

Содержание статьи
Сам себе Большой Брат
Что вообще такое «мониторинг»? Поскольку я в свое время оканчивал химический университет, у меня это понятие четко ассоциируется с системами управления технологическими производствами. По сути, у нас есть ряд параметров сложной системы, которые мы отслеживаем, а по результатам можем, если необходимо, выполнить управляющее воздействие. Например, понизить давление в реакторе. А еще мы можем отправить уведомление оператору, который уже независимо примет то или иное управляющее решение.
У тех, кто далек от химии, но близок к IT, ассоциация немного другая, но в целом похожая — обычно это экран с кучей графиков, на которых творится какая-то магия, как в голливудских сериалах. Для многих администраторов так оно и выглядит — Graphite/Icinga/Zabbix/Prometheus/Netdata (нужное подчеркнуть) как раз рисуют красивый интерфейс, в который можно задумчиво глядеть, почесывая бороду и гладя свитер.
Большинство этих систем работают одинаково: на конечные ноды, за которыми мы хотим наблюдать, устанавливаются так называемые агенты, или коллекторы, а дальше все происходит по методике push или pull. То есть либо мы указываем этому агенту мастер-ноду, и он начинает периодически отсылать туда отчеты и heartbeat, либо же, наоборот, мы добавляем ноду в список для мониторинга на мастере, а тот уже, в свою очередь, сам ходит и опрашивает агенты о текущей ситуации.
Нет, я не буду рассказывать в подробностях, как настраивать подобные системы. Вместо этого мы голыми руками докопаемся до того, что вообще происходит в системе. Кстати, хороший перечень утилит для сисадмина приведен в статье Евгения Зобнина «Сисадминский must have». Настоятельно советую взглянуть.
Средняя температура по больнице
Об одной из самых базовых метрик часто рассказывают на первых же занятиях по Linux даже в школах. Это всем известный uptime, он же время непрерывной работы системы с момента последней перезагрузки. Утилита для его измерения называется точно так же и выдает целую строчку полезной информации:
$ uptime
13:43 up 9 days, 9:23, 2 users, load averages: 0.01 0.04 0.01
В начале идет текущее время, потом собственно аптайм, потом количество залогинившихся в систему пользователей, а дальше показатели load average, те самые таинственные три цифры, о которых часто спрашивают на собеседованиях. Кстати, есть еще команда w, которая выдает ту же самую строчку плюс чуть более подробную информацию о том, что каждый из юзеров делает.
Информацию об uptime можно посмотреть напрямую в /proc, только в таком случае она будет слегка менее интерпретируемой:
$ cat /proc/uptime
5348365.91 5172891.73
Здесь первое число — это сколько секунд система работала с момента старта, а второе — сколько из них она работала «вхолостую», не делая толком ничего.
Но давай остановимся подробнее на load average, ибо тут есть один подвох. Еще раз взглянем на числа, в этот раз воспользовавшись интерфейсом /proc (числа те же самые, различается только способ):
$ cat /proc/loadavg
0.01 0.04 0.01 1/2177 27278
Тебе не составит труда найти информацию, что в UNIX-системах эти числа означают усредненное количество процессов, стоящих в очереди за ресурсами CPU, причем взятые в трех временных периодах до текущего момента: 1 минуту, 5 минут и 15 минут назад. Дальше, четвертая колонка — это разделенные слешем количество процессов, выполняющихся в системе сейчас, и количество процессов в системе вообще, а пятая — последний выданный системой PID. Так где же здесь подвох?
А подвох в том, что это верно для UNIX, но не для Linux. С виду все нормально: если числа уменьшаются — нагрузка снижается, если увеличиваются — растет. Если ноль — система простаивает, если равна числу ядер — значит, загрузка под 100%, если в выводе десятки и сотни… стоп, что? Формально Linux учитывает не только процессы в статусе RUNNING, но и процессы, находящиеся в UNINTERRUPTIBLE_SLEEP, то есть висящие на вызовах в ядро. Это значит, что на эти числа могут также оказывать влияние I/O-операции, да и далеко не только они, потому что вызовы в ядро не ограничиваются I/O. Пожалуй, я здесь остановлюсь, а за подробностями рекомендую проследовать вот в эти две статьи: «Как считается Load Average», «Load Average в Linux: разгадка тайны».
Файлы, которых нет
Если говорить совсем откровенно, в Linux основным источником информации как о процессах, так и о железе служит именно файловая виртуальная файловая система procfs (/proc), а также sysfs (/sys). И у них довольно богатая и интересная история.
Дело в том, что одно из официальных положений идеологии UNIX гласит: «Всё есть файл», то есть взаимодействие с любым системным компонентом теоретически должно вестись через реальный или виртуальный файл, доступный через обычное дерево каталогов. Эту идею до абсолюта довели в наследнике UNIX под названием Plan 9, где все процессы превратились в каталоги и взаимодействовать с ними можно было даже посредством команд cat и ls, поскольку они были текстовыми. Именно так появилась файловая система procfs, которая позже перекочевала в Linux и BSD.
Но, как и в случае с load average, конкретно в Linux есть свои тонкости (это я так политкорректно называю адскую кашу-малашу). Например, линуксовый /proc, вопреки названию, с самого начала был универсальным интерфейсом получения информации от ядра в целом, а не только от процессов. Более того, именно взаимодействовать с процессами через эту систему практически не получается, только извлекать информацию по их PID’ам.
С течением времени в /proc появлялось все больше и больше файлов, содержащих информацию о самых разных подсистемах ядра, железе и многом другом. В конечном итоге он превратился в помойку, и разработчики решили вынести информацию хотя бы о железе в отдельную файловую систему, которую к тому же можно было бы использовать для формирования каталога /dev. Так и появилась /sys со своей странной структурой каталогов — ее трудно разгребать вручную, но она очень удобна для автоматического анализа другими приложениями (такими как udev, который и формирует содержимое каталога /dev на основе информации из /sys).
В итоге куча информации до сих пор дублируется в /proc и /sys просто потому, что, если выкинуть файлы из /proc, можно сломать некоторые фундаментальные системные компоненты (легаси!), которые до сих пор не переписаны.
Ну а еще есть /run, конечно же. Это файловая система, которая монтируется одной из первых и служит перевалочным пунктом для данных рантайма основных системных демонов, в частности udev и systemd (о нем поговорим отдельно чуть позже). Кстати, сам проект udev в 2012 году влился в systemd и дальше развивается как его часть.
В общем, как писал Льюис Кэрролл, «все чудесатее и чудесатее».
Ну и ссылочки почитать: Procfs and sysfs и «Файловая система /proc».
Но вернемся к нашим замерам. Для того чтобы смотреть, какие PID присвоены процессам, есть команды pidstat и htop (из одноименного пакета, более продвинутая версия top, заодно показывает чертову прорву всего, аналог графического диспетчера задач).
Кроме того, команда time позволяет запустить процесс, попутно измерив время его выполнения, точнее, целых три времени:
$ time python3 -c "import time; time.sleep(1)"
python3 -c "import time; time.sleep(1)" 0.04s user 0.01s system 4% cpu 1.053 total
Как выше я уже проговорился, любая программа может проводить разное время в kernel space и user space, то есть выполняя вызовы в ядро или свой собственный код. Поэтому при базовом взгляде на эти цифры можно в некоторых случаях уже сделать вывод об узком месте в программе: если первый показатель сильно выше, то, вполне возможно, затык в I/O, а если второй — то, возможно, в коде есть неэффективно написанные куски, которые стоит запрофилировать подробнее.
А вот третье время, total time, оно же wall clock time или real time, — это время, которое реально заняло выполнение программы с момента запуска до момента возврата управления. Кстати, user time может быть сильно больше real time, потому что оно рассчитывается как сумма по всем ядрам CPU. Если такое происходит — значит, программа неплохо параллелится.
Ну и напоследок, чтобы посмотреть загрузку для каждого ядра в отдельности, можно использовать вот такую команду:
$ mpstat -P ALL 1
Если будут сильные перекосы в загрузке ядер — значит, какая-то из программ, напротив, параллелится крайне плохо. А единичка значит «обновляй-ка раз в секунду».
Получше, чем у золотой рыбки
Что в науке, что в инжиниринге периодически возникает одна и та же «проблема» — нельзя просто так взять и ответить на, казалось бы, простой вопрос. Все потому, что есть нюансы и тонкости, а задающий вопрос человек начинает злиться и говорить: «Не надо мне этого всего, ты мне цифру назови». А потом зависает, когда внезапно оказывается, что разные утилиты показывают абсолютно разные значения, скажем, для размера файла или для количества доступной оперативки…
Кстати, об оперативке. Поскольку это у нас железо, то мы можем первым делом опять нахально проследовать в /proc:
$ cat /proc/meminfo
…и получить кучу разных цифр, из которых большая часть абсолютно непонятна, так как это вообще все параметры нашей RAM, которые видит ядро. Поэтому лучше все-таки использовать старую добрую команду free:
$ free -ht


Кстати, почему мы получаем информацию об оперативке не из /sys, как я описал во врезке? Да потому что «пошел ты, вот почему». Вот ссылка на заметочку, в которой написано, где там память в /sys и как с ней работать: How memory is represented in sysfs. Если кратко — придется перемножать в уме и читать кучу разных файлов.
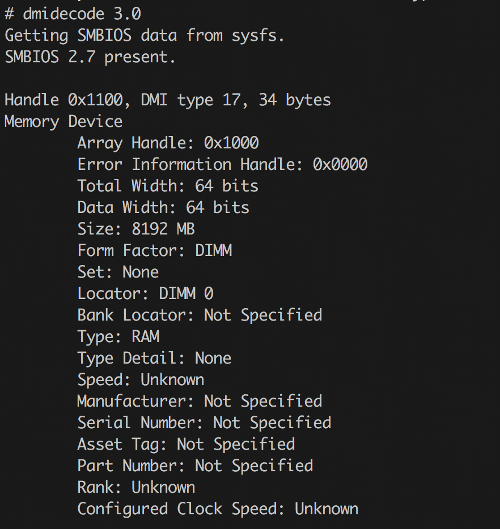
Как ни странно, есть возможность получить и более низкоуровневую информацию об оперативке, чем /proc/meminfo. Это утилита dmidecode из одноименного пакета. Она общается непосредственно с BIOS и возвращает даже имена вендоров-производителей. Правда, не всегда верные (особенно весело запускать ее под гипервизором, но это совсем другая история).
$ sudo dmidecode --type 17
Кстати, top и htop, как и банальный ps aux, тоже выводят информацию о занятой памяти, а второй еще и диаграмму в ASCII рисует по ней и по ядрам. Цветную. Лепота.
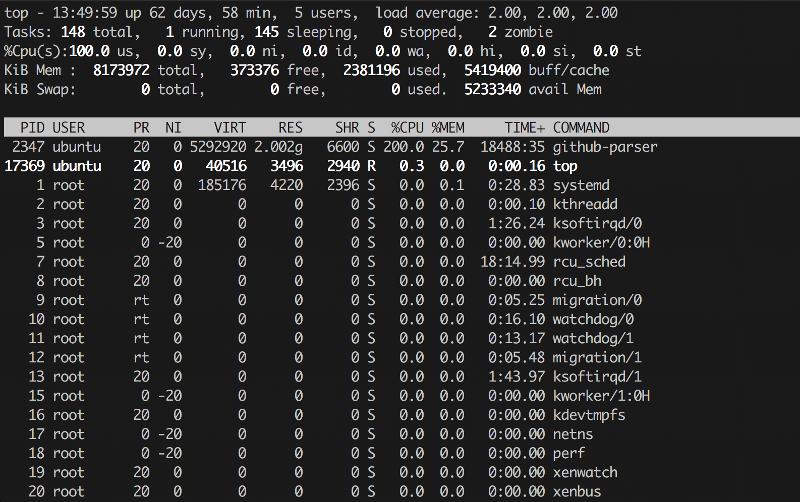
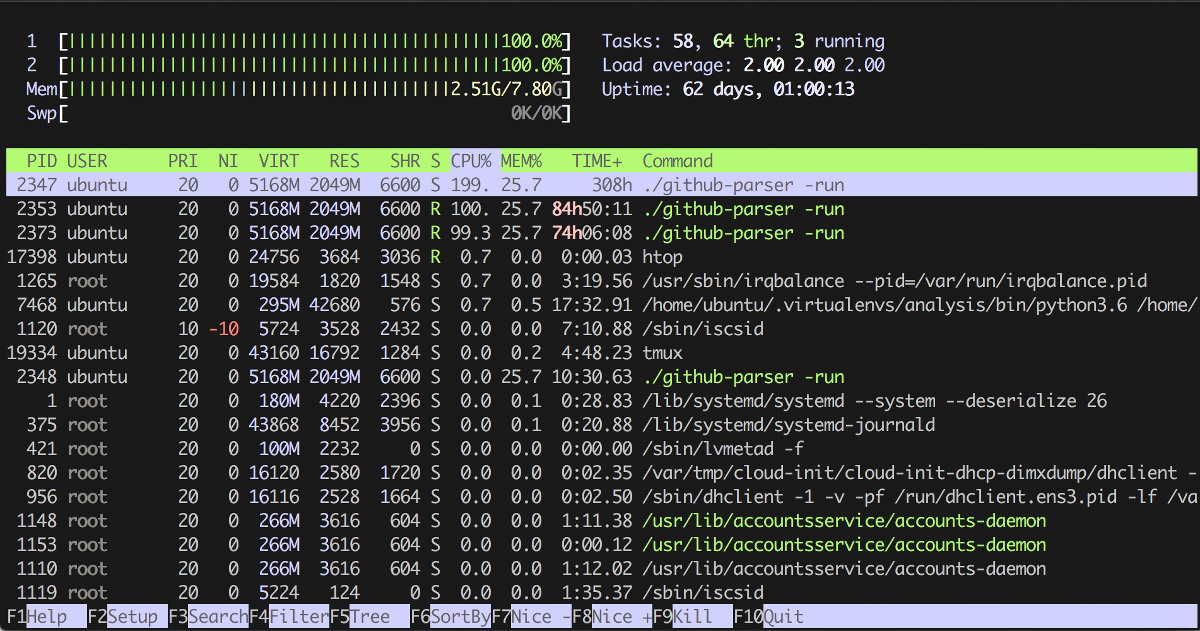
Первые две колонки очевидны:
- PID — идентификатор процесса;
- User — пользователь, от которого он запущен.
А вот две следующие чуть интересней: Priority и Niceness, причем первая в общем случае равна второй + 20. По сути, Priority показывает абсолютное значение приоритета процесса в ядре, а Niceness показывает значение относительно ноля (ноль обычно назначается по умолчанию). Этот самый приоритет учитывается при выдаче процессу квантов процессорного времени, поэтому, формально говоря, при увеличении приоритета командой renice можно заставить какую-нибудь сильно CPU-bound задачу выполняться чуточку быстрее. Для процессов реального времени в колонке Priority будет стоять rt, то есть real time, «как только — так сразу».
Дальше следуют данные о памяти:
- VIRT — виртуальная память, «обещанная» процессу системой;
- RES — фактически используемая память (кстати, благодаря механизму copy-on-write может быть несколько (N) форков одного и того же процесса с одним и тем же числом M в этой колонке, что вовсе не значит, что сожрано N*M памяти, потому что они разделяют ее между собой);
- SHR — shared memory, то есть память, которая потенциально может использоваться для межпроцессного взаимодействия.
Ну и совсем базовые показатели:
- CPU% — сколько процентов CPU жрет процесс; легко может быть больше 100%, если параллелится на несколько ядер;
- MEM% — процент памяти, потребляемой процессом;
- TIME+ — сколько времени процесс бежит;
- COMMAND — какая команда (программа + аргументы) запущена.
Но мы же хотим идти еще глубже, надо больше подробностей!
$ vmstat 1
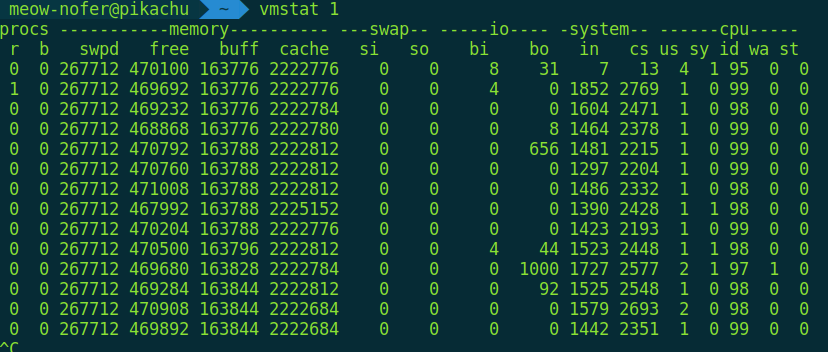
Здесь тоже много колонок, для простоты взглянем на четыре:
- r — размер очереди процессов на доступ к памяти;
- b — число процессов в uninterruptible sleep;
- si/so — сколько страниц памяти в текущий момент пишется в своп / читается из свопа.
Надо ли явно подчеркивать, что в идеальном мире в них должны быть ноли?
Где хранить коллекцию лютневой музыки
Если ты хоть раз размечал диск руками (например, при установке Arch Linux), то наверняка знаешь о существовании утилиты fdisk. С ее помощью проще всего посмотреть разделы на этом самом диске:
$ sudo fdisk -l
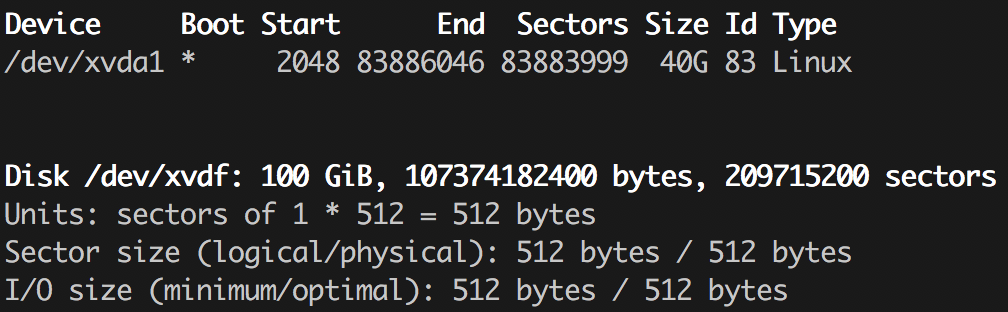
Есть ее более развесистая версия с псевдографическим интерфейсом, называется cfdisk, а также еще пара утилит, которые, на первый взгляд, делают весьма похожие вещи — позволяют управлять разделами на дисках. Это parted (к которому, кстати, есть неплохой GUI на GTK в лице gparted) и gdisk. Наличие такого зоопарка связано с тем, что существует несколько вариантов структурирования разделов на диске, и исторически для разных вариантов использовались разные программы. Наверняка ты уже встречал такие аббревиатуры, как MBR и GPT. Я не буду подробно останавливаться на различиях, но почитать можно, например, в статье «Сравнение структур разделов GPT и MBR». Там оно обсуждается с позиции настройки Windows, но суть от этого не меняется. И да, в современном же мире fdisk уже умеет работать с обоими вариантами, как и parted, поэтому выбирать можно исключительно из личных предпочтений.
Но вернемся к сбору информации. Мы знаем, какие у нас разделы, а теперь давай взглянем на дерево файловой системы, точнее, что куда смонтировано:
$ df -h
Как и раньше, -h тут отвечает за «человеческий» вывод размеров. Ну и как ты помнишь, размеры файлов у нас можно посмотреть командой du:
$ du -h /path/to/folder
Наверняка часть читателей сейчас подумала: «Ну что за банальщина, это даже школьники знают, давай чего посвежее». Ладно, давай привнесем реалтайма, как уже делали с оперативкой:
$ iostat -xz 1
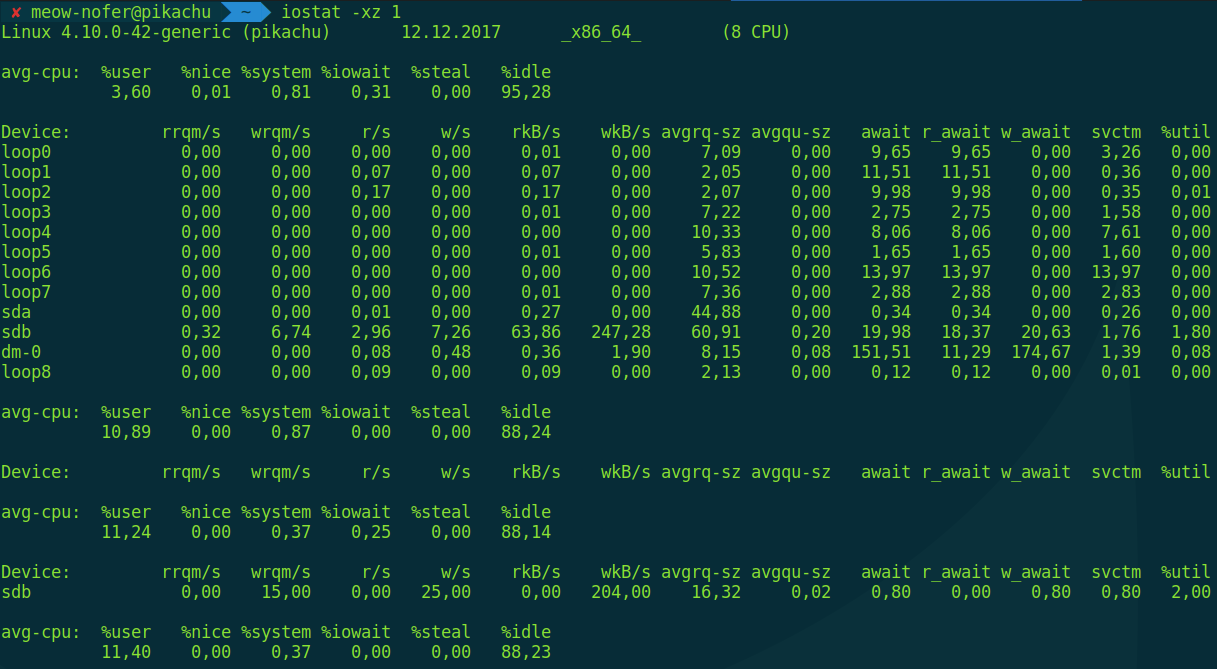
Эта команда выводит средние значения количества операций чтения-записи для всех блочных устройств в системе, обновляя информацию раз в секунду. Это больше «железные» параметры, поэтому есть еще одна команда для просмотра статистики I/O попроцессно, и она, по аналогии, называется iotop.
$ sudo iotop
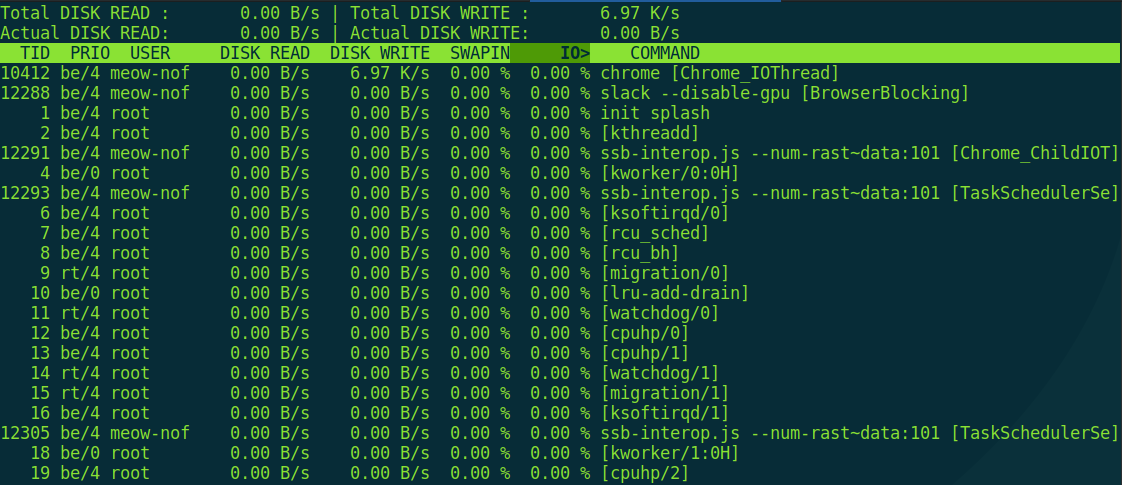
При попытке запуска без прав root она начнет очень мило оправдываться, что, мол, есть один такой баг CVE-2011-2494, который может приводить к утечке потенциально важных данных от одних пользователей другим, «поэтому настрой-ка ты, дружочек, sudo». Оно и верно.
Пакеты брать будете?
Что еще из операций ввода-вывода у нас осталось? Правильно, сетевое взаимодействие. Здесь царит та еще чехарда — «официальные» утилиты меняются от релиза к релизу, что, с одной стороны, круто, потому что удобств становится больше, с другой — надо переучиваться каждый раз.
Скажем, какой утилитой смотреть существующие в системе интерфейсы? Кто сказал ifconfig? На современных системах ifconfig, как правило, уже вообще отсутствует, ибо есть
$ ip a
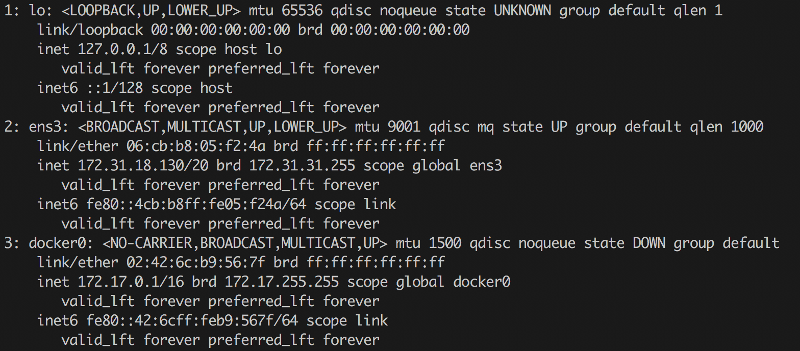
Вроде выглядит немного по-другому, а вроде то же самое. Кстати, для управления сетевыми мостами из консоли часто необходимо ставить пакет bridge-utils. Тогда в консольке появится утилита brctl, с помощью которой можно будет их просматривать (brctl show), ну и менять. Но иногда бывает по-другому. Мне встречался случай, когда бриджи были, а brctl их не показывал. Оказалось, что для их создания использовался Open vSwitch и кастомный модуль ядра, для настройки которого надо взять другую утилиту — ovs-vsctl. Если вдруг у тебя окружение на OpenStack, где эта штука активно используется, — может быть полезно.
Дальше — как насчет таблиц маршрутизации? Как, говоришь, route -n? Нет, мимо. Сейчас чаще используются netstat -nr и ip route show. Ну и самое банальное — как посмотреть открытые порты и процессы, которые их запросили? Например, вот так:
$ sudo netstat -tnlp

Но думаю, ты уже понял, что банальщиной мы ограничиваться не будем. Давай посмотрим теперь в реальном времени, как пакеты бегают по интерфейсам.
$ sar -n DEV 1
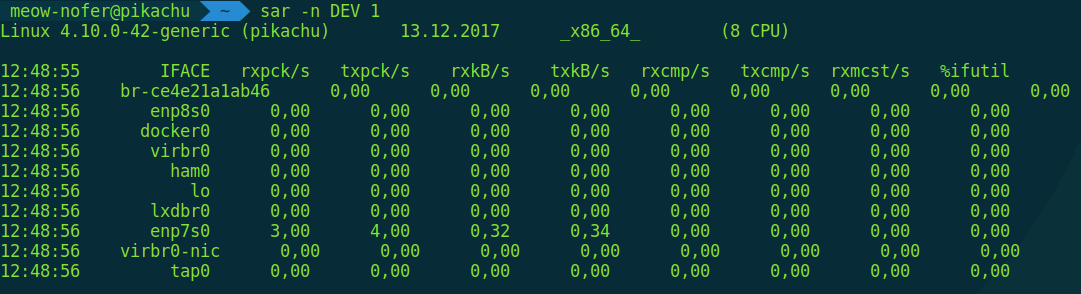
Да, sar — это еще одна отличная утилита для мониторинга. Умеет показывать не только сетевые операции, но и диски и активность процессора. Почитать о ней можешь, например, в статье «Простой мониторинг системы с помощью SAR».
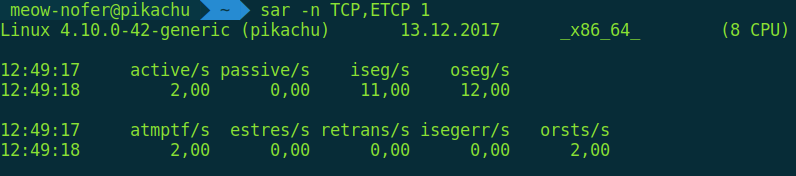
Также sar позволяет мониторить открытие/закрытие соединений и ретрансмиты (это повторные отправки тех же данных, когда сетевое оборудование сбоит или коннект крайне нестабильный, очень помогает траблшутить) в реальном времени.
$ sar -1 TCP,ETCP 1
Ну и последнее — конечно, по порядку, а не по значению — это просмотр самого сетевого трафика. Чаще всего для этого используют две утилиты: tcpdump и wireshark. Первая — консольная, ей можно, к примеру, запустить прослушивание на всех интерфейсах и записать трафик в дамп-файл в формате pcap:
$ tcpdump -w test.dump
Вторая же — графическая. Из нее можно точно так же запустить прослушивание, а можно просто открыть в ней готовый файл дампа, слитый с удаленного сервера. И наслаждаться красотой слоев модели OSI (точнее, TCP/IP).
Если тебя окружили демоны — логируй их немедленно!
Один из самых простых и банальных способов проверить, что происходит в системе, — это посмотреть системные логи. Вот тут можно почитать о том, какие секреты скрываются в каталоге /var/log и откуда они там берутся. До недавнего времени основным механизмом записи логов был syslog, точнее, его относительно современная реализация rsyslog. Она до сих пор активно используется, если интересно почитать, где там что, — можно глянуть, например, сюда.
А что в авангарде? В современных дистрибутивах Linux на основе systemd используется свой механизм логирования, которым можно управлять через утилиту journalctl. Там есть крайне удобная фильтрация по разным параметрам и прочие плюшки. Ссылка на хороший обзор.
Сам же systemd до сих пор остается довольно жарким топиком для обсуждения, поскольку «подминает» под себя многие устоявшиеся инструменты и предоставляет альтернативы к существующим решениям. Например, как запускать какой-то процесс регулярно? Crontab? Вовсе не обязательно, теперь у нас есть systemd timers. А как насчет настройки реакций на системные и «железные» события? В systemd есть поддержка watchdog. А что там со сменой корня — старый добрый chroot? Необязательно, теперь есть новенький systemd-nspawn.
Информация — это новое золото
Когда речь идет о компьютерных системах, всегда лучше знать, чем не знать, особенно в области инжиниринга и инфобезопасности. Наверняка настройка системы мониторинга с уведомлениями займет не очень много времени и принесет кучу пользы, но возможность зайти руками на удаленный сервер, из консоли за пару минут диагностировать проблему и предложить решение — это особая уличная магия, которая подвластна далеко не всем. Хорошо, что у тебя теперь есть набор инструментов для подобных фокусов, верно?










