

Когда-то Линус Торвальдс назвал ядро Linux результатом эволюции, а не инженерии и проектирования, объяснив таким образом серьезную запутанность кода и мешанину из применяемых технологий. Тем не менее Linux держится на нескольких ключевых механизмах и подсистемах, которые как раз и делают его уникальным. Эта статья — экскурс в историю таких подсистем, анализ причин их появления и их значение в успехе Linux.
Ext2, ext3, ext4
В первых версиях ядра Linux использовалась 16-битная файловая система Minix, разработанная Эндрю Таненбаумом как простой и наглядный пример ФС для студентов. Ее максимальный размер составлял 64 Мб, а длина имени файла не могла превышать 14 символов. Вскоре для ее замены была разработана файловая система ext (extended — расширенная), которая подняла ограничение на размер ФС до 2 Гб, а длину имен файлов — до 255 символов. Фактически ext была всего лишь продвинутым вариантом ФС Minix, в которой отсутствовала даже такая простая вещь, как поддержка дат модификации файлов, поэтому она долго не прожила и была заменена на ext2.
Новая ФС была создана с нуля на основе идей оригинальной UFS из UNIX и унаследовала почти все преимущества последней. Общий размер файловой системы мог составлять 4 Тб с возможностью выбора размера блока для подгонки производительности под определенные задачи. Благодаря продуманному дизайну, ext2 можно было с легкостью усовершенствовать, и вскоре для нее появились реализации ACL и расширенных атрибутов файлов. На последнем этапе разработки драйвер ext2 оптимизировали, и она стала самой быстрой файловой системой среди открытых никсов.

Ext2 получилась настолько удачной, что долгое время о ее замене и не задумывались. Единственным ограничением было отсутствие журналирования, что благополучно исправила компания Red Hat, создав ext3, доработанный вариант ext2, — нового в нем было только наличие журнала, а также твики производительности и небольшие доработки. Во всем остальном ext3 оставалась ext2, и ее можно было подключить с помощью драйвера последней (потеряв журналирование) или преобразовать ext2 в ext3, просто задействовав журнал с помощью утилиты tune2fs.
С развитием файловых систем стало ясно, что технологии ext3 уже не могут обеспечить достаточную производительность и функциональность в сравнении с конкурентами, и началась разработка ext4. Задачи сохранения обратной совместимости на этот раз не стояло, поэтому разработчики смогли развернуться по полной, применив при разработке ФС самые передовые техники оптимизации.
Наиболее значительным усовершенствованием ФС стала идея так называемых экстентов. Они используются для представления непрерывных участков блоков файловой системы, закрепленных за файлом. В ext3 с этой целью использовалась классическая идея карт соответствия, то есть списков блоков, по которому драйверу ФС нужно было проходить каждый раз при чтении и записи файлов, что снижало производительность. Экстенты позволяют адресовать непрерывные последовательности блоков, а потому вместо карты соответствия файла из тысяч записей ext4 может использовать всего несколько экстентов, что существенно поднимает производительность ФС.
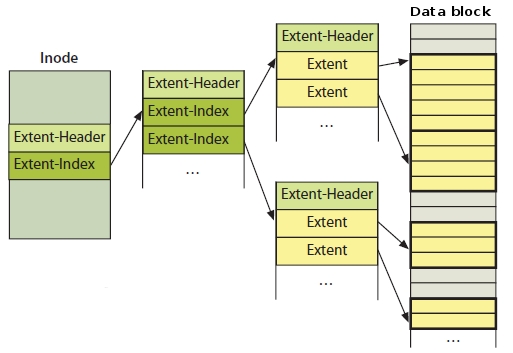
Таким же образом хранится информация о свободных блоках ФС. Вместо таблиц адресов блоков теперь применяются те же экстенты, что увеличивает скорость распределения блоков при создании или модификации файлов. Сам механизм выделения блоков был переработан. Теперь операция выделения происходит не сразу при создании файла, а откладывается вплоть до момента сброса его содержимого на диск. Как результат, процесс создания и модификации файлов теперь происходит очень быстро.
Кроме того, было добавлено и большое количество других оптимизаций и улучшений, таких как 48-битная адресация, позволившая расширить размер ФС до одного эксбибайта, размещение расширенных атрибутов прямо в inode для увеличения скорости доступа к ним, резервирование inode для возможных файлов при создании каталога, технология предварительного распределения блоков для файлов для таких приложений, как торрент-клиенты, контрольные суммы журнала и многое другое. Особо стоит отметить поддержку онлайн-дефрагментации файловой системы, которая позволяет сохранить высокую производительность, не отключая ФС и не производя дефрагментацию вручную.
Предварительная версия ext4 появилась в ядре Linux 2.6.19, допиливание файловой системы продолжалось больше года, и с выходом ядра версии 2.6.28 ext4 стала стабильной и рекомендованной для повсеместного тестирования. Сегодня ext4 — это стандарт в мире Linux и наиболее производительная журналируемая файловая система.
Btrfs
Как бы хороша ни была еxt4, ее узкие места отлично понимают и прямо говорят, что она лишь переходный этап к файловым системам будущего, которые будут иметь концептуально иной дизайн и возможности. Наиболее близкий кандидат в такие ФС — это Btrfs, разрабатываемая под руководством компании Oracle в качестве альтернативы ZFS (разработка была начата еще до приобретения компании Sun, владеющей правами на ZFS).
Три основные изюминки этой ОС — отличная масштабируемость, плотная интеграция с менеджером томов и расширяемость. Как и еxt4, Btrfs базируется на идее экстентов, которая позволяет сделать управление данными эффективным даже для очень больших объемов данных и размеров файлов. Выделение inode в файловой системе происходит в полностью динамическом режиме, что снимает ограничение на общий объем файлов. Мелкие файлы могут быть размещены прямо в inode, так же как это сделано в Reizer4, поэтому производительность работы ФС с большим количеством небольших файлов остается очень высокой.
Как и в ZFS, размещение файлов производится по принципу copy-on-write (COW), а это означает, что файл никогда не перезаписывается, вместо этого при его модификации происходит выделение новых блоков данных для хранения измененных частей. Такой подход позволяет сделать процесс модификации файлов более эффективным, идеально подходит для SSD-накопителей с их ограниченным количеством циклов перезаписи, а также делает возможной такую технологию, как снапшоты, когда пользователь в любой момент может откатиться к предыдущей версии файловой системы или отдельных файлов.
Для гарантии целостности файловая система использует хеши данных и метаданных. Файловая система может иметь несколько корней (подтомов), благодаря чему одну файловую систему можно использовать для размещения нескольких виртуальных окружений или сэндбоксов. Уже реализован механизм прозрачной компрессии данных с помощью алгоритмов lzo и zlib, который позволяет сэкономить дисковое пространство и при этом поднять производительность ФС (распаковка данных происходит быстрее их чтения с диска). Реализована система онлайн-дефрагментации, а также динамического расширения и сжатия ФС по необходимости.
Чтобы сделать работу файловой системы поверх RAID-массивов более эффективной и повысить надежность, разработчики тесно интегрировали Btrfs с подсистемой управления томами Device Mapper. Такой дизайн позволяет консолидировать работу файловой системы и подсистемы RAID, в результате чего возрастает как производительность, так и надежность массива. Файловая система знает об используемой RAID-схеме, текущем состоянии дисков и балансирует нагрузку в зависимости от условий (например, наиболее используемые файлы будут автоматически перемещены на более производительный диск). Сбой в работе RAID-массива позволяет вовремя остановить операции ввода-вывода и восстановить свою работу, дождавшись переконфигурирования. В совокупности с контрольными суммами, которые файловая система хранит для каждого блока, RAID-массив на основе Btrfs становится крайне надежным.
На текущий момент Btrfs уже достаточно стабильна для повседневного применения и в некоторых тестах производительности обгоняет еxt4. Она использовалась в качестве основной ФС в мобильной платформе MeeGo и доступна для использования по умолчанию во многих дистрибутивах.

Sysfs
Работая над ядром экспериментальной ветки 2.5.X и реализуя новую подсистему управления драйверами устройств, разработчики решили оснастить ядро новым интерфейсом отладки, реализованным в виде виртуальной файловой системы. Интерфейс получил имя ddfs (Driver Debug Filesystem) и позволял получать различную информацию об устройствах, состоянии драйверов и другие низкоуровневые данные.
К моменту релиза ядра 2.6 оказалось, что ddfs может быть полезна и для многих других приложений, работающих с железом, поэтому ФС было решено переименовать в sysfs (System Filesystem) и включить в будущий релиз. Это событие повлекло за собой целый ряд изменений в подходе к построению окружения Linux. Вся «железная» информация теперь хранилась централизованно и всегда в актуальном состоянии, что позволило проектам вроде KDE и GNOME реализовать действительно умное управление оборудованием. Интерфейсы управления железом также начали перекочевывать в sysfs, разгружая и без того запутанную procfs. И наконец, sysfs позволила выпилить из ядра файловую систему devfs, отвечающую за динамическое создание файлов-устройств, и заменить ее на легковесный и гибкий в управлении демон udev, полностью руководствующийся информацией из sysfs.
Сегодня ядро Linux без sysfs представить невозможно. Файловая система используется огромным количеством утилит, демонов и систем умного управления энергосбережением. Она занимает центральное место в подсистеме управления оборудованием Android и других мобильных систем, основанных на ядре Linux. С помощью sysfs можно разгонять процессор, управлять яркостью дисплея, настройками жестких дисков и планировщиков.
FUSE
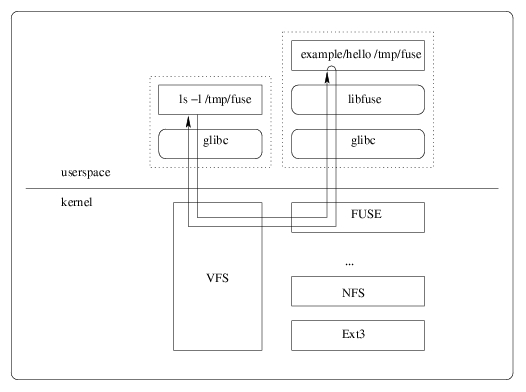
С самого момента своего появления ядро Linux критиковалось за монолитный дизайн, снижающий надежность ОС, затрудняющий разработку и тестирование драйверов и не обладающий достаточной гибкостью. Линус Торвальдс никогда не воспринимал всерьез подобную критику, однако добавил-таки в ядро версии 2.6.14 интерфейс FUSE, позволяющий выносить файловые системы из ядра, реализуя их в виде обычных приложений.
FUSE представляет собой небольшой модуль ядра, посредством обращения к которому (через сокет) любое приложение может реализовать собственную файловую систему или файловый интерфейс к любым другим сущностям. С помощью FUSE были созданы приложения, позволяющие подключать в виде файловых систем tar-архивы, FTP-, SMB- и WebDAV-ресурсы, специальные шифрующие файловые системы и многое, многое другое.
Наиболее известный представитель ФС на основе FUSE — драйвер NTFS-3G, позволяющий подключать NTFS на чтение и запись, но реализованный полностью в пространстве пользователя. С помощью FUSE также разработаны многие серьезные файловые системы, такие как, например, кластерная файловая система GlusterFS, используемая в крупных компаниях для хранения данных в облаке, а также многие другие, ссылки на которые можно найти на официальном сайте FUSE.
FUSE часто используется для прототипирования и отладки файловых систем, планируемых к реализации внутри ядра, а создать свою ФС с ее помощью настолько просто, что это можно сделать за полчаса, не обладая никакими специальными знаниями.
Cgroups и пространства имен
Как и в любой другой UNIX-подобной операционной системе, в Linux всегда существовало несколько механизмов контроля процессов и их ресурсов. Это значения приоритета (nice) и лимитирование ресурсов с помощью системного/библиотечного вызова ulimit. Эти интерфейсы не могли предоставить возможности гибкого управления ресурсами, поэтому компания Google приступила к разработке технологии, изначально получившей имя process containers, а затем переименованной в Cgroups (Control Groups).
Cgroups — это официально включенный в ядро 2.6.24 фреймворк группировки процессов и управления их ресурсами, такими как количество оперативной памяти, процессорные ресурсы, приоритеты ввода-вывода и доступа к сети. Технология Cgroups тесно связана с системой управления пространствами имен, которая позволяет поместить выбранную группу процессов в независимое от основной системы окружение, которое может иметь собственный корень файловой системы, собственный список процессов, сетевой стек и систему межпроцессного взаимодействия.
В сочетании эти две технологии позволяют создать полностью виртуализированное окружение для группы процессов, чем с успехом пользуются системы виртуализации OpenVZ и LXC для запуска «Linux внутри Linux». Также с помощью Cgroups можно легко выполнить довольно сложные задачи, вроде ограничения всех малозначимых фоновых демонов в процессоре, безопасный запуск подозрительных приложений, многопользовательское окружение с полным отделением юзеров друг от друга (как сделано в Ubuntu Touch), назначение всем интерактивным процессам более высокого приоритета (такой подход применяется в текущих версиях Linux) и многое другое.
CFS
За все время существования Linux сменил множество различных алгоритмов планирования процессов, от самых простых и примитивных до алгоритмов, способных предугадывать будущие потребности процессов в ресурсах процессора и равномерно распределять время между всеми процессами. Однако наиболее значимым стал переход к использованию планировщика CFS, который позволил вплотную приблизить работу системы к идеалу.
CFS (Completely Fair Scheduler) был разработан Инго Молнаром под впечатлением от планировщика Rotating Staircase Deadline за авторством непризнанного Linux-хакера Кона Коливаса, известного своим нестандартным подходом к реализации внутриядерных механизмов. CFS отличается простотой, отсутствием какой-либо эвристики и удивительной способностью к правильной балансировке нагрузки. В системе с CFS можно спокойно запустить компиляцию в несколько потоков, форк-бомбу, фильм и при этом спокойно сидеть в интернете, практически не замечая каких-либо притормаживаний. Нагрузка будет распределена полностью равномерно.
Достигается это за счет простого алгоритма распределения времени, в котором процессы встают в очередь в том порядке, в котором они использовали время процессора в предыдущий раз. Наименее жадные получают процессор первыми, наиболее жадные — последними. Поэтому, например, компилятор и форк-бомба будут находиться ближе к концу в очереди, а интерактивные процессы, которые большую часть времени простаивают, ожидая ввода пользователя или данных с диска, — к началу, что является разумным, но полностью автоматизированным разделением времени.
CFS был включен в ядро, начиная с версии 2.6.23, и, вероятнее всего, еще не скоро покинет его (если это вообще случится). Разработчики FreeBSD портировали его в свою систему, но, к сожалению, забросили разработку в пользу собственного планировщика ULE.
KVM
К началу бума виртуализации в мире Linux уже существовал инструмент, позволяющий превратить пингвина в полноценную платформу для запуска виртуальных машин. Это Xen, который появился еще до начала продаж процессоров с поддержкой аппаратной виртуализации и позволяющий запускать (модифицированные) гостевые окружения на скорости, близкой к нативной. Однако с появлением технологий аппаратной виртуализации Intel VT и AMD SVM стало ясно, что Xen, будучи оправданным решением в мире паравиртуализации, в новых условиях оказывается решением избыточным, требуя использовать специальное ядро и инструменты даже в том случае, если предполагается аппаратная виртуализация.
Решением проблемы стал KVM (Kernel-based Virtual Machine), небольшой модуль Linux-ядра, позволяющий получить все возможности аппаратной виртуализации без необходимости наложения патчей, установки специального ядра и тому подобных извращений. Достаточно загрузить модуль, установить специальную версию эмулятора QEMU — и можно начинать запуск виртуальных окружений, работающих со скоростью 99% от нативных.
Козырь KVM в предельной простоте. Это всего лишь небольшой драйвер для подсистем Intel VT и AMD SVM, который, в отличие от того же Xen, не затрагивает никаких базовых структур ядра и не требует использования специальных драйверов в виртуальных окружениях. Вся сложная работа выполняется в пространстве пользователя силами того самого QEMU, тогда как KVM играет роль интерфейса для настройки адресного пространства гостя виртуальной машины.
По этой причине код KVM был очень быстро принят в ядро Linux 2.6.20, а компания Qumranet, ответственная за его разработку, куплена Red Hat. Сегодня KVM — это стандарт в мире Linux-виртуализации. Он используется во многих облачных платформах и фреймворках. В виртуальных окружениях, созданных KVM, работают миллионы серверов. Он является базовой частью всех облачных решений таких компаний, как Red Hat, Ubuntu, SUSE и многих других.
Даты выхода файловых систем
- 1987 — Minix FS (0.01)
- 1992 — ext (0.96c)
- 1993 — ext2 (0.99.15)
- 2001 — ReiserFS (2.4.1)
- 2001 — ext3 (2.4.15)
- 2006 — ext4 (2.6.28, 2.6.19)
- 2009 — Btrfs (2.6.29)
В скобках указано первое появление ФС в ядре Linux.
Выводы
Linux развивается стремительными темпами, серьезно обновляясь до шести-семи раз в год. Однако по-настоящему фундаментальные технологии появляются в нем не так часто. В статье мы рассмотрели наиболее важные из этих технологий, что совсем не значит, будто на этом их список заканчивается. За более чем 20 лет существования ядра в Linux появилось и исчезло огромное количество технологий, для описания которых пришлось бы расширить статью до полноценной книги.







