Содержание статьи
Собрать информацию по заголовкам email
Решение
Технологий становится все больше и больше. Они рождаются, меняются, исчезают и перерождаются. Все это создает большой ком, который растет и растет. Зачастую во многих компаниях разобраться с тем, что вообще используется в корпоративной инфраструктуре, — уже большая задача, не говоря о том, чтобы это все безопасно настроить… Это я к тому, что мест, через которые мы можем что-то где-то поломать или хотя бы выведать, — огромное количество. Сегодня этого мы и коснемся. И первым примером будет электронная почта.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.Как сервис она была придумана много лет назад. В ее основе лежит протокол SMTP, функционирующий на двадцать пятом TCP-порту. Принцип его работы выглядит примерно так. Мы, используя свой почтовый клиент, подключаемся к почтовому серверу (Mail Transfer Agent) по SMTP и говорим, что хотим отправить письмо на такой-то адрес. MTA принимает от нас письмо и подключается к тому MTA-серверу (опять по SMTP), куда мы посылаем письмо. IP-адрес удаленного MTA наш MTA получает из MX-записи той доменной зоны, куда мы шлем письмо (то, что идет в email после @). Найти MX-запись (читай — MTA) для любого домена очень просто:
Nix:
dig MX any_host_name.com
Win:
nslookup -type=mx any_host_name.com
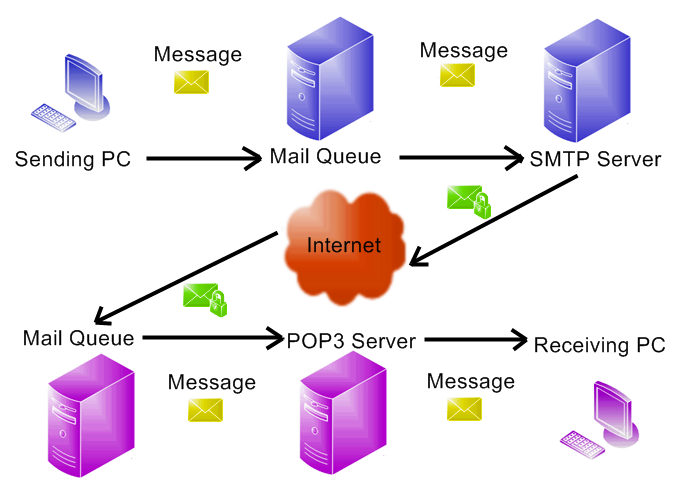

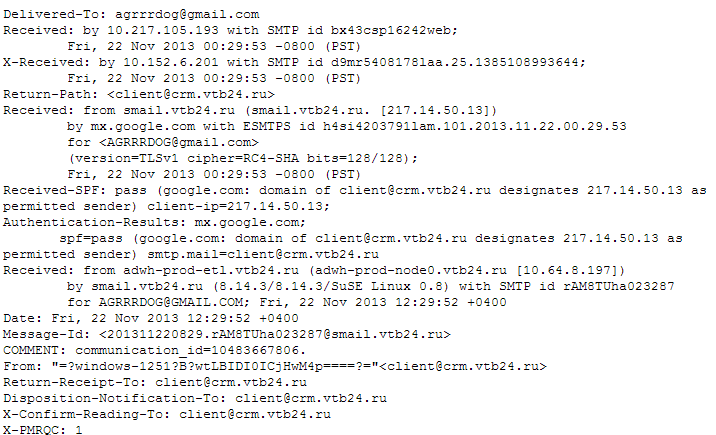
Ты даже сам можешь отправить письмо, используя ncat или Telnet. Все, что потребуется, — это четыре команды: HELO, MAIL TO, RCPT TO, DATA (хотя есть ряд ограничений в зависимости от настроек сервера). Также стоит отметить, что каждое письмо имеет заголовки и тело сообщения. Заголовки только частично отображаются конечному пользователю (например, «Subject:») и используются, например, при возврате письма из-за проблем в конечном MTA.
Но самое важное, что фактически письмо проходит больше чем через один MTA и каждый из них добавляет ряд своих заголовков. Причем здесь все очень и очень «разговорчивы». Например, если письмо приходит из какой-то корпоративной сети к нам на почту, то мы, скорее всего, увидим в заголовках IP-адрес оправившего его пользователя (то есть того, кто подключился к внутреннему MTA в корпоративной сети) и версию используемого почтового клиента. Далее мы увидим данные уже самого MTA: IP-адрес (или имя в корпоративном домене), версию серверного ПО. А после этого очень часто — аналогичную запись, но уже по другому сетевому интерфейсу MTA.
Вдобавок к этому можно часто увидеть версию корпоративного антивируса, проверяющего всю почту, или применяемого спам-фильтра, а также характеристики детекта спама. Все это можно задействовать для более заточенных атак с использованием социальной инженерии. Например, в определенных ситуациях мы можем заранее «отслеживать» вероятность, что наше письмо попадет в спам. Кстати, если ты посылаешь письмо через какой-то веб-сайт (например, mail.ru), то твой IP тоже можно будет увидеть в заголовках.
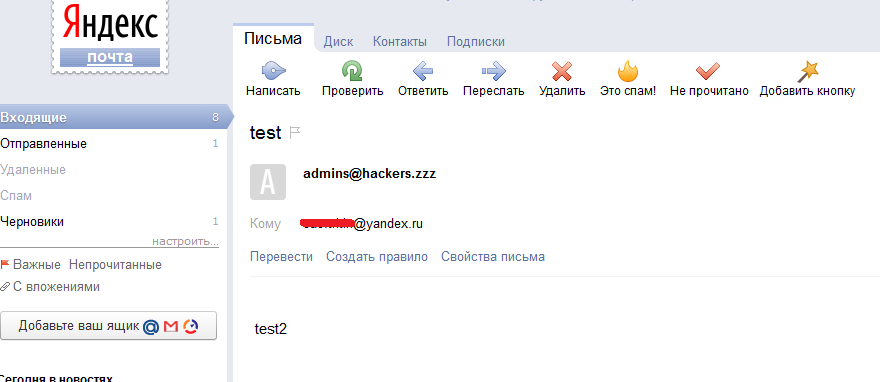
Как же посмотреть эти заголовки? Очень просто. Все почтовые клиенты поддерживают их. Например, в Thunderbird — <Ctrl + U>. В Gmail — стрелка «Еще» — показать оригинал. При анализе заголовков Received (то есть списке участвовавших в пересылке письма) нужно помнить, что они идут в обратном порядке. А для упрощения парсинга их рекомендую воспользоваться каким-нибудь онлайн-сервисом (которых немало), например E-Mail Header Analyzer.
Итог. Отправляем одно письмо секретарше в какую-то компанию, та нам отвечает. И мы уже знаем, что да как у них там :).
Получить список доменов
Решение
Продолжим сбор информации. Давай представим себе компанию, которую мы хотим поломать снаружи. Одна из первых задач для пентеста через интернет — получить список доменных имен / виртуальных хостов. Методов много, и они стары как мир: обратный резолв IP, перебор имен, гуглохакинг. И ни один из них не дает полного результата, так что попробуем использовать их все вместе, попутно добавив чего-нибудь новенького :).
«Новенькое» — это сбор информации об именах с помощью SSL. Итак, давай вспомним основу. При подключении по SSL к любому серверу он возвращает нам свой сертификат. Сертификат — это набор полей (в том числе и открытый ключ сервера), подписанный корневым центром сертификации. В нем также есть поле CN (Common Name), где содержится имя сервера, на который выдан данный сертификат. Это уже что-то.
Например, когда мы сканируем по IP-адресам сеть и находим какой-то HTTP-сервер, то часто мы можем получить от него ответ с ошибкой (403). Все правильно, ведь мы не знаем, что указывать в заголовке Host HTTP-запроса. Тут-то нам и пригодится имя сервера. Посмотрим в SSL-сертификат, и вуаля — мы уже знаем, что подставить в заголовок.
Но это еще не все. Есть еще одно малоизвестно поле того же сертификата — SubjectAltName. Оно позволяет задавать альтернативные имена. То есть фактически один ключик может быть использован для совсем разных имен. Смотри рисуночки, и все станет ясно.
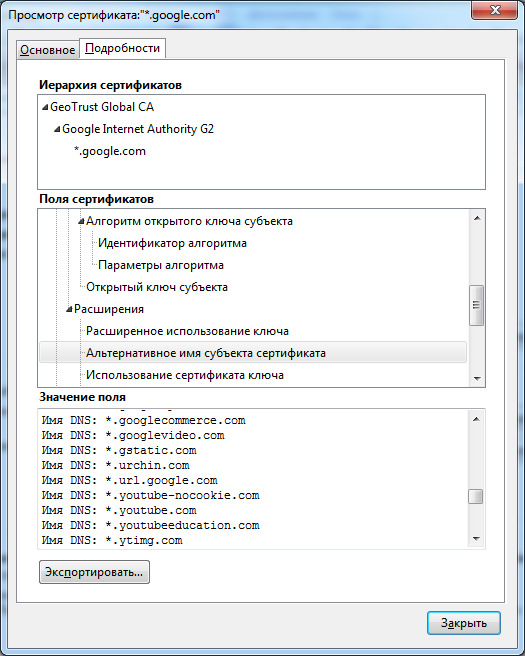
Получается, что вроде бы из «секьюрити»-фишки мы достаем крупицы интересующей нас информации. Отмечу еще из личного опыта, что иногда в сертификаты попадает информация и о внутренних именах хостов.
Атаковать с использованием техники session puzzling
Решение
Логические уязвимости — это всегда весело. Они бывают простыми и сложными, но их объединяет одно — необходимость правильно подумать. Вот только есть с ними и небольшая проблема: их как-то не особо типизируют (возможно, как раз-таки потому, что они все такие разнообразные :)). Ну да ладно. Хочу рассказать тебе об интересной технике (или виде уязвимостей, это уж как посмотреть), которую презентовали относительно недавно, пару лет назад. Название ей — session puzzling или session variable overloading (по версии OWASP).
Для начала давай вспомним, как веб-приложения аутентифицируют и авторизуют пользователя (HTTP ведь stateless).
- Юзер входит на сайт.
- Юзер вводит логин и пароль и отправляет на сервер.
- Сервер проверяет эти данные и, если все верно, пускает его во внутреннюю часть, при этом отправляя юзеру cookie в HTTP-ответе.
- Когда юзер переходит на какую-то еще страницу, браузер добавляет к запросу куки. Сервер по данной куке понимает, что юзер уже аутентифицирован, и работает в соответствии с этой мыслью.
Все выглядит вполне четко, но здесь пропущен важный момент. Он состоит в том, что сервер хранит у себя информацию о сессии конкретного пользователя. То есть приходит кука от юзера, он берет ее и смотрит (в памяти, в БД — в зависимости от ПО), а что же к ней у него «привязано». Простейший пример: он может хранить имя пользователя в сессии. И по куке получать из сессии имя и точно знать, кто к нему обратился в данный момент.
Вообще, в сессии хранят обычно «временную» информацию, а что-то более-менее постоянное — уже в БД. Например, логично хранить имя юзера в сессии, а вот его «роль» можно хранить в БД и запрашивать только по необходимости. Здесь, на самом деле, многое зависит от конкретного приложения и разработчика ПО.
Например, хранение большого объема данных в сессии может привести к исчерпанию либо памяти веб-сервера (Tomcat), либо свободного места на жестком диске (PHP). С другой стороны, обращения в БД требуют больше времени. Обусловлен выбор обычно производительностью, и о безопасности здесь редко думают (конечно, ведь как можно повлиять на то, что хранится на серверной стороне?).
И вот мы подошли к самой сути данной атаки: в определенных ситуациях мы можем влиять на то, что хранится на сервере. В каких конкретно — это тоже зависит от ситуации. Чаще всего нам нужны несколько различных точек входа в приложения, данные из которых попадают в одну и ту же переменную сессии.
Я приведу классический пример, и все будет ясно. Та же ситуация, что описана выше. Клиент, который может входить в приватную зону на сайте через страницу логина. Сайт, который хранит имя клиента в сессии, а доступ к приватным страницам проверяет по имени пользователя из сессии.
Но добавим к этому страницу с восстановлением пароля, на которой ты должен ввести свое имя (1), а система в ответ задаст секретный вопрос (2), на который ты должен будешь ввести правильный ответ для сброса пароля (3). И, как ты вероятно уже понял, для того чтобы провести по этой последовательности тебя (от 1 до 3), сервер должен также воспользоваться сессией и хранить в ней имя пользователя.
Так вот, атака будет заключаться в том, что, когда мы заходим на страницу восстановления и вводим имя пользователя администратора, сервер в сессии отмечает, что юзер — админ, и выводит для админа секретный вопрос. Все! Мы можем ничего не вводить, а просто перейти на приватный раздел сайта. Сервер посмотрит сессию, увидит, что имя пользователя админа, и даст нам доступ. То есть во время восстановления пароля мы «поставили» необходимое нам значение и дальше пошли бороздить приватные части. Бага здесь и в том, что сайт использует одно имя переменной и при аутентификации, и при восстановлении пароля.
Сначала может показаться, что данный тип уязвимости — редкость. На самом деле это не так. Я лично находил такие в достаточно распространенных продуктах. Вот только не знал тогда, что это так называется.
Кстати, кроме обхода аутентификации, использовать данную технику можно для повышения привилегий или перескока шагов на многошаговых операциях…
Как искать такого типа баги? Фактически какой-то суперметодики для этого нет. Но в качестве начала необходимо выискать входные точки в приложение, имеющие потенциальную возможность влиять на значения в сессионных переменных. А дальше — мозг, руки и тесты, тесты, тесты.
Если заинтересовался или хочешь попробовать на специальном уязвимом приложении — прошу к авторам изначального ресерча.
Провести атаку с подделкой Host
Решение
Еще один пример почти логической веб-уязвимости. Она основана на возможности подделки заголовка Host HTTP-запроса. Точнее, на отсутствии его проверки веб-сайтом при его последующем использовании. Но по порядку.
Когда ты вводишь в браузере какое-то имя сайта, он подключается к полученному из имени IP-адресу и в HTTP-запросе обязательно использует заголовок «Host:», в котором указывает это имя. Часто веб-приложения берут значение из Host для построения путей до ресурсов (скриптов, картинок и прочего). Вероятно, это позволяет им работать без привязки к конкретному названию сайта. Вроде как таким образом работает Joomla, Drupal.
Вообще, с точки зрения безопасности, это немного странная, но неопасная ситуация. Казалось бы, да, подставив свое доменное имя в Host, мы можем сделать так, чтобы на ресурс загрузились бы наши JS-скрипты (считай — XSS). Но заставить чужой браузер сделать то же самое (то есть вставить неверный Host), по сути, невозможно. Так что с точки зрения SOP здесь все вроде вполне нормально.
Но недавно я прочитал интересный пример эксплуатации данной фичи. Представь себе страницу восстановления пароля. Вводишь имя почты, и на нее отправляется ссылка со случайным токеном для смены пароля (классическая ситуация). Так вот, мы также можем подставить свой Host в запросе, и тогда письмо, которое придет пользователю, будет содержать наш домен! И как только пользователь кликнет на данную ссылку, на наш домен он перейдет вместе с токеном, который мы можем быстренько использовать для смены пароля.
Конечно, здесь есть важное затруднение — требуется применить социальную инженерию. Пользователь, конечно, не должен кликать на все сообщения о сбросе пароля. Кроме того, есть ряд серверных ограничений, так как веб-серверы будут отказываться обрабатывать запросы для неизвестных им Host.
Но все же в этой атаке что-то точно есть.
Поломать UPnP
Решение
Universal Plug and Play (UPnP) — это набор сетевых протоколов, которые были созданы для упрощения взаимного нахождения различными девайсами, а также для их взаимодействия. Девайсом в данном случае может быть почти все что угодно: роутер, принтер, smartTV, какие-то сервисы Windows… И хотя, возможно, термин UPnP кажется тебе незнакомым, фактически он очень и очень распространен.
С точки зрения примера взаимодействия можно посмотреть в сторону Skype или BitTorrent и Wi-Fi-роутеров. Первые с помощью UPnP могут найти роутер и отправить ему набор команд на проброс какого-то внешнего порта вовнутрь. Очень удобно получается: никаких заморочек с ручной настройкой port forwarding’а.
Но если посмотреть на это с нашей хакерской точки зрения, то здесь есть чем поживиться… UPnP как технология появился еще в начале 2000-х и, возможно, потому имеет приличный ряд огрехов с точки зрения безопасности. Отсутствие аутентификации, например. Но давай обо всем по порядку.
UPnP основывается на нескольких протоколах, а также, что важнее, на определенной логической последовательности:
Обнаружение устройств. И для этого используется протокол SSDP (Simple Service Discovery Protocol — UDP, 1900-й порт). Каждое устройство, поддерживающее UPnP и предоставляющее какой-то сервис, систематически отправляет SSDP Notify пакет на 1900 UDP на multicast-адрес 239.255.255.250. Формат данных пакетов — HTTP.
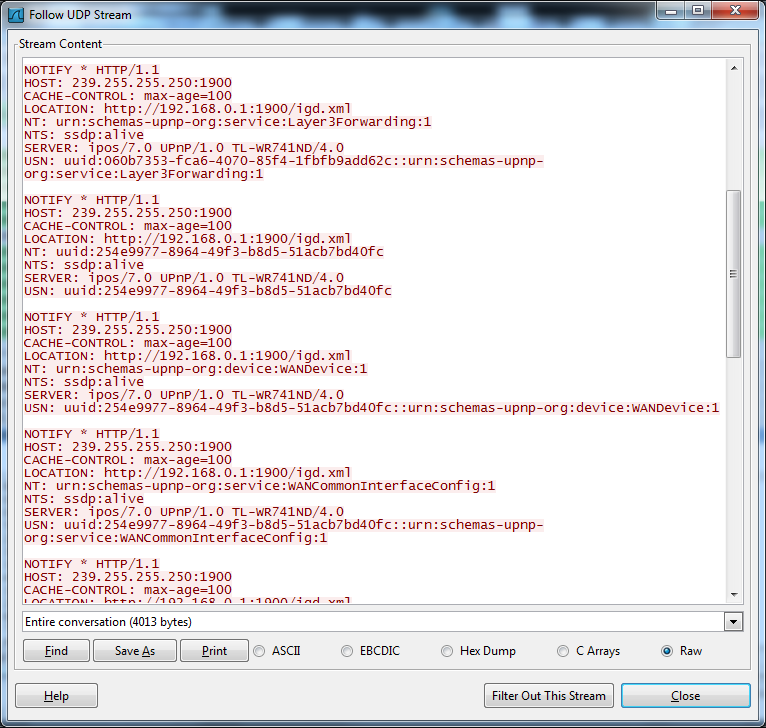
В нем он сообщает поддерживаемые стандарты, а также TCP-порт и URL до описания (XML) каждого из своих сервисов. Например, http://192.168.0.1:1900/igd.xml описывает возможности сервиса InternetGatewayDevice.
Кроме прослушки 239.255.255.250, мы «насильно» можем посылать M-SEARCH запросы на тот же 1900-й порт. UPnP-серверы должны будут ответить на данный запрос. Отвечают все тем же Notify-пакетом.
Итак, первая задача — это, по сути, получение списка UPnP-серверов, а также URL’ов до XML’ек, с полным описанием функциональных возможностей каждого из сервисов сервера. Это важно, так как и порт, и URL’ы могут быть различными у разных производителей.
Определение возможностей. Итак, из SSDP мы получаем список сервисов со ссылкой на их описание в формате XML. Для доступа к ним уже используется обычный HTTP. В данном файле идет описание каждого из сервисов, а также ссылки на XML-файлы со списком возможных действий для каждого из них. То есть в данном случае XML’ки — это просто статические описания всех возможностей сервисов, а также перечень входных точек в сервисы и необходимых данных для выполнения действий.
Контроль. Получив данные XML’ки, мы уже можем создавать SOAP-пакеты и посылать их на сервер по HTTP, выполняя, таким образом, какие-то действия на сервере.
Аутентификация, как я уже говорил, отсутствует, и сервер выполнит все действия, которые ему придут в SOAP-запросе.
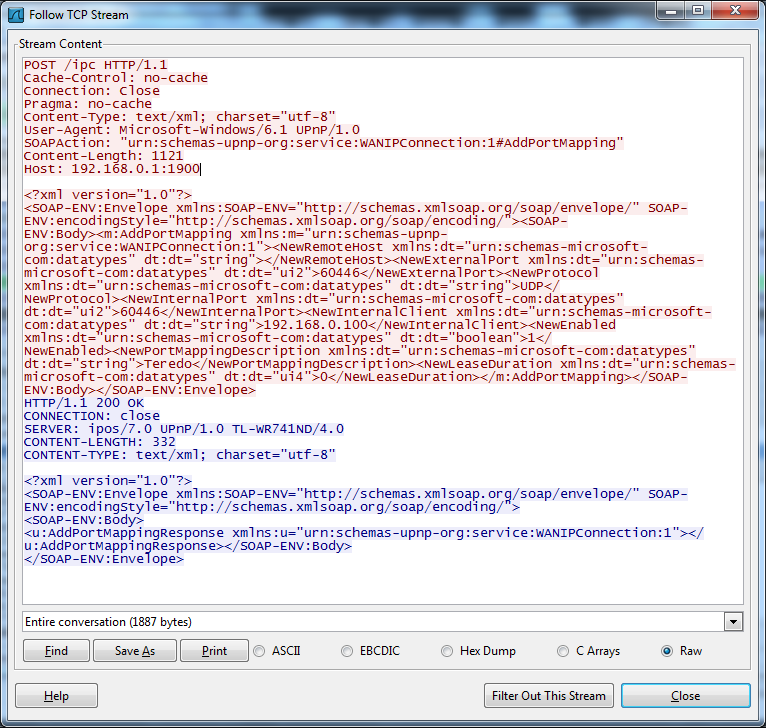
В 2008 году GNUCitizen даже выложили специальную SWF’ку. Эта SWF’ка (Flash) посылала SOAP-запрос на роутер (его IP необходимо указать), чтобы тот прокинул произвольный внешний порт на порт хоста юзера-жертвы. И получается, что, как только юзер-жертва открывал сайт с данной SWF, флеш «пропиливал» дырку в роутере до юзера и мы могли его атаковать. Очень удобно!
К сожалению, данный способ больше не работает: с тех пор ужесточилась песочница Flash’а и мы уже не можем посылать произвольные POST-запросы (самое главное, нам надо добавить еще заголовок SOAPAction) на любой другой хост (так как сначала произойдет запрос на разрешающие правила в crossdomain.xml).
Итак, теперь, я думаю, мы видим, как это все работает. Давай еще посмотрим, что можно с этим сделать.
Во-первых, это прошитые возможности SOAP’а. Кроме примера с пробросом портов, есть случаи, когда мы можем сменить настройки роутера и выставить свой DNS-сервер. А это уже ого-го! Тут все зависит от конкретного устройства, сервисов и нашей фантазии.
Во-вторых, это приличный инф-дисклоуз: IP-адреса, версия девайса и UPnP-библиотек и прочее (в SSDP, HTTP-сервере и XML’ках) Вдобавок к этому многие прошитые возможности также могут нам что-то рассказать. Пароли, например. Как-то во время внешнего пентеста обнаружили доступный SSDP и накопали пучок приватной инфы о внутренностях компании.
В-третьих, мы можем поломать сами сервисы. Год назад Rapid7 сделали прикольнейшее исследование UPnP. Они просканили интернет на SSDP и на SOAP (на стандартных портах), пофингерпринтили их. Оказалось, что большинство UPnP-серверов построено на четырех SDK. Из них выделяются MiniUPnP и Portable UPnP (libupnp), на которых «держится» больше половины. Но что важнее, почти все серверы используют устаревшие версии библиотек, в каждой из которых есть пучок уязвимостей, в том числе приводящих к RCE. Причем и в SOAP’е, и в SSDP.
Кроме того, в этом исследовании показано, как на самом деле много таких устройств торчит наружу, хотя бы SSDP. То есть даже если тот же SOAP закрыт, мы можем захватить удаленный контроль над устройством через SSDP.
Конечно, здесь надо отметить, что с удаленным сплоитингом может быть не очень просто, так как устройства эти часто построены на всяких MIPS, ARM, что точно все затрудняет. К тому же придется бороться еще и с механизмами защиты памяти ОС (тот же ASLR). Но все-таки это возможно.
Что же нам надо, чтобы все поломать?
Тулз на деле немного. В метасплоите есть модуль для поиска UPnP (и детекта CVE по ним). Плюс есть два «комбайна», позволяющих выполнять SOAP-команды. Это Miranda и Umap. Оба написаны на Python’е, только под *nix и при этом не очень хорошо работают.
Надеюсь, прочтенное наполнило тебя энтузиазмом и жаждой жизни, так что если есть желание поресерчить — пиши на ящик. Всегда рад :). И успешных познаний нового!