
Несколько лет назад оказалось, что SQL внезапно устарел. И начали появляться и множиться NoSQL-решения, отбросившие язык SQL и реляционную модель хранения данных. Основные аргументы в поддержку такого подхода: возможность работы с большими данными (те самые Big Data), хранения данных в самых экзотичных структурах и, самое главное, возможность все это делать очень быстро. Давай посмотрим, насколько это получается у самых популярных представителей мира NoSQL.
За счет чего достигается скорость в NoSQL? В первую очередь, это следствие совсем другой парадигмы хранения данных. Парсинг и трансляция SQL-запросов, работа оптимизатора, объединение таблиц и прочее сильно увеличивают время ответа. Если взять и выкинуть все эти слои, упростить запросы, читать с диска прямо в сеть или хранить все данные в оперативной памяти, то можно выиграть в скорости. Уменьшается как время обработки каждого запроса, так и количество запросов в секунду. Так появились key-value БД, самым типичным и широко известным представителем которых является memcached. Да, этот кеш, широко применяемый в веб-приложениях для ускорения доступа к данным, тоже является NoSQL.
Типы NoSQL
Можно выделить четыре основные категории NoSQL-систем:
- Ключ — значение (key-value). Большая хеш-таблица, где допустимы только операции записи и чтения данных по ключу.
- Колоночные (column). Таблицы, со строками и колонками. Вот только в отличие от SQL количество колонок от строки к строке может быть переменным, а общее число колонок может измеряться миллиардами. Также каждая строка имеет уникальный ключ. Можно рассматривать такую структуру данных как хеш-таблицу хеш-таблицы, первым ключом является ключ строки, вторым — имя колонки. При поддержке вторичных индексов возможны выборки по значению в колонке, а не только по ключу строки.
- Документо-ориентированные (document-oriented). Коллекции структурированных документов. Возможна выборка по различным полям документа, а также модификация частей документа. К этой же категории можно отнести поисковые движки, которые являются индексами, но, как правило, не хранят сами документы.
- Графовые (graph). Специально предназначены для хранения математических графов: узлов и связей между ними. Как правило, позволяют задавать для узлов и связей еще и набор произвольных атрибутов и выбирать узлы и связи по этим атрибутам. Поддерживают алгоритмы обхода графов и построения маршрутов.
Для теста мы взяли представителей первых трех категорий:
- Aerospike (в девичестве Citrusleaf). Очень быстрая key-value БД (а с версии 3.0 — еще и частично документо-ориентированная). В явном виде поддерживает SSD, использует их напрямую, без файловой системы, как блочные устройства. Создавалась для рынка онлайн-рекламы (в том числе для так называемого RTB — Real Time Bidding), где требуются быстрые и большие кеши данных.
- Couchbase. Возник как симбиоз проектов CouchDB и Membase и является, таким образом, последователем memcached, то есть key-value БД (хотя опять-таки с версии 2.0 появилась поддержка JSON объектов-документов). От memcached в нем остались совместимость на уровне протокола доступа и стремление все хранить в ОЗУ. Отличается от memcached персистентностью и кластерностью, эти новые фичи написаны на Erlang.
- Cassandra. Старейшая СУБД в списке. Возникла в недрах Facebook и была отпущена под крылышко Apache в 2008 году. Является колоночно-ориентированной БД, идейным наследником Google BigTable.
- MongoDB. Весьма известная документо-ориентированная БД. Пожалуй, родоначальник жанра документо-ориентированных NoSQL БД. Документы представляют собой JSON (точнее, BSON) объекты. Создавалась для нужд веб-приложений.
Как проводился тест
В распоряжении у нас было четыре серверных машинки. В каждой: восьмиядерный Xeon, 32 Гб ОЗУ, четыре интеловских SSD по 120 Гб каждый.
Тестировали мы с помощью YCSB (Yahoo! Cloud Serving Benchmark). Это специальный бенчмарк, выпущенный командой Yahoo! Research в 2010 году под лицензией Apache. Бенчмарк специально создан для тестирования NoSQL баз данных. И сейчас он остается единственным и довольно популярным бенчмарком для NoSQL, фактически стандартом. Написан, кстати, на Java. Мы добавили к оригинальному YCSB драйвер для Aerospike, слегка обновили драйвер для MongoDB, а также несколько подшаманили с выводом результатов.
INFO
Кроме YCSB, тестировать производительность NoSQL БД можно с помощью, например, JMeter.
Для создания нагрузки на наш маленький кластер потребовалось восемь клиентских машин. По четырехъядерному i5 и 4 Гб ОЗУ на каждой. Одного (и двух, и трех, и четырех...) клиентов оказалось недостаточно, чтобы загрузить кластер. Может показаться странным, но факт.
Все это шевелилось в одной гигабитной локальной сети. Пожалуй, было бы интереснее в десятигигабитной сети, но такого железа у нас не было. Интереснее, потому что, когда количество операций в секунду начинает измеряться сотнями тысяч, мы утыкаемся в сеть. При пропускной способности в гигабит в секунду (10^9 бит/c) сеть может пропустить килобайтных пакетов (~10^4 бит) лишь около 100 000 (10^5) штук. То есть получаем лишь 100k операций в секунду. А нам вообще-то хотелось получить миллион :).
Сетевые карты тоже имеют значение. Правильные серверные сетевухи имеют несколько каналов ввода-вывода, соответственно, каждый с собственным прерыванием. Вот только по умолчанию в линуксе все эти прерывания назначены на одно ядро процессора. Только ребята из Aerospike озаботились этой тонкостью, и их скрипты настройки БД раскидывают прерывания сетевых карт по ядрам процессора. Посмотреть прерывания сетевых карт и то, как они распределены по ядрам процессора, можно, например, такой командой: «cat /proc/interrupts | grep eth».
Отдельно стоит поговорить про SSD. Мы хотели протестировать работу NoSQL БД именно на твердотельных накопителях, чтобы понять, действительно ли эти диски того стоят, то есть дают хорошую производительность. Поэтому старались настроить SSD правильно. Подробнее об этом можно прочитать на врезке.
Настраиваем SSD
В частности, SSD требуют действий, называемых непереводимым словом overprovisioning. Дело в том, что в SSD присутствует слой трансляции адресов. Адреса блоков, видные операционной системе, совсем не соответствуют физическим блокам во флеш-памяти. Как ты знаешь, число циклов перезаписи у флеш-памяти ограничено. К тому же операция записи состоит из двух этапов: стирания (часто — сразу нескольких блоков) и собственно записи. Поэтому, для обеспечения долговечности накопителя (равномерного износа) и хорошей скорости записи, контроллер диска чередует физические блоки памяти при записи. Когда операционная система пишет блок по какому-то адресу, физически запись происходит на некий чистый свободный блок памяти, а старый блок помечается как доступный для последующего (фонового) стирания. Для всех этих манипуляций контроллеру диска нужны свободные блоки, чем больше, тем лучше. Заполненный на 100% SSD может работать весьма медленно.
Свободные блоки могут получиться несколькими способами. Можно с помощью команды hdparm (с ключом '-N') указать количество секторов диска, видимых операционной системой. Остальное будет в полном распоряжении контроллера. Однако это работает не на всяком железе (в AWS EC2, например, не работает). Другой способ — оставить не занятое разделами место на диске (имеются в виду разделы, создаваемые, например, fdisk). Контроллер достаточно умен, чтобы задействовать это место. Третий способ — использовать файловые системы и версии ядра, которые умеют сообщать контроллеру о свободных блоках. Это та самая команда TRIM. На нашем железе хватило hdparm, мы отдали на растерзание контроллеру 20% от общего объема дисков.
Для SSD важен также планировщик ввода-вывода. Это такая подсистема ядра, которая группирует и переупорядочивает операции ввода-вывода (в основном записи на диск) с целью повысить эффективность. По умолчанию линукс использует CFQ (Completely Fair Queuing), который старается переставить операции записи так, чтобы записать как можно больше блоков последовательно. Это хорошо для обычных вращающихся (так и говорят — spinning :)) дисков, потому что для них скорость линейного доступа заметно выше доступа к случайным блокам (головки нужно перемещать). Но для SSD линейная и случайная запись — одинаково эффективны (теоретически), и работа CFQ только вносит лишние задержки. Поэтому для SSD-дисков нужно включать другие планировщики, например NOOP, который просто выполняет команды ввода-вывода в том порядке, в каком они поступили. Переключить планировщик можно, например, такой командой: «echo noop > /sys/block/sda/queue/scheduler», где sda — твой диск. Справедливости ради стоит упомянуть, что свежие ядра сами умеют определять SSD-накопители и включать для них правильный планировщик.
Любая СУБД любит интенсивно писать на диск, а также интенсивно читать. А Linux очень любит делать read-ahead, упреждающее чтение данных, — в надежде, что, раз ты прочитал этот блок, ты захочешь прочитать и несколько следующих. Однако с СУБД, и особенно при случайном чтении (а этот как раз наш вариант), этим надеждам не суждено сбыться. В результате имеем никому не нужное чтение и использование памяти. Разработчики MongoDB рекомендуют по возможности уменьшить значение read-ahead. Сделать это можно командой «blockdev --setra 8 /dev/sda», где sda — твой диск.
Любая СУБД любит открывать много-много файлов. Поэтому необходимо заметно увеличить лимиты nofile (количество доступных файловых дескрипторов для пользователя) в файле /etc/security/limits.conf на значение сильно больше 4k.
Также возник интересный вопрос: как использовать четыре SSD? Если Aerospike просто подключает их как хранилища и как-то самостоятельно чередует доступ к дискам, то другие БД подразумевают, что у них есть лишь один каталог с данными. (В некоторых случаях можно указать и несколько каталогов, но это не предполагает чередования данных между ними.) Пришлось создавать RAID 0 (с чередованием) с помощью утилиты mdadm. Я полагаю, что можно было бы поиграть с LVM, но производители СУБД описывают только использование mdadm.
Естественно, на всех машинах кластера (как серверных, так и клиентских) часы должны быть синхронизированы с помощью ntpd. Ntpdate тут не годится, потому что требуется бóльшая точность синхронизации. Для всех распределенных систем жизненно важно, чтобы время между узлами было синхронизировано. Например, Cassandra и Aerospike хранят время изменения записи. И если на разных узлах кластера найдутся записи с разным таймстампом, то победит та запись, которая новее.
Сами NoSQL БД настраивались следующим образом. Бралась конфигурация из коробки, и применялись все рекомендации, описанные в документации и касающиеся достижения наибольшей производительности. В сложных случаях мы связывались с разработчиками БД. Чаще всего рекомендации касались подстроек под количество ядер и объем ОЗУ.
Проще всего настраивается Couchbase. У него есть веб-консоль. Достаточно запустить сервис на всех узлах кластера. Затем на одном из узлов создать bucket («корзину» для ключей-значений) и добавить другие узлы в кластер. Все через веб-интерфейс. Особо хитрых параметров настройки у него нет.
Aerospike и Cassandra настраиваются примерно одинаково. На каждом узле кластера нужно создать конфигурационный файл. Эти файлы почти идентичны для каждого узла. Затем запустить демонов. Если все хорошо, узлы сами соединятся в кластер. Нужно довольно хорошо разбираться в опциях конфигурационного файла. Тут очень важна хорошая документация.
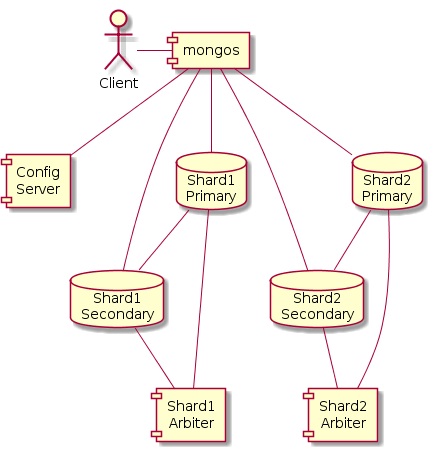
Сложнее всего с MongoDB. У других БД все узлы равнозначны. У Mongo это не так. Мы хотели поставить все БД по возможности в одинаковые условия и выставить у всех replication factor в 2. Это означает, что в кластере должно быть две копии данных, для надежности и скорости. В других БД replication factor — это лишь настройка хранилища данных (или «корзины», или «семейства колонок»). В MongoDB количество копий данных определяется структурой кластера. Грамотно настроить кластер MongoDB можно, только дважды прочтя официальную документацию, посвященную этому :). Говоря кратко, нам нужны shards or replica-sets. Шарды (ну ты наверняка слышал термин «шардинг») — это подмножества всего набора данных, а также узлы кластера, где каждое подмножество будет хранится. Реплика-сеты — это термин MongoDB, обозначающий набор узлов кластера, хранящих одинаковые копии данных. В реплика-сете есть главный узел, который выполняет операции записи, и вторичные узлы, на которые осуществляется репликация данных с главного узла. В случае сбоев роль главного узла может быть перенесена на другой узел реплика-сета. Для нашего случая (четыре сервера и желание хранить две копии данных) получается, что нам нужно два шарда, каждый из которых представляет собой реплика-сет из двух серверов с данными. Кроме того, в каждый реплика-сет нужно добавить так называемый арбитр, который не хранит данные, а нужен для участия в выборах нового главного узла. Число узлов в реплика-сете для правильных выборов должно быть нечетным. Еще нужна маленькая конфигурационная БД, в которой будет храниться информация о шардах и о том, какие диапазоны данных на каком шарде хранятся. Технически это тоже MongoDB, только (по сравнению с основными данными) очень маленькая. Арбитры и конфигурационную БД мы разместили на клиентских машинах. И еще на каждом клиенте нужно запустить демон mongos (mongo switch), который будет обращаться к конфигурационной БД и маршрутизировать запросы от каждого клиента между шардами.

Хакер #180. 2014: люди, вирусы, баги, релизы
У каждой NoSQL БД свой уникальный способ представления данных и допустимых операций над ними. Поэтому YCSB пошел по пути максимального обобщения любых БД (включая и SQL).
Набор данных, которыми оперирует YCSB, — это ключ и значение. Ключ — это строка, в которую входит 64-битный хеш. Таким образом, сам YCSB, зная общее количество записей в БД, обращается к ним по целочисленному индексу, а для БД множество ключей выглядит вполне случайным. Значение — десяток полей случайных бинарных данных. По умолчанию YCSB генерирует записи килобайтного размера, но, как ты помнишь, в гигабитной сети это ограничивает нас лишь в 100k операций в секунду. Поэтому в тестах мы уменьшили размер одной записи до 100 байт.
Операции над этими данными YCSB осуществляет тоже простейшие: вставка новой записи с ключом и случайными данными, чтение записи по ключу, обновление записи по ключу. Никаких объединений таблиц (да и вообще подразумевается лишь одна «таблица»). Никаких выборок по вторичным ключам. Никаких множественных выборок по условию (единственная проверка — совпадение первичного ключа). Это очень примитивно, но зато может быть произведено в любой БД.
Непосредственно перед тестированием БД нужно наполнить данными. Делается это самим YCSB. По сути, это нагрузка, состоящая лишь из операций вставки. Мы экспериментировали с двумя наборами данных. Первый гарантированно помещается в оперативную память узлов кластера, 50 миллионов записей, примерно 5 Гб чистых данных. Второй гарантированно не помещается в ОЗУ, 500 миллионов записей, примерно 50 Гб чистых данных.
Сам тест — выполнение определенного набора операций — производится под нагрузкой разного типа. Важным параметром является соотношение операций — сколько должно быть чтений, а сколько обновлений. Мы использовали два типа: интенсивная запись (Heavy Write, 50% чтений и 50% обновлений) и в основном чтение (Mostly Read, 95% чтений и 5% обновлений). Какую операцию выполнить, каждый раз выбирается случайно, проценты определяют вероятность выбора операции.
YCSB может использовать различные алгоритмы выбора записи (ключа) для выполнения операции. Это может быть равномерное распределение (любой ключ из всего множества данных может быть выбран с одинаковой вероятностью), экспоненциальное распределение (ключи «в начале» набора данных будут выбираться значительно чаще) и некоторые другие. Но типичным распределением команда Yahoo выбрала так называемое zipfian. Это равномерное распределение, в котором, однако, отдельные ключи (небольшой процент от общего количества ключей) выбираются значительно чаще, чем другие. Это симулирует популярные записи, скажем в блогах.
YCSB стартует с несколькими потоками, запуская цикл выполнения операций в каждом из них, и все это на одной машине. Имея лишь четыре ядра на одной клиентской машине, довольно грустно пытаться запускать там более четырех потоков. Поэтому мы запускали YCSB на восьми клиентских машинах одновременно. Для автоматизации запуска мы использовали fabric и cron (точнее, at). Небольшой скрипт на Python формирует необходимые для запуска YCSB команды на каждом клиенте, эти команды помещаются в очередь at на одно и то же время на ближайшую минуту в будущем на каждом клиенте. Потом срабатывает at, и YCSB успешно (или не очень, если ошиблись в параметрах) запускается в одно и то же время на всех восьми клиентах. Чтобы собрать результаты (лог файлы YCSB), снова используется fabric.
Результаты
Итак, исходные результаты — это логи YCSB, с каждого клиента. Выглядят эти логи примерно так (показан финальный кусочек файла):
[READ], Operations, 1187363
[READ], Retries, 0
[READ], AverageLatency(us), 3876.5493619053314
[READ], MinLatency(us), 162
[READ], MaxLatency(us), 278190
[READ], 95thPercentileLatency(ms), 12
[READ], 99thPercentileLatency(ms), 22
[READ], Return=0, 1187363
[OVERALL], Reconnections, 0.0
[OVERALL], RunTime(ms), 303574.0
[OVERALL], Operations, 1249984.0
[OVERALL], Throughput(ops/sec), 4117.5594747903315
Как видишь, здесь есть количество операций определенного типа (в данном примере — чтения), средняя, минимальная и максимальная задержки, задержка, в которую уложились 95 и 99% операций, количество успешных операций (код возврата 0), общее время теста, общее количество всех операций и среднее количество операций в секунду. Нас больше всего интересует средняя задержка (AverageLatency) и количество операций в секунду (Throughput).
С помощью очередного скрипта на Python данные из кучи логов собирали в табличку, а по табличке строили красивые графики.
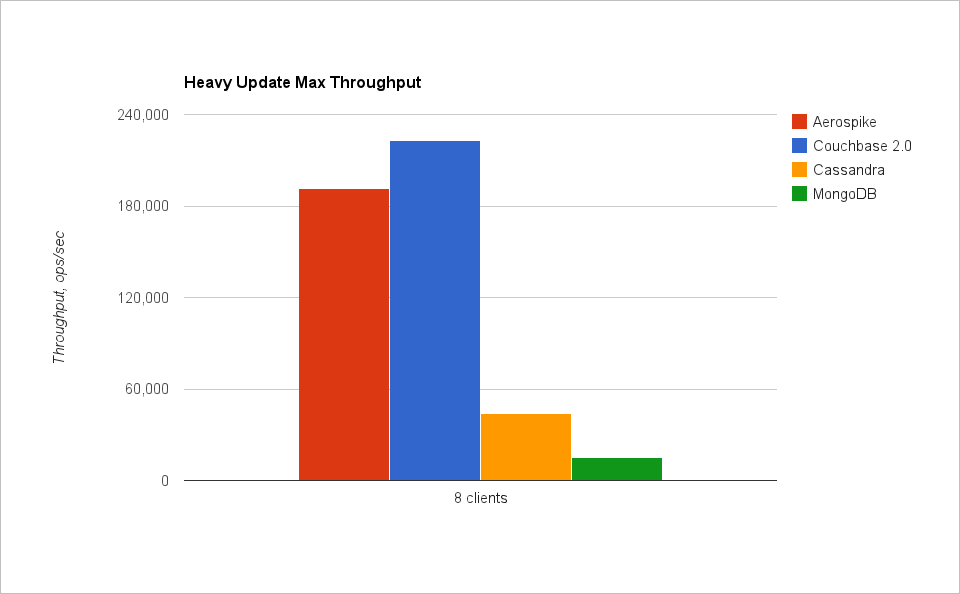
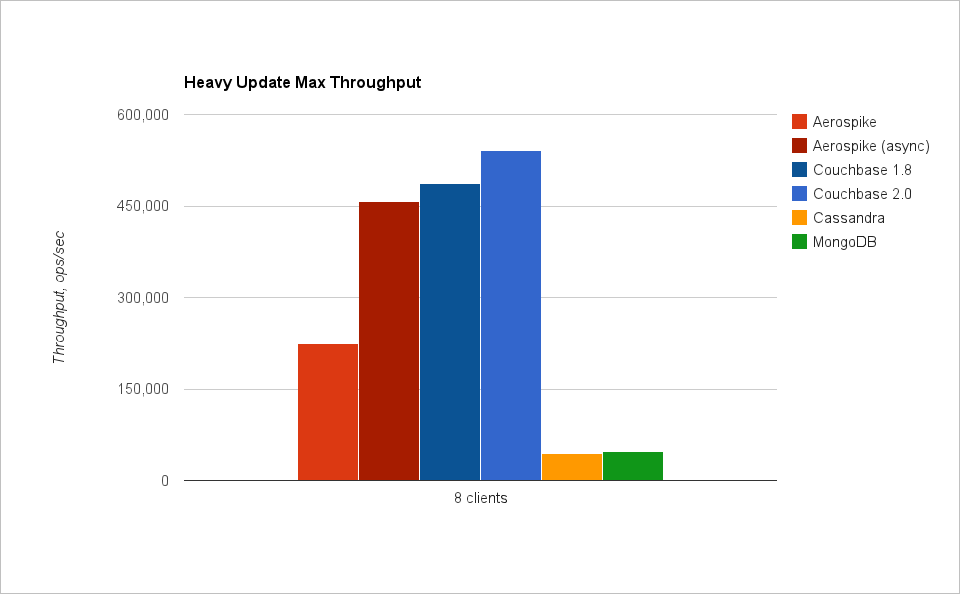

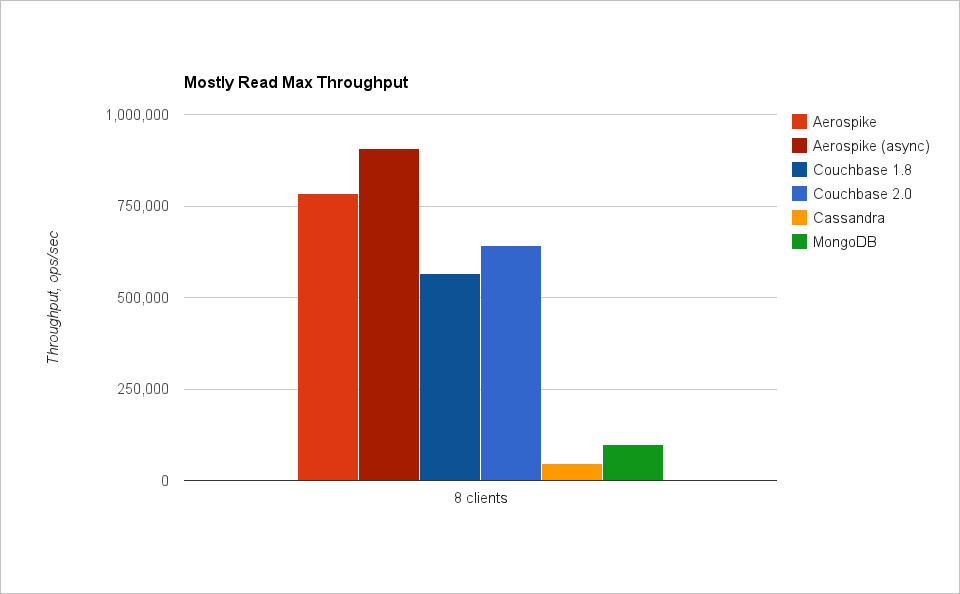
Выводы
NoSQL БД разделились на две группы: быстрые и медленные. Быстрыми, как, собственно, и ожидалось, оказались key-value БД. Aerospike и Couchbase сильно опережают соперников.
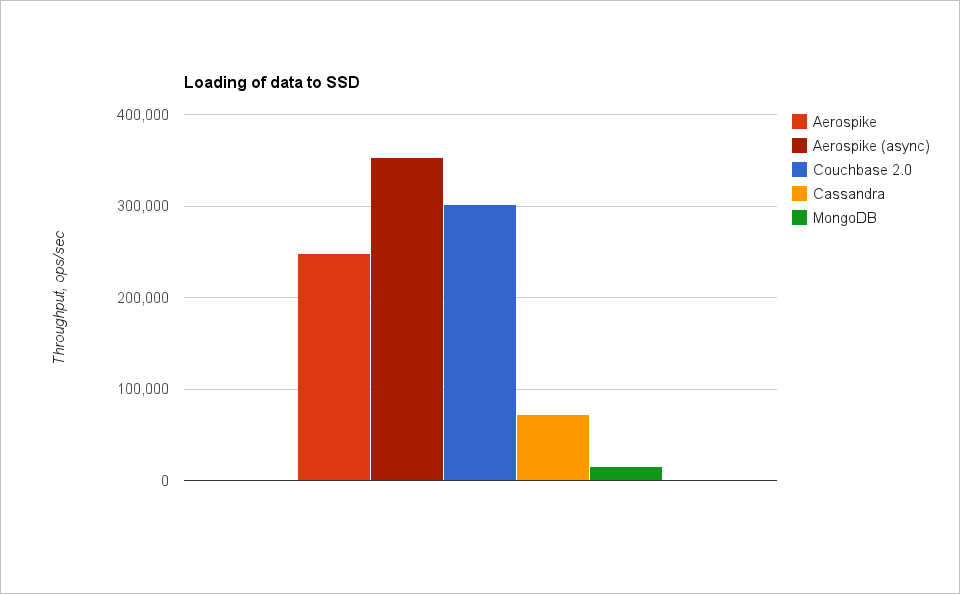
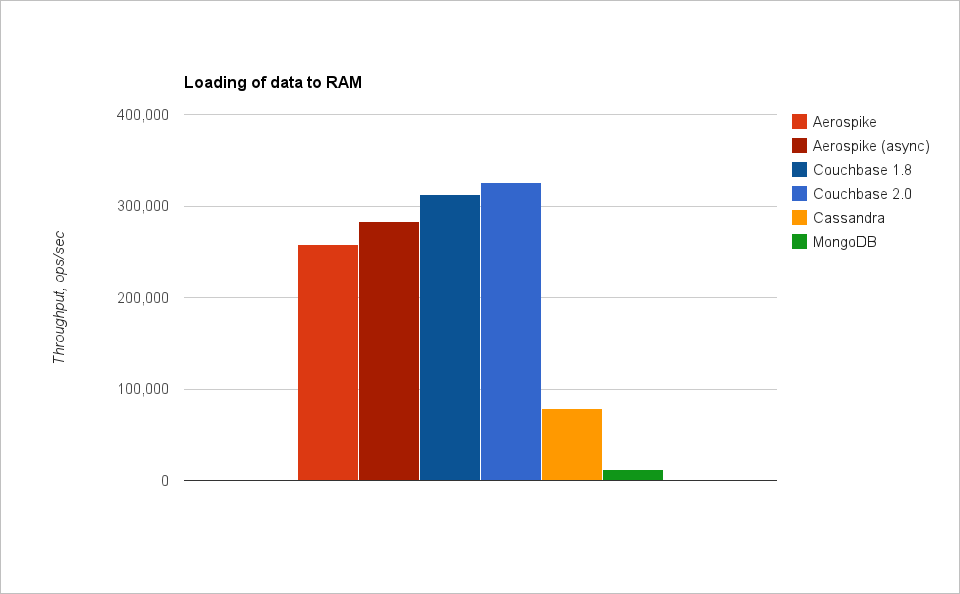
Aerospike действительно очень быстрая БД. И нам почти получилось дойти до миллиона операций в секунду (на данных в памяти). Aerospike весьма неплохо работает и на SSD, особенно если учитывать, что Aerospike в этом режиме не использует кеширование данных в памяти, а на каждый запрос обращается к диску. Значит, в Aerospike действительно можно поместить большое количество данных (пока хватит дисков, а не ОЗУ).
Couchbase быстр, но быстр только на операциях в памяти. На графиках с тестами SSD показана скорость работы Couchbase на объеме данных лишь чуть больше объема ОЗУ — всего 200 миллионов записей. Это заметно меньше 500 миллионов, с которыми тестировались другие БД. В Couchbase просто не удалось вставить больше записей, он отказывался вытеснять кеш данных из памяти на диск и прекращал запись (операции записи завершались с ошибками). Это хороший кеш, но лишь для данных, помещающихся в ОЗУ.
Cassandra — единственная БД, которая пишет быстрее, чем читает :). Это оттого, что запись в ней успешно завершается (в самом быстром варианте) сразу после записи в журнал (на диске). А вот чтение требует проверок, нескольких чтений с диска, выбора самой свежей записи. Cassandra — это надежный и довольно быстрый масштабируемый архив данных.
MongoDB довольно медленна на запись, но относительно быстра на чтение. Если данные (а точнее, то, что называют working set — набор актуальных данных, к которым постоянно идет обращение) не помещаются в память, она сильно замедляется (а это именно то, что происходит при тестировании YCSB). Также нужно помнить, что у MongoDB существует глобальная блокировка на чтение/запись, что может доставить проблем при очень высокой нагрузке. В целом же MongoDB — хорошая БД для веба.
PS
Давай немного отвлечемся от вопросов производительности и посмотрим на то, как будут развиваться дальше SQL- и NoSQL-решения. На самом деле то, что мы видим сейчас, — это повторение хорошо знакомой истории. Все это уже было в шестидесятых и семидесятых годах двадцатого века: до реляционных БД существовали иерархические, объектные и прочие, и прочие. Потом захотелось стандартизации, и появился SQL. И все серьезные СУБД, каждая из которых поддерживала свой собственный язык запросов и API, переключились на SQL. Язык запросов и реляционная модель стали стандартом. Любопытно, что сейчас тоже пытаются привить SQL к NoSQL, что приводит к созданию как оберток поверх существующих NoSQL, так и совершенно новых БД, которые называют NewSQL.
Если NoSQL решили отказаться от «тяжелого наследия» SQL, пересмотреть подходы к хранению данных и создали совершенно новые решения, то термином NewSQL называют движение по «возрождению» SQL. Взяв идеи из NoSQL, ребята воссоздали SQL-базы на новом уровне. Например, в мире NewSQL часто встречаются БД с хранением данных в памяти, но с полноценными SQL-запросами, объединениями таблиц и прочими привычными вещами. Чтобы все же хранить много данных, в эти БД встраивают механизмы шардинга.
К NewSQL причисляют VoltDB, TokuDB, MemDB и другие. Запомни эти имена, возможно, скоро о них тоже будут говорить на каждой ИТ-конференции.










