
Для установки jq достаточно скачать исполняемый файл — есть версии для Windows, macOS и Linux. Подобно grep, sed, awk и похожим утилитам из арсенала юниксоида, jq просто принимает данные на вход и выводит результаты в stdout. К примеру, чтобы прочитать и вывести данные из файла data.json в UNIX-подобных системах, надо написать
cat data.json | jq '.'В одинарных кавычках содержатся инструкции jq (в данном случае — точка, то есть вывод всех данных). Эти инструкции пишут на языке, который предназначен специально для фильтрации и преобразования JSON.
Для упражнения я взял массив данных, который мы собирали, готовя тему номера «Секреты даркнета». В этом файле содержится четыре с лишним тысячи ссылок на теневые ресурсы и для каждой прописаны категория, URL, заголовок и количество входящих ссылок с других сайтов в .onion.
Хорошенько полазив по странице документации, я в качестве упражнения сочинил запрос, который выбирает сайты определенной категории и с количеством входящих ссылок не меньше заданного. А в конце еще фильтрует те, где в заголовке есть конкретное слово.
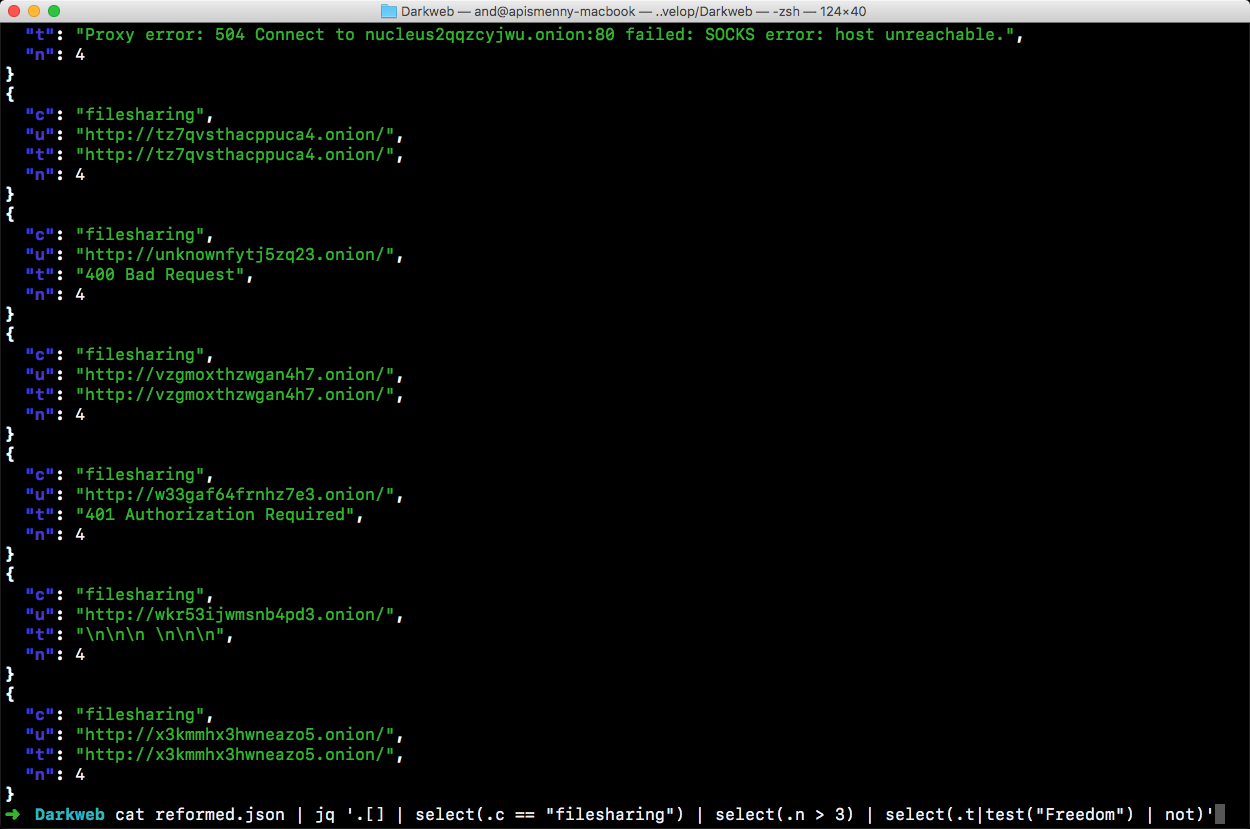

Как видишь, фильтры можно комбинировать, скармливая выход одного на вход другому. А еще у jq есть внушительное количество встроенных функций, поддержка регулярных выражений, условия и переменные. В общем, целый новый язык, который дарует тебе новую суперспособность.
