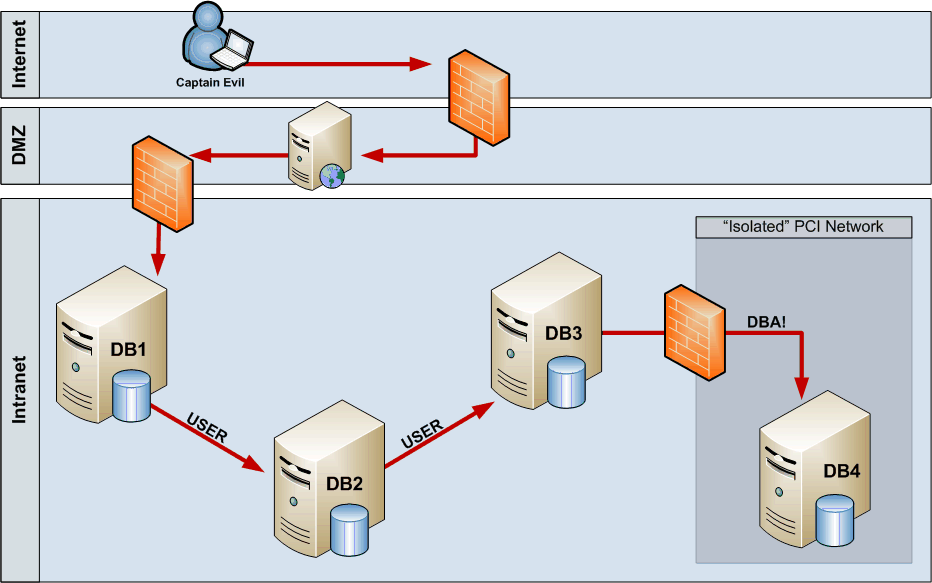
Задача
Энумерация пользователей для OpenSSH, OWA, SNMPv3 ###
Решение
Начнем мы сегодня с лайта — с классических методов энумерации. Энумерация — это «перечисление» пользователей какой-то системы. То есть возможность узнать имена пользователей в атакуемой системе. Этот перечень можно использовать для различных целей (это во многом зависит от фантазии и конкретной ситуации), но самая классика — это последующий перебор паролей к полученным логинам.
Вообще, энумерация — это такое широкое понятие, сегодня же хотел сконцентрироваться на методах удаленного перебора и определении существования пользователя по изменению ответов от сервера. Я тут прикинул, что есть три основных метода, и к ним как раз нашлось несколько показательных примеров.
По ошибкам или изменению ответа от сервера
Это когда сам сервер жалуется, что указанный логин неверный, либо когда само тело ответа меняется. По последнему был кейс в одном веб-приложении, когда для несуществующего пользователя ответ отличался всего на один байт. Выявить его было достаточно просто: отправляем два запроса на сервер с реальным юзером и точно рандомным, а потом сравниваем ответы в Burp’е в Comparer.
Другой пример — многие реализации SNMPv3. На несуществующих пользователей они так и говорят — неизвестный юзер. Забавно, что протокол SNMPv3 создавался как более защищенный вариант, а тут такие штуки. С другой стороны, насколько мне известно, фича SNMPv3 еще и в том, что по умолчанию там не должно быть ни дефолтных учеток, ни интересной инфы в MIB’е, так как админ обязан сам заводить учетки и выбирать ветки с интересующими его настройками.
Практически же эту атаку можно выполнить с помощью тулзы-брутфорсера на Python Patator или еще одной на Ruby.
По задержке ответа от сервера
Этот метод основывается на том, что для существующего пользователя задержка при ответе будет одной, а для несуществующего — другой. Причем разница должна быть такой, чтобы сетевые задержки не мешали нам. Что интересно, даже если все внедрено с виду секьюрно, эта проблема может проявиться, особенно при определенных подходах взаимодействия с бэкендом.
Одним из интересных примеров выступает OWA — Outlook Web App. Это такое комплексное веб-приложение, которое по сути представляет собой веб-версию аутлук. По версиям точно не скажу, но, наверное, все, что я видел, были уязвимы к такой атаке. В одной доке было сказано, что причина тому — привязка к домену. То есть OWA для проверки учетки должен обратиться к контроллеру домена, что и вызывает задержки. У меня здесь есть некоторые сомнения, так как я пентестил другие приложения, повязанные с доменом, и там такого поведения не проявлялось.
По реакции на нестандартные входные данные
Здесь мы пытаемся понять работу приложения и подставить некорректные данные в логин или пароль. Итогом может быть либо временная задержка, либо изменения ответа. Главная идея здесь именно в нетипичности данных. Простой пример пояснит все.
OpenSSH — один из самых распространенных SSH-серверов на никсах. И последние версии его (4, 5 и 6) уязвимы к time-based энумерации пользователей. Но не к простой. Для выявления существующих юзеров нам необходимо указывать при переборе логинов пароль длиной порядка 30 тысяч. И фича тут вся в том, что OpenSSH сначала проверяет имя юзера, а потом, в случае нахождения его, сравнивает пароль. Но введенный пароль нужно захешировать (так как он хранится не в плейн-тексте), а потому ощутимая временная задержка возникает только в случае, когда пароль очень большой и серверу требуется много времени на преобразование.
Метод рабочий — проверено. А вот с помощью тулзы OSUETA мы сможем его проворачивать.
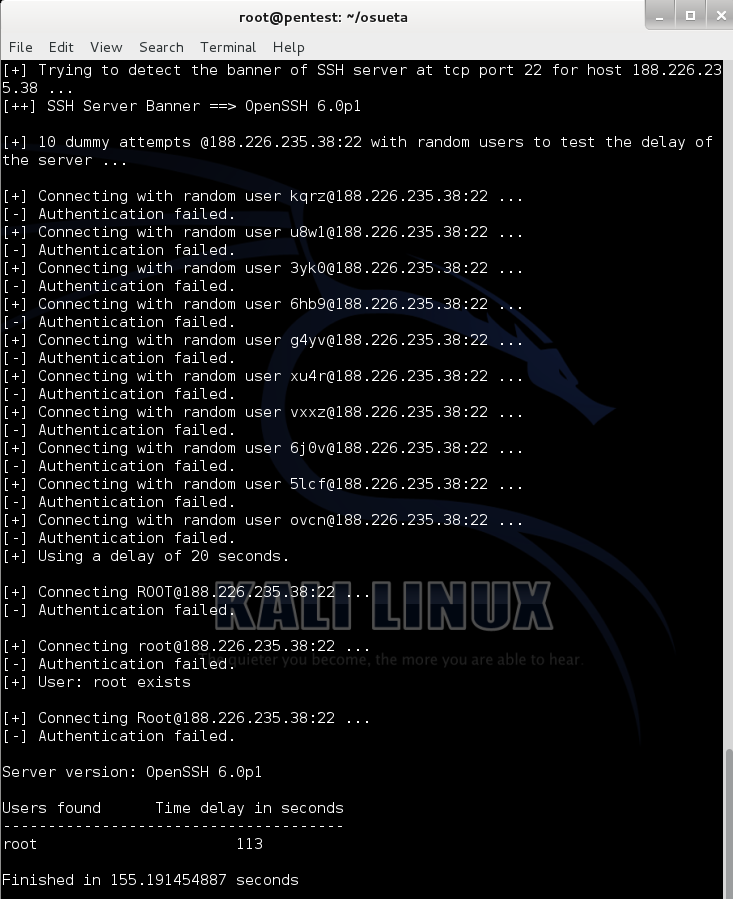
Плюс еще один эффект от атаки в ее несколько измененном виде — мы можем задосить сервер (загружается CPU).
Правда, нужно подчеркнуть, что уязвимость проявляется на всех ОС и/или всех версиях OpenSSH, так что надо тестить.
Задача
Использовать Heartbleed через STARTTLS
Решение
Вот так бывает — уедешь на недельку в отпуск, а по приезду смотришь: кто-то поломал интернет. Так же было и с Heartbleed’ом. Конечно, бага эпичная. И без NSA здесь, верно, не обошлось :). Напомню, что с помощью этой атаки, которой были подвержены последние версии OpenSSL, можно было по чуть-чуть читать память на сервере. С учетом того, что бага эта была именно в либе, то привязки к конечному (обернутому) протоколу не было — веб-сервер с HTTPS или FTP в SSL, все можно атаковать.
Но вот первая волна, да и вторая, наверное, уже прошли, многие запатчились, но осталось самое интересное — множество продуктов, которые используют дырявую либу, многие внутренние или не топовые публичные сервисы, которые забыли пропатчить, представляют собой лакомый кусочек. Но еще интересней дело обстоит с относительно нестандартным внедрением SSL. Обычно протокол заворачивают в SSL: сначала создается защищенное SSL-соединение, а потом уже идет подключение на уровне протокола самого приложения (как с HTTPS). Но есть ряд протоколов, которые поддерживают инициализацию SSL-соединения после установления соединения на уровне приложения. Например, SMTP. Клиент подключается на 25-й порт без защищенного подключения; сервер отвечает ему приветствием; клиент говорит EHLO, на что сервер отвечает перечнем поддерживаемых фич… А дальше клиент может инициировать начало защищенного SSL-соединения, отправив команду STARTTLS на сервер (если он ее, конечно, поддерживает) и начав стандартное SSL-рукопожатие. Что важно — SSL-соединение будет обычным.
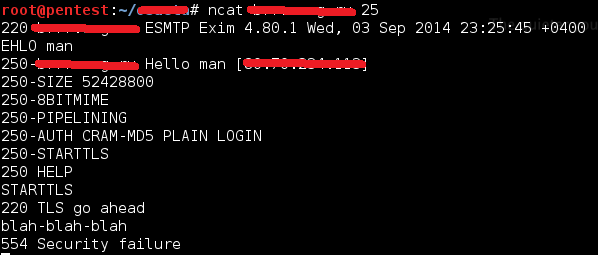
Конечно, потенциально это решение более уязвимо к MITM (хотя при корректном внедрении и на серверной, и на клиентской стороне все будет безопасно), но у него есть большой плюс — использование одного порта и для SSL, и для обычного протокола. Если же сначала производится SSL-подключение, то добиться такого мы не сможем, а потому требуется отдельный порт (как у HTTP — 80, а у HTTPS — 443). И для такого протокола, как SMTP, которым пользуются и юзеры, и MTA, изменение порта практически невозможно (по крайней мере для MTA), так что без STARTTLS не обойтись.
И теперь соберем это вместе. Многие админы (особенно далекие от ИБ), возможно, слышали о Heartbleed’е, возможно, проверили свой сайт с помощью одной из кучи тестилок, но вряд ли патчили все системы подряд. А потому нужно смотреть и SMTP, и POP3, и FTP, и другие протоколы, причем не только на SSL-портах, а еще и на стандартных, но с проверкой на STARTTLS. Ведь через них тоже можно что-нибудь выцепить полезного с помощью Heartbleed.
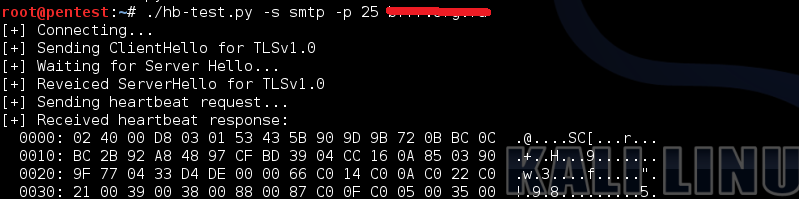
Теперь немного практики. К сожалению, скрипт Nmap для теста на Heartbleed проверяет лишь SSL-порты, так что необходимо использовать другие средства. Например, модуль в Metasploit’е (auxiliary/scanner/ssl/openssl_heartbleed) или питоновский скрипт на GitHub’e поддерживают проверку через STARTTLS.
Задача
Обойти SSL pinning на iOS и Android
Решение
И еще немного про SSL. Как ты, наверное, знаешь, одна из главных задач SSL — проверить точку нашего подключения, то есть туда ли подключились, куда мы хотели. Достигается это за счет сертификата, который сервер должен отправить клиенту на стадии рукопожатия. В сертификате хранится открытый ключ сервера, информация о нем (имя сервера, например), а также подпись удостоверяющего центра. Чтобы проверить сертификат, клиент должен проверить подпись.
Подпись — это зашифрованный закрытым ключом удостоверяющего центра (УЦ) хеш от информации в сертификате. То есть для проверки клиент считает хеш полученного сертификата и получает второй хеш, из расшифровывания открытым ключом УЦ подписи в сертификате. Хеши сошлись — значит, все хорошо, нет — рисуем алерт юзеру. Как видишь, все здесь строится на том, что у клиента ДОЛЖЕН храниться открытый ключ УЦ (типа доверенный).
И казалось бы, все хорошо и вполне секьюрно, но... Есть и здесь ряд проблем. Клиент, получается, доверяет УЦ, и все, что подписано УЦ, — «правда». А что, если УЦ скомпрометируют? Такое уже бывало, и не раз. Тогда кто-то может сделать валидный SSL-сертификат на www.google.com и втихую снифать весь HTTPS-трафик. Добавим к этому, что в среднем в ОС хранятся сотни различных доверенных УЦ и что есть промежуточные центры сертификации, к которым тоже есть доверие (хотя их нет в локальном хранилище, но они подписаны доверенным УЦ). А если еще и вспомнить про интерес государства к контролю данных пользователей, которое запросто может надавить на какой-нибудь промежуточный центр и получить любой сертификат. Ну и конечно, многие организации устанавливают на хосты (а также мобильные устройства) своих пользователей сертификаты УЦ самой организации… В общем, это большая проблема (особенно из-за неразберихи), и сейчас пытаются придумать замену.
Так вот, в качестве одного решения придумали SSL pinning (или certificate pinning). Он проявляется в двух видах: клиентское приложение хранит у себя информацию либо о сертификате сервера, либо об открытом ключе сервера. То есть приложение не пользуется системным хранилищем сертификатов, а рассчитывает только на себя. Таким образом, даже если какой-то другой доверенный УЦ сделает сертификат, то он не сможет подпихнуть его в приложение, так как оно сразу же задетектит неладное. Здесь есть одно большое ограничение — приложение должно заранее знать (хранить у себя) отпечатки сертификатов или открытых ключей. То есть повсеместно внедрить это затруднительно, а вот в мобильных приложениях — вполне просто. Чаще всего мобильное приложение общается с какой-то конкретной точкой входа на сервере, а не со всеми подряд, а потому мы можем хранить сам сертификат / открытый ключ в приложении. Надеюсь, что здесь все стало ясно.
Но с другой стороны, для нас, добрых исследователей, такая защита несет некоторые проблемы. Например, платформы iOS и Windows Phone внедрили SSL pinning для своих магазинов App Store, Market. И теперь мы не можем перехватывать SSL-трафик при анализе просто так — из-за добавления сертификата в доверенные.
Что же делать? Вариант первый — пропатчить само приложение (джейлбрейк или рутование, конечно, нужно). То есть вырезать проверку сертификата. Но это затруднительно и не универсально. Вариант второй — полностью отключить проверку сертификатов на уровне всей ОС. В 2012 году на Black Hat USA компания iSEC Partners, а именно Джастин Осборн (Justine Osborne) и Олбан Дикет (Alban Diquet), представили свою разработку Android-SSL-TrustKiller и iOS-SSL-Kill-Switch.
Суть обеих тулз одинакова. На рутованных/джейлбрейкнутых устройствах с помощью Java Debug Wire Protocol / MobileSubstrate захукать функции базового API, отвечающего за SSL, и при любых проверках сертификата возвращать положительное значение. Тут важно, что если приложение хочет использовать certificate pinning, то оно должно переопределить некоторые функции базовых классов, но в случае использования этих тулз мы хукаем функции на более раннем этапе. Технические подробности упущу, так как глубоко в этом не шарю. Интересующиеся могут посмотреть в презентации и в этом блоге. Хотя здесь скорее важно то, что обе тулзы работают 🙂
Задача
Просканировать порты, используя FTP Port bounce
Решение
Попинаем мертвечинку? 🙂 Шучу, но на самом деле хотел кратенько пробежаться по одной старой атаке — FTP Port Bounce (от 1997 года), так как и о классике знать полезно, да и «глубина» ее также подкупает.
Итак, протокол FTP был придуман для обмена файлами (что и следует из названия). Пользователь подключается на 21-й порт, аутентифицируется (протокол плейн-текстовый), а дальше открывает у себя порт и отправляет на сервер команду PORT с указанием своего IP-адреса и открытого порта. Сервер подключается к нему. По первому подключению (21-й порт) идет управление (команды от пользователя и ответы от сервера), а по второму — уже данные. Неплохое решение, но имело приличную дырку.

Когда мы подключаемся к серверу, мы сами указываем и IP, и порт для подключения сервера. Если сервер подключается, все ОК, если нет — ругается. Таким образом, за счет перебора IP-адресов и портов мы можем удаленно сканировать сеть через FTP-сервер. Также атаку использовали для обхода файрволов. Олдскульный такой SSRF. Что самое важное — он возможен именно на уровне протокола, а не конкретных реализаций.
Сейчас, к сожалению, большинство ФТП-серверов запатчено: в команде PORT можно использовать только IP подключившегося, да и значение для порта ограничено определенным диапазоном.
Проверить на уязвимость к атаке можно с помощью скрипта ftp-bounce в Nmap.
Задача
Атаковать PRNG
Решение
Продолжим тему крипты и поговорим о такой важной штуке, как PRNG (Pseudorandom number generator), то есть генераторе случайных чисел. Вообще, в крипте без него никак — практически вся она построена на том, что мы можем сгенерировать некую непредсказуемую последовательность. А вот с этим все достаточно плохо, ведь математическим алгоритмом мы этого не можем добиться. Все равно алгоритм где-то зацикливается, есть какие-то закономерности. До сих пор это остается одной из больших задач в информатике. Дабы уменьшить уровень проблемы, обычно используются какие-то внешние источники энтропии, такие как движения мышкой, загрузка процессора, количество потоков, время… но и с этим также есть трудности. На самом деле это большая тема, так что мне хотелось бы обратиться именно к практическим примерам, чтобы у тебя появилось желание покопаться в ней :).
Да, забыл отметить. PRNG обычно разделяют на криптостойкие и обычные. Для последних мы имеем возможность по результату их работы рассчитать их состояние и потом генерировать предыдущие и последующие значения. Круто, да?
На последнем Positive Hack Days был очень крутой доклад (ИМХО, один из лучших в этом году) от Михаила Егорова и Сергея Солдатова, в котором они полностью раскрутили java.util.Random (обычный PRNG) и выпустили под него тулзу для расчета состояний и последующей генерации последовательностей. Что еще круче, они подкрепили свое исследование практическими багами.
Например, они поломали сессионную куку у Jenkins (знаменитое в определенных кругах веб-приложение). В ней в качестве основы для ее генерации используется MD5-хеш от конкатенации клиентского IP, порта на сервере, времени в миллисекундах, а также значения сгенерированного java.util.Random (инициализированного так же временем). Для понятности смотри картинку.

Казалось бы, все вполне секьюрно… Но нет, мы можем провести атаку. Все, что нам надо, — выяснить состояние PRNG, что даст нам возможность генерировать последующие куки. Нам неизвестно время генерации, время инициализации и количество сгенерированных кук (см. Entropy на картинке). Но и это не проблема: часть времени мы можем получить из HTTP-заголовков от веб-сервера, часть — рассчитать на основании анализа TCP/IP-стека (подробности см. в презентации). В общем, все сводится к минимальному брутфорсу.
Восстановив значение PRNG, мы систематически отправляем запросы на сервер для мониторинга его состояния, и, когда какой-то пользователь залогинится, мы заметим расхождение в сгенерированных значениях и останется только перебрать его IP-адрес. Итог — мы сгенерим точно такую же куку, как и у залогиненного юзера.
Конечно, надо побрутить, но атака, ИМХО, очень крута.
Перейдем ко второму примеру. И здесь уже мы имеем дело с секьюрным генератором. Но хотя «предсказывать» мы не можем, у нас есть еще возможность атаковать. В данном случае нас интересует источник изначальной энтропии. Если он плох, то мы можем получить примерный список всех значений и опять-таки все возможные варианты.
В 2008 году всплыл толстый баг в ОС семейства Debian, и касался он OpenSSL. Произошло все в 2006 году, когда разрабы Debian пробежались по пакетам с помощью Valgrind и Purify. Последние тулзы ругались на использование (возможно) неинициализированных переменных в генераторе в OpenSSL. Дабы пресечь возможные проблемы, после одобрения парней от OpenSSL пару строк закомментировали (см. картинку).

По ужасному стечению обстоятельств (или опять NSA :)) эти строчки как раз и отвечали за наполнение генератора энтропией. В результате единственная энтропия, которая осталась, был PID процесса. А значение он может принимать от 1 до 32 768. В результате все это привело к тому, что в течение двух лет люди использовали генератор с такой маленькой энтропией. Самым универсальным последствием стало то, что все возможно сгенеренные ключи (открытые и закрытые) можно было рассчитать. То есть можно подобрать закрытый ключ для SSL и спокойно делать man in the middle атаки либо обойти аутентификацию по сертификату для какого-нибудь юзера на SSH-сервере…
Реально большая дыра была. Конечно, сейчас, после шести лет, найти уязвимые системы тут вряд ли возможно, но все-таки. Сама база прегенеренных RSA-, DSA-ключей есть на exploit-db.com, скрипт атаки на SSH там же, а на уязвимый SSL умеет тестить www.ssllabs.com (+ много других онлайн-сервисов).
Надеюсь, мне удалось показать интересность практических атак на крипто. Теория теорией, но практические атаки очень увлекательны.
Спасибо за внимание и успешных познаний нового!