

Содержание статьи
Может быть, ты умеешь взламывать устройства на другом конце света или кодить крутые веб-приложения, но понимаешь ли ты, как работает твой компьютер? И речь не о том, что делает операционка, как функционирует garbage collector в Java или как устроен компилятор C++. Я говорю о самом низком, аппаратном уровне, ниже ассемблера: как работает железо.
Что происходит в микросхеме сетевой карты, когда приходит пакет Ethernet? Как этот пакет передается дальше в оперативную память компьютера через шину PCI Express? Как работают самые быстрые системы распознавания изображений на аппаратном уровне?
Для ответа на эти вопросы надо немного разбираться в цифровой логике работы микросхем ASIC, но начинать с них очень сложно и дорого, и вместо этого лучше начать с FPGA.
INFO
FPGA расшифровывается как field-programmable gate array, по-русски — программируемые пользователем вентильные матрицы, ППВМ. В более общем случае они называются ПЛИС — программируемые логические интегральные схемы.
С помощью FPGA можно в буквальном смысле проектировать цифровые микросхемы, сидя у себя дома с доступной отладочной платой на столе и софтом разработчика за пару килобаксов. Впрочем, есть и бесплатные варианты. Заметь: именно проектировать, а не программировать, потому что на выходе получается физическая цифровая схема, выполняющая определенный алгоритм на аппаратном уровне, а не программа для процессора.
Работает это примерно так. Есть готовая печатная плата с набором интерфейсов, которые подключены к установленной на плате микросхеме FPGA, вроде крутой платы для дата-центра или отладочной платы для обучения.
Пока мы не сконфигурируем FPGA, внутри микросхемы просто нет логики для обработки данных с интерфейсов, и потому работать ничего, очевидно, не будет. Но в результате проектирования будет создана прошивка, которая после загрузки в FPGA создаст нужную нам цифровую схему. Например, так можно создать контроллер 100G Ethernet, который будет принимать и обрабатывать сетевые пакеты.
Важная особенность FPGA — возможность реконфигурации. Сегодня нам нужен контроллер 100G Ethernet, а завтра эта же плата может быть использована для реализации независимых четырех интерфейсов 25G Ethernet.
Существуют два крупных производителя FPGA-чипов: Xilinx и Intel, которые контролируют 58 и 42% рынка соответственно. Основатели Xilinx изобрели первый чип FPGA в далеком 1985 году. Intel пришла на рынок недавно — в 2015 году, поглотив компанию Altera, которая была основана в то же время, что и Xilinx. Технологии Xilinx и Altera во многом схожи, как и среды разработки. Чаще я работал с продуктами компании Xilinx, поэтому не удивляйся ее постоянному упоминанию.
FPGA широко применяются в разных устройствах: потребительской электронике, оборудовании телекома, платах-ускорителях для применения в дата-центрах, различной робототехнике, а также при прототипировании микросхем ASIC. Пару примеров я разберу чуть ниже.
Также рассмотрим технологию, которая обеспечивает аппаратную реконфигурацию, познакомимся с процессом проектирования и разберем простой пример реализации аппаратного счетчика на языке Verilog. Если у тебя есть любая отладочная плата FPGA, ты сможешь повторить это самостоятельно. Если платы нет, то все равно сможешь познакомиться с Verilog, смоделировав работу схемы на своем компе.
Принцип работы
Микросхема FPGA — это та же заказная микросхема ASIC, состоящая из таких же транзисторов, из которых собираются триггеры, регистры, мультиплексоры и другие логические элементы для обычных схем. Изменить порядок соединения этих транзисторов, конечно, нельзя. Но архитектурно микросхема построена таким хитрым образом, что можно изменять коммутацию сигналов между более крупными блоками: их называют CLB — программируемые логические блоки.
Также можно изменять логическую функцию, которую выполняет CLB. Достигается это за счет того, что вся микросхема пронизана ячейками конфигурационной памяти Static RAM. Каждый бит этой памяти либо управляет каким-то ключом коммутации сигналов, либо является частью таблицы истинности логической функции, которую реализует CLB.
Так как конфигурационная память построена по технологии Static RAM, то, во-первых, при включении питания FPGA микросхему обязательно надо сконфигурировать, а во-вторых, микросхему можно реконфигурировать практически бесконечное количество раз.


Блоки CLB находятся в коммутационной матрице, которая задает соединения входов и выходов блоков CLB.
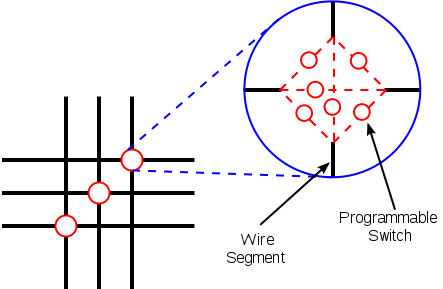
На каждом пересечении проводников находится шесть переключающих ключей, управляемых своими ячейками конфигурационной памяти. Открывая одни и закрывая другие, можно обеспечить разную коммутацию сигналов между CLB.
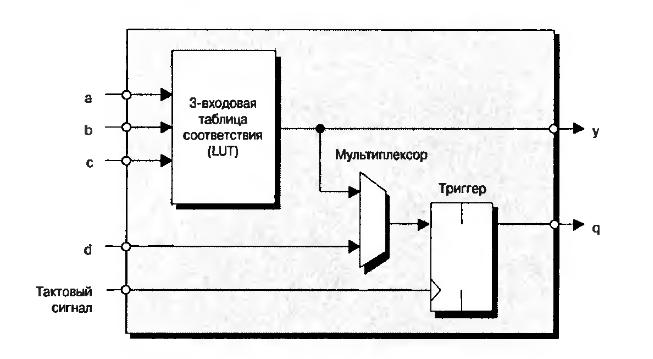
CLB очень упрощенно состоит из блока, задающего булеву функцию от нескольких аргументов (она называется таблицей соответствия — Look Up Table, LUT) и триггера (flip-flop, FF). В современных FPGA LUT имеет шесть входов, но на рисунке для простоты показаны три. Выход LUT подается на выход CLB либо асинхронно (напрямую), либо синхронно (через триггер FF, работающий на системной тактовой частоте).
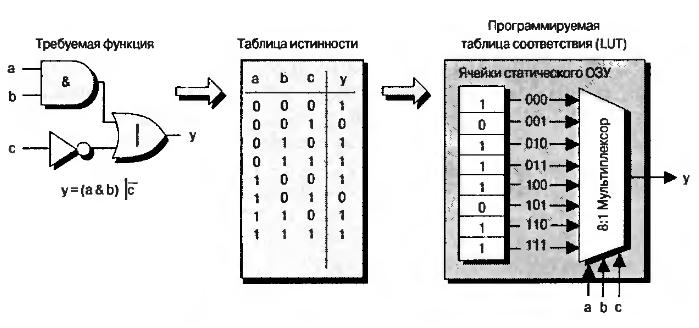
Интересно посмотреть на принцип реализации LUT. Пусть у нас есть некоторая булева функция y = (a & b) | ~ c. Ее схемотехническое представление и таблица истинности показаны на рисунке. У функции три аргумента, поэтому она принимает 2^3 = 8 значений. Каждое из них соответствует своей комбинации входных сигналов. Эти значения вычисляются программой для разработки прошивки ПЛИС и записываются в специальные ячейки конфигурационной памяти.
Значение каждой из ячеек подается на свой вход выходного мультиплексора LUT, а входные аргументы булевой функции используются для выбора того или иного значения функции. CLB — важнейший аппаратный ресурс FPGA. Количество CLB в современных кристаллах FPGA может быть разным и зависит от типа и емкости кристалла. У Xilinx есть кристаллы с количеством CLB в пределах примерно от четырех тысяч до трех миллионов.
Помимо CLB, внутри FPGA есть еще ряд важных аппаратных ресурсов. Например, аппаратные блоки умножения с накоплением или блоки DSP. Каждый из них может делать операции умножения и сложения 18-битных чисел каждый такт. В топовых кристаллах количество блоков DSP может превышать 6000.
Другой ресурс — это блоки внутренней памяти (Block RAM, BRAM). Каждый блок может хранить 2 Кбайт. Полная емкость такой памяти в зависимости от кристалла может достигать от 20 Кбайт до 20 Мбайт. Как и CLB, BRAM и DSP-блоки связаны коммутационной матрицей и пронизывают весь кристалл. Связывая блоки CLB, DSP и BRAM, можно получать весьма эффективные схемы обработки данных.
Применение и преимущества FPGA
Первый чип FPGA, созданный Xilinx в 1985 году, содержал всего 64 CLB. В то время интеграция транзисторов на микросхемах была намного ниже, чем сейчас, и в цифровых устройствах часто использовались микросхемы «рассыпной логики». Были отдельно микросхемы регистров, счетчиков, мультиплексоров, умножителей. Под конкретное устройство создавалась своя печатная плата, на которой устанавливались эти микросхемы низкой интеграции.
Использование FPGA позволило отказаться от такого подхода. Даже FPGA на 64 CLB значительно экономит место на печатной плате, а доступность реконфигурации добавила возможность обновлять функциональность устройств уже после изготовления во время эксплуатации, как говорят «in the field» (отсюда и название — field-programmable gate array).
За счет того, что внутри FPGA можно создать любую аппаратную цифровую схему (главное, чтобы хватило ресурсов), одно из важных применений ПЛИС — это прототипирование микросхем ASIC.
Разработка ASIC очень сложна и затратна, цена ошибки очень высока, и вопрос тестирования логики критичен. Поэтому одним из этапов разработки еще до начала работы над физической топологией схемы стало ее прототипирование на одном или нескольких кристаллах FPGA.
Для разработки ASIC выпускают специальные платы, содержащие много FPGA, соединенных между собой. Прототип микросхемы работает на значительно меньших частотах (может быть, десятки мегагерц), но позволяет сэкономить на выявлении проблем и багов.
Однако, на мой взгляд, существуют более интересные применения ПЛИС. Гибкая структура FPGA позволяет реализовывать аппаратные схемы для высокоскоростной и параллельной обработки данных с возможностью изменить алгоритм.

Давай подумаем, чем принципиально отличаются CPU, GPU, FPGA и ASIC. CPU универсален, на нем можно запустить любой алгоритм, он наиболее гибок, и использовать его легче всего благодаря огромному количеству языков программирования и сред разработки.
При этом из-за универсальности и последовательного выполнения инструкций CPU снижается производительность и повышается энергопотребление схемы. Происходит это потому, что на каждую полезную арифметическую операцию CPU совершает много дополнительных операций, связанных с чтением инструкций, перемещением данных между регистрами и кешем, и другие телодвижения.
На другой стороне находится ASIC. На этой платформе требуемый алгоритм реализуется аппаратно за счет прямого соединения транзисторов, все операции связаны только с выполнением алгоритма и нет никакой возможности изменить его. Отсюда максимальная производительность и наименьшее энергопотребление платформы. А вот перепрограммировать ASIC невозможно.
Справа от CPU находится GPU. Изначально эти микросхемы были разработаны для обработки графики, но сейчас используются и для майнинга вычислений общего назначения. Они состоят из тысяч небольших вычислительных ядер и выполняют параллельные операции над массивом данных.
Если алгоритм можно распараллелить, то на GPU получится добиться значительного ускорения по сравнению с CPU. С другой стороны, последовательные алгоритмы будут реализовываться хуже, поэтому платформа оказывается менее гибкой, чем CPU. Также для разработки под GPU надо иметь специальные навыки, знать OpenCL или CUDA.
Наконец, FPGA. Эта платформа сочетает эффективность ASIC с возможностью менять программу. ПЛИС не универсальны, но существует класс алгоритмов и задач, которые на них будут показывать лучшую производительность, чем на CPU и даже GPU. Сложность разработки под FPGA выше, однако новые средства разработки делают этот разрыв меньше.
Решающее же преимущество FPGA — это способность обрабатывать данные в темпе их поступления с минимальной задержкой реакции. В качестве примера можешь вообразить умный сетевой маршрутизатор с большим количеством портов: при поступлении пакета Ethernet на один из его портов необходимо проверить множество правил, прежде чем выбрать выходной порт. Возможно, потребуется изменение некоторых полей пакета или добавление новых.
Использование FPGA позволяет решать эту задачу мгновенно: байты пакета еще только начали поступать в микросхему из сетевого интерфейса, а его заголовок уже анализируется. Использование процессоров тут может существенно замедлить скорость обработки сетевого трафика. Ясно, что для маршрутизаторов можно сделать заказную микросхему ASIC, которая будет работать наиболее эффективно, но что, если правила обработки пакетов должны меняться? Достичь требуемой гибкости в сочетании с высокой производительностью поможет только FPGA.
Таким образом, FPGA используются там, где нужна высокая производительность обработки данных, наименьшее время реакции, а также низкое энергопотребление.
FPGA in the cloud
В облачных вычислениях FPGA применяются для быстрого счета, ускорения сетевого трафика и осуществления доступа к массивам данных. Сюда же можно отнести использование FPGA для высокочастотной торговли на биржах. В серверы вставляются платы FPGA с PCI Express и оптическим сетевым интерфейсом производства Intel (Altera) или Xilinx.
На FPGA отлично ложатся криптографические алгоритмы, сравнение последовательностей ДНК и научные задачи вроде молекулярной динамики. В Microsoft давно используют FPGA для ускорения поискового сервиса Bing, а также для организации Software Defined Networking внутри облака Azure.
Бум машинного обучения тоже не обошел стороной FPGA. Компании Xilinx и Intel предлагают средства на основе FPGA для работы с глубокими нейросетями. Они позволяют получать прошивки FPGA, которые реализуют ту или иную сеть напрямую из фреймворков вроде Caffe и TensorFlow.
Причем это все можно попробовать, не выходя из дома и используя облачные сервисы. Например, в Amazon можно арендовать виртуальную машину с доступом к плате FPGA и любым средствам разработки, в том числе и machine learning.
FPGA on the edge
Что еще интересное делают на FPGA? Да чего только не делают! Робототехника, беспилотные автомобили, дроны, научные приборы, медицинская техника, пользовательские мобильные устройства, умные камеры видеонаблюдения и так далее.
Традиционно FPGA применялись для цифровой обработки одномерных сигналов (и конкурировали с процессорами DSP) в устройствах радиолокации, приемопередатчиках радиосигналов. С ростом интеграции микросхем и увеличением производительности платформы FPGA стали все больше применяться для высокопроизводительных вычислений, например для обработки двумерных сигналов «на краю облака» (edge computing).
Эту концепцию легче всего понять на примере видеокамеры для анализа автомобильного трафика с функцией распознавания номеров машин. Можно взять камеру с возможностью передачи видео через Ethernet и обрабатывать поток на удаленном сервере. С ростом числа камер будет расти и нагрузка на сеть, что может привести к сбоям системы.
Вместо этого лучше реализовать распознавание номеров на вычислителе, установленном прямо в корпус видеокамеры, и передавать в облако номера машин в формате текста. Для этого даже можно взять сравнительно недорогие FPGA с низким энергопотреблением, чтобы обойтись аккумулятором. При этом остается возможность изменять логику работы FPGA, например, при изменении стандарта автомобильных номеров.
Что до робототехники и дронов, то в этой сфере как раз особенно важно выполнять два условия — высокая производительность и низкое энергопотребление. Платформа FPGA подходит как нельзя лучше и может использоваться, в частности, для создания полетных контроллеров для беспилотников. Уже сейчас делают БПЛА, которые могут принимать решения на лету.
Как разрабатывать проект на FPGA?
Существуют разные уровни проектирования: низкий, блочный и высокий. Низкий уровень предполагает использование языков типа Verilog или VHDL, на которых ты управляешь разработкой на уровне регистровых передач (RTL — register transfer level). В этом случае ты формируешь регистры, как в процессоре, и определяешь логические функции, изменяющие данные между ними.
Схемы FPGA всегда работают на определенных тактовых частотах (обычно 100–300 МГц), и на уровне RTL ты определяешь поведение схемы с точностью до такта системной частоты. Эта кропотливая работа приводит к созданию максимально эффективных схем с точки зрения производительности, потребления ресурсов кристалла FPGA и энергопотребления. Но тут требуются серьезные скиллы в схемотехнике, да и с ними процесс небыстрый.
На блочном уровне ты занимаешься в основном соединением уже готовых крупных блоков, которые выполняют определенные функции, для получения нужной тебе функциональности системы на кристалле (system-on-chip).
На высоком уровне проектирования ты уже не будешь контролировать данные на каждом такте, вместо этого сконцентрируешься на алгоритме. Существуют компиляторы или трансляторы с языков C и C++ на уровень RTL, например Vivado HLS. Он довольно умный и позволяет транслировать на аппаратный уровень широкий класс алгоритмов.
Главное преимущество такого подхода перед языками RTL — ускорение разработки и особенно тестирования алгоритма: код на C++ можно запустить и верифицировать на компьютере, и это будет намного быстрее, чем тестировать изменения алгоритма на уровне RTL. За удобство, конечно, придется заплатить — схема может получиться не такой быстрой и займет больше аппаратных ресурсов.
Часто мы готовы платить эту цену: если грамотно использовать транслятор, то эффективность не сильно пострадает, а ресурсов в современных FPGA достаточно. В нашем мире с критичным показателем time to market это оказывается оправданным.
Часто в одном дизайне нужно совместить все три стиля разработки. Допустим, нам нужно сделать устройство, которое мы могли бы встроить в робота и наделить его способностью распознавать объекты в видеопотоке — например, дорожные знаки. Возьмем микросхему видеосенсора и подключим ее напрямую к FPGA. Для отладки можем использовать монитор HDMI, тоже подключенный к FPGA.
Кадры с камеры будут передаваться в FPGA по интерфейсу, который заведомо определен производителем сенсора (USB тут не катит), обрабатываться и выводиться на монитор. Для обработки кадров понадобится фреймбуфер, который обычно находится во внешней памяти DDR, установленной на печатной плате рядом с микросхемой FPGA.
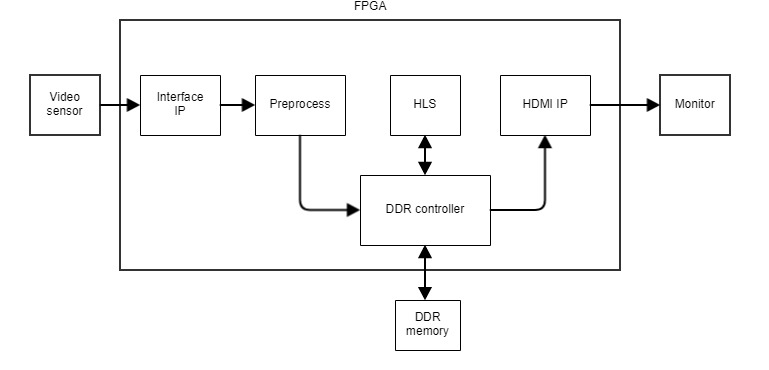
Если производитель видеосенсора не предоставляет Interface IP для нашей микросхемы FPGA, то нам придется писать его самостоятельно на языке RTL, считая такты, биты и байты в соответствии со спецификацией протокола передачи данных. Блоки Preprocess, DDR Controller и HDMI IP мы, скорее всего, возьмем готовые и просто соединим их интерфейсы. А блок HLS, который выполняет поиск и обработку поступающих данных, мы можем написать на C++ и транслировать при помощи Vivado HLS.
Скорее всего, нам еще потребуется какая-то готовая библиотека детектора и классификатора дорожных знаков, адаптированная для использования в FPGA. В этом примере я, конечно, привожу сильно упрощенную блок-схему дизайна, но логику работы она отражает корректно.
Рассмотрим путь проектирования от написания кода RTL до получения конфигурационного файла для загрузки в FPGA.
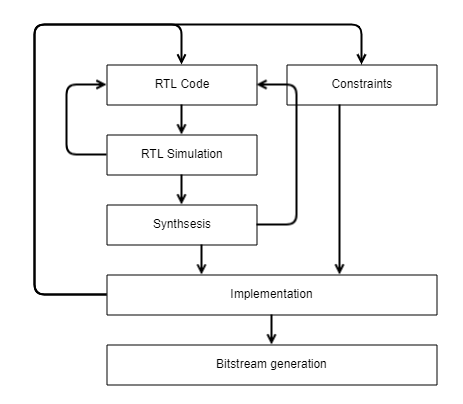
Итак, ты пишешь код RTL, который реализует нужную тебе схему. Прежде чем его проверять на реальном железе, надо убедиться, что он верный и корректно решает требуемую задачу. Для этого используется RTL-моделирование в симуляторе на компьютере.
Ты берешь свою схему, представленную пока только в коде RTL, и помещаешь ее на виртуальный стенд, где подаешь последовательности цифровых сигналов на входы схемы, регистрируешь выходные диаграммы, зависимости от времени выходных сигналов и сравниваешь с ожидаемыми результатами. Обычно ты находишь ошибки и возвращаешься к написанию RTL.
Далее логически верифицированный код подается на вход программе-синтезатору. Она преобразует текстовое описание схемы в связанный список цифровых элементов из библиотеки, доступной для данного кристалла FPGA. В этом списке будут отображены такие элементы, как LUT, триггеры, и связи между ними. На этой стадии элементы пока никак не привязаны к конкретным аппаратным ресурсам. Чтобы это сделать, требуется наложить на схему ограничения (Constraints) — в частности, указать, с какими физическими контактами ввода-вывода микросхемы FPGA связаны логические входы и выходы твоей схемы.
В этих ограничениях также требуется указать, на каких тактовых частотах должна работать схема. Выход синтезатора и файл ограничений отдаются процессору Implementation, который, помимо прочего, занимается размещением и трассировкой (Place and Route).
Процесс Place каждый пока еще обезличенный элемент из netlist привязывает к конкретному элементу внутри микросхемы FPGA. Далее начинает работу процесс Route, который пытается найти оптимальное соединение этих элементов для соответствующей конфигурации коммутационной матрицы ПЛИС.
Place и Route действуют, исходя из ограничений, наложенных нами на схему: контактами ввода-вывода и тактовой частотой. Период тактовой частоты очень сильно влияет на Implementation: он не должен быть меньше, чем временная задержка на логических элементах в критической цепи между двумя последовательными триггерами.
Часто сразу удовлетворить это требование не удается, и тогда надо вернуться на начальный этап и изменить код RTL: например, попытаться сократить логику в критической цепи. После успешного завершения Implementation нам известно, какие элементы где находятся и как они связаны.
Только после этого запускается процесс создания бинарного файла прошивки FPGA. Остается его загрузить в реальное железо и проверить, работает ли оно так, как ожидалось. Если на этом этапе возникают проблемы, значит, моделирование было неполным и на этом этапе не были устранены все ошибки и недочеты.
Можно вернуться на стадию симуляции и смоделировать нештатную ситуацию, а если и это не сработает, на крайний случай предусмотрен механизм отладки непосредственно в работающем железе. Ты можешь указать, какие сигналы хочешь отслеживать во времени, и среда разработки сгенерирует дополнительную схему логического анализатора, которая размещается на кристалле рядом с твоей разрабатываемой схемой, подключается к интересующим тебя сигналам и сохраняет их значения во времени. Сохраненные временные диаграммы нужных сигналов можно выгрузить на компьютер и проанализировать.
Существуют и высокоуровневые средства разработки (HLS, High-level synthesis), и даже готовые фреймворки для создания нейросетей в ПЛИС. Эти средства на выходе генерят код RTL на языках VHDL или Verilog, который дальше спускается по цепочке Synthesis → Implementation → Bitstream generation. Ими вполне можно пользоваться, но, чтобы использовать их эффективно, надо иметь хотя бы минимальное представление о языках уровня RTL.
Продолжение следует
Надеюсь, теория тебя не слишком загрузила! В следующей статье я расскажу о практике: мы посмотрим, что конкретно нужно делать, чтобы запрограммировать FPGA.
