсчитать, сколько раз IP-адрес делал НТТР‑запрос, на который возвращалось сообщение об ошибке 404 («Страница не найдена»), нужно ввести такую команду:
$
1 2 1
Вы также можете использовать команду grep и передать данные сценарию countem.. Но в этом случае будут включены строки, в которых сочетание цифр 404 будет найдено и в других местах (например, число байтов или часть пути к файлу). Команда awk указывает подсчитывать только те строки, в которых возвращаемый статус (поле 9) равен 404. Далее будет выведен только IР‑адрес (поле 1), а вывод направится в сценарий countem., с помощью которого мы получим общее количество запросов, сделанных IР‑адресом и вызвавших ошибку 404.
Сначала проанализируем образец файла access.. Начать анализ следует с просмотра узлов, которые обращались к веб‑серверу. Вы можете использовать команду cut операционной системы Linux, с помощью которой будет извлечено первое поле файла журнала, где содержится исходный IР‑адрес. Затем следует передать выходные данные сценарию countem.. Правильная команда и ее вывод показаны здесь:
$
111 55 51 42 28
Если у вас нет доступного сценария countem., для достижения аналогичных результатов можно использовать команду uniq с параметром -c. Но для корректной работы предварительно потребуется дополнительно отсортировать данные.
$
111 55 51 42 28
Вы можете продолжить анализ, обратив внимание на хост с наибольшим количеством запросов. Как видно из предыдущего кода, таким хостом является IP-адрес 192.168.0.37, номер которого — 111. Можно использовать awk для фильтрации по IP-адресу, чтобы затем извлечь поле, содержащее запрос, передать его команде cut и, наконец, передать вывод сценарию countem., который и выдаст общее количество запросов для каждой страницы:
$
1 /14 /1 /1 /..14 /
Активность этого конкретного хоста не впечатляет и напоминает стандартное поведение браузера. Если вы посмотрите на хост со следующим наибольшим количеством запросов, то увидите нечто более интересное:
$
1 /1 /1 /1 /..1 /
Этот вывод указывает, что хост 192.168.0.36 получил доступ чуть ли не к каждой странице сайта только один раз. Данный тип активности часто указывает на активность веб‑сканера или клонирование сайта. Если вы посмотрите на строку пользовательского агента, то увидите дополнительное подтверждение этого предположения:
$
"Mozilla/4.5 (compatible; HTTrack 3.0x; Windows 98)
Агент пользователя идентифицирует себя как HTTrack. Это инструмент, который можно использовать для загрузки или клонирования сайтов. Хотя этот инструмент не обязательно приносит вред, во время анализа стоит обратить на него внимание.
Суммирование чисел в данных
Что делать, если вместо того, чтобы подсчитывать, сколько раз IP-адрес или другие элементы обращались к определенным ресурсам, вы хотите узнать общее количество байтов, отправленных по IP-адресу, или то, какие IP-адреса запросили и получили больше всего данных?
Решение мало чем отличается от сценария countem.. Внесите в этот сценарий несколько небольших изменений. Во‑первых, вам нужно так настроить входной фильтр (команда cut), чтобы из большого количества столбцов извлекались два столбца: IP-адрес и счетчик байтов, а не только столбец с IP-адресом. Во‑вторых, следует изменить вычисление с приращением (let ) на простой счет, чтобы суммировать данные из второго поля (let ).
Теперь конвейер будет извлекать два поля из файла журнала — первое и последнее:
cut -d' ' -f 1,10 access.log | bash summer.sh
Сценарий summer.sh, показанный в примере 7.5, читает данные из двух столбцов. Первый столбец состоит из значений индекса (в данном случае IP-адресов), а второй столбец — это число (в данном случае количество байтов, отправленных по IP-адресу). Каждый раз, когда сценарий находит в первом столбце повторяющийся IP-адрес, он добавляет значение из второго столбца к общему количеству байтов для этого адреса, суммируя таким образом количество байтов, отправленных этим IP-адресом.
Пример 7.5. summer.sh
declare -A cnt # ассоциативный массивwhile read id count
do let cnt[$id]+=$countdonefor id in "${!cnt[@]}"do printf "%-15s %8d\n" "${id}" "${cnt[${id}]}" # <1>done<1> Обратите внимание, что в формат вывода мы внесли несколько изменений. К размеру поля мы добавили 15 символов для первой строки (данные IP-адреса, в нашем примере), установили выравнивание по левому краю (с помощью знака минус) и указали восемь цифр для значений суммы. Если сумма окажется больше, то будет выведено большее число, если же строка окажется длиннее, то она будет напечатана полностью. Это сделано для того, чтобы выровнять данные по соответствующим столбцам: так столбцы будут аккуратными и более читабельными.
Для получения представления об общем объеме данных, запрашиваемых каждым хостом, можно в сценарии summer. запустить файл access.. Для этого используйте команду cut, которая извлечет IP-адрес и переданные байты полей, а затем передайте вывод в сценарий summer.:
$
192.192.192.192.192.
Эти результаты могут быть полезны для выявления хостов, которые передали необычно большие объемы данных по сравнению с другими хостами. Всплеск может указывать на кражу данных и эксфильтрацию. Когда такой хост будет определен, нужно просмотреть конкретные страницы и файлы, к которым он обращался, чтобы попытаться классифицировать его как вредоносный или безопасный.
Отображение данных в виде гистограммы
Можно выполнить еще одно действие, обеспечив более наглядное отображение полученных результатов. Вы можете взять вывод сценария countem. или summer. и передать его в другой сценарий, который будет создавать гистограмму, отображающую результаты.
Сценарий, выполняющий печать, будет принимать первое поле в качестве индекса ассоциативного массива, а второе поле — в качестве значения для этого элемента массива. Затем следует пересмотреть весь массив и распечатать несколько хештегов для представления самого большого числа в списке (пример 7.6).
Пример 7.6. histogram.sh
function pr_bar () # <1> local -i i raw maxraw scaled # <2> raw=$1 maxraw=$2 ((scaled=(MAXBAR*raw)/maxraw)) # <3> # гарантированный минимальный размер ((raw > 0 && scaled == 0)) && scaled=1 # <4> for((i=0; i<scaled; i++)) ; do printf '#' ; done printf '\n'} # pr_bar## "main"#declare -A RA
declare -i MAXBAR max # <5>max=0
MAXBAR=50 # размер самой длинной строкиwhile read labl val
do let RA[$labl]=$val # <6> # сохранить наибольшее значение; для масштабирования (( val > max )) && max=$valdone# масштабировать и вывестиfor labl in "${!RA[@]}" # <7>do printf '%-20.20s ' "$labl" pr_bar ${RA[$labl]} $max # <8>done<1> Мы определяем функцию, с помощью которой нарисуем один столбец гистограммы. Определение должно находиться перед самой функцией, поэтому имеет смысл поместить все определения функций в начале нашего сценария. Данная функция в будущем сценарии будет использована повторно, поэтому ее можно поместить в отдельный файл и подключать с помощью команды source. Но мы сделали по‑другому.
<2> Мы объявляем все эти переменные локальными, так как не хотим, чтобы они мешали определению имен переменных в остальной части данного сценария (или любых других, если мы копируем/вставляем этот сценарий для использования в другом месте). Мы объявляем все эти переменные целыми числами (это параметр -i), потому что будем вычислять только целые значения и не станем использовать строки.
<3> Вычисление выполняется в двойных скобках. Внутри них не нужно использовать символ $ для указания значения каждого имени переменной.
<4> Это оператор if-less. Если выражение внутри двойных скобок равно true, то тогда и только тогда выполняется второе выражение. Такая конструкция гарантирует, что если исходное значение не равно нулю, то масштабированное значение никогда не будет равно нулю.
<5> Основная часть сценария начинается с объявления RA как ассоциативного массива.
<6> Здесь мы ссылаемся на ассоциативный массив, используя метку строки в качестве его индекса.
<7> Поскольку массив не индексируется по числам, мы не можем просто считать целые числа и использовать их в качестве индексов. Эта конструкция определяет все различные строки, которые использовались в качестве индекса массива, по одному индексу в цикле for.
<8> Мы еще раз используем метку как индекс, чтобы получить счетчик и передать его как первый параметр нашей функции pr_bar.
Обратите внимание, что элементы отображаются не в том порядке, что и входные данные. Это связано с тем, что алгоритм хеширования для ключа (индекса) не сохраняет порядок. Вы можете упорядочить этот вывод или использовать другой подход.
Пример 7.7 представляет собой версию сценария для построения гистограммы — в нем сохраняется последовательность вывода и не используется ассоциативный массив. Это также может быть полезно для старых версий bash (до 4.0), в которых ассоциативный массив еще не использовался. Здесь показана только основная часть сценария, так как функция pr_bar остается прежней.
Пример 7.7. histogram_plain.sh
declare -a RA_key RA_val # <1>declare -i max ndx
max=0
maxbar=50 # размер самой длинной строкиndx=0
while read labl val
do RA_key[$ndx]=$labl # <2> RA_value[$ndx]=$val # сохранить наибольшее значение; для масштабирования (( val > max )) && max=$val let ndx++
done# масштабировать и вывестиfor ((j=0; j<ndx; j++)) # <3>do printf "%-20.20s " ${RA_key[$j]} pr_bar ${RA_value[$j]} $maxdoneЭта версия сценария позволяет избежать использования ассоциативных массивов (например, в более старых версиях bash или в системах macOS). Здесь мы применяем два отдельных массива: один для индексного значения и один — для счетчиков. Поскольку это обычные массивы, мы должны использовать целочисленный индекс и будем вести простой подсчет в переменной ndx.
<1> Здесь имена переменных объявляются как массивы. Строчная a указывает, что они являются массивами, но это не ассоциативные массивы. Это не обязательное требование, зато рекомендуемая практика. Аналогично в следующей строке мы задаем параметр -i для объявления этих переменных целыми числами, что делает их более эффективными, чем необъявленные переменные оболочки (которые хранятся в виде строк). Повторимся: как видно из того, что мы не объявляем maxbar, а просто используем его, это не обязательное требование.
<2> Пары «ключ/значение» хранятся в отдельных массивах, но в одном и том же месте индекса. Это ненадежный подход — изменения в сценарии в какой‑то момент могут привести к тому, что два массива не синхронизируются.
<3> Цикл for, в отличие от предыдущего сценария, используется для простого подсчета целых чисел от 0 до ndx. Здесь переменная j выступает препятствием для индекса в цикле for внутри сценария pr_bar, несмотря на то что внутри функции мы достаточно аккуратно объявляем эту версию i как локальную функцию. Вы доверяете этой функции? Измените здесь j на i и проверьте, работает ли цикл (а он работает). Затем попробуйте удалить локальное объявление и проверить, успешно ли завершится цикл.
Такой подход с двумя массивами имеет одно преимущество. Используя числовой индекс для хранения метки и данных, можно получить их в том порядке, в котором они были прочитаны, — в числовом порядке индекса.
Теперь, извлекая соответствующие поля из access. и перенося результаты в summer., а затем — в histogram., можно наглядно увидеть, какие хосты передали наибольшее количество байтов:
$
192.192.192.192.192.
Хотя данный подход может показаться не столь эффективным для небольшого объема выборочных данных, возможность визуализации имеет неоценимое значение при рассмотрении более крупных наборов данных.
Помимо количества байтов, передаваемых через IP-адрес или хост, часто интересно просмотреть данные, отсортированные по дате и времени. Для этого можно использовать сценарий summer., но из‑за формата файла access., прежде чем передать его в сценарий, его нужно дополнительно обработать. Если для извлечения переданных полей с датой/временем и байтов используется команда cut, остаются данные, которые могут вызвать некоторые проблемы для сценария:
$
[[[
Как видно из этого вывода, необработанные данные начинаются с символа [. Из‑за него в сценарии появляется проблема, так как он обозначает начало массива в bash. Чтобы эту проблему устранить, можно использовать дополнительную итерацию команды cut с параметром -c2, с помощью которого символ будет удален.
Этот параметр указывает команде cut извлекать данные по символам, начиная с позиции 2 и переходя к концу строки (-). Вот исправленный вывод с удаленной квадратной скобкой:
$
12/12/12/
info
Вместо того чтобы второй раз использовать команду cut, можно добавить команду tr. Параметр -d удаляет указанный символ — в данном случае квадратную скобку.
cut -d' ' -f4,10 access.log | tr -d '['
Необходимо также определить способ группирования данных, связанных с датами: по дню, месяцу, году, часу и т. д. Для этого можно просто изменить параметр для второй итерации команды cut. В таблице показаны параметры команды cut, которые используются для извлечения различных форм поля даты/времени. Обратите внимание, что эти параметры предназначены для файлов журнала Apache.
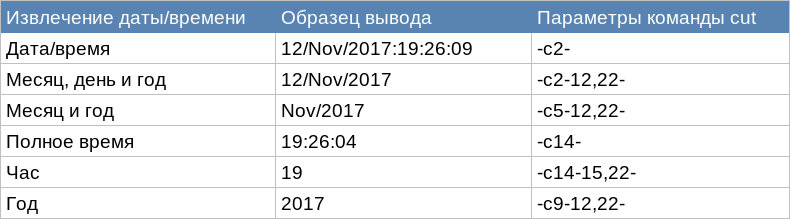
Сценарий histogram. может быть особенно полезен при просмотре данных, связанных с датами. Например, если в организации имеется внутренний веб‑сервер, доступ к которому осуществляется только в рабочее время с 09:00 до 17:00, можно с помощью такой гистограммы ежедневно просматривать файл журнала сервера, чтобы проверить, имеются ли всплески активности после обычного рабочего дня.
Большие всплески активности или передача данных вне обычного рабочего времени может свидетельствовать об эксфильтрации со стороны злоумышленника. При обнаружении каких‑либо аномалий можно отфильтровать данные по конкретной дате и времени и проверять доступ к странице, чтобы определить, является ли действие вредоносным.
Например, если требуется просмотреть гистограмму общего объема данных, полученных в определенный день за каждый час, можно выполнить следующую команду:
$
17 16 15 19 18
Здесь файл access. пересылается с помощью команды awk для извлечения записей с определенной датой. Обратите внимание на использование вместо символов == оператора подобия (~), поскольку поле 4 также содержит информацию о времени. Эти записи передаются команде cut сначала для извлечения полей даты/времени и переданных байтов, а затем для извлечения данных о времени. После этого с помощью сценария summer. данные суммируются по времени (часам) и с помощью histogram. преобразуются в гистограмму. Результатом становится гистограмма, которая отображает общее количество байтов, передаваемых каждый час 12 ноября 2017 года.
info
Чтобы получить вывод в числовом порядке, передайте его из сценария гистограммы команде sort . Зачем нужна сортировка? Сценарии summer. и histogram., просматривая список индексов своих ассоциативных массивов, генерируют свои выходные данные. Поэтому их вывод вряд ли будет осмысленным (скорее данные будут выведены в порядке, определяемом внутренним алгоритмом хеширования). Если это объяснение оставило вас равнодушными, просто проигнорируйте его и не забудьте использовать сортировку на выходе.
Если вы хотите, чтобы вывод был упорядочен по объему данных, добавьте сортировку между двумя сценариями. Необходимо также использовать histogram_plain. — версию сценария гистограммы, в которой не применяются ассоциативные массивы.
Поиск уникальности в данных
Ранее IP-адрес 192.168.0.37 был идентифицирован как система, которая имела наибольшее количество запросов страницы. Следующий логический вопрос: какие страницы запрашивала эта система? Ответив на него, можно получить представление о том, что система делала на сервере, и классифицировать это действие как безопасное, подозрительное или вредоносное. Для этого можно использовать команду awk и cut и передать вывод в countem.:
$
14 /14 /14 /14 /3 /
Хотя извлечение и обрезка данных могут быть реализованы путем конвейерной передачи команд и сценариев, для этого потребуется передавать данные несколько раз. Такой метод можно применить ко многим наборам данных, но он не подходит для очень больших наборов. Метод можно оптимизировать, написав сценарий bash, специально разработанный для извлечения и подсчета количества доступов к страницам, — для этого требуется только один проход данных. В примере 7.8 показан такой сценарий.
Пример 7.8. pagereq.sh
declare -A cnt # <1>while read addr d1 d2 datim gmtoff getr page therest
do if [[ $1 == $addr ]] ; then let cnt[$page]+=1 ; fidonefor id in ${!cnt[@]} # <2>do printf "%8d %s\n" ${cnt[$id]} $iddone<1> Мы объявляем cnt как ассоциативный массив и в качестве индекса можем использовать строку. В данной программе в качестве индекса мы будем использовать адрес страницы (URL).
<2> ${ выводит список всех значений индекса, которые были обнаружены. Обратите внимание: они не будут перечислены в удобном порядке.
В ранних версиях bash ассоциативных массивов нет. Подсчитать количество различных запросов страниц с определенного IP-адреса вы можете с помощью команды awk, потому что в ней есть ассоциативные массивы (пример 7.9).
Пример 7.9. pagereq.awk
# подсчитать количество запросов страниц с адреса ($1)awk -v page="$1" '{ if ($1==page) {cnt[$7]+=1 } } END { for (id in cnt) { # <1> printf "%8d %s\n", cnt[id], id # <2> }}'<1> В этой строке есть две переменные $1, разница между которыми очень большая. Первая переменная $1 является переменной оболочки и ссылается на первый аргумент, предоставленный этому сценарию при его вызове. Вторая переменная $1 — это awk. В каждой строке эта переменная относится к первому полю ввода. Первая переменная $1 была назначена переменной page , чтобы ее можно было сравнить с каждой переменной $1 (с каждым первым полем входных данных).
<2> Простой синтаксис приводит к тому, что переменная id перебирает значения индекса в массиве cnt. Это гораздо более простой синтаксис, чем синтаксис оболочки ${, но такой же эффективный.
Можно запустить сценарий pagereq., указав IP-адрес, который требуется найти и перенаправить access. в качестве входных данных:
$
14 /14 /14 /14 /3 /
Выявление аномалий в данных
В Интернете строка агента пользователя представляет собой небольшой фрагмент текстовой информации, отправляемый браузером на веб‑сервер, который идентифицирует операционную систему клиента, тип браузера, версию и другую информацию. Обычно используется веб‑серверами для обеспечения совместимости страниц с браузером пользователя. Вот пример такой строки:
Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0
Эта строка идентифицирует систему как Windows NT версии 6.3 (она же Windows 8.1) с 64-разрядной архитектурой и с браузером Firefox. Строка агента пользователя может нас заинтересовать по двум причинам. Во‑первых, значительный объем информации, которую эта строка передает, можно применять для идентификации типов систем и браузеров, обращающихся к серверу. Во‑вторых, эта строка настраивается конечным пользователем и может быть использована для идентификации систем, в которых не установлен стандартный браузер или вообще нет браузера (поисковых роботов, web crawler).
Вы можете определить необычные пользовательские агенты, предварительно составив список известных безопасных пользовательских агентов. Для этого упражнения мы используем очень маленький список браузеров, которые не являются специфичными для конкретной версии (пример 7.10).
Пример 7.10. useragents.txt
Firefox
Chrome
Safari
Edge
Затем вы можете прочитать журнал веб‑сервера и сравнить каждую строку со списком популярных пользовательских агентов (браузеров), пока не будет получено совпадение. Если совпадения не будет, строка должна рассматриваться как аномалия и печататься в стандартном выводе вместе с IP-адресом системы, выполняющей запрос. Такое сравнение дает нам дополнительную информацию, связанную с рассматриваемыми данными, — с ее помощью мы сможем идентифицировать систему с необычным пользовательским агентом и получим еще один путь для дальнейшего изучения.
Пример 7.11. useragents.sh
# несовпадение — поиск по массиву известных имен# возвращает 1 (false), если совпадение найдено# возвращает 0 (true), если совпадений нетfunction mismatch () # <1>{ local -i i # <2> for ((i=0; i<$KNSIZE; i++)) do [[ "$1" =~ .*${KNOWN[$i]}.* ]] && return 1 # <3> done return 0
}readarray -t KNOWN < "useragents.txt" # <4>KNSIZE=${#KNOWN[@]} # <5># предварительная обработка лог-файла (stdin),# чтобы выбрать IP-адреса и пользовательские агентыawk -F'"' '{print $1, $6}' | \while read ipaddr dash1 dash2 dtstamp delta useragent # <6>do if mismatch "$useragent" then echo "anomaly: $ipaddr $useragent" fidone<1> Сценарий будет основан на функции несовпадения. Если обнаружится несоответствие, будет возвращено успешное значение (или true). Это значит, что совпадение со списком известных пользовательских агентов не найдено. Данная логика может показаться нестандартной, но так удобнее читать оператор if, содержащий вызов mismatch.
<2> Объявление нашего цикла for в качестве локальной переменной — хорошая идея. Данный шаг в сценарии не является обязательным.
<3> Здесь представлены две строки для сравнения: входные данные из файла журнала и строка из списка известных пользовательских агентов. Для гибкого сравнения используется оператор сравнения регулярных выражений (=~). Значение . (ноль или более вхождений любого символа), размещенное по обе стороны ссылки массива $KNOWN, говорит о том, что совпадение известной строки может быть найдено в любом месте другой строки.
<4> Каждая строка файла добавляется как элемент к указанному имени массива. Это дает нам массив известных пользовательских агентов. В bash существует два способа добавить строки к массиву: использовать либо readarray, как сделано в этом примере, либо mapfile. Опция -t удаляет завершающий символ новой строки из каждой прочитанной строки. Здесь указан файл, содержащий список известных пользовательских агентов; при необходимости его можно изменить.
<5> Здесь вычисляется размер массива. Полученное значение используется внутри функции mismatch для циклического перебора массива. Вне нашего цикла мы вычисляем его один раз, чтобы при каждом вызове функции избежать повторного вычисления.
<6> Входная строка представляет собой сложное сочетание слов и кавычек. Чтобы захватить строку агента пользователя, в качестве разделителя полей мы указываем двойные кавычки. Однако это означает, что наше первое поле содержит больше чем просто IP-адрес. Используя команду read для получения IP-адреса, мы можем проанализировать пробелы. Последний аргумент read принимает все оставшиеся слова, чтобы можно было захватить все слова строки пользовательского агента.
При запуске сценария useragents. будут выведены любые строки пользовательского агента, не найденные в файле useragents.:
$
anomaly: anomaly: anomaly: anomaly: ..anomaly:
Выводы
В этой главе мы рассмотрели методы статистического анализа для выявления необычной и аномальной активности в файлах журналов. Такой анализ даст вам представление о том, что происходило ранее. В следующей главе мы рассмотрим, как анализировать файлы журналов и другие данные, чтобы понять, что происходит в системе в режиме реального времени.
