Содержание статьи
Перехватить HTTPS-трафик, используя transparent proxy
Решение: Нередко бывает нужно потребоваться перехватить данные. Например, для решения исследовательских задач или при проведении реальных атак. Причем наряду с возможностью посмотреть желательно еще иметь возможность и поменять что-то в потоке данных. И если с обычными протоколами по большей части все просто, то при оборачивании их в SSL (что случается в последнее время все чаще) мы получаем проблемку.
Warning!
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
Окей, если говорить об анализе трафика из браузера, то проблем не возникает. Любой перехватывающий прокси-сервер (а-ля Burp или ZAP) справится с этим на раз. А что делать, если «ломаемое» клиентское приложение не умеет использовать прокси? А что делать, если используется там какой-нибудь не HTTP-протокол? О решении второй проблемы мы поговорим в следующей задаче (разделены они были лишь для будущего удобного поиска), о первой же — читай ниже.
Хотелось бы отметить, что идейно «атака» на SSL будет одинакова для любой из тулз. Важно понимать, что никто не пытается расшифровать передаваемые данные, ведь главное — это обойти проверку правильности конечной точки подключения, которая происходит на первых этапах подключения, то есть заставить клиент думать, что наш сервис — это то место, куда он хотел подключиться. Подписи, сертификаты и все такое. Но не будем углубляться и перейдем к сути.
Есть клиентское приложение, работает по HTTPS, но юзать прокси не умеет. Мы можем использовать тот же Burp или любой другой прокси, который в состоянии работать в режиме transparent (invisible).
Немного поясню, в чем разница. Начнем с простого — с HTTP, а потом перейдем к HTTPS. Для обычного HTTP-трафика, когда используется прокси, ПО (а-ля браузер) посылает такой запрос:
GET http://any\_host.com/url?query=string HTTP/1.1
Host: any\_host.com
Когда прокси отсутствует, то браузер шлет
GET /url?query=string HTTP/1.1
Host: any\_host.com
Как видишь, в варианте с прокси (обычным прокси) в запросе (то, что после GET) присутствует имя хоста. При получении запроса прокси по этому имени понимает, куда нужно подключиться и отправить запрос.
Если же приложение не поддерживает работу с прокси, то у нас возникает две проблемы: как заставить его подключиться к нам и как наш прокси может понять, куда подключаться.
Для решения первой задачи нам пригодится любой метод, при котором трафик от приложения потечет через нас. Мы можем либо стать гейтвеем/шлюзом для подсети (ARP poisoning в помощь), либо стать сервером (запись в hosts, DNS spoofing и прочее), либо использовать что-то поизвращенней.
Вторая же задача решается тем, что прокси берет имя сервера, куда надо подключаться, но не из URL’а, а из заголовка Host в самом запросе. Вот такое поведение прокси и называется transparent (хотя имеются и другие значения). Ты, например, можешь ходить в инет на работе, не указав прокси, но фактически подключения твои будут все равно идти через корпоративный прокси, с теми же ограничениями на контактик, что и у проксированных юзеров.
Но это было про HTTP. А как же с HTTPS? Здесь все труднее.
В прошлом номере я описывал, как работает браузер через прокси, подключаясь к HTTPS-сайтам. Напомню, что браузер подключается к прокси методом CONNECT с указанием имени хоста, куда он хочет подключиться. Прокси же, в свою очередь, подключается по указанному имени хоста, а дальше просто редиректит трафик от браузера на сервер.
Если же приложение не поддерживает прокси, то как же transparent прокси узнает, куда ему подключать клиента? В описанных условиях — никак. Во всяком случае, в автоматическом режиме.
Но все-таки вариант есть, если добавить сюда еще одну технологию. Она называется Server Name Indication (SNI) и является одним из расширений SSL-протокола. Поддерживается еще далеко не всеми, но основные браузеры уже в лодке. Технология очень простая. Клиент указывает имя сервера, куда подключается в самом начале SSL handshak’а (то есть эта инфа не зашифрована).
Таким образом, у transparent-прокси опять-таки появляется возможность автоматически проксировать данные между клиентом и серверами на основе анализа SNI при подключениях.
Теперь общая ситуация примерно ясна. Перейдем к частностям. За основу возьмем Burp и его возможности, как типовой пример.
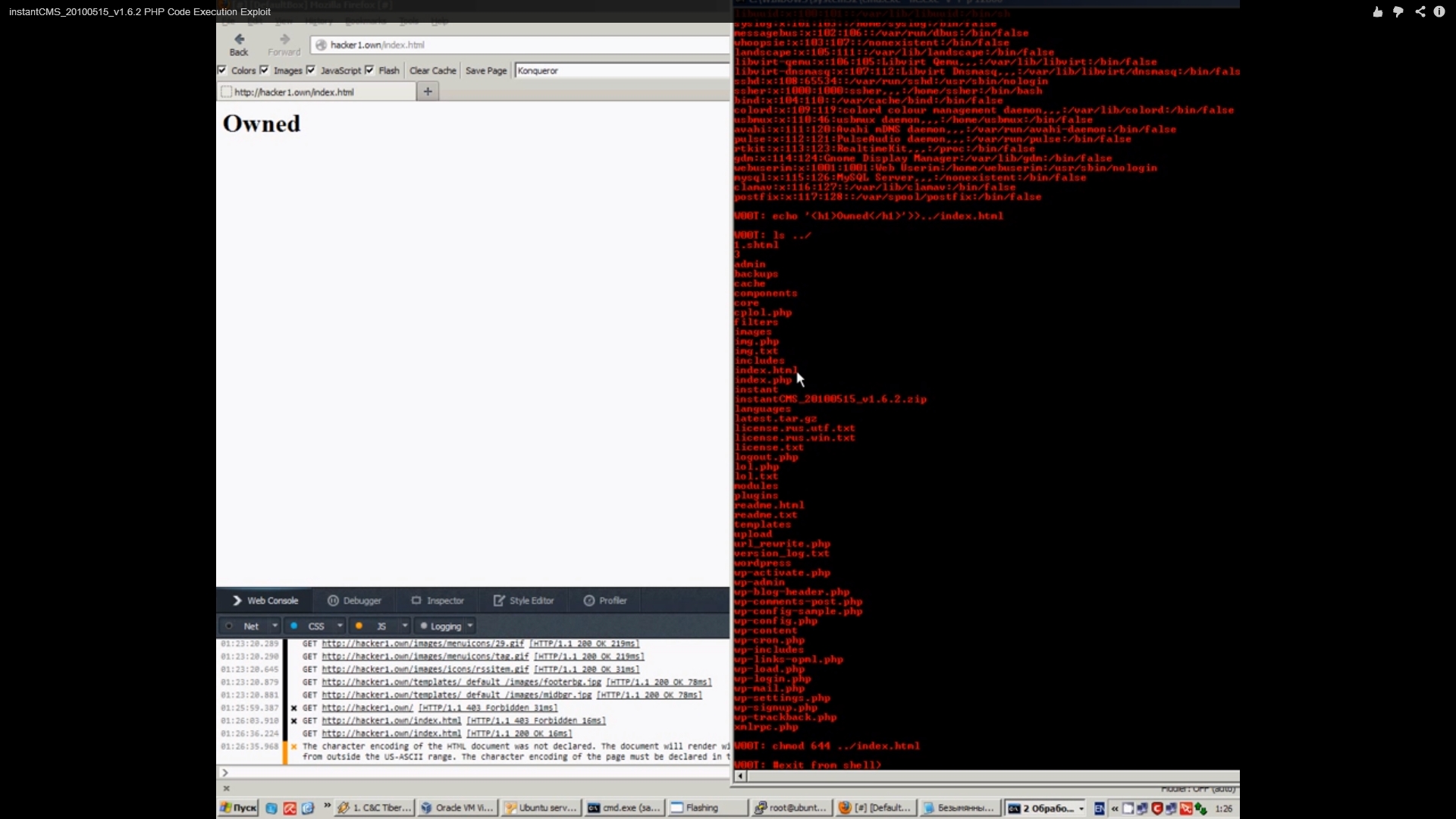
Если клиентское приложение не поддерживает прокси, то Burp, как ты уже понял, умеет работать в режиме invisible proxy. Включить его можно, воспроизведя следующую цепочку:
Proxy -> Options -> Proxy Listeners -> Выделение прокси -> Edit -> Request Handling -> Support Invisible Proxy.
Если клиент поддерживает SNI, то все хорошо: Burp может и к нужному хосту подключиться, и сгенерировать сертификат либо самоподписанный, либо подписанный Burp’овским CA. Но если это не так, то придется поработать руками.
Во-первых, на вкладке Request Handling мы должны указать адрес и порт, куда необходимо осуществлять подключение. Во-вторых, в Certificate указать имя сервера, для которого будет сгенерен сертификат. Самоподписанный создать совсем не получится.
Ясное дело, эти данные надо еще откуда-то получить. Тебе, скорее всего, потребуется посмотреть, к какому IP-адресу и порту подключается клиентское приложение, а далее подключиться к нему напрямую и из полученного SSL-сертификата взять имя для генерации своего.
Как видишь, все просто, но местами муторно. Но в итоге мы получаем чистый HTTP-трафик в Burp’е. За подробностями по этой возможности Burp’а обращайся сюда.
Хакер #184. Современный фронтенд
Перехватить не HTTP-трафик в SSL
Решение: Как ты, наверное, заметил, описанный выше транспарент-прокси для SSL-трафика, по сути, представляет собой простой порт-форвардинг. Получается такой редирект с подменой сертификата. И на самом деле, ведь в данном случае нет никакой особой привязки к протоколу, который находится внутри SSL. То есть предыдущая задача в какой-то мере подвид этой.
Наш же вопрос с прошлого топика — а что делать, если внутри SSL используется не HTTP-протокол? IMAPS, FTPS и почти любой другой аналогичный протокол с буковкой S на конце. В SSL запихивают все подряд. А ведь как сладко было бы обойти SSL и добраться до чистого трафика…
Ответ простой. В других случаях — не использовать Burp :), а использовать что-то другое. Есть много различных тулз, которые в этом помогут. Какие-то из них заточены под конкретный протокол, но есть и универсальные. С одним из универсалов я и хотел бы тебя сегодня познакомить — с SSLsplit.
Тулза эта прекрасна тем, что ее основная идея очень проста и понятна, но при этом имеется приличный объем специфичных настроек. Она представляет собой простой порт-форвардер («если трафик пришел на такой-то порт — пересылай все в такое-то место»), но имеет возможность для «работы» с SSL. Можно подсунуть реальный (краденый) сертификат, создать самоподписанный или подписанный своим CA. Также поддерживает автоматическую генерацию на основе SNI или редирект трафика на конечный IP-адрес (когда мы изображаем из себя гейтвей). Плюс она консольна, что позволяет легко автоматизировать типовые действия. Все это в целом делает ее куда более юзабельной для проведения атак (а не просто анализа протоколов приложений). Что делать дальше с трафиком — это уже зависит от твоих потребностей.
Не буду приводить здесь мануалы по пользованию, а ограничусь небольшим показательным примером.
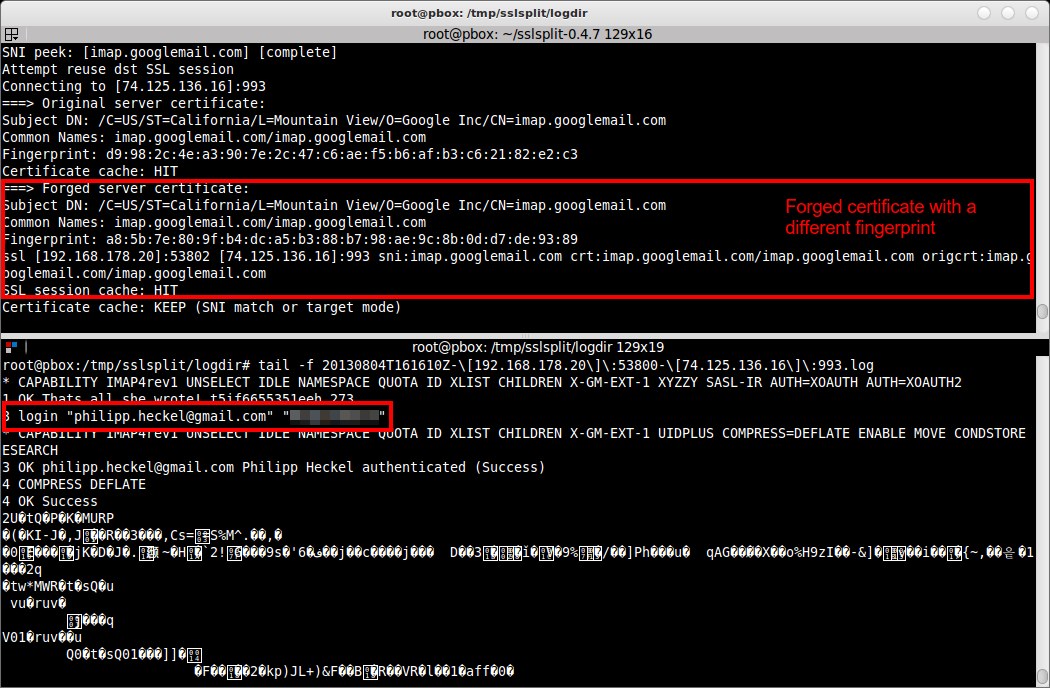
sslsplit -k ca.key -c ca.crt -l connect.log -L /tmp ssl 0.0.0.0 993 www.example.org 993 tcp 0.0.0.0 143
Здесь -k и -c указывают путь до приватного ключа и сертификата нашего CA, которые можно сгенерить при необходимости, используя openssl. Остальные параметры:
- -l — путь до файла, в котором будет вестись лог коннектов;
- -L — путь до директории, в которой будут сохраняться логи всех подключений (в плейн-тексте);
Далее блок «ssl 0.0.0.0 993 www.example.org 993». Ssl указывает, что мы снифаем SSL и надо подменить сертификат. Далее интерфейс и порт, на котором SSLsplit будет прослушивать трафик. Последняя пара — имя домена и порт, куда SSLsplit должен подключиться.
Блок «tcp 0.0.0.0 143» почти аналогичен. Но здесь мы указываем, что ssl не используется (поэтому tcp), а также входной порт SSLsplit. Если SSLsplit «подключен», как гейт (шлюз), то можно не указывать конечную точку подключения, так как она будет взята из IP-заголовков.
Таким образом, мы имеем простую и универсальную тулзу. Описание ее использования с примерами можно почитать здесь, а здесь перечень всех возможностей (man).
Настроить Nmap для сложных условий
Решение: Nmap, несомненно, тулзенка из топ-десятки самых необходимых и заюзанных тулз — как для пентестов, так и для мониторинга системы, да и для других дел. С одной стороны, она проста, умна и быстра, за что ее все любят. С другой стороны, при работе с ней в нестандартных условиях возникают различного рода трудности, во многом связанные с тем, что не совсем понятно, как же она устроена внутри, ее алгоритмы.
А внутренности Nmap совсем не простые, даже если взять ее главный функционал — сканирование портов. Не вдаваясь в подробности, можно четко утверждать, что целью создателей Nmap было сделать сканер, который бы предельно точно находил открытые порты (то есть без false positive, false negative), мог бы работать в различных сетях (стабильных/нестабильных, быстрых и медленных), подстраиваться под меняющиеся характеристики сети (например, когда промежуточное сетевое оборудование перестало справляться с нагрузками). То есть поведение Nmap меняется динамически, под конкретную сеть, под конкретный хост.
С другой стороны, его нацеленность на точность часто очень негативно сказывается на производительности. Приведу типичный пример: сканирование хостов в интернете, часть из которых находится за файрволом. На SYN-запрос на закрытый порт файрвол не отвечает ничего, вместо RST. Казалось бы, в чем проблема? Как раз в умности Nmap. Так как причин проблемы он не знает (файрвол, лагучая сеть, ограничения конечного хоста), то он будет замедлять частоту отправки запросов на сервер (до одной секунды по умолчанию), увеличивать ожидание до ответа на отправленный запрос (до десяти секунд). И добавь сюда то, что Nmap перепроверяет порты по десять раз. Получается, чтобы просканировать все TCP-порты зафайрволенного хоста с одним открытым портом, счет переходит даже не на часы, а на дни. Но найти-то данный открытый порт необходимо.
Но это еще не самая проблема. Nmap, дабы повысить свою производительность, сканирует сеть группами хостов, а не по одному. При этом характеристики сети для каждого из хостов будут отслеживаться индивидуально, что тоже хорошо. Проблема же заключается в том, что новая группа хостов не начинается, пока не закончилась предыдущая. Получится, что один хост может затормозить сканирование целого диапазона хостов… И чтобы такого не случилось, желательно наконец-то разобраться с возможностями тонкой настройки Nmap.
Признаюсь, сам я не глубокий знаток алгоритмов Nmap (об этом ведь даже книги пишут:Nmap Reference Guide, Nmap Network Scanning), что необходимо для корректной настройки таймингов. С другой стороны, у нас тут Easy Hack, так что сконцентрируемся на основных параметрах и практических рекомендациях (которые в большинстве случаев отлично работают).
Итак, у Nmap есть ряд параметров, напрямую влияющих на производительность. Все приводить не буду, а лишь понравившиеся :).
Перед началом сделаю два замечания. Здесь, раньше и далее «по умолчанию» значит «для профиля Т3», который и на самом деле используется по умолчанию, когда не выбран какой-то другой профиль. А значение задается в секундах, но можно использовать и другие единицы времени, добавляя соответствующую букву. Например, 3000ms, 5h, 10s.
--initial-rtt-timeout , --max-rtt-timeout . RTT (Round Trip Time) — время от отправки пакета до получения на него ответа. Очень важный параметр, который постоянно подсчитывается Nmap’ом во время сканирования. И не зря, ведь по нему Nmap понимает «производительность» сети и конечного хоста. Фактически он напрямую влияет на то, как долго будет ждать Nmap между отправкой запроса и получением ответа.
И как ты понимаешь, если ответа мы не получаем, то это значительно влияет на RTT. Как следствие, Nmap, послав SYN-пакет в «черную дыру» файрвола, будет ждать в итоге max-rtt (даже в быстрой сети), перед тем как понять, что порт зафильтрован. По умолчанию initial — одна секунда, max — десять секунд.
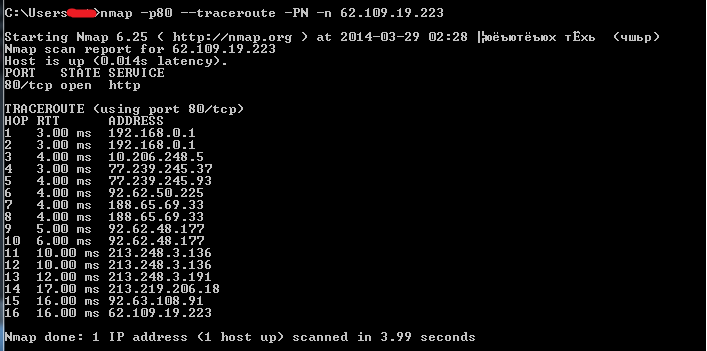
Для выбора же корректных значений RTT запускаем Nmap с параметром -traceroute (команда ping тоже подойдет). По сути, нам надо получить время прохождения пакета до конечного хоста или хотя бы «близкого» к нему. Далее, рекомендуется для initial указать удвоенное полученное значение, а для max — учетверенное.
--max-retries — очень простой параметр — максимальное количество повторов. Хотя я уже и писал, что десять повторов может быть, но это только в случае, если Nmap ощущает «плохую» сеть. Обычно меньше. Так что если сеть хороша — можешь обрезать вполовину и даже больше.
--max-scan-delay — максимальное время ожидания между отсылкой пакетов. По умолчанию — секунда. Если сеть хороша и нагрузки не боится (то есть почти всегда), то спокойно можно уменьшать даже в пять раз.
--host-timeout . Последний параметр относится косвенно к настройке тайминга, но очень и очень полезен. Он позволяет установить значение, после которого хост «пропускается» в сканировании.
Представь, сканируем мы сеть класса С и сканирование идет скоренько. Но тут бац! Два-три хоста где-то в середине сильно зафильтрованы. Если не настроил все заранее (как указано выше), либо жди «до бесконечности», либо пересканируй все заново, но уже с настройками.
Так вот, если Nmap достигает host-timeout для конкретного хоста, то он останавливает сканирование и переходит к следующим хостам. Установив значение минут в двадцать-тридцать, можно уже не опасаться «зафайрволенных» хостов, по достижению лимитов они проскочат. А разобраться с ними можно будет уже позже, настроив сканирование вручную. И да, по умолчанию он бесконечен.
Для выбора корректного значения рекомендуется просканировать один-два типовых хоста и удвоить/утроить это значение.
Конечно, есть еще другие параметры для настройки производительности Nmap’а, так что если эти тебе не помогли, то обратись сюда. Но главная мысль, скорее, такова: лучше потратить чуть больше времени на первичную настройку, чем потом ждать или пересканировать.
Установить любое приложение на Android
Решение: Недавно была задискложена отличнейшая логическая бага в Android. И мне кажется, это хороший, типичный представитель логических уязвимостей, а потому хотелось бы познакомить тебя с ней. Ведь такие баги — это просто кайф: и мозгом пошевелить надо, и найти можно там, где уже «каждый совал свою кавычку».
Итак, суть проблемы заключалась в том, что любое андроидовское приложение, обладающее определенными, не очень большими привилегиями, имело возможность установить ЛЮБОЕ другое приложение с маркета, с любыми привилегиями. То есть закачал себе человек игрульку, а та взяла и поставила еще софта на девайс и слила все деньги через какой-нить SMS-сервис. Здесь мы видим прямой профит для злых дядек, а потому ее автору гугл заплатила две тысячи долларов.
Давай же разберем багу. Я не буду вдаваться в технические глубины, а сконцентрируюсь на базовых вещах, чтобы те, кто незнаком с дройдами, тоже ощутил всю крутость. Ведь на самом деле она проста! Здесь все по принципу: по отдельности каждый из «фрагментов мозаики» защищен, а в целом — дыра.
Мозаика складывается из следующего:
- В наше приложение мы можем добавить WebView, то есть браузер. При этом мы можем подпихнуть свой JavaScript на любую страницу.
- Для установки приложения из маркета нам необходим лишь браузер. Например, ты можешь зайти на Google play и, если аутентифицирован, установить любое приложение на любой свой подцепленный девайс.
- Обладая кое-какими правами (android.permission.USE_CREDENTIALS), приложение может запросить у Account Manager’а девайса токен на аутентификацию и автоматически залогиниться в WebView в твой акк.
Ощущаешь? Наше приложение может автоматически залогиниться в гугл и с помощью подконтрольного JS в WebView полностью эмулировать поведение пользователя! Всевозможные анти-CSRF-токены, запросы на согласие о высоких правах и прочее мы можем вынуть и «накликать».
Хотя фактически так же мы можем получить доступ и к другим сервисам гугла. Почту, например, почитать :).
Так как багу задисклозили, значит, ее и закрыли. По предположению автора, главным изменением стала отмена автоматического логина. Теперь выводится сообщение, правда ли мы хотим залогиниться, и без юзерского клика «ОК» никак не обойтись.
На этом все. За подробностями отправляю к источникам, да и рекомендую запилить личный PoC.
В конце хотел бы лишь добавить про «глубину проникновения» гугла в нашу жизнь. Я не говорю о проблеме приватности. Аккаунт на гугле для очень многих людей главный, к которому привязано почти все. Причем это не просто набор критичных сервисов, а доступ к браузеру Chrome (а потом к ОС?), дройдо-девайсам (чему-то еще?). Мне кажется, что это в будущем значительно поменяет типовые подходы к безопасности. Например, трояны. Зачем «закапываться» вглубь систем, обходить разграничение прав ОС, подписи драйверов, когда можно спрятаться в JS-коде одного из компонентов браузера, ничего при этом не обходя и обладая контролем над главным «выходом»? Хотя понятно зачем :).
Или какую защиту для банк-клиентов может дать одноразовый код по SMS, если с затрояненного браузера на компе на все дройд-девайсы пользователя можно поставить троянчик, который будет читать SMS? Но это так — словоблудие :).
Спасибо за внимание и успешных познаний нового!