Содержание статьи
Весь мир еще не успел отойти от BEAST и Padding Oracle Attack на .NET Framework, как пара исследователей обнаружила уязвимость в механизме XML Encryption, применяемом для шифрования XML-контента. На этот раз всему виной снова стал многострадальный режим шифрования CBC и неправильная обработка ошибок приложениями.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.WWW
www.w3.org/TR/xmlenc-core/ — спецификация XML Encryption на официальном сайте W3C.bit.ly/qMupEv — оригинальная статья исследователей, обнаруживших уязвимость в XML Encryption.
XML ENCRYPTION
Технология XML Encryption, стандартизованная W3C в 2002 году, в настоящее время широко используется в различных XML Framework’ах (этот стандарт поддерживают .NET, Apache Axis2, JBOSS и т. д.). Сегодня она активно применяется для защиты коммуникаций между веб-сервисами в продуктах многих компаний, в частности Microsoft и Red Hat. На техническом уровне спецификация XML Encryption точно описывает синтаксис криптографических алгоритмов, разработанных для произвольных XML-структурированных данных, — шифрования, дешифрования и восстановления измененной части XML-документа — и порядок их применения. Стандарт не определяет никаких новых криптографических алгоритмов, а предписывает использовать уже существующие. В случае блочных шифров стандарт не оставляет нам другого выбора, кроме AES и 3DES в режиме CBC. Далее я буду все описывать на примере шифра AES (хотя для понимания сути уязвимости это не принципиально, главное — режим CBC).
ВЕБ-СЛУЖБЫ
Веб-служба — это метод взаимодействия между двумя электронными устройствами через сеть передачи данных. W3C определяет web-service как программную систему, спроектированную для поддержки интероперабельности machine-to-machine-взаимодействия. Интероперабельность подразумевает открытость интерфейсов и способность взаимодействовать с другими продуктами без каких-либо ограничений доступа и реализации. Зачастую интерфейсы взаимодействия описываются на специальном языке WSDL (Web Services Description Language), в основе которого лежит XML. Веб-сервисы представляют собой наборы инструментов, к наиболее популярным способам использования которых относятся RPC (Remote procedure calls, основная единица взаимодействия — вызов удаленной функции или метода), SOA (Service-oriented architecture, основная единица взаимодействия — сообщение) и REST (Representational state transfer). В последнем случае основными единицами взаимодействия являются операции типа GET, POST, PUT, DELETE и т. д. в протоколах типа HTTP, которые не поддерживают состояния.
МАТЧАСТЬ
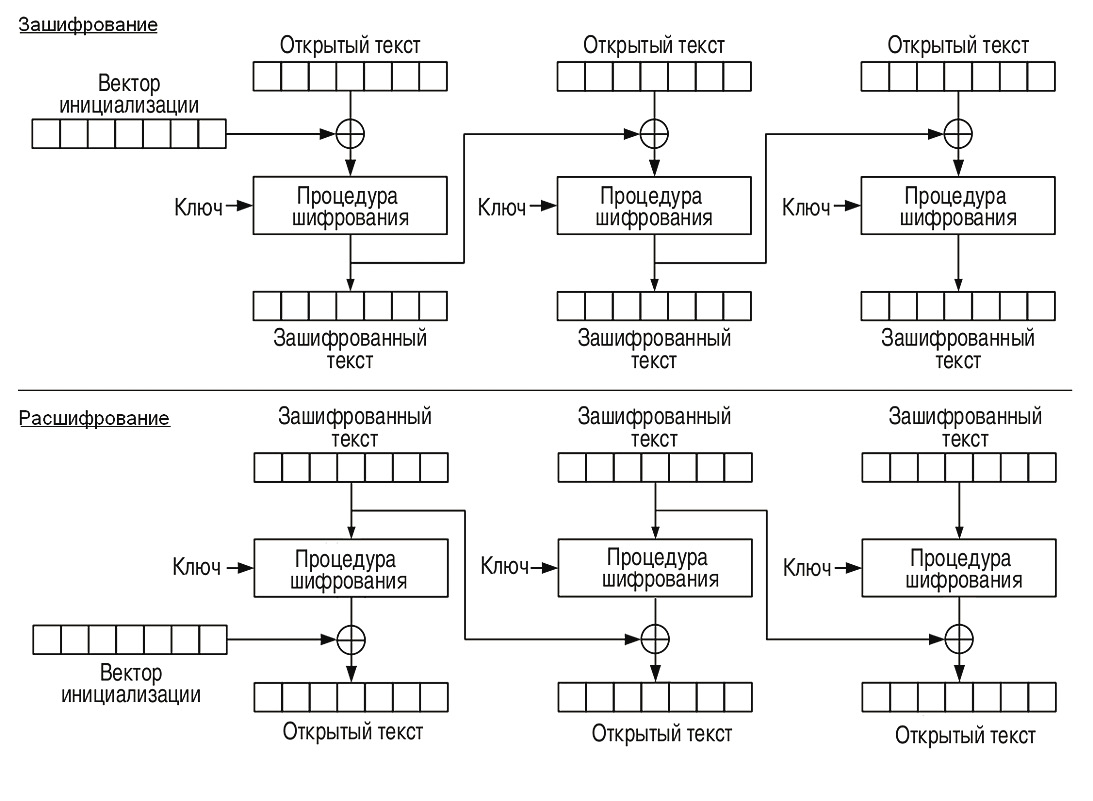
Известно, что блочный шифр преобразует блок открытого текста (обычно длиной 16 байт, то есть 128 бит) в блок шифрованного текста. Если данные занимают больше одного блока, приходится использовать алгоритмы, самым популярным из которых на сегодня является CBC. Принцип его работы легко понять из первой иллюстрации. Для первого блока открытого текста случайно выбирается вектор инициализации (IV), а затем над этим вектором и первым блоком открытого текста выполняется операция XOR, результат которой шифруется с помощью блочного алгоритма. В качестве вектора инициализации для последующих блоков открытого текста используется предыдущий блок шифрованного текста, то есть весь процесс шифрования и дешифрования описывается следующим псевдокодом:
//Шифрование
C[0] = AES_ENC(k, IV xor M[0]);
C[i] = AES_ENC(k, C[i-1] xor M[i]);
//Дешифрование
M[0] = AES_DEC(k, C[0]) xor IV;
M[i] = AES_DEC(k, C[i]) xor C[i-1];
Здесь k — ключ, С — шифротекст, М — открытый текст, IV — вектор инициализации (синхропосылка).
Стандарт не только предписывает использовать режим шифрования CBC, но и определяет схему дополнения данных до полного блока.

Хакер #156. Взлом XML Encryption
Суть этой схемы, в которой также нет ничего сложного, такова: неполный блок с помощью произвольных значений дополняется до полного, а в его последний байт вписывается количество этих произвольных значений. Так, если последний блок содержит всего три байта, то мы добавляем 12 произвольных байт и один байт со значением 0x05. Если же последний блок полон (содержит 16 байт), то мы цепляем к нему еще один блок, 15 байт которого задаются произвольно, а 16-й имеет значение 0x10.
ОСНОВНАЯ ИДЕЯ АТАКИ
Прежде чем переходить к рассмотрению практических случаев, я опишу основную идею атаки на XML Encryption. Как ты уже догадался, ее не просто так ставят в один ряд с BEAST и Padding Oracle Attack. В данном случае атака также строится на передаче атакуемому серверу специально сформированных запросов и анализе получаемых сообщений об ошибках. Перейдем к делу. Основной недостаток режима шифрования CBC состоит в том, что изменение шифрованного текста влияет на открытый текст, то есть если применить XOR к вектору инициализации IV и произвольной битовой маске MSK, то шифротекст (IV xor MSK, C[0]) будет соответствовать сообщению M[0] xor MSK. Как видишь, зависимость в данном случае очень проста.
Чтобы осуществить предлагаемую атаку, нужно изменить шифрованный текст с помощью маски MSK, передать измененное сообщение на удаленный сервер и проанализировать сообщение об ошибке, которое позволяет узнать дополнительную информацию об открытом тексте. Таким образом, получается этакий побочный канал для получения конфиденциальной информации.
Для начала давай разберемся с простеньким примером атаки, который показывает, как получить открытый текст зашифрованного сообщения. Атака на XML Encryption основана именно на этой идее, которая слегка адаптирована к «реальному миру».
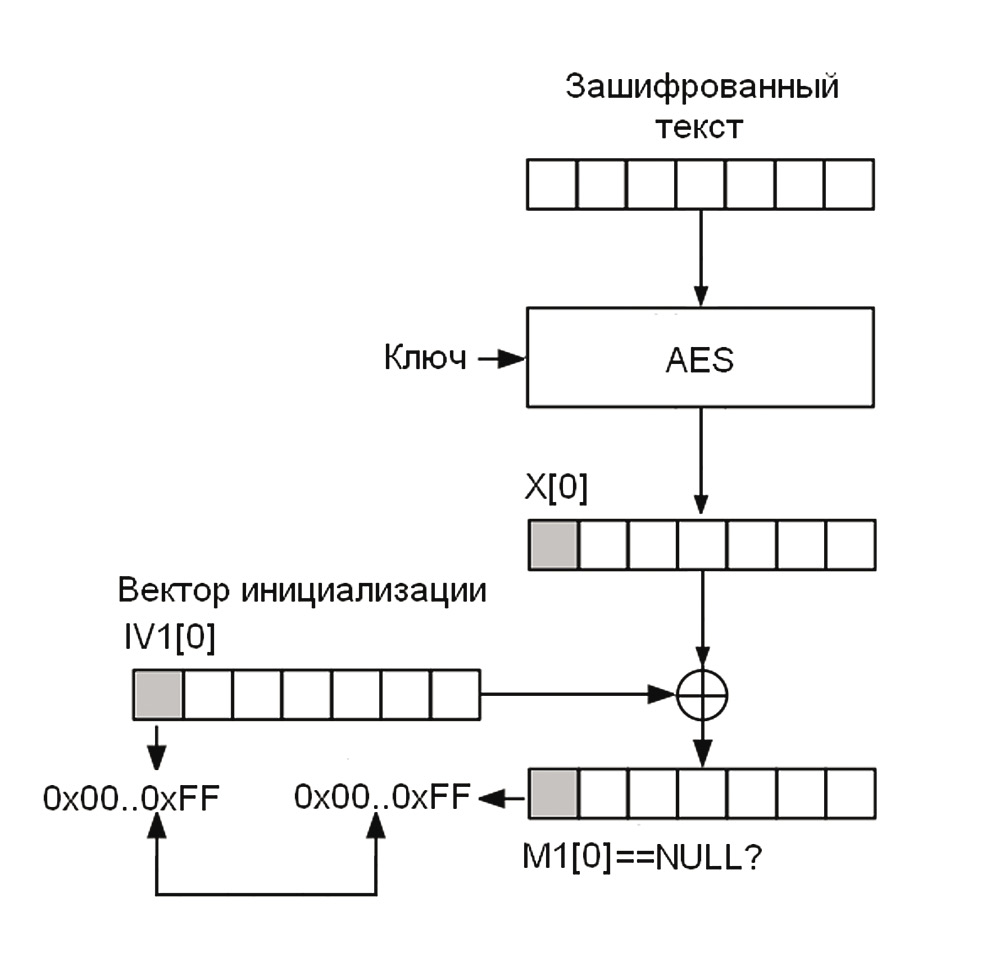
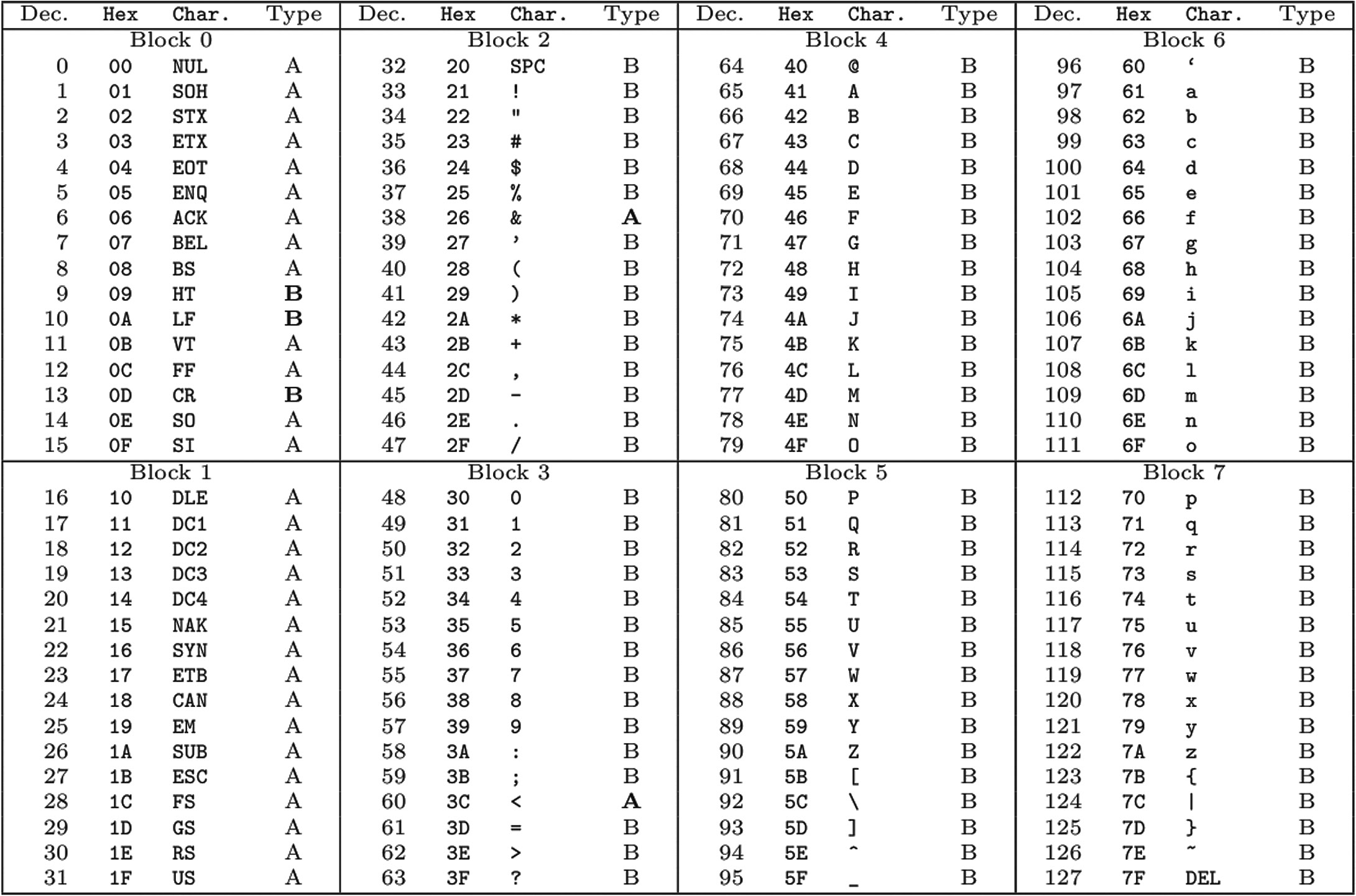
Будем считать, что информация, которую мы передаем, кодируется в ASCII. Разобьем всю таблицу ASCII на две части. В первую часть войдут все символы, кроме NULL (список А), а во вторую — все остальные символы (список B). Шифрованный текст, полученный из открытого текста, символы которого находятся в списке B, будем считать «правильно сформированным». Таким образом, если шифротекст сформирован правильно, то наш сервер при парсинге открытого сообщения не будет выдавать ошибок. Условимся также, что наши сообщения состоят всего лишь из одного блока открытого текста, то есть из 16 байт, а удаленный сервер в ответ на наши запросы возвращает true, если открытый текст M[0] = AESDECCBC(k, (IV, C[0])) не содержит запретного символа NULL, и false — в противном случае.
Теперь, посылая запросы нашему серверу, можно побайтно восстанавливать сообщения. Алгоритм восстановления состоит всего из трех этапов:
- Получаем такой новый вектор инициализации IV1, чтобы шифрованный текст (IV1, C[0]) был сформирован правильно. Для этого просто случайно выбираем новый вектор инициализации nIV, отсылая на сервер пару (nIV, C[0]). Если сервер возвращает true, то IV1 = nIV, ну а в случае false повторяем процедуру заново. В своей статье авторы атаки объясняют, почему мы найдем такой вектор инициализации за 2–3 обращения к серверу, но, я думаю, ты и сам уже догадался.
- Побайтно восстанавливаем промежуточный открытый текст (тот, который получен после AES_DEC при дешифровании, снова обрати внимание на первую иллюстрацию). Алгоритм восстановления описывается следующим псевдокодом:
msk = 0 repeat msk++ IV2 = IV1 xor (0...0||msk||0...0) // msk на j-й позиции until Server((IV2, C[0])) == true return X[j] = ASCIICode(NULL) xor IV2[j] // код "запретного" символаВот что имеется у нас на входе и выходе:
Input: C=(IV1, C[0]), j — номер байта в блоке Output: j-й байт X[j] блока промежуточного открытого текста X = AES_DEC(k, C[0])В алгоритме нет ничего сложного. Изменяя j-й байт вектора инициализации, мы наблюдаем за сообщениями сервера и ждем, пока на j-м месте в открытом тексте появится наш запретный символ. Ты спросишь меня, почему так? Отвечу: таков режим CBC. Для него справедливо следующее (опять все внимание на первую иллюстрацию):
AES_DEC_CBC(k, (IV2, C[0])) = IV2 xor AES_DEC(k, C[0]) = IV2 xor X[0]. - Так как весь промежуточный блок X[0] восстановлен, то нам остается получить блок открытого текста M[0]. Для этого мы осуществляем операцию XOR над X[0] и вектором инициализации IV. Вот такой незамысловатый алгоритм действий. Вся последовательность наглядно проиллюстрирована на втором рисунке.
XML И XML ENCRYPTION
Extensible Markup Language (или коротко XML) представляет собой язык разметки для сериализации древовидных структур. Важная особенность XML состоит в том, что символы «<» и «>» разрешается использовать только для обозначения узловых элементов (node). Так, если текст содержит один из этих символов, то перед сериализацией в XML его необходимо заменить на «<» или «>» соответственно. Точно так же для символа апмерсанда «&» применяется escape-последовательность «&». Перечисленные свойства XML играют важную роль при атаке на XML Encryption.

Консорциум W3C выпустил рекомендации XML Signature и W3C XML Encryption, что способствовало стандартизации XML и средств для применения криптографических примитивов (электронной цифровой подписи, симметричных алгоритмов и т. д.) к произвольным данным в формате XML.
XML SIGNATURE
XML Signature — спецификация W3C, определяющая синтаксис и порядок применения электронной цифровой подписи и кодов аутентификации для данных в формате XML.
Сначала разберемся с синтаксисом XML Encryption, который проиллюстрирован на третьем рисунке. Как видно, спецификация описывает формат метаданных, используемых при шифровании (идентификаторы ключей, алгоритмов, схем шифрования и т. д.). Наиболее важным является элемент , который, собственно, и содержит шифрованный текст.
Обработка полученного шифрованного сообщения осуществляется с помощью крайне простого способа. Сначала во всем документе проводится поиск элементов . Каждый такой элемент содержит метаданные с информацией о ключах, которая разбирается, обрабатывается и используется для построения ключа дешифрования данных. Затем содержимое извлекается и разбирается для получения шифрованного текста. Для дешифрования полученного шифротекста используется алгоритм, информация о котором содержится в элементе . Особенно важный момент для атаки наступает на последнем этапе, когда открытый текст парсится и вставляется в XML-документ. Если во время процесса дешифрования и разбора возникает ошибка, то она передается XML-процессору, который обычно выбрасывает исключение. А что еще ему остается делать? 🙂
Так как технологию XML Encryption можно применять к произвольной части дерева XML-документа (лишь бы она имела корректный синтаксис XML), то для разных типов контента существуют разные режимы шифрования. Используемый режим указывается в поле Type тега. Тип Encrypted Element означает, что дешифрованию подвергается один XML-элемент со всеми своими дочерними узлами. Тип Encrypted Content говорит о том, что дешифрованию подвергается произвольное количество узловых элементов со всеми своими дочерними элементами, комментариями, инструкциями по обработке и т. д. Тип Encrypted Text Content, являющийся частным случаем типа Encrypted Content, выделен для таких открытых текстов, которые состоят только из текстовых данных. Таким образом, информация в поле Type дает нам подсказку об открытом тексте. Стоит отметить, что при дешифровании этот атрибут обычно игнорируется XML Framework’ом и не влияет на последовательность действий при обработке шифрованного текста.
Пару слов необходимо сказать и еще об одном важном моменте — кодировке. Стандарт XML Encryption предписывает использовать кодировку UTF-8, которая указывает битовое представление символов различных алфавитов, а также других специальных символов. Наиболее значимая для нас группа символов всей таблицы UTF-8 — это символы английского алфавита, цифры, а также спецсимволы перевода строки (line feed) и возврата каретки (carriage return). Важно знать, что для этой группы символов коды ASCII совпадают с кодами UTF-8.
Также ты наверняка помнишь, что код ASCII представляет символы как одиночные байты и позволяет закодировать 128 различных символов (смотри рисунок 4). Замечу, что эта кодировка использует только семь из восьми бит в байте, старший бит всегда равен нулю.
AXIS2 — ФРЕЙМВОРК ДЛЯ СОЗДАНИЯ ВЕБ-СЕРВИСОВ
За последние несколько лет появилось довольно много фреймворков для разработки веб-сервисов. Одним из самых популярных решений в этой области является Apache Axis2 Framework, модуль Rampart которого содержит реализацию стандарта WS-Security. Этот стандарт и позволяет нам применять XML Encryption и XML Signature в сообщениях SOAP.
WS-SECURITY
WS-Security — гибкое и многофункциональное расширение SOAP, служащее для организации безопасного взаимодействия в веб-сервисах. WS-Security активно использует XML Encryption и XML Signature.
Чтобы этот модуль можно было использовать в Axis2 Framework, он должен быть элементом потока обработки сообщений (message flow). Поток обработки сообщений (message flow) — это цепочка модулей, каждый из которых получает входящее SOAP-сообщение (или контекст сообщения), обрабатывает его и передает следующему модулю в цепочке. Когда SOAP-сообщение достигает конца цепочки, оно перенаправляется в Message Receiver, который, в свою очередь, вызывает функцию класса Service и отправляет результат пользователю сервиса.
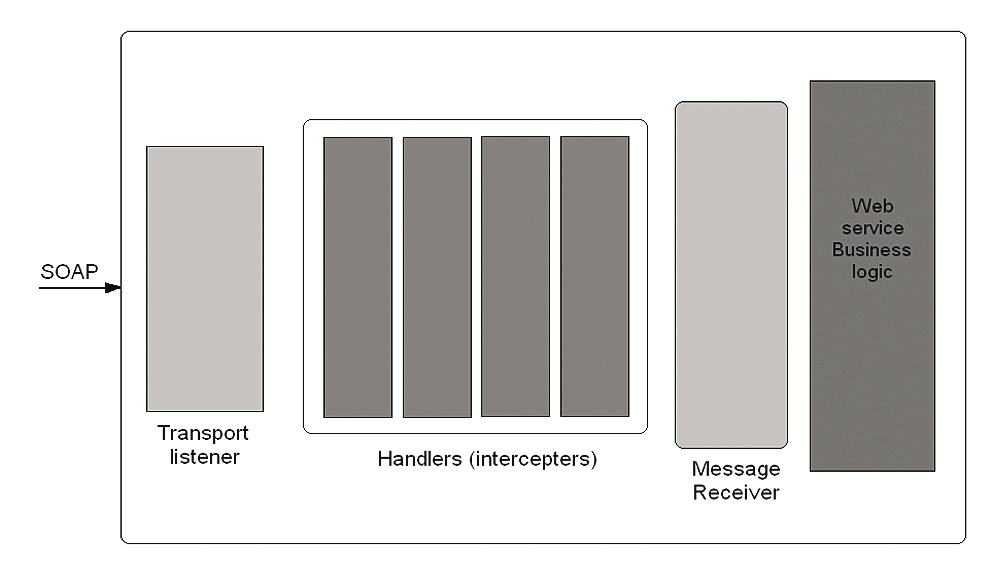
Обычно поток обработки сообщений в Axis2 состоит из трех модулей: Transport, Security и Dispatch. Модуль Security, как видно из названия, отвечает за безопасность. В процессе обработки зашифрованного сообщения он сначала осуществляет процесс дешифрования, а затем парсит открытый текст с помощью парсера XML и обновляет контекст SOAP-сообщения. Дешифрованный и проверенный контент передается модулю Dispatch. Как и Message Receiver, каждый модуль в цепочке message flow может прервать процесс обработки сообщения SOAP при возникновении ошибки, после чего процесс обработки прекращается и пользователю сервиса выдается соответствующее сообщение.
Теперь ты наверняка понял, к чему я все это рассказывал и кто виновник уязвимости в Axis2. 🙂
ОШИБКИ В СИСТЕМЕ БЕЗОПАСНОСТИ В AXIS2
ЧТО ТАКОЕ ОРАКУЛЫ?
В современной криптографии есть направление Provable Security, которое подразумевает анализ исследуемой системы при активном воздействии на нее. Предполагается, что злоумышленник имеет возможность посылать запрос и анализировать полученный ответ, затем создавать новый запрос на основе полученной информации, опять получать ответ и т. д. Под оракулом понимают то, что отвечает на запросы злоумышленника (сервер, просто комп, смарт-карту, СКЗИ, шифровальщик и др.). В нашем сегодняшнем примере в качестве оракула выступает сервер с веб-сервисом, то есть мы посылаем сервису запрос на обработку данных, а он возвращает либо ошибку, либо результат обработки данных. Axis2, в свою очередь, — это фреймворк для создания веб-сервисов. Недавно была новость про Padding Oracle Attack, где в качестве оракула выступало приложение (веб-сервис, сайт на ASP.NET), созданное с использованием .net.
В качестве оракула у нас будет выступать сервер с веб-сервисом, созданным с использованием Axis2. Поначалу нам нужно понять, какие сообщения об ошибках безопасности выдает сервер, так как тогда мы сможем отличить ответ true от ответа false нашего оракула. При возникновении ошибки безопасности сервис передает нам security fault. Причины генерации security fault можно разделить на две категории: 1. Ошибка дешифрования Такая ошибка возникает при некорректном дополнении последнего блока. Помнишь, я говорил, что последний байт каждого сообщения содержит число, равное количеству дополненных байтов? Так вот, этот последний байт может принимать значения от 0x01 до 0x10, в противном случае мы получаем сообщение об ошибке. 2. Ошибка парсинга данных Эта ошибка может возникнуть по двум причинам. Первая — открытый текст содержит «запрещенные» символы, то есть символы с кодами ASCII от 0x00 до 0x1F (за исключением 0x09, 0x0A, 0x0D — пробела, конца строки и возврата каретки). Вторая причина — некорректный XML-синтаксис дешифрованного сообщения, что означает появление в открытом тексте символа «&» (0x26) или «<» без соответствующего закрывающего символа «>».
В обоих случаях мы получаем одинаковое сообщение об ошибке и различить эти два случая между собой лишь по сообщению не можем.
Как и в приведенном ранее простом примере, разобьем всю нашу таблицу ASCII на две группы символов (все внимание на четвертый рисунок). Группа A содержит запрещенные для формата XML символы плюс два «зарезервированных» символа «&» и «<», ну а группа B включает в себя все остальные символы.
Теперь все готово для построения оракула. Как и в примере, наш оракул, то есть сервер, получает на вход один блок текста, зашифрованного в режиме CBC, то есть 16-байтовый вектор инициализации и зашифрованный блок такого же размера, и возвращает true или false. Конечно, этот блок должен быть правильно «обернут» в SOAP-сообщение, но здесь мы этим пренебрегаем. Итак, оракул возвращает true, если сервер в ответ на SOAP(AESENCCBC(k, (IV, C))) передает нам security fault, и возвращает false в противном случае.
Как я уже говорил, сервер не выдаст security fault, если на стороне сервера сообщение имеет правильное дополнение до полного блока, то есть открытый текст M имеет верную XML-структуру:
PAD(M) == (IV xor AES_DEC(k, C))
Здесь должны выполняться следующие условия: 1. M, содержащий XML-тег , обязательно должен содержать и закрывающий тег . 2. Если M содержит символ амперсанда «&», то он должен служить началом существующей escape-последовательности, например «>». 3. M не должен содержать символы из определенной нами группы B.
В противном случае возникает ошибка security fault, что позволяет нам использовать оракул точно так же, как и в предыдущем более простом примере.
ВОССТАНОВЛЕНИЕ ОТКРЫТОГО ТЕКСТА
Ну вот, теперь все готово для того, чтобы описать алгоритм восстановления открытого текста из шифрованного. Этот шифрованный текст может содержать произвольное число блоков. Мы будем представлять его как массив C=(IV, C[1], ... , C[d]), на первом месте в котором стоит вектор инициализации. Самое время еще раз вспомнить, что в режиме CBC вектором инициализации для блока С[i] является блок C[i-1].
Для простоты считаем, что открытый текст состоит только из символов ASCII (то есть в тексте нет ни одного символа из расширенной секции UTF-8). В отличие от случая, описанного в простом примере, здесь «правильно сформированным» шифротекстом является такой шифротекст, открытый текст которого состоит из символов группы B и имеет однобайтное дополнение, то есть последний его байт равен 0x01 (это допущение введено для более простого изложения идеи атаки).
Алгоритм восстановления открытого текста включает в себя две процедуры. Первая (FindIV) подготавливает шифротекст к проведению атаки. Она принимает на вход С = (IV, C[1], ... , C[d]) и номер блока i, а возвращает «правильно сформированный» блок шифртекста с новым вектором инициализации C=(iv, C[i]). Здесь все практически так же, как в описанном выше простом примере. Вторая процедура (FindXbyte) принимает на вход «правильно сформированный» блок шифрованного текста (полученный при помощи FindIV) и возвращает j-й байт X[i][j] промежуточного блока открытого текста X[i] = AES_DEC(k, C[i]). Используя эти процедуры, опишем в псевдокоде алгоритм восстановления открытого текста.
Input: C=(C[0] = IV, C[1], ..., C[d])
Output: M=(M[1], ..., M[d])
for i = 1 to d do
iv = FindIV(C, i)
for j = 1 to 16
X[i][j] = FindXbyte(C[i], iv, j)
end for
X[i] = (X[i][1], ..., X[i][16])
M[i] = X[i] xor C[i-1]
end for
return (M[1], ..., M[d])
Алгоритм прост и не нуждается в подробном разъяснении. Скажу лишь только, что получить открытый текст M таким способом возможно благодаря режиму CBC (смотри на картинку, и все станет ясно). Остается только рассказать тебе об устройстве двух загадочных функций: FindIV и FindXbyte.
ПРОЦЕДУРЫ FINDIV И FINDXBYTE
Процедура FindIV чуть сложнее процедуры из тестового примера, и во многом, как часто бывает в прикладной криптографии, эти сложности носят переборно-технический характер. Подробное описание я приводить не буду, а ограничусь лишь изложением идеи.
Она, собственно, состоит в том, чтобы перебирать некоторые байты вектора инициализации и, анализируя результат, решить две задачи: убрать все символы «<» из открытого текста и задать такой последний байт нового вектора инициализации IV, чтобы байт дополнения равнялся 0x01. В результате мы получим правильно дополненный шифротекст с одним байтом дополнения, требуемый для процедуры FindXbyte. Эта процедура, во многом также имеющая переборно-технический характер, сводится, в свою очередь, к побитному восстановлению байта для блока промежуточного открытого текста. Она немного сложнее аналогичной упрощенной процедуры, описанной ранее, так как в данном случае «запрещенных символов» гораздо больше.
ВАРИАНТЫ АТАКИ
На практике обычно всегда имеется дополнительная информация, которая во многом облегчает жизнь криптоаналитику. В данном случае любые дополнительные сведения об открытом тексте (его статистика, структура) могут во многом помочь и сократить число запросов к оракулу (удаленному серверу). Так, например, знание XML Schem’ы документа позволяет не тратить время на восстановление уже известного открытого текста (XML-тегов) и сосредоточить усилия на полезной информации. В то же время, если мы знаем, что в данном поле хранится, например, номер кредитной карты, это сильно сокращает группы разрешенных и запрещенных символов и позволяет эффективно отсеивать при переборе ложные варианты байтов открытого текста. Интересен также тот факт, что оракул можно использовать не только для дешифрования, но и для шифрования произвольных данных с помощью неизвестного нам ключа. В этом случае процедуру надо начинать с конца (с последнего блока), а процесс шифрования будет проходить «справа налево».
ВАРИАНТЫ ЗАЩИТЫ
Когда речь заходит о средствах, помогающих предотвратить изменение шифрованного текста, в голову прежде всего приходит мысль об использовании ЭЦП или аутентификации в рамках стандарта XML Signature. Однако этот способ защиты отпадает как неэффективный, поскольку атака под названием XML Signature Wrapping, разработанная довольно давно, позволяет модифицировать шифрованный текст в обход подписи и/или MAC. Второй очевидный путь — унификация сообщений об ошибках, чтобы хакеры не могли распознавать типы возникающих ошибок. Однако и этот вариант тоже не идеален. Во-первых, он перекладывает обязанности по созданию системы унификации ошибок на разработчика веб-сервиса, а во-вторых, приводит к появлению других каналов получения информации. В криптографии давно известен класс тайминг-атак, которые основаны на замерах времени, затрачиваемого удаленным сервером на обработку запроса. Пожалуй, самая действенная мера, которую можно предложить, — это смена режима шифрования CBC, основанного на блочном алгоритме, на режим с одновременной аутентификацией (например, ISO/IEC 19772:2009), но это влечет за собой необходимость переделывания стандарта XML Encryption. Вообще, если есть возможность, лучше всего перевести шифрование на более низкий уровень OSI (например, вместо XML Encryption использовать версию SSL/TLS, которая не подвержена BEAST).
ВМЕСТО ЗАКЛЮЧЕНИЯ
Мне нравятся все атаки, основанные на использовании оракулов и анализе сообщений об ошибках, так как они ярко иллюстрируют ситуацию, когда разработчики берут отличные надежные криптографические примитивы, но все равно получают epic fail. Я уверен, что уязвимость в XML Encryption далеко не завершает список багов, которые позволяют проводить атаки side-channel, и подобные уязвимости еще проявят себя. Надеюсь, что тебе было интересно, а если ты хочешь обсудить какие-то моменты этой статьи, смело пиши мне на почту. Напоследок хочу выразить благодарность Juraj Somorovsky и Tibor Jager, обнаружившим эту уязвимость, за очередной интересный пример применения криптоанализа на практике.