Содержание статьи
Вытащить из системы пароль от локальной учетки
РЕШЕНИЕ: Как же давно я не писал о такой прекрасной виндовой фиче, как групповые политики! Тема их обхода стала особенно актуальной после появления исследования секьюрити-группы ESEC.
Warning!
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
Для начала давай уточним задачу. Итак, на гипотетической рабочей станции нам нужно вытащить и расшифровать пароль от локальной учетной записи, которая была создана при помощи групповых политик. Если я не ошибаюсь, то начиная с Windows Server 2008 Microsoft ввела специальное расширение для локальных политик под названием Group Policy Preferences (GPP). В Windows Vista и Windows 7 локальные политики поддерживаются нативно, а вот для XP потребуется поставить специальное обновление. Так вот, одной из добавленных функций была возможность создавать локальные учетные записи для группы доменных хостов. Функция, безусловно, полезная, и, как уверяют люди из ESEC, часто используемая администраторами. Вот такие учетки мы и научимся доставать.
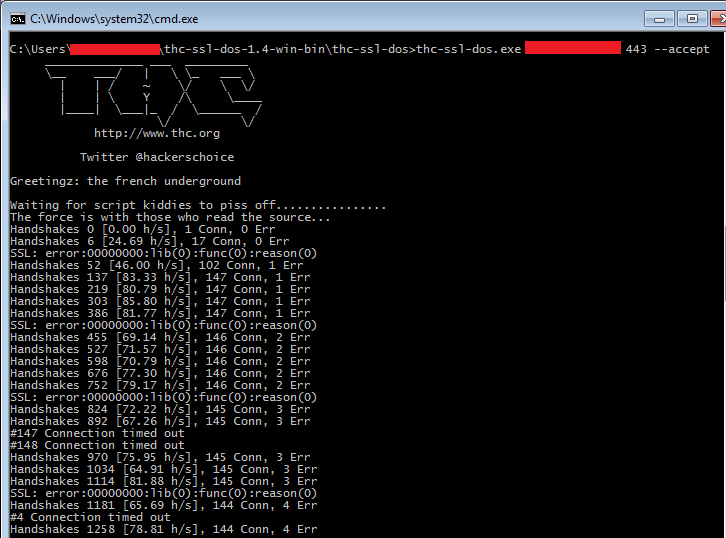
Теперь давай посмотрим, где же эти учетки создаются. Для этого мы должны найти на контроллере домена раздел «Group Policy Management» (gpmc.msc). В нем создаем новую политику, а затем в «Local Users and Groups» ветки «Computer Configuration» — нового пользователя. В процессе создания мы указываем пароль и задаем другие стандартные настройки аккаунта. После этого при обновлении политик на доменных хостах наш пользователь будет успешно создан.
Дальше ребята из ESEC посмотрели, как все происходит изнутри, и как данные о групповых политиках передаются с контроллера на хосты. Итог оказался вполне предсказуемым.
При обновлении политик доменный хост залезал на шару SYSVOL-домена и скачивал XML-файл c политикой. В нем как раз и находились имя пользователя и пароль. В общем, все стандартно. Пример такого файла:
<?xml version="1.0" encoding="utf-8"?>
<Groups clsid="{3125E937-EB16-4b4c-9934-544FC6D24D26}">
<User clsid="{DF5F1855-51E5-4d24-8B1A-D9BDE98BA1D1}"
name="MyLocalUser" image="0" changed="2011-12-26 10:21:37"
uid="{A5E3F388-299C-41D2-B937-DD5E638696FF}">
<Properties action="C" fullName="" description=""
cpassword="j1Uyj3Vx8TY9LtLZil2uAuZkFQA/4latT76ZwgdHdhw"
changeLogon="0" noChange="0" neverExpires="0" acctDisabled="0"
subAuthority="" userName="MyLocalUser" />
</User>
</Groups>
Здесь необходимо уточнить еще несколько моментов. Во-первых, данный файл доступен всем доменным пользователям, даже непривилегированным. Во-вторых, пароль расшифровать очень просто, ведь хотя и используется AES 256, но вот ключ прошит в самой ОС, то есть известен априори. На нашем диске ты сможешь найти питоновский скрипт для расшифровки таких паролей.
За остальными подробностями советую обратиться к оригинальному исследованию ESEC. Хотя оно и не является исследованием в своем первоначальном смысле (это скорее доведение до хакерских масс официально описанной фичи), Microsoft в описании GP четко предупреждает, что данные в GPP передаются в незащищенном виде.
И что использовать функционал требуется с большой осторожностью, особенно при создании привилегированных учеток в ОС.

Хакер #159. Подделка контрольной суммы и ЭЦП с помощью коллизий

Получить список хостов или DNS Zone Transfer
РЕШЕНИЕ: При проведении любого ИБ-исследования в первую очередь нам требуется ответить на вопрос «а кого же атаковать»? Это важно, так как практически любая атака чаще всего проводится против какой-то организации, у которой может быть очень много ресурсов. А нам необходимо определить среди них самое слабое звено или наиболее критичный ресурс. DNS-имя хоста может дать приличный профит в этом смысле, так как зачастую оно отражает свой функциональный смысл. Например, в корпоративных сетях вполне могут присутствовать такие имена как «buhgal» или «bank», до которых тебе, конечно же, захочется добраться. Как пример, для веба можно взять поиск «скрытых» доменов вроде admin.example.com.
Одним из простейших методов определения имен хостов является обратный DNS-запрос (reverse), когда мы запрашиваем у DNS-сервера имена хостов на основании их IP-адресов. Однако для корпоративок этот метод шумноват, так как необходимо запрашивать имена для всех хостов по очереди, а для веба он не совсем оправдан, — домены могут находиться не на смежных IP-адресах. Но если нам повезет, и DNS-сервер не совсем корректно настроен, то мы сможем получить всю необходимую информацию разом. Да-да, я говорю про DNS Zone Transfer. Для тех, кто не в курсе, эта документированная функция DNS предназначена для того, чтобы делиться своими записями о зоне. При корректной настройке Zone Transfer должен быть разрешен с первичного DNS-сервера только на вторичный, но об этом часто забывают.
Итак, чтобы получить зону, нам требуется подключиться к 53 порту DNS-сервера по протоколу TCP и создать AXFR-запрос. Практически это можно выполнить, используя только функционал стандартной виндовой команды nslookup, но практичней всего будет использование Nmap.
nmap --script dns-zone-transfer.nse \
--script-args dns-zone-transfer.domain=<domain>
Но все это классика. Приведу в пример небольшое исследование, проведенное небезызвестным экспертом HD Moore. Он просканировал основные DNS-серверы от их TLD (top-level-domain: .net, .org, .и так далее) и вывел, что многие из них разрешают проводить zone transfer. Если точнее, то 65 из 312 TLD позволяют получить все свои записи. Жаль, конечно, что в этом списке отсутствуют .com и .ru, но все равно приятно. Полученный им список на 250 заархивированных мегабайт можно получить по ссылке. Но давай попробуем собрать такой список сами:
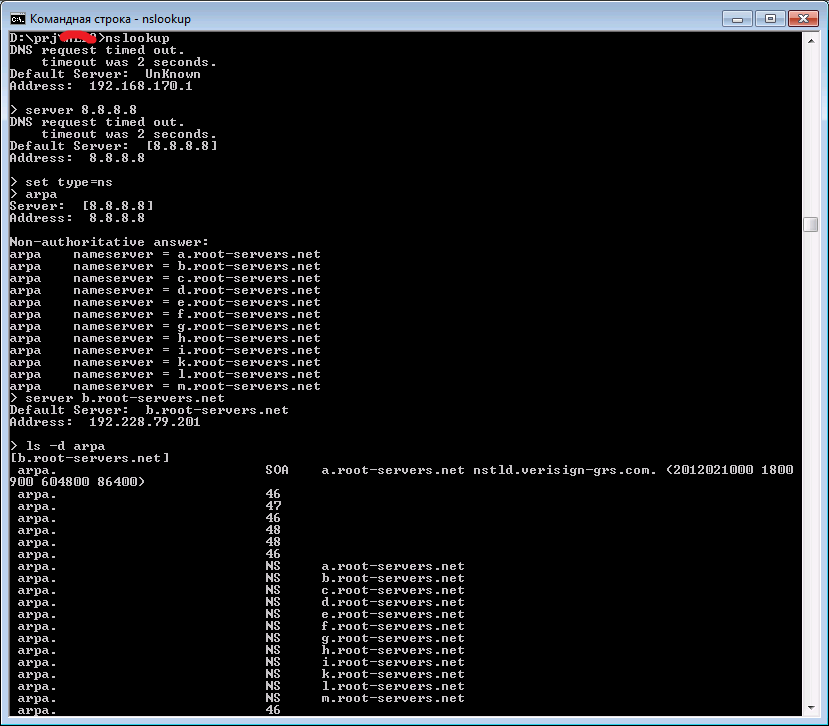
- Используем стандартную команду nslookup.
- Выбираем DNS-сервер от Гугла: server 8.8.8.8.
- Выставляем тип искомых записей: Set type=NS.
- Делаем запрос на домен arpa и получаем обслуживающие его DNS-серверы: arpa.
- Подключаемся к одному из DNS-серверов в списке: server b.root-servers.net.
- Трансферим зону для указанного домена: ls –d arpa.
Конечно, arpa – это так, для забавы, много интересной информации мы не получим. Но общая идея, думаю, понятна.
Просмотреть листинг файлов в Apache
РЕШЕНИЕ: Для начала давай представим себе ситуацию, что мы исследуем какой-то сайт. На этом сайте крутится Apache. Первым делом желательно понять, какой же движок используется нашим ресурсом.
Если точно определить CMS, то, используя общеизвестные уязвимости, произвести взлом будет очень просто. Но если это что-то нестандартное и без доступных исходников, то могут возникнуть проблемы. Хотя многое зависит от самого приложения. В любом случае я не думаю, что нужно сразу же погружаться в дебри взлома, стоит еще немного пособирать информацию. Что мы ищем? Любые полезные нам данные. Например, исходники, файлы бэкапов, конфиги. Как искать?
Первым делом желательно проверить возможность листинга директорий на сервере, и, если она присутствует, мы сразу поймем, что можем получить. Например, на одном из сайтов, с которыми я когда-то имел дело, как раз присутствовал такой листинг, а в самом приложении, как оказалось, находилось всего пара php-скриптов, которые просто подгружали остальной функционал из inc-файлов. Так как файлы типа inc Apache не считает какими-то особенными и позволяет их спокойно скачивать, то я быстро и легко получил почти все исходники сайта. Но так везет не всегда. А что делать, если листинга нет? Классика пентеста – это брутфорс по словарю. Некогда я писал об этом и упоминал тулзу DirBuster. Но брутфорс — штука грубая, хотя и вполне рабочая.
Но давай ближе к теме. Всем известный веб-сервер Apache содержит интересный модуль под названием mod_negatiation. Данное расширение чаще всего включено по дефолту. Если говорить по-простому, то отвечает оно за «умную отдачу контента». То есть, если пользователь запрашивает какой-то ресурс (страницу), то ему будет отдаваться страница, которая подходит больше всего. Например, если на сервере хранится пара файлов foo.htm.en и foo.htm.de, то по запросу /foo.htm будет отдан тот, который совпадает с пришедшим от клиента заголовком «Accept-Language».
Но еще более интересным является поведение модуля с использованием параметра MultiViews. Если он включен, то при тестовом запросе «foo» Apache проводит поиск в данной директории по маске «foo.*», а потом отдает пользователю «наилучший вариант».
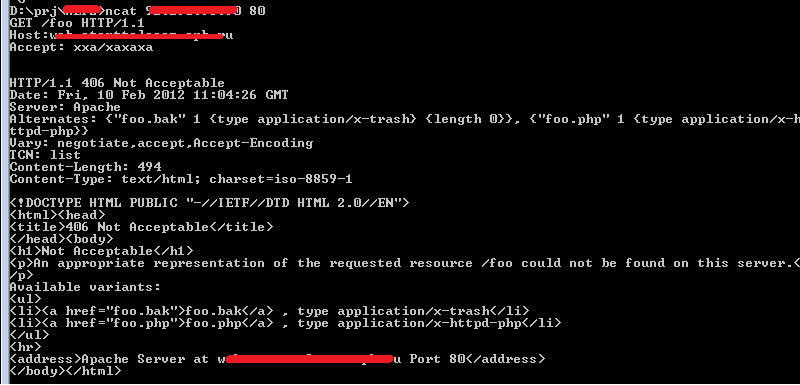
Включение MultiViews производится за счет записи строки Options MutiViews в секции виртуальных хостов или конкретных директорий. Хорошо, но что это нам дает? Тебе ответит ИБ-исследователь Стефано Ди Паола (Stefano Di Paola, goo.gl/ly8HK): частичный листинг файлов. Как? Все очень просто. В 2007 году Стефано помучал данный функционал и выявил, что при установке некорректного заголовка «Accept» при запросе к серверу последний с помощью логики mod_negatiation вернет нам список всех файлов с запрашиваемым именем, так как не сможет выбрать «лучший вариант». Смотри, если мы запрашиваем файл foo без расширения, но с заголовком «Accept», то нам вернется «наилучший» вариант:
Запрос
GET /foo HTTP/1.1
Accept: */*
Ответ
HTTP/1.1 200 OK
Server: Apache/2.0.55
Content-Location: foo.php
Vary: negotiate,accept
TCN: choice
A если мы запрашиваем то же самое, но с некорректным заголовком «Accept», то нам вернется практически полноценный листинг:
Запрос
GET /foo HTTP/1.1
Accept:/blabla
Ответ
HTTP/1.1 406 Not Acceptable
Server: Apache/2.0.55
Alternates: {"foo.bak" 1 {type application/x-trash} {length 3}},
{"foo.php" 1 {type application/x-httpd-php} {length 3}}
Vary: negotiate,accept
TCN: list
Что это может дать? Конечно, все сильно зависит от ситуации, но в основном это попытка добраться до бэкапов. Кстати, ситуации, когда файлы бэкапов хранятся рядом, случаются очень часто, – многие программы автоматом создают их при редактировании основных файлов. Важным ограничением способа является то, что в вывод веб-сервера попадают только те файлы, чье расширение присутствует в конфиге апача (AddType). То есть файл с расширением .php~ в листинг, к сожалению, не попадет.
Думаю, здесь важно подчеркнуть, что описанное выше поведение Apache — нормально. То есть разработчики не собираются менять его. И как уже было сказано выше, это свойственно всем основным веткам Apache. Хотя данная фича в любом случае не избавляет нас от необходимости перебора, но мы вполне можем воспользоваться уже имеющимися данными (именами страниц) и не перебирать вслепую.
В Metasploit присутствует соответствующий модуль (auxiliary/scanner/http/modnegotiationbrute), проводящий брутфорс с учетом этой фичи, да и сканер от Acunetix имеет аналогичный функционал. В качестве простейшего примера – чекер mod_negotiation с использованием nmap:
nmap --script=http-apache-negotiation –p80 –sV
Выполнить действия от имени пользователя в какой-либо CMS
РЕШЕНИЕ: Для начала давай расширим задачу. Есть пользователь, залогинившийся в какую-нибудь веб-систему (например в админку). Есть хакеры, которые хотят получить привилегированный доступ в эту систему. Для приличия добавим возможность подсунуть этому пользователю произвольную ссылку или проснифать его незашифрованный трафик (хотя сама админка будет находиться за https’ом). Самый простой и действенный способ — это, наверное, CSRF:
https://victim.com/admin.php?adduser=1&user=hacker&password=hacker
Если мы заставим браузер перейти по этой ссылке, то в системе будет создан новый пользователь. Но это возможно только в том случае, если веб-приложение уязвимо к таким атакам. К счастью, во все большее количество ПО внедряются всяческие механизмы защиты от CSRF. Самый распространенный – токены. К каждому запросу на странице добавляется токен, который действителен только для одного запроса. Таким образом мы получаем ссылку вида
https://victim.com/admin.php?adduser=1&user=hacker&password=hacker
&token=long_random_bukva_cifra
Да, CSRF уже не прокатит. Что дальше? Конечно же, XSS. С помощью этого вида атак мы сможем загрузить нужную страницу, вынуть токен и создать ядовитый запрос (плюс много еще всякого страшного). Но у XSS есть пара проблемных моментов. Хотя они и являются самым распространенным видом багов на сегодняшний день, но в основном это касается reflected XSS (то есть когда код попадает из запроса), ведь stored XSS (когда мы можем добавить контент в страницу) бывает не часто. Но во многие браузеры нативно или с помощью плагинов встроена хорошая защита от reflected XSS. Классический пример – IE. И здесь без извращений и/или социальной инженерии защиту не обойти.
Давай посмотрим, можем ли мы сделать что-то еще? Ответ – flash. У него есть несколько плюсов. Во-первых, сейчас он стоит по дефолту на всех компьютерах (привет яблочникам :). А во-вторых, предоставляет много возможностей по взаимодействию с сетью. В самом простом виде атака с использованием flash будет иметь следующий вид. Есть evil.com – хост атакующего со специальной флэшкой, и есть victim.com с нужными нам данными. Когда юзер зайдет к нам на evil.com, флэш автоматически запустится и выполнит загрузку страницы с victim.com, причем используя родные кукисы пользователя! Далее все стандартно, – из страницы достаем токен, подставляем его в запрос и выполняем.
Все круто? Как бы ни так. Здесь нам мешают same origin policies. Ведь evil.com – один домен, victim.com – другой, а следовательно взаимодействие по флэшу запрещено. Однако существует и вполне легальный способ, разрешающий такое «общение», — это файл crossdomain.xml. В нем указывается, что можно делать флэшу. Он должен быть расположен в самом корне сервера victim.com. Таким образом, когда флэш-ролик пытается прочитать страничку с victim.com, флэш сначала читает victim.com/crossdomain.xml и на основе него уже делает вывод, разрешено ли подключаться к этой странице. В настоящий момент флэш поддерживает целый набор ограничений. Я не буду описывать все, коснусь лишь основных, общая спецификация от adobe находится по адресу goo.gl/A02R1. Вот пример:
<?xml version="1.0"?>
<!DOCTYPE cross-domain-policy SYSTEM
"http://www.adobe.com/xml/dtds/cross-domain-policy.dtd">
<cross-domain-policy>
<site-control permitted-cross-domain-policies="master-only"/>
<allow-access-from domain="*.victim.com" secure="false"/>
<allow-access-from domain="www.microsoft.com"/>
</cross-domain-policy>
Поясню некоторые моменты. Главный пункт здесь, конечно же, это allow-access-from, указывающий на то, с каких серверов доступ разрешен. Здесь это любые поддомены victim.com и один — Microsoft. Master-only указывает на то, что используется только crossdomain.xml, лежащий в корне, хотя есть и другие варианты, но об этом дальше. Вот теперь у нас появляется возможность для маневров. Например, с помощью DNS или NBNS-spoofing мы можем представиться одним из поддоменов victim.com и получить, таким образом, возможность использовать флэш на полную. Кроме того, мы можем искать уязвимости уже во всех этих доменах и через них атаковать пользователей victim.com.
Далее нам интересен атрибут secure (по-дефолту «true»), указывающий на то, нужно ли флэшу обращаться к данному хосту только c https. То есть в данном случае (false) мы можем провести на victim.com атаку Man-in-the-middle, а затем внедрить нашу флэшку в HTTP-ответ от сервера. Получается, флэшке будет разрешено «общаться» и с https'ом этого домена.
Также хочу добавить еще несколько важных замечаний. Во-первых, когда флэш-ролик отправляет куда-либо запрос, то в качестве его родного домена определяется то место, где он хостится фактически, а не то, где он вставлен в страницу. Во-вторых, при отсутствии crossdomain.xml флэшу на самом деле не «запрещается все», как считают многие. В таком случае флэшу можно указать альтернативный файл политик, называющийся по-другому и лежащий на victim.com. В-третьих, файлы crossdomain.xml могут лежать и в папках. Но должно быть разрешение от корневого файла (значение директивы «site-control» находится не в положении «master-only»), а доступ флэш-ролику будет разрешен только в данную директорию или ее поддиректории. Таким образом, у нас есть небольшая возможность либо найти альтернативные файлы на victim.com, либо залить xml’ку.
Кстати, наиболее простым и частым багом здесь является неправильное использование директивы <allow-access-from domain="* ">. В данном случае мы можем обращаться к жертве с любого из хостов, а также производить почти любые действия от чужого имени. Много ли таких сайтов? Прилично. Подробности смотри в научной работе про анализ Alexa Top 50 000 от наших коллег из Сан-Диего (goo.gl/rlCL1).
Еще хотелось бы вспомнить про такую альтернативу флэшу как Silverlight от Microsoft. У них почти аналогичная система кроссдоменного взаимодействия, только с несколькими отличиями. Файл политик называется clientaccesspolicy.xml, однако если Silverlight его не находит, то ищется crossdomain.xml. Сам же clientaccesspolicy.xml не поддерживает использование символа множества («*») для описания доменов и не различает http- и https-протоколы. Так что через него также можно выполнять действия от имени пользователя, если только повезет с xml’ками.
Обойти флаг cookies HttpOnly
РЕШЕНИЕ: XSS – это одна из самых распространенных ныне уязвимостей веб-приложений. К тому же она очень опасна, потому что по сути мы можем выполнять почти любые действия от имени пользователя. Но если все же вернуться к классике, то итогом XSS должна быть украденная сессия пользователя. Так как чаще всего авторизация юзера происходит именно по кукисам, то целью атаки с использованием XSS является их угон. Чаще всего это можно сделать с помощью данных из переменной document.cookie. Но все несколько затруднилось, когда появился такой чудо-браузер, как IE6. Разработчики внедрили в него специальный флаг httpOnly. Основная его задача заключается в том, чтобы указать браузеру, что данную куку нельзя доставать из javascript. Ага, идея хорошая. Вот только с реализацией не так все здорово, ведь по идее флаг должны выставлять сами разработчики ПО, которые до сих пор этим пренебрегают.
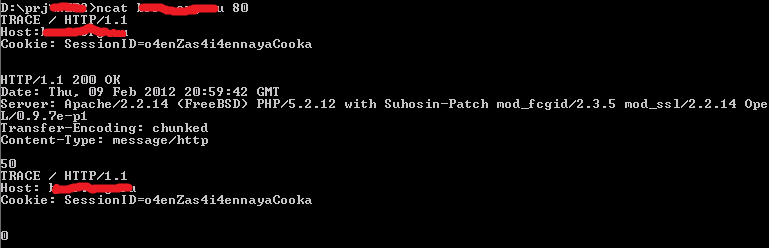
Теперь давай предположим, что «httpOnly» установлен. Как его обойти? Бородатый метод – cross-site tracing. Придуман он аж в 2003 году и основан на том, что многие веб-серверы наряду с GET- и POST-методами поддерживают еще и TRACE-метод. Данный метод крайне прост: веб-сервер возвращает полностью весь запрос, который был отправлен клиентом. То есть получается так: мы должны внедрить через XSS такой код, который должен будет отправить любой запрос на тот же сервер с методом TRACE, а затем прочитать пришедший ответ. В этом ответе кроме искомых кукисов могут содержаться и другие интересные данные (basic или ntlm-аутентификация). Важно упомянуть, что многие веб-серверы до сих пор поддерживают данный метод.
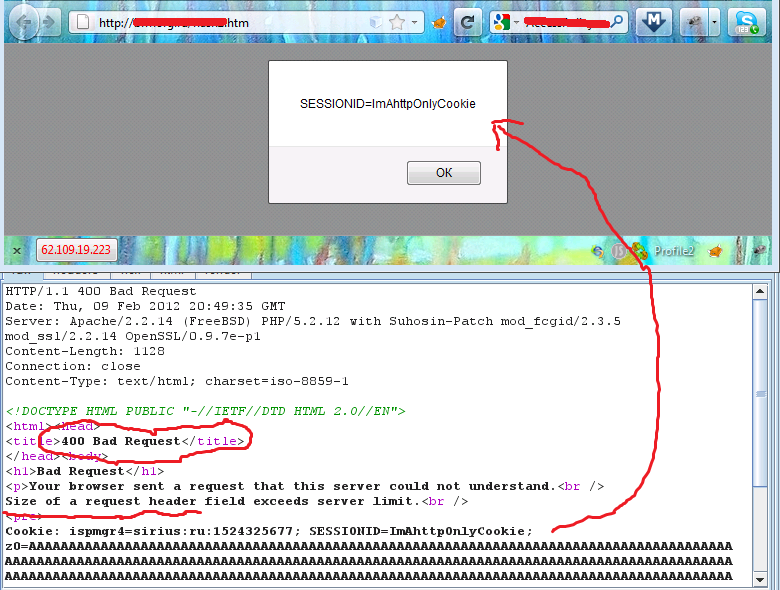
Кроме всего этого существуют также и несколько зависимых от сервера возможностей. Новым и крайне забавным примером является Apache. Если точнее, то вся его ветка 2.2 вплоть до версии 2.2.22. Логика здесь такая же, как и в случае с TRACE, только куки возвращаются в ответе об ошибке веб-сервера. Норман Хипперт (Norman Hippert, goo.gl/ndGpv) обнаружил, что при ошибке 400 (HTTP 400 Bad Request) возвращается весь отправленный клиентом запрос. Чтобы создать такой запрос, требуется всего лишь отправить легитимный пакет с очень большим заголовком. В PoC’е автора используется простейшая реализация этого бага: с помощью javascript он выставляет большое количество длинных кукисов и отправляет запрос на сервер.