Содержание статьи
Все материалы сюжета:
Это — вторая статья из цикла «Криптография под прицелом» Романа Коркикяна. Также стоит прочесть:
- Ищем ключи криптографических алгоритмов
- Дифференциальный анализ питания
Вместо введения
Человек постоянно пользуется эффектами, которые проявляются при взаимодействии объектов, чтобы судить о свойствах самих объектов. С помощью такого подхода, например, было открыто строение атома. В начале XX века не было возможности увидеть сам атом, поэтому его строение представлялось в виде «булочки с изюмом», где в качестве изюма выступали электроны. Эта модель использовалась как основная до тех пор, пока Резерфорд и Гейгер не провели эксперимент по рассеиванию альфа-частиц в тонких пластинах. Эксперимент не позволил увидеть строение атома, но по второстепенному эффекту ученые смогли догадаться, что модель «булочки с изюмом» не работает. Другим очевидным примером служит вычисление объема тела произвольной формы. Самое простое, что можно сделать, — это опустить такое тело в воду и рассчитать объем по новому уровню воды. Похожие методы можно применить и для взлома криптографических алгоритмов.
В криптографии существует целый класс атак, называемых атаками по второстепенным каналам, которые используют физические параметры вычислительного устройства для определения ключей шифров. Основы атак были рассмотрены в предыдущей статье («Криптография под прицелом», #189), где секретный ключ алгоритма DES определялся по времени работы всего шифра. Если ты ее не читал, то настоятельно рекомендую это сделать, ибо в ней объясняется математическая составляющая атаки, а именно закон больших чисел Чебышева и коэффициент корреляции. В этой статье возвращаться к основам не будем, а больше сосредоточимся на микроэлектронике и статистике.
Скажи мне, как ты ешь, и я скажу... что ты ел
Для расширения кругозора в этот раз мы будем использовать алгоритм AES-128 (описание которого можно посмотреть тут). Код шифра был взят из Сети и выполнялся на 8-битовом микроконтроллере STM8 Discovery. В рассматриваемой реализации AES нет уязвимостей, о которых говорилось в предыдущей статье, поэтому будем полагать, что ты пока не нашел, как взламывать этот шифр.
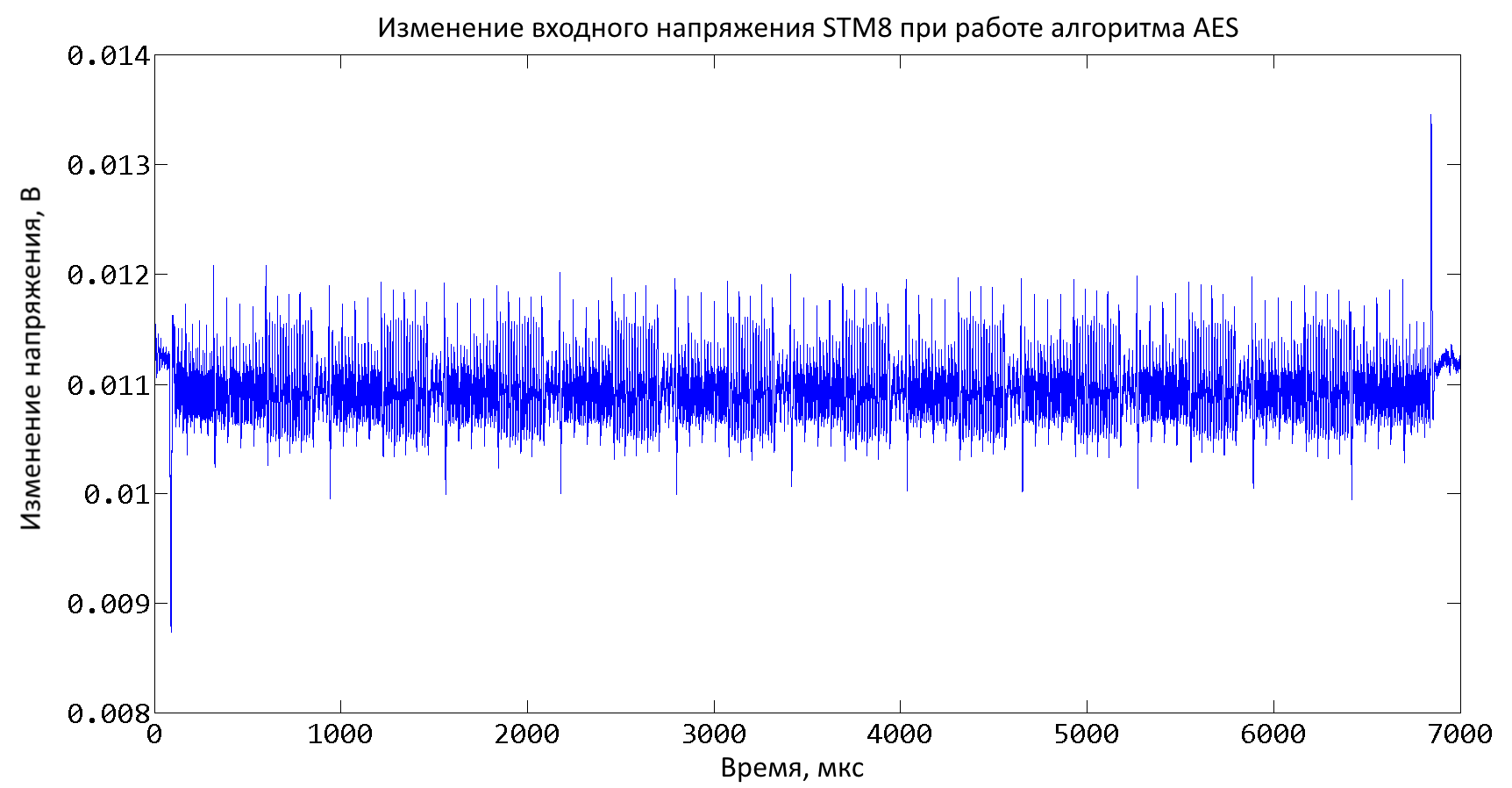
Как мы уже говорили, исполнение алгоритма изменяет свойства вычислительного устройства. Если ты до сих пор этому не веришь, то посмотри на рис. 1 и скажи, видишь ли ты AES. На нем изображено измерение входного напряжения всего микроконтроллера, которое обычно обозначается как Vdd. Это напряжение используется для работы всех блоков STM8, включая ЦПУ, память, устройства ввода/вывода и другие подсистемы. Измерение было сделано с помощью цифрового осциллоскопа Picoscope 3207A, пропускная способность которого 250 МГц. В данном случае интервал между двумя точками равен 352 нс, а на графике всего 19 886 точек. Так как частота микроконтроллера 16 МГц (период 62,5 нс), то в среднем напряжение измерялось для каждого 5-го такта, тем не менее раунды и даже операции каждого раунда могут быть явно различены (таблица замещения Sbox, перестановка MixColumn, сложение с ключом). Данный осциллоскоп позволяет уменьшить интервал вплоть до 100 пс (правда, в этом случае одно измерение будет содержать около 70 миллионов точек).
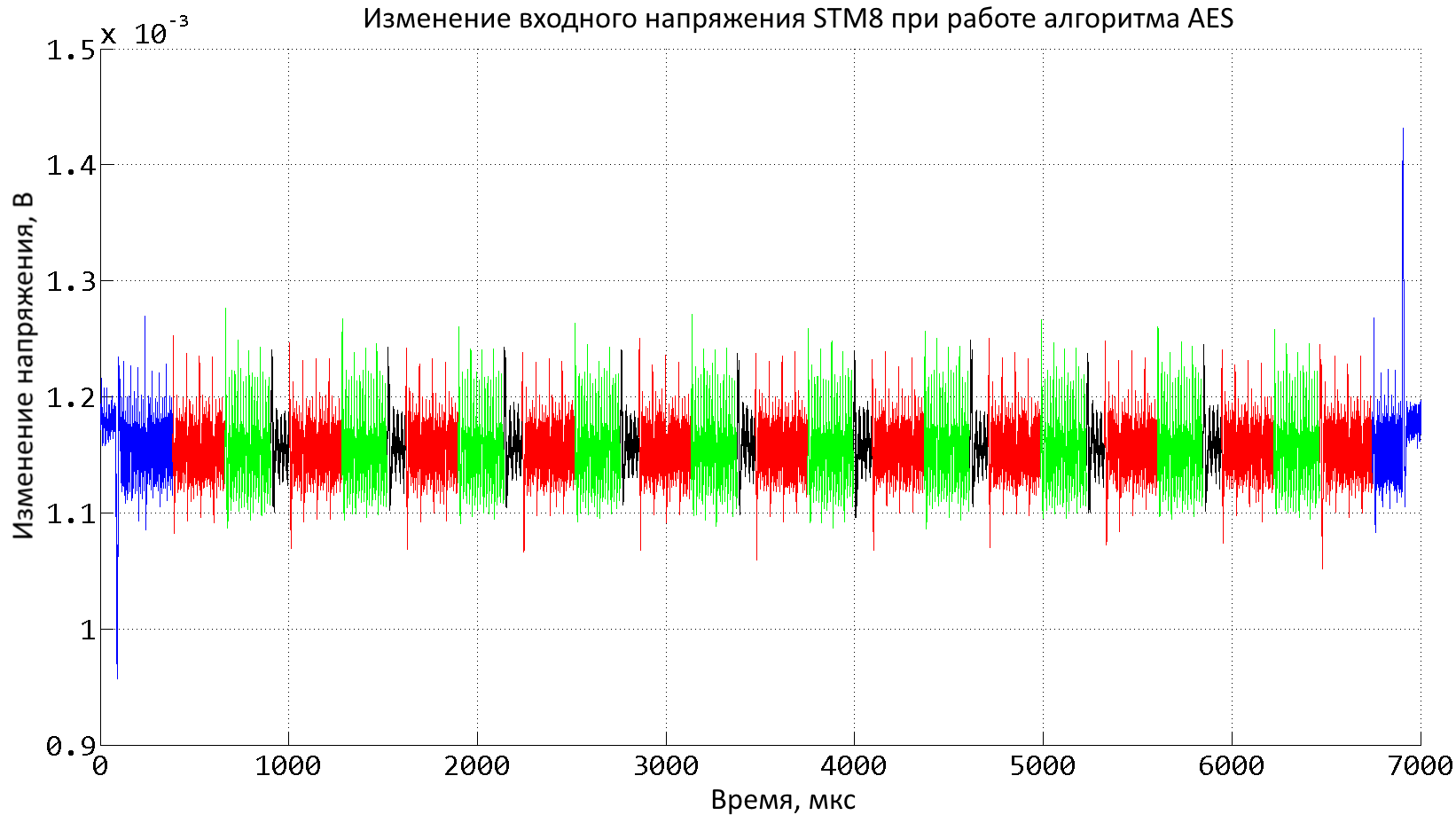
Несмотря на то что алгоритм AES симметричный, он имеет различное число базовых операций: 11 сложений с ключом, по 10 операций таблицы замены (Sbox), и лишь 9 операций над колонками MixColumn. На рис. 2 красным цветом выделены 11 сложений с ключом, зеленым цветом — 10 операций замены и черным цветом — 9 операций MixColumn. В начале и конце алгоритма могут происходить копирование или инициализация, поэтому они выделены синим цветом. Вообще, измеренное напряжение позволяет определить очень многое:
- Начало и окончание работы шифра, которые позволяют определить время работы всего шифра.
- Начало и окончание работы каждого раунда, которые опять же позволяют определить время работы раунда.
- Операции каждого раунда: сложение с ключом, таблица замены Sbox и так далее.

Хакер #191. Анализ безопасности паркоматов
Кроме того что показывает время выполнения каждой операции алгоритма AES, рис. 1 должен натолкнуть тебя на мысль, что каждая отдельная группа инструкций (да и вообще каждая отдельная инструкция) потребляет свое количество энергии. Если мы научимся моделировать энергию, потребленную во время выполнения инструкции, и эта энергия будет зависеть от значения ключа и известных нам параметров, то мы сможем определить правильное значение ключа. Правда, нам, как всегда, не обойтись без короткой теории, и в данном случае нужно разобраться, когда и почему происходит расход энергии.
МОПсы и их питание
Большинство современных вычислительных устройств создается по технологии КМОП (комплементарная структура металл — оксид — полупроводник). Технология замечательна тем, что микросхема практически не потребляет энергии в статическом состоянии, то есть когда не производится никаких вычислений. Это сделано для того, чтобы сберечь твой кошелек и позаботиться об окружающей среде, так как материалы для этой технологии (в основном кремний) широко распространены. Энергия в этом устройстве потребляется только в момент транзакции, то есть когда 1 заменяется на 0 или 0 заменяется на 1. Например, если на входы логического элемента И подаются два стабильных сигнала, то логический элемент не потребляет энергию (ну только самую малость). Если хотя бы одно входное значение изменяется, то происходит переключение транзисторов, которое требует энергии. Еще раз: если в течение минуты на вход элемента И подавались стабильные неизменные сигналы, то он не потреблял энергию, а вот если за эту минуту хотя бы один из входных сигналов поменялся, то в момент изменения энергия была затрачена на «пересчет» выходного значения. Таким образом, логические элементы — это один из потребителей энергии.
В микросхеме, помимо логических элементов, есть еще регистры, хранящие промежуточные значения вычислений. В отличие от логических элементов, для работы регистров требуется синхросигнал, который будет синхронизировать операции в микросхеме. Синхросигнал обычно имеет прямоугольную форму фиксированной частоты, например, STM8 Discovery использует 16 МГц, а современные процессоры от Intel и AMD способны работать выше 3,5 ГГц. Переключение регистра происходит следующим образом: на первый вход регистра подается сигнал от логических элементов, этот сигнал должен быть получен заранее и уже более не должен обновляться в данный такт. На второй вход регистра подается синхросигнал, в момент, когда синхросигнал переключается с низкого на высокое значение, происходит перезапись регистра и, соответственно, потребление энергии. Поэтому вторым и основным источником потребления энергии являются регистры памяти.
МОПсы и их поведение
На рис. 3 схематично изображена система любой инструкции или любого аппаратного дизайна. Есть регистры общего назначения R1 и R2, которые хранят промежуточные значения вычислений. Есть «облако» логических элементов, которое позволяет выполнять те или иные операции (сложение, умножение, операции сдвига и так далее). Облако логических элементов, равно как и регистры общего назначения, контролируется регистрами специального назначения. Именно они определяют, какая операция будет выполняться и в какой момент.
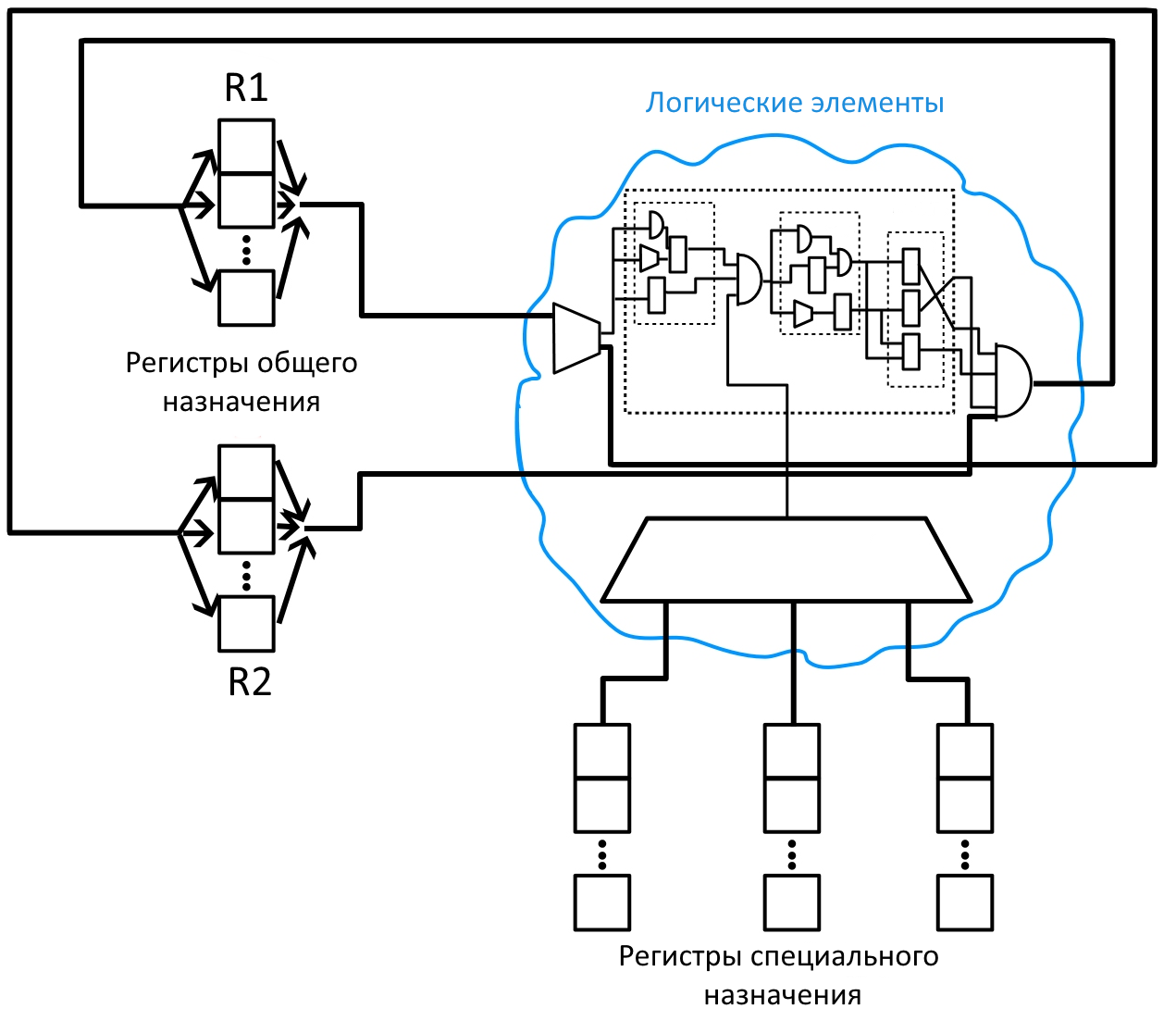
Предположим, мы хотим сложить значение регистров R1 (исходный текст) и R2 (ключ) и результат записать в регистр R1. Регистры специального назначения уже загружены, и они активировали нужные части микроконтроллера. На первом такте оба значения R1 и R2 отправляются в облако, где с помощью логических элементов складываются. Так как выполняется новая операция, то с распространением сигнала от R1 и R2 обновляется состояние логических элементов, и это вызывает потребление энергии. Затем, когда все логические элементы обновились и результат сложения отправился на вход R1, система замирает, и питание не потребляется до тех пор, пока на регистр R1 не пришел синхросигнал. В этот момент регистр обновился, и сразу же новое значение отправилось в облако логических элементов, тем самым вызвав новый всплеск в потребленной энергии. Если выполняется другая инструкция, то, возможно, ты увидишь всплеск другой формы (посмотри на паттерны на рис. 2, выделенные разным цветом), так как будут задействованы другие логические элементы.
Момент обновления регистров общего назначения очень важен. Во-первых, в этот момент происходит наибольшее потребление энергии, так как обновленное значение регистра вызывает дальнейшее переключение логических элементов. Во-вторых, из-за стабильной частоты осциллятора все операции совершаются в один и тот же момент времени, поэтому измеренное напряжение будет синхронизировано. Я хочу сказать, что для двух различных выполнений одного и того же кода система в момент времени t будет находиться в одинаковом состоянии, то есть сигнал будет обрабатываться одними и теми же логическими элементами. Возможно, это сложно понять, но в дальнейшем ты увидишь, почему это важно.
В данном объяснении тебе важно запомнить, что наибольшее потребление энергии происходит в момент переключения регистра и все кривые напряжения синхронизированы по времени.
Теперь мы посмотрим, как использовать эти знания для вычисления ключа. Мы разберем лишь один, самый первый способ атаки, а некоторые важные улучшения этого метода рассмотрим в следующей статье.
Дифференциальный анализ питания. Теория
Первая атака через потребленную энергию была опубликована Полом Кохером в 1996 году, хотя, строго говоря, его нельзя назвать автором этого метода — на тот момент технологии атаки активно обсуждались в фидонете. Согласно неофициальным данным, уже в конце 80-х годов прошлого века наши спецслужбы профилировали выполнение каждой отдельной инструкции микроконтроллеров, то есть они могли сказать, какая инструкция соответствует данной кривой напряжения (а первые зарубежные опубликованные работы на эту тему появились лишь в середине 2000-х — посмотри Template Attacks), хотя, еще раз повторюсь, информация неофициальная.
Дифференциальный анализ питания основан на том, что энергия переключения из 0 в 1 отличается от энергии переключения из 1 в 0. Это очень незначительное предположение, и я смело заявляю, что оно верно для 100% полупроводниковых устройств, то есть для всех гаджетов, которые ты используешь каждый день. По крайней мере существует строгое доказательство того, что для КМОП-технологии это действительно так (вот книга, объясняющая это свойство КМОП-систем еще до появления анализа питания).
Дифференциальный анализ питания проходит в несколько этапов. Вначале определяется целевой регистр, то есть инструкция, результат работы которой ты будешь атаковать. Внимательно прочти еще раз, ты будешь атаковать не саму инструкцию, а ее результат, то есть значение, записываемое в регистр. Целевой регистр может использоваться несколько раз, и, как ты увидишь, это повлияет на атаку. Результат работы инструкции должен зависеть от известных тебе данных (исходных текстов или шифротекстов) и от неизвестного значения ключа. Для AES-128 обычно используют операции, связанные с одной таблицей замещения Sbox, так как в этом случае ключ можно искать побайтово, плюс Sbox нелинейная операция, и она позволяет быстрее отбросить неправильные значения ключей. Во время каждого шифрования измеряется кривая напряжения, затем с помощью известных данных и неизвестного ключа вычисляется значение целевого регистра (как это делается — объясняется ниже). Из этого значения выбирается один бит (например, первый), и все кривые напряжения разделяются на две группы. В первую группу (группа 1) входят те кривые, для которых этот бит установлен в 1, во вторую группу (группа 0) входят те кривые, для которых этот бит равен 0. Затем вычисляется среднее арифметическое каждой группы и рассматривается их разность, собственно поэтому анализ и называется дифференциальным. Если модель и ключ были верны, то на разности средних арифметических в тот момент, когда использовался результат моделируемого регистра, можно увидеть значительный всплеск. Теперь рассмотрим все более детально.
Дифференциальный анализ питания. Все об AES
Если нам доступны шифротексты, то мы можем моделировать результат Sbox последнего раунда. Мы знаем, что первый байт шифротекста вычислялся следующим образом: С(1) = Sbox[S9(1)] xor K10(1), где S9(1) — это первый байт результата работы девяти раундов, а K10(1) — это первый байт ключа последнего раунда. Согласно алгоритму AES, значение S9(1) должно быть получено, чтобы рассчитать конечное значение шифротекста, пропустить вычисление S9(1) невозможно, просто потому, что так задан алгоритм. Мы работаем с 8-битным микроконтроллером и незащищенной реализацией алгоритма AES, поэтому, скорее всего, значение S9(1) было получено и сохранено вначале в регистре (значение нужно получить, а все результаты вначале записываются в регистры общего назначения), а затем в стеке, чтобы использоваться в следующем раунде. Таким образом, мы определились с целевой инструкцией, которая зависит как от ключа, так и от шифротекста, плюс это нелинейная операция, что помогает в атаках по второстепенным каналам.
Давай выберем первый бит значения S9(1) = InvSbox[С(1) xor K10(1)], с помощью которого мы будем классифицировать кривые напряжения. Оставшиеся биты можно использовать для улучшения/ускорения вычисления ключа, но мы пока будем работать лишь с одним первым битом.
Помнишь, мы говорили, что энергия переключения из 1 в 0 и из 0 в 1 отличается. Мы можем смоделировать результат, который должен быть записан в регистр, но мы не знаем предыдущее значение регистра, поэтому точно не можем определить, было ли переключение или нет. На самом деле это и не нужно. Мы просто полагаем, что предыдущее значение регистра не зависело линейным образом от нового значения. Попробую объяснить на примере. У нас есть N шифротекстов. Так как алгоритм AES все перемешивает и переставляет, то примерно в половине случаев из этих N шифротекстов наш искомый бит будет равен 1, а в другой половине он равен 0. Предположим теперь, что предыдущее значение регистра хранило промежуточный «случайный» результат шифра (результат другой Sbox, к примеру). Когда наш моделируемый бит равен 1 в половине случаев, предыдущее значение регистра было 0 (то есть в четверти случаев от N), и примерно в четверти случаев переключение будет происходить, а в четверти нет. То же самое с нулем: в среднем переключение из 1 в 0 будет у N/4 шифрований, и в оставшейся части переключений не будет (0 перезапишет 0). Получается, что среди N шифрований будет N/4 переключений из 0 в 1 и примерно столько же переключений из 1 в 0.
Если предыдущее значение регистра было постоянным, например в нем записывался счетчик цикла, то он всегда равен либо 1, либо 0. В этом случае еще проще, так как одна из двух групп, созданных по моделируемому биту, будет всегда переключаться, а другая никогда.
В случае если предыдущее значение регистра линейным образом зависело от нового значения, то могла получиться ситуация, когда в группе 1 было лишь очень ограниченное число переключений, которое чуть меньше, чем число переключений в группе 0. В этой ситуации количество переключаемых и не переключаемых битов было бы не сбалансировано и разность средних арифметических была бы бесполезна. Именно для того, чтобы избежать линейности, используется результат работы Sbox.
Согласно закону больших чисел Чебышева, среднее арифметическое группы 1 в момент выполнения целевой инструкции даст тебе константу плюс энергию переключения из 0 в 1, а среднее арифметическое группы 0 в тот же самый момент времени даст ту же самую константу плюс энергию переключения из 1 в 0. Так как мы знаем, что энергии переключения из 0 в 1 и из 1 в 0 отличаются, то разность средних арифметических даст тебе всплеск в момент выполнения инструкции.
Давай разберем, почему все остальные точки на разности средних арифметических будут стремиться к нулю. Это опять действует закон Чебышева: так как мы сортировали кривые с помощью нашего целевого регистра, то, скорее всего, все остальные инструкции будут случайным образом попадать в обе группы, следовательно, среднее арифметическое двух групп для всех остальных инструкций будет сходиться к одному и тому же значению. Таким образом, разность средних арифметических будет сходиться к нулю во всех точках, за исключением инструкций, которые тем или иным образом зависят от выбранного бита целевого регистра. Иногда, правда, можно встретить «призрачные» всплески. Они возникают в случае, если бит целевого регистра влияет на дальнейшие вычисления, но «призрачные» всплески можно использовать во благо, если понимать, откуда они берутся.
Дифференциальный анализ питания. Практика
Перейдем наконец от теории к практике. С помощью того же самого осциллоскопа было измерено напряжение для 10 тысяч шифрований. Чтобы убрать шумы, каждое шифрование выполнялось 1000 раз, а напряжение усреднялось. Дискретизация была увеличена в два раза, поэтому каждая кривая напряжения содержит 40 500 точек. Мы будем атаковать операцию, использующую значение регистра S9(1) = InvSbox[С(1) xor K10(1)]. Как ты потом убедишься, таких операций несколько. Для этого мы воспользуемся первым байтом каждого шифротекста и рассчитаем результаты регистра для всех шифрований и всех возможных значений байта ключа (см. табл.).
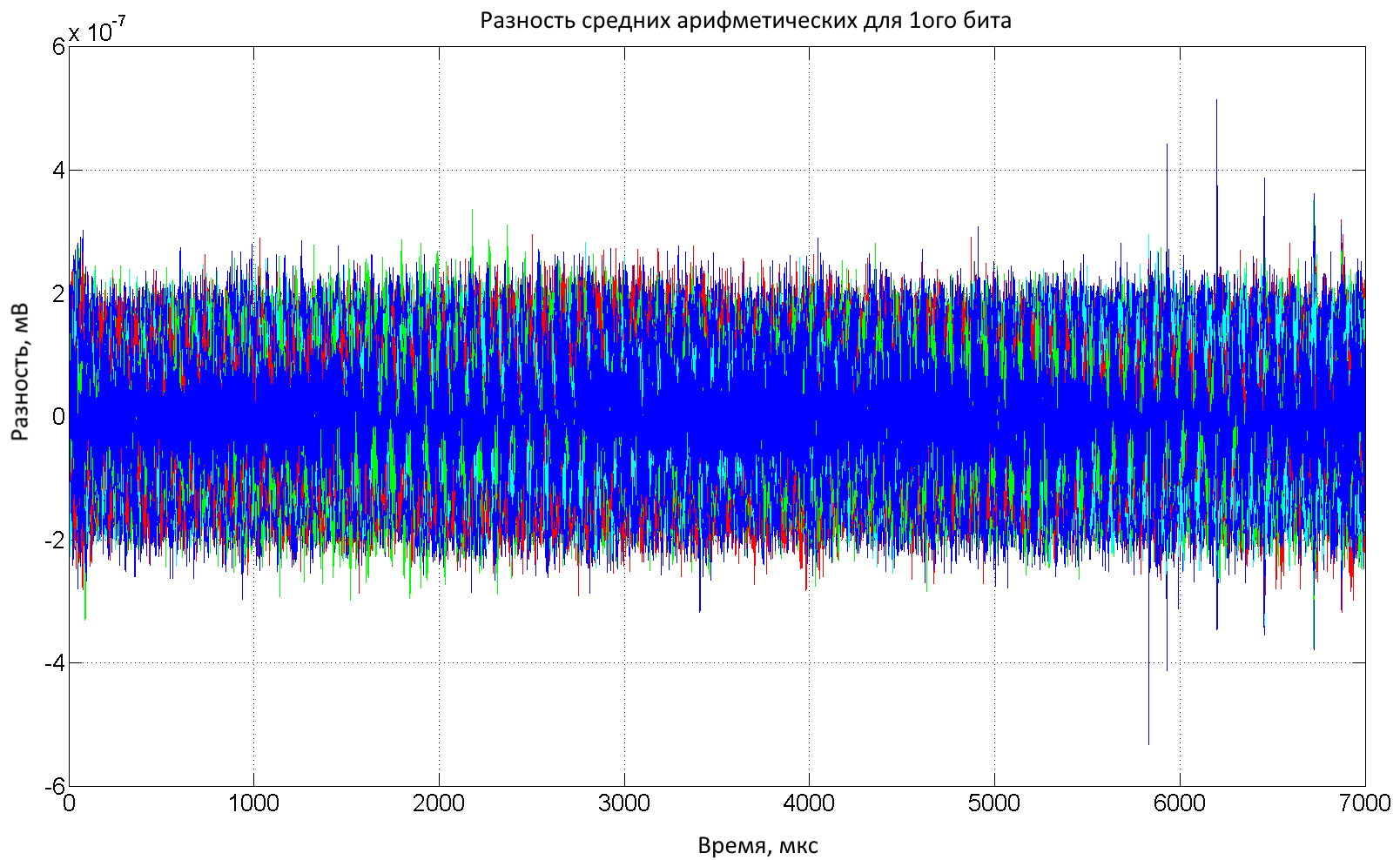
На основе значений из колонки 4 (первый бит S9(1) для ключа 0х00) таблицы мы отберем в группу 1 все кривые напряжений шифрований, для которых целевой бит S9(1) равен 1, а в группу 0 — все кривые напряжений шифрований, для которых этот бит равен 0. Теперь построим разность средних арифметических двух групп. Проделаем точно такую же операцию для оставшихся 255 ключей и построим их графики, как это сделано на рис. 4. Как видно из этого рисунка, у одного ключа есть значительный выброс ближе к концу шифрования, его увеличенное изображение показано на рис. 5.
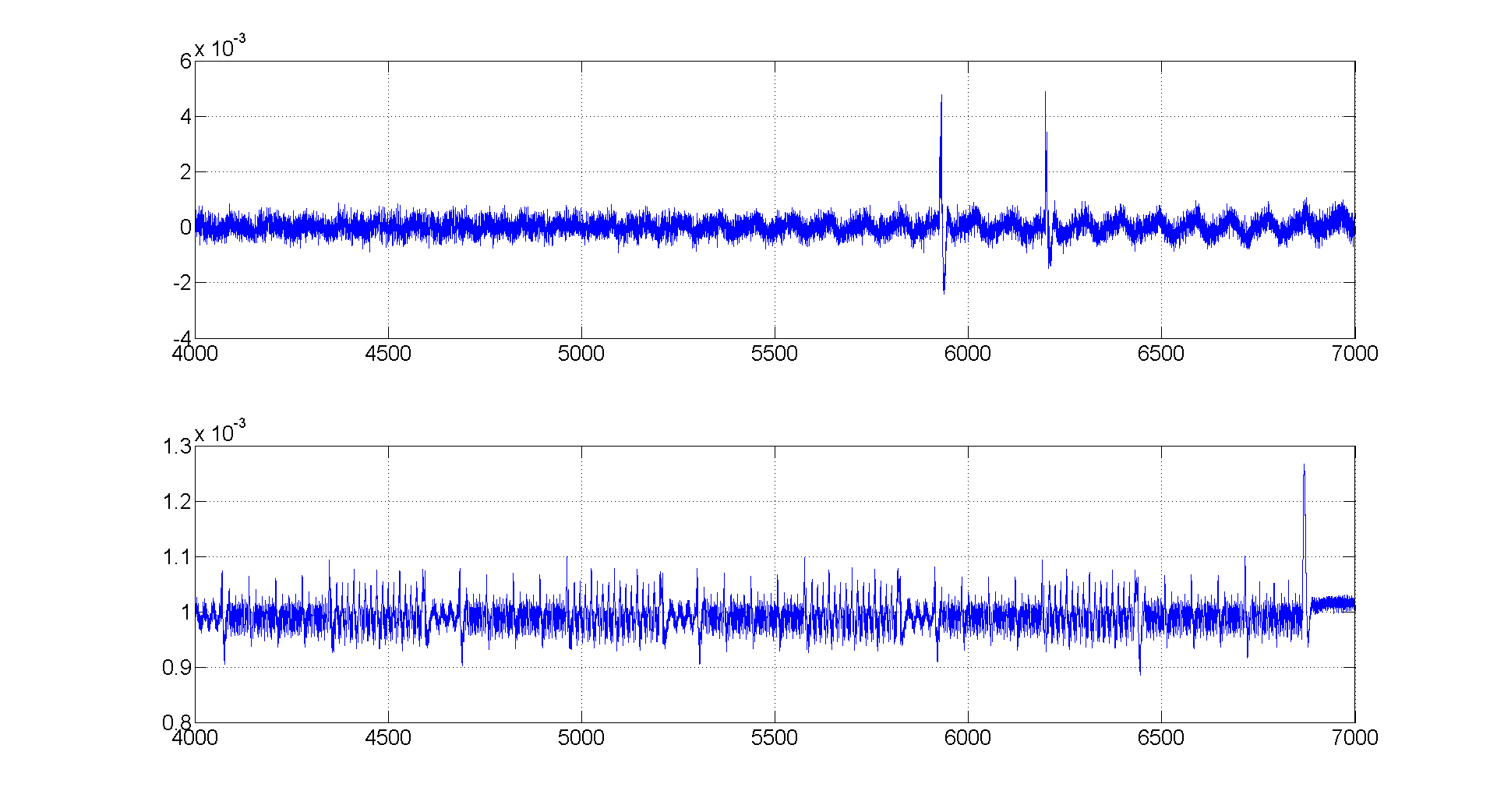
На нем мы видим три всплеска (они пронумерованы от 1 до 3). Третий пик я бы объяснил тем, что значение S9(1) считывается из стека для вычисления Sbox, так как оно находится в зоне выполнения Sbox последнего раунда (от 6200 до 6420 — это зона Sbox и Shift Rows). А вот два предыдущих пика объяснить чуть сложнее. Второй пик связан с операцией сложения с ключом, когда значение S9(1) было непосредственно получено, а самый первый пик связан с операцией MixColumn (так как находится в зоне MixColumn). Здесь важно понимать, что сложение с ключом — это линейная операция, и если бит ключа равен 1, то до сложения с ключом значение битов из таблицы было точно противоположным. Если бит ключа равен 0, то биты до сложения с ключом были точно такие же. До сложения с ключом значение байта должно быть получено после операции MixColumn, и именно этот момент, когда происходит получение байта нашего ключа, мы видим на графике. Так как пик направлен в противоположную (отрицательную сторону), то, скорее всего, группы 1 и 0 поменялись местами (мы из меньшего вычитаем большее), то есть в группе 1 были все шифрования, для которых бит установлен в 0, а в группе 0 все шифрования, для которых бит установлен в 1. Это возможно в случае, если бит ключа равен 1, так как в этом случае наша модель из таблицы будет строго противоположной и это приведет к тому, что пик будет отрицательным.
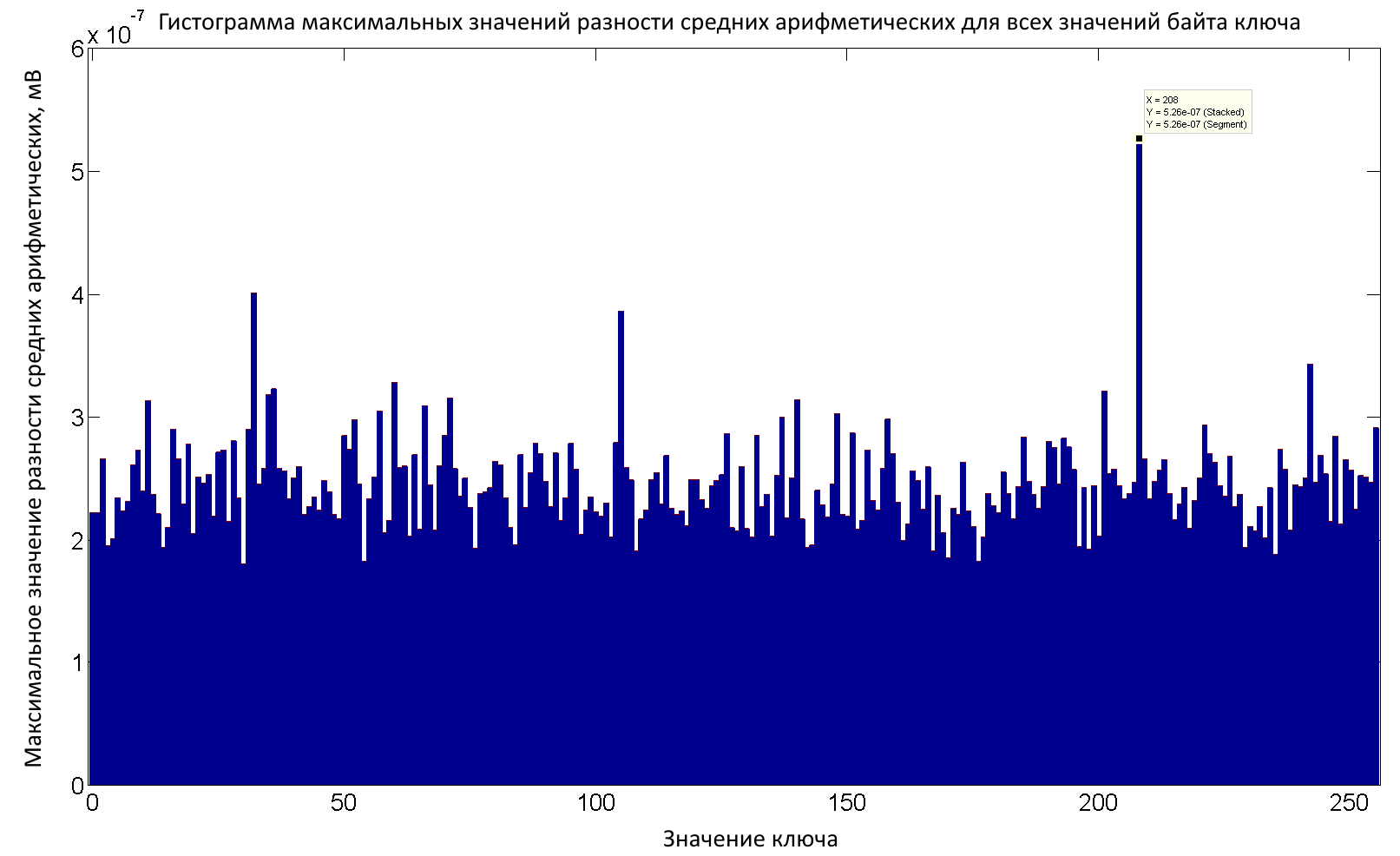
Чтобы найти ключ, обычно строят график максимальных значений для ключа, как показано на рис. 6. Видно, что значение ключа 208=0хD0, наибольшее, и этот ключ, скорее всего, является верным.

Ради сравнения построим те же самые графики, но в качестве целевого бита выберем восьмой бит значения S9(1) (наименее значимый бит). Согласно предыдущим расчетам, этот бит должен быть равен 0, поэтому на рис. 8 мы должны увидеть первый пик в положительной зоне, а не в отрицательной, как это было для первого бита. Также мы должны получить тот же самый ключ, ибо он не менялся, а менялся лишь бит для атаки. Все пики должны быть в те же самые моменты времени, ибо сама операция место не поменяла. Картинки 7–8 получились согласно нашим гипотезам, плюс ко всему максимальное значение разности средних было получено для одного и того же значения ключа на разных целевых битах, поэтому, скорее всего, мы нашли правильный байт ключа (на микроконтроллере был ключ, взятый из стандарта AES, так что можешь проверить все его байты).

Аналогичным образом ты можешь восстановить все оставшиеся байты ключа последнего раунда. Множество работ объясняют, как ускорить/упростить/улучшить алгоритм атаки, но тебе сейчас главное — разобраться в основе этого процесса. Некоторые улучшения мы рассмотрим в следующей статье.
Что посмотреть?
Я уверен, что у тебя осталось множество вопросов по самой атаке. Предлагаю тебе поискать ответы в Сети. Для этого можно воспользоваться scholar.google.com и ключевыми словами: differential power analysis, power analysis attacks. Существует специальный сайт dpacontest.org, которые проводит соревнования по скорости и точности применения атак по второстепенным каналам. На этом сайте есть примеры кода и множество данных для атак. Ну и следи за различными событиями в России, где даются практикумы по этим атакам. Также советую взглянуть на материалы таких конференций, как COSADE, CHES и CARDIS.
Заключение
Ничто не происходит бесследно, в том числе выполнение криптографических алгоритмов. Во время исполнения шифров информация утекает по второстепенным каналам, например потребленной энергии. Чтобы произвести вычисление, нужно затратить энергию, поэтому полностью защититься от атак по второстепенным каналам невозможно, эта проблема фундаментальна. В статье показано, как в действительности проходит атака и как найти ключ шифра на примере AES-128, исполняемого на микроконтроллере STM8. Для нахождения ключа использовано минимум информации о модели потребленной энергии, но и ее было достаточно, чтобы успешно взломать алгоритм. Статья демонстрирует одну из первых атак, созданных в 1996 году, а с тех пор анализ по второстепенным каналам значительно эволюционировал. Частично улучшенные методы атаки будут рассмотрены в следующей статье, поэтому, как обычно, stay tuned...