

Содержание статьи
- Фундаментальные основы хакерства
- Идентификация чисто виртуальных функций
- Совместное использование виртуальной таблицы несколькими экземплярами класса
- Копии виртуальных таблиц
- Связанный список
- Вызов через шлюз
- Сложный пример наследования
- Переименование инструкций
- На заметку
- Статические объекты
- Идентификация виртуальных таблиц
- Второй вариант инициализации массива
- Заключение
Фундаментальные основы хакерства
Пятнадцать лет назад эпический труд Криса Касперски «Фундаментальные основы хакерства» был настольной книгой каждого начинающего исследователя в области компьютерной безопасности. Однако время идет, и знания, опубликованные Крисом, теряют актуальность. Редакторы «Хакера» попытались обновить этот объемный труд и перенести его из времен Windows 2000 и Visual Studio 6.0 во времена Windows 10 и Visual Studio 2019.
Ссылки на другие статьи из этого цикла ищи на странице автора.
Идентификация чисто виртуальных функций
Если функция объявляется в базовом, а реализуется в производном классе, она называется чисто виртуальной функцией, а класс, содержащий хотя бы одну такую функцию, — абстрактным классом. Язык C++ запрещает создание экземпляров абстрактного класса, да и как они могут создаваться, если по крайней мере одна из функций класса не определена?
В стародавние времена компилятор в виртуальной таблице замещал вызов чисто виртуальной функции указателем на библиотечную функцию purecall, потому что на стадии компиляции программы он не мог гарантированно отловить все попытки вызова чисто виртуальных функций. И если такой вызов происходил, управление получала заранее подставленная сюда purecall, которая «ругалась» на запрет вызова чисто виртуальных функций и завершала работу приложения.
Однако в современных реалиях дело обстоит иначе. Компилятор отлавливает вызовы чисто виртуальных функций и банит их во время компиляции. Таким образом, он даже не создает таблицы виртуальных методов для абстрактных классов.
В этом нам поможет убедиться следующий пример (листинг примера PureCall):
#include <stdio.h>
class Base {
public:
virtual void demo(void) = 0;
};
class Derived :public Base {
public:
virtual void demo(void) {
printf("DERIVED\n");
}
};
int main()
{
Base *p = new Derived;
p->demo();
delete p; // Хотя статья не о том, как писать код на C++,
// будем правильными до конца
}
Результат его компиляции в общем случае должен выглядеть так:
main proc near
push rbx
sub rsp, 20h
mov ecx, 8 ; size
; Выделение памяти для нового экземпляра объекта
call operator new(unsigned __int64)
mov rbx, rax
lea rax, const Derived::`vftable'
mov rcx, rbx ; this
mov [rbx], rax
; Вызов метода
call cs:const Derived::`vftable'
mov edx, 8 ; __formal
mov rcx, rbx ; block
; Очищаем выделенную память, попросту удаляем объект
call operator delete(void *,unsigned __int64)
xor eax, eax
add rsp, 20h
pop rbx
retn
main endp
Чтобы узнать, какой метод вызывается инструкцией call cs:const Derived::'vftable', надо сначала перейти в таблицу виртуальных методов класса Derived (нажав Enter):
const Derived::`vftable' dq offset Derived::demo(void)
а отсюда уже в сам метод:
public: virtual void Derived::demo(void) proc near
lea rcx, _Format ; "DERIVED\n"
jmp printf
public: virtual void Derived::demo(void) endp
В дизассемблерном листинге для x86 IDA сразу подставляет правильное имя вызываемого метода:
call Derived::demo(void)
Это мы выяснили. И никакого намека на purecall.
Хочу также обратить твое внимание на следующую деталь. Старые компиляторы вставляли код проверки и обработки ошибок выделения памяти непосредственно после операции выделения памяти, тогда как современные компиляторы перенесли эту заботу внутрь оператора new:
void * operator new(unsigned __int64) proc near
push rbx
sub rsp, 20h
mov rbx, rcx
jmp short loc_14000110E ; После пролога выполняется
; безусловный переход
loc_1400010FF:
mov rcx, rbx
call _callnewh_0 ; Вторая попытка выделения памяти
test eax, eax
jz short loc_14000111E ; Если память снова не удалось
; выделить — переходим в конец,
; где вызываем функции
; обработки ошибок
mov rcx, rbx ; Size
loc_14000110E:
call malloc_0 ; Первая попытка выделения памяти
test rax, rax ; Проверка успешности выделения
jz short loc_1400010FF ; Если rax == 0 — значит, произошла
; ошибка и память не выделена.
; Тогда совершаем переход
; и делаем еще попытку
add rsp, 20h
pop rbx
retn
loc_14000111E:
cmp rbx, 0FFFFFFFFFFFFFFFFh
jz short loc_14000112A
call __scrt_throw_std_bad_alloc(void)
align 2
loc_14000112A:
call __scrt_throw_std_bad_array_new_length(void)
align 10h
void * operator new(unsigned __int64) endp
После пролога функции командой jmp short loc_14000110E выполняется безусловный переход на код для выделения памяти: call malloc_0. Проверяем результат операции: test rax, rax. Если выделение памяти провалилось, переходим на метку jz short loc_1400010FF, где еще раз пытаемся зарезервировать память:
mov rcx, rbx
call _callnewh_0
test eax, eax
Если эта попытка тоже проваливается, нам ничего не остается, как перейти по метке jz short loc_14000111E, обработать ошибки и вывести соответствующее ругательство.
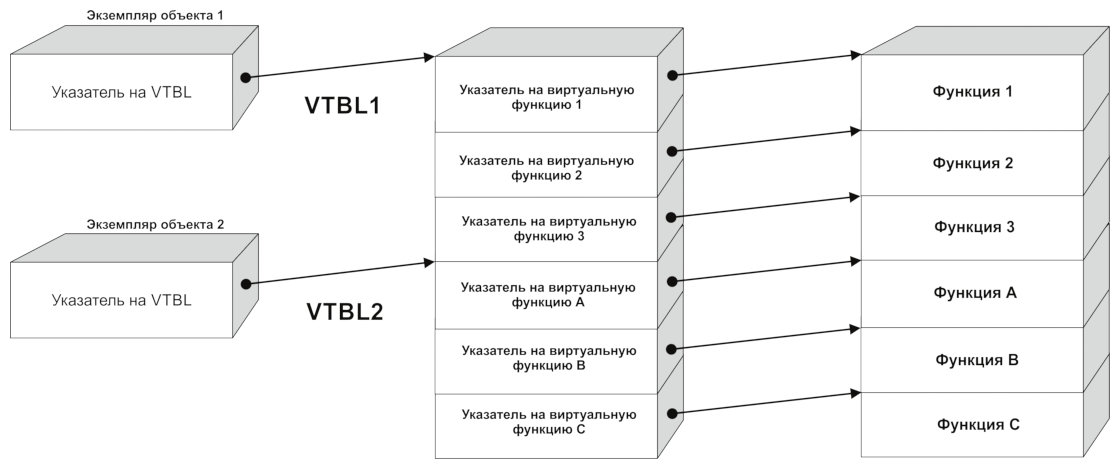
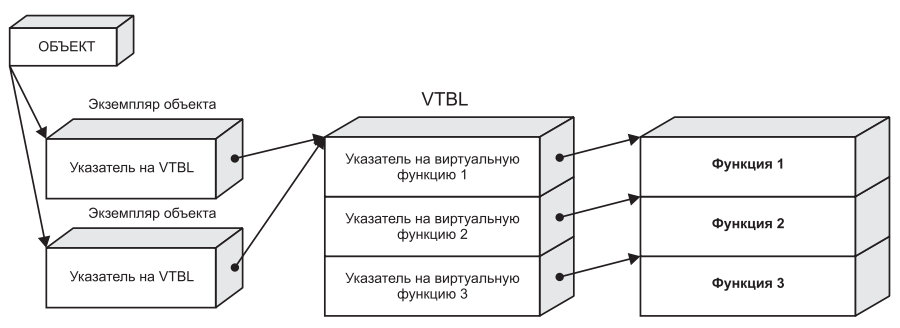
Совместное использование виртуальной таблицы несколькими экземплярами класса
Сколько бы экземпляров класса (другими словами, объектов) ни существовало, все они пользуются одной и той же виртуальной таблицей. Виртуальная таблица принадлежит самому классу, но не экземпляру (экземплярам) этого класса. Впрочем, из этого правила существуют исключения.
Для демонстрации совместного использования одной копии виртуальной таблицы несколькими экземплярами класса рассмотрим следующий пример (листинг примера UsingVT):
#include <stdio.h>
class Base {
public:
virtual void demo()
{
printf("Base\n");
}
};
class Derived : public Base {
public:
virtual void demo()
{
printf("Derived\n");
}
};
int main()
{
Base *obj1 = new Derived;
Base *obj2 = new Derived;
obj1->demo();
obj2->demo();
delete obj1;
delete obj2;
}
Результат его компиляции в общем случае должен выглядеть так:
main proc near
mov [rsp+arg_0], rbx
mov [rsp+arg_8], rsi
push rdi
sub rsp, 20h
mov ecx, 8 ; size
; Выделяем память под первый экземпляр класса
call operator new(unsigned __int64)
; В созданный объект копируем виртуальную таблицу класса Derived
lea rsi, const Derived::`vftable'
mov ecx, 8 ; size
mov rdi, rax
; RAX теперь указывает на первый экземпляр
mov [rax], rsi
; Выделяем память под второй экземпляр класса
call operator new(unsigned __int64)
; В RDI — указатель на виртуальную таблицу класса Derived
mov rcx, rdi
mov rbx, rax
; В RSI находится первый объект
mov [rax], rsi
; Берем указатель на виртуальную таблицу методов
mov r8, [rdi]
; Для первого объекта, скопированного в RAX, вызываем метод
; по указателю в виртуальной таблице
call qword ptr [r8]
; В RBX — указатель на виртуальную таблицу класса Derived
mov r8, [rbx]
mov rcx, rbx
; Вызываем метод по указателю в этой же самой таблице
call qword ptr [r8]
mov edx, 8 ; __formal
mov rcx, rdi ; block
call operator delete(void *,unsigned __int64)
mov edx, 8 ; __formal
mov rcx, rbx ; block
call operator delete(void *,unsigned __int64)
mov rbx, [rsp+28h+arg_0]
xor eax, eax
mov rsi, [rsp+28h+arg_8]
add rsp, 20h
pop rdi
retn
main endp
Виртуальная таблица класса Derived выглядит так:
const Derived::`vftable' dq offset Derived::demo(void), 0
Обрати внимание: виртуальная таблица одна на все экземпляры класса.
Копии виртуальных таблиц
Окей, для успешной работы, понятное дело, вполне достаточно и одной виртуальной таблицы, однако на практике приходится сталкиваться с тем, что исследуемый файл прямо-таки кишит копиями этих виртуальных таблиц. Что же это за напасть такая, откуда она берется и как с ней бороться?
Если программа состоит из нескольких файлов, компилируемых в самостоятельные obj-модули (а такой подход используется практически во всех мало-мальски серьезных проектах), компилятор, очевидно, должен поместить в каждый obj свою собственную виртуальную таблицу для каждого используемого модулем класса. В самом деле, откуда компилятору знать о существовании других obj и наличии в них виртуальных таблиц?
Вот так и возникают никому не нужные дубли, отъедающие память и затрудняющие анализ. Правда, на этапе компоновки линкер может обнаружить копии и удалить их, да и сами компиляторы используют различные эвристические приемы для повышения эффективности генерируемого кода. Наибольшую популярность завоевал следующий алгоритм: виртуальная таблица помещается в тот модуль, в котором содержится реализация первой невстроенной невиртуальной функции класса.
Обычно каждый класс реализуется в одном модуле, и в большинстве случаев такая эвристика срабатывает. Хуже, если класс состоит из одних виртуальных или встраиваемых функций. В этом случае компилятор «ложится» и начинает запихивать виртуальные таблицы во все модули, где этот класс используется. Последняя надежда на удаление «мусорных» копий — линкер, но и он не панацея. Собственно, эти проблемы должны больше заботить разработчиков программы (если их волнует, сколько памяти занимает программа), для анализа лишние копии всего лишь досадная помеха, но отнюдь не непреодолимое препятствие!
Связанный список
В большинстве случаев виртуальная таблица — это обыкновенный массив, но некоторые компиляторы представляют ее в виде связанного списка. Каждый элемент виртуальной таблицы содержит указатель на следующий элемент, а сами элементы не размещены вплотную друг к другу, а рассеяны по всему исполняемому файлу.
На практике подобное, однако, попадается крайне редко, поэтому не будем подробно на этом останавливаться — достаточно лишь знать, что такое бывает. Если ты встретишься со списками (впрочем, это вряд ли) — разберешься по обстоятельствам, благо это несложно.
Вызов через шлюз
Будь также готов и к тому, чтобы встретить в виртуальной таблице указатель не на виртуальную функцию, а на код, который модифицирует этот указатель, занося в него смещение вызываемой функции. Этот прием был предложен самим разработчиком языка C++ Бьерном Страуструпом, позаимствовавшим его из ранних реализаций алгола-60. В алголе код, корректирующий указатель вызываемой функции, называется шлюзом (thunk), а сам вызов — вызовом через шлюз. Вполне справедливо употреблять эту терминологию и по отношению к C++.
Однако в настоящее время вызов через шлюз чрезвычайно мало распространен и не используется практически ни одним компилятором. Несмотря на то что он обеспечивает более компактное хранение виртуальных таблиц, модификация указателя приводит к излишним накладным расходам на процессорах с конвейерной архитектурой (а все современные процессоры как раз и построены на основе такой архитектуры). Поэтому использование шлюзовых вызовов оправданно лишь в программах, критических к размеру, но не к скорости.
Подробнее обо всем этом можно прочесть в руководстве по алголу-60 (шутка) или у Бьерна Страуструпа в «Дизайне и эволюции языка C++».
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Вариант 2. Открой один материал
Заинтересовала статья, но нет возможности стать членом клуба «Xakep.ru»? Тогда этот вариант для тебя! Обрати внимание: этот способ подходит только для статей, опубликованных более двух месяцев назад.
Я уже участник «Xakep.ru»
