

Содержание статьи
Данные, которые необходимо обработать в рамках комплексных расследований (журналы автоматизированных систем и средств защиты, выгрузки бизнес-систем, биллинги, транзакции, данные СКУД, артефакты операционных систем, результаты OSINT-анализа, пояснения сотрудников по факту инцидента), — это, конечно, не Big Data, но информация, также требующая специальных инструментов для фильтрации релевантных к расследованию данных, их обработки и формирования целостной картины.
INFO
СКУД — система контроля и управления доступом. Служит для ограничения входа людей на определенную территорию и регистрации их входа-выхода через установленные точки прохода (обычно турникеты).
OSINT — Open Source INTelligence — поиск, сбор и анализ информации, полученной из общедоступных источников.
Прототип одного из таких инструментов ты наверняка видел в детективных фильмах и сериалах — назовем его детективной доской. На ней вывешивают фотографии людей и мест, вырезки из газет, отчеты, а затем соединяют их разноцветными нитями.


Такие доски появляются в фильмах, чтобы показать аналитическую работу детективов, — это декорация, создающая атмосферу. Используются ли такие доски в реальной работе? Насколько они полезны?
Американский полицейский на пенсии Тим Дис рассказывает, что в докомпьютерную эпоху полиция США действительно использовала такие доски, но только для сложных расследований. Детективные доски давали ряд преимуществ, главное из которых — возможность компактно и полно представить информацию о произошедшем инциденте и связанных лицах. Такой ассоциативный способ представления позволяет быстро понять суть случившегося, а также помогает выдвигать гипотезы о том, как произошел инцидент, для дальнейшей их проверки.
Впрочем, большую часть времени такая доска была закрыта, чтобы «лишние» люди ее не увидели. Доска занимала много места и позволяла размещать информацию только об одном-двух расследованиях, а полиция параллельно ведет множество дел. Это в значительной мере снижало эффективность инструмента. Затем пришла эпоха широкого распространения компьютеров, и детективные доски перекочевали в цифру.
Оцифровка устранила ряд недостатков физических досок и добавила новые преимущества: количество одновременно размещаемых элементов на «доске», скорость занесения на нее данных, а кроме того, возможность использования математики. Ведь по сути «доска» представляет собой граф связанности, а значит, мы можем делать вычисления на графе: находить значимые узлы, пути и кластеры.
Нагляднее такой способ представления информации в рамках расследований будет показать на конкретных примерах, которые связаны с инцидентами кибербезопасности (собственно, ими в отделе расследований департамента кибербезопасности Сбербанка мы и занимаемся). Сразу договоримся, что не будем затрагивать источники и способы получения данных для построения графа, а кейсы будут синтетическими.
Кейс 1. Продавцы конфиденциальной информации
Если бы ты нашел в интернете объявление о продаже базы данных твоей компании, с чего бы начали расследование? Естественно, с проверки, что это не фейк: люди в этом бизнесе могут сверстать тестовый образец из обрывков данных, полученных из разных источников, и рекламировать это как слитую актуальную базу. Таким образом, первоочередная задача — получить как можно больше тестовых образцов для проверки на фейковость. Впрочем, параллельно проверке стоит начинать собирать:
- информацию о том, где слитые данные хранятся: пусть для данного кейса это будет АС «База1» и АС «База2»;
- информацию о пользователях и администраторах, имевших доступ и возможность неконтролируемого доступа к «слитым» данным, — пусть это будет пятнадцать пользователей и три админа — П1Б1, П2Б1, …, П5Б1; А1Б1, А2Б1; П1Б2, П2Б2, …, П10Б2; А1Б2;
- список сайтов-площадок, где продается информация: назовем их С1, С2, С3, С4;
- платежную и контактную информацию продавцов, указанную на площадках (в результате ее анализа можно выйти на личности продавцов, пусть это будут Пр1 и Пр2);
- профили продавцов Пр1 и Пр2 в соцсетях, списки «друзей»;
- профили пользователей и администраторов, имевших доступ к слитым данным, в соцсетях, списки «друзей»;
- биллинги, переписку по электронной почте и данные о денежных транзакциях всех указанных выше лиц.
Теперь задача сводится к тому, чтобы найти пересечения между продавцами и пользователями или администраторами, имевшими доступ к утекшим данным. Можно решить задачу, сравнивая поля разных таблиц, но это долго, к тому же легко допустить ошибку. Мы подобрали тестовые данные таким образом, чтобы между одним из продавцов и одним из пользователей пересечение было. Поэтому, разместив всю найденную информацию на простой схеме, мы получили примерно следующую картинку.
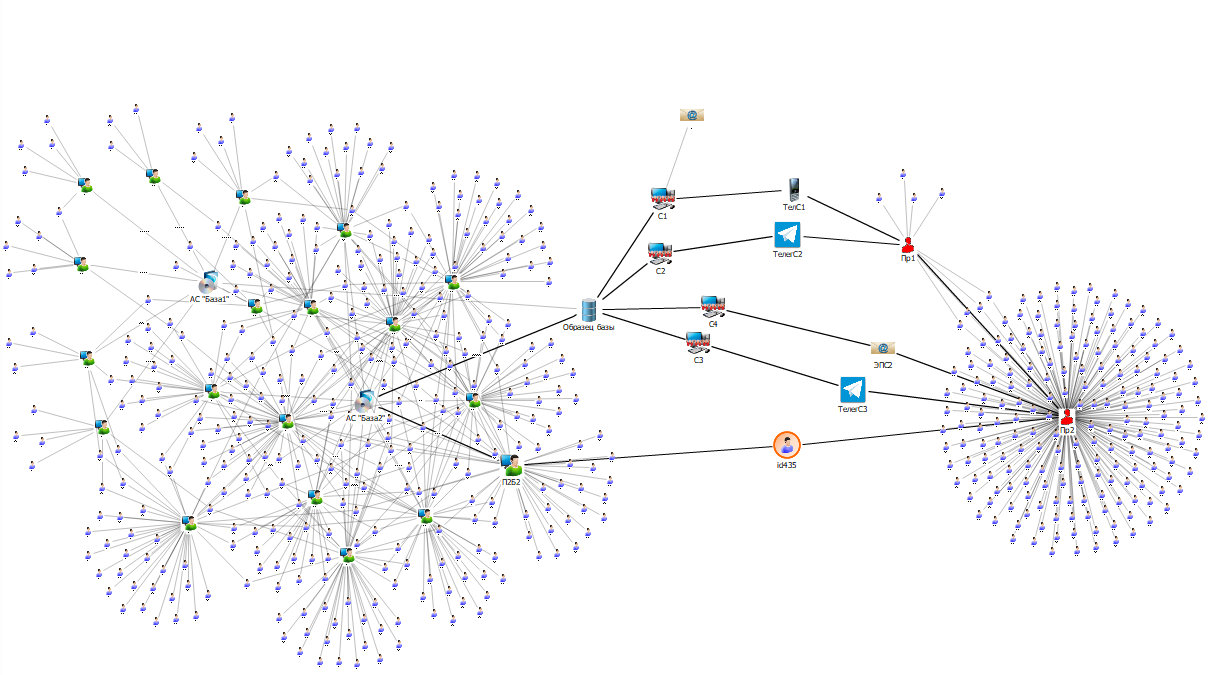
Такая схема наглядно показывает наличие общего контакта между пользователем П2Б2 и Пр2, кроме того, отражает, что этот пользователь имел доступ к слитым данным. Это, конечно, не доказательство причастности П2Б2 к утечке базы данных, но правдоподобная гипотеза, требующая более глубокой проработки. При такой проработке мы можем получить новые доказательства: например, может оказаться, что П2Б2 и Пр1 учились в одном и том же заведении в одно и то же время или что Пр1 и Пр2 живут в одном городе на соседних улицах, что мы также отобразим на схеме.
Кроме того что такая схема удобна для восприятия, она отвечает на некоторые незаданные вопросы: нет ли других связей сотрудников из списка потенциальных нарушителей с продавцами? Как именно вышли на того или иного продавца? Связаны ли продавцы?
Кейс 2. Серия фишинговых атак
Предположим, твоя компания столкнулась с несколькими фишинговыми рассылками и вы подозреваете, что они связаны, так как сценарии одинаковы: доставка писем с вредоносной ссылкой или вложением на схожий пул адресов корпоративной почты за короткий период времени.
- Первая атака: письма с адреса
support@evildomain1.comна 40 адресов со ссылкойhttps://evillink1.com. По ссылке грузится вредонос 1, управляемый через2Cserver1.com. - Вторая атака: письма с адреса
info@evildomain2.comна 20 адресов с вложениемevil.pdf. Открытие вложения приводит к эксплуатации уязвимости и скачиванию вредоноса 2 с адресаhttps://evillink2.com, который управляется через2Cserver2.com. - Третья атака: письма с адреса
sonotreply@evildomain3.comна 30 адресов со ссылкойhttps://evillink3.com. По ссылке загружается вредонос 3, управляемый через2Cserver3.com.
Нарисуем схемы атак.
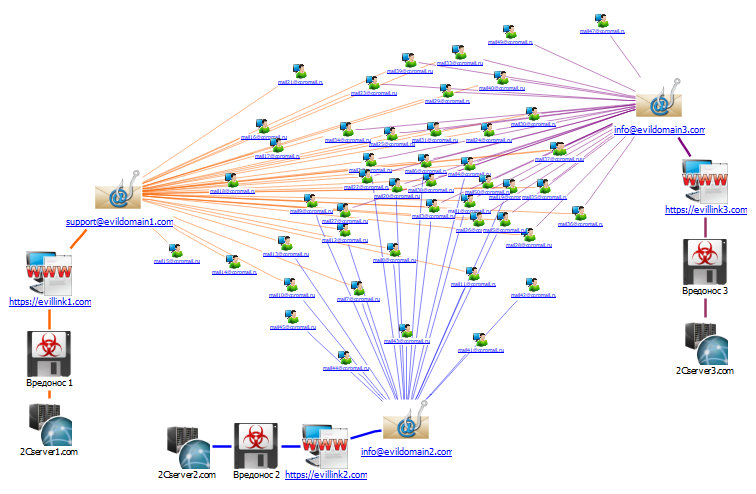
Сейчас эти три атаки объединены только общими получателями (что и послужило причиной гипотезы о связи между атаками). Схемы хоть и схожи, но это крайне косвенный показатель: под него подойдут и многие другие атаки.
Забудем на время получателей, а по остальным сущностям соберем дополнительную информацию: технические заголовки писем (домены и IP-адреса в заголовках Received, интересные X-заголовки) и данные whois найденных доменов и IP-адресов (даты регистрации, дополнительные IP, домены, регистранты, телефоны и адреса email).
INFO
Иногда полезную информацию для нахождения общих признаков (помимо C&C-серверов) можно выделить при анализе самого вредоноса. Например, метаданные, время компиляции, способ кодирования, паттерны имен.
Найденную информацию разместим на схеме таким образом, чтобы были видны элементы атак, характерные сразу для нескольких волн. В данном случае общие элементы: регистратор доменных имен и время регистрации доменов, удостоверяющий центр, который использовали для покупки сертификатов SSL. Кроме того, как выяснилось, в обеих атаках местами фигурировал один и тот же IP-адрес. Это позволяет нам объединить все три атаки в один кейс (и быстро объяснить заинтересованным лицам, почему мы это сделали).
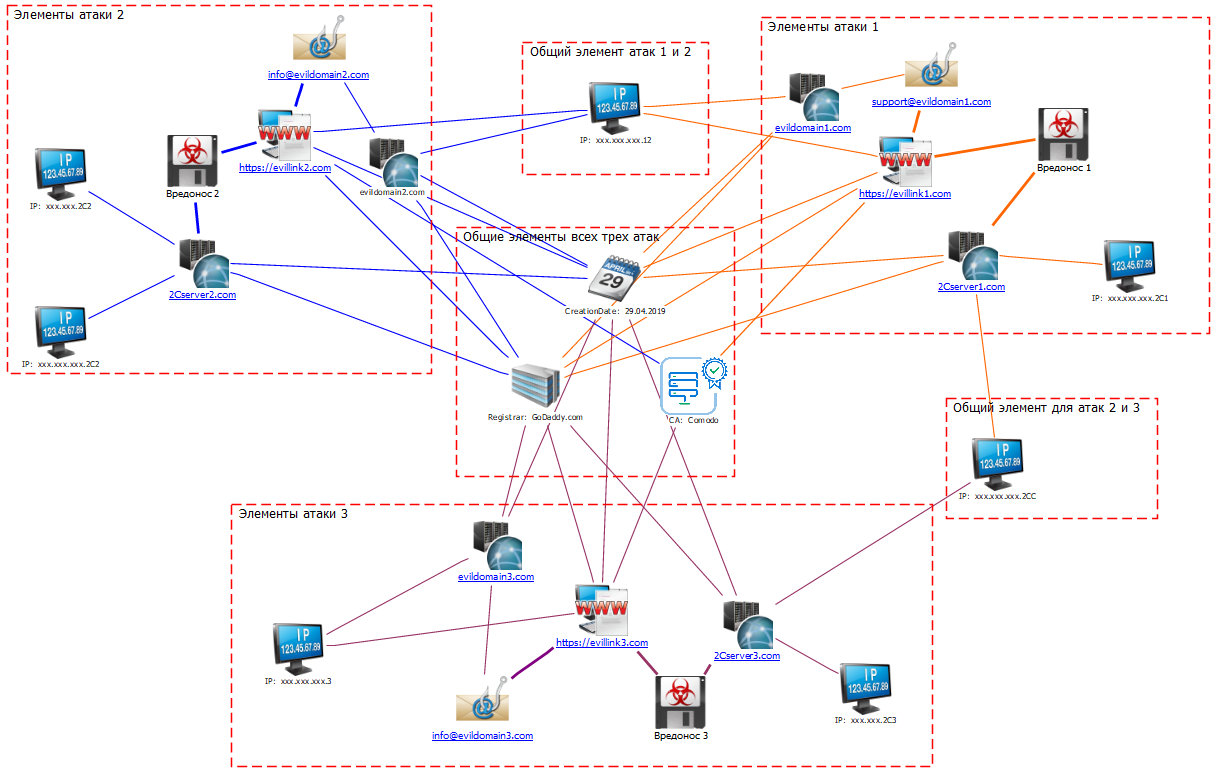
Такая схема лаконична и, думаю, понятна. Но здесь в отличие от первого кейса нет значительных объемов данных, которые требуется сравнить, поэтому логичный вопрос — зачем нужно такое представление, ведь общие элементы можно было описать в двух-трех предложениях?
Основная цель графовой модели — не доставить эстетическое наслаждение, а дать целостную картину, отсеяв нерелевантную информацию. Кроме того, граф масштабируем и, если будут еще фишинговые рассылки, может быть дополнен новыми элементами.
Кейс 3. Расследование информационных атак
Ранее в качестве преимущества графовых моделей упоминалась возможность использования теории графов, а до этого момента было продемонстрировано использование графа только как инструмента визуализации. Дело в том, что в предыдущих кейсах математика на графах была избыточна. Для ее демонстрации возьмем новый кейс: информационную атаку на организацию.
При расследовании таких кейсов первое, что стоит сделать, — это определить, действительно ли имеет место информационная атака, или же мы столкнулись с естественным распространением негатива. Для этого анализируем как сам контент (поиск признаков SEO- и SMM-оптимизации), так и характер распространения контента: время его «переброса» между площадками, доля ботов, участвующих в распространении, наличие платной рекламы, характер затухания интереса к контенту.
Предположим, нам удалось установить всю цепочку распространения информации (на картинке ниже) и построить на основе этих данных ориентированный граф. «Нулевой пациент» окрашен коричневым. Возьмем самый начальный этап распространения контента (выделен прямоугольником).
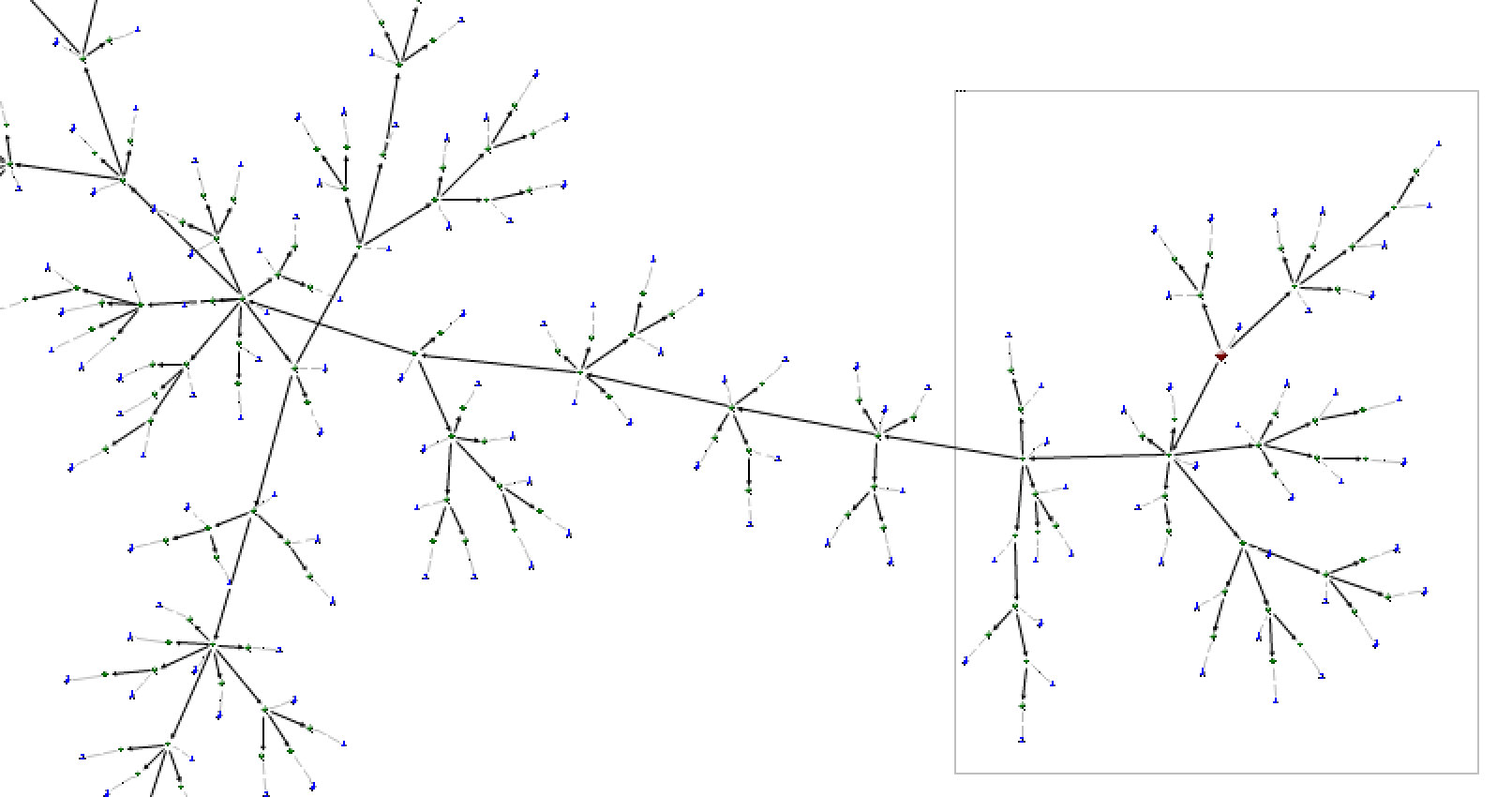
Кстати, на таком графе легко обнаруживается явный признак информационных атак — «карусели». Принцип «карусели»: информационный источник 1 ссылается на информационный источник 2, тот на источник 3, а источник 3 на источник 1 (естественно, источников в цепочке может быть больше) — такие «карусели» будут отображаться на графе как замкнутые петли.
Если информация распространяется в соцсетях, загрузив списки друзей и указав путь распространения информации, получим, к примеру, такой граф.
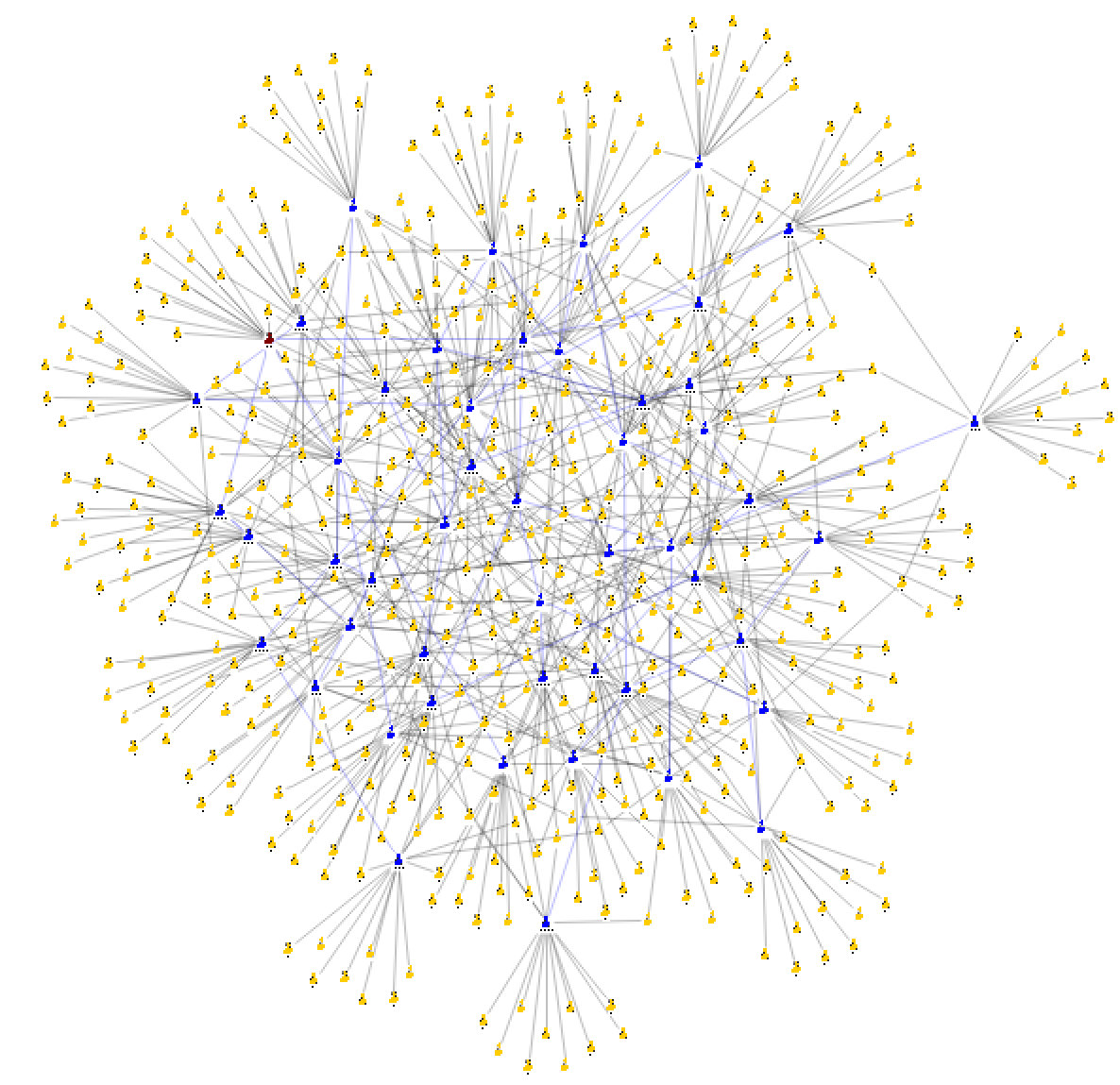
Синим на рисунке выделены те, кто участвовал в цепочке распространения. Подобный граф говорит о необычном распространении информации, так как связи между друзьями распространителей носят случайный характер.
Когда за аккаунтами-распространителями находятся обычные живые люди, цепочка вместе с друзьями распространителей будет выглядеть скорее следующим образом.
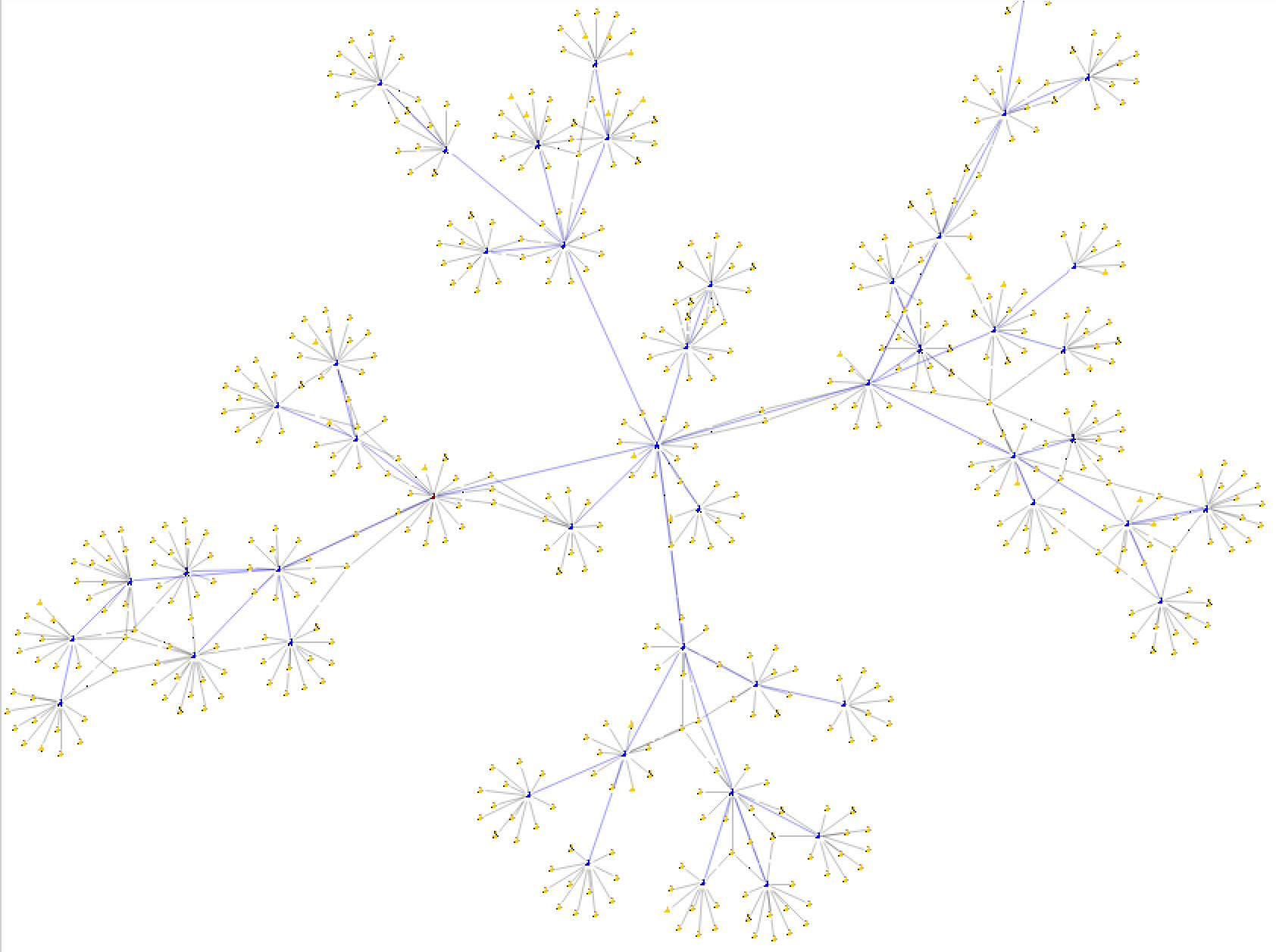
Реальный граф будет отличаться от представленного выше количеством друзей у каждого из распространителей — их будет значительно больше.
Теперь вернемся к математике на графе — вычисляем ключевые узлы и кластеры.
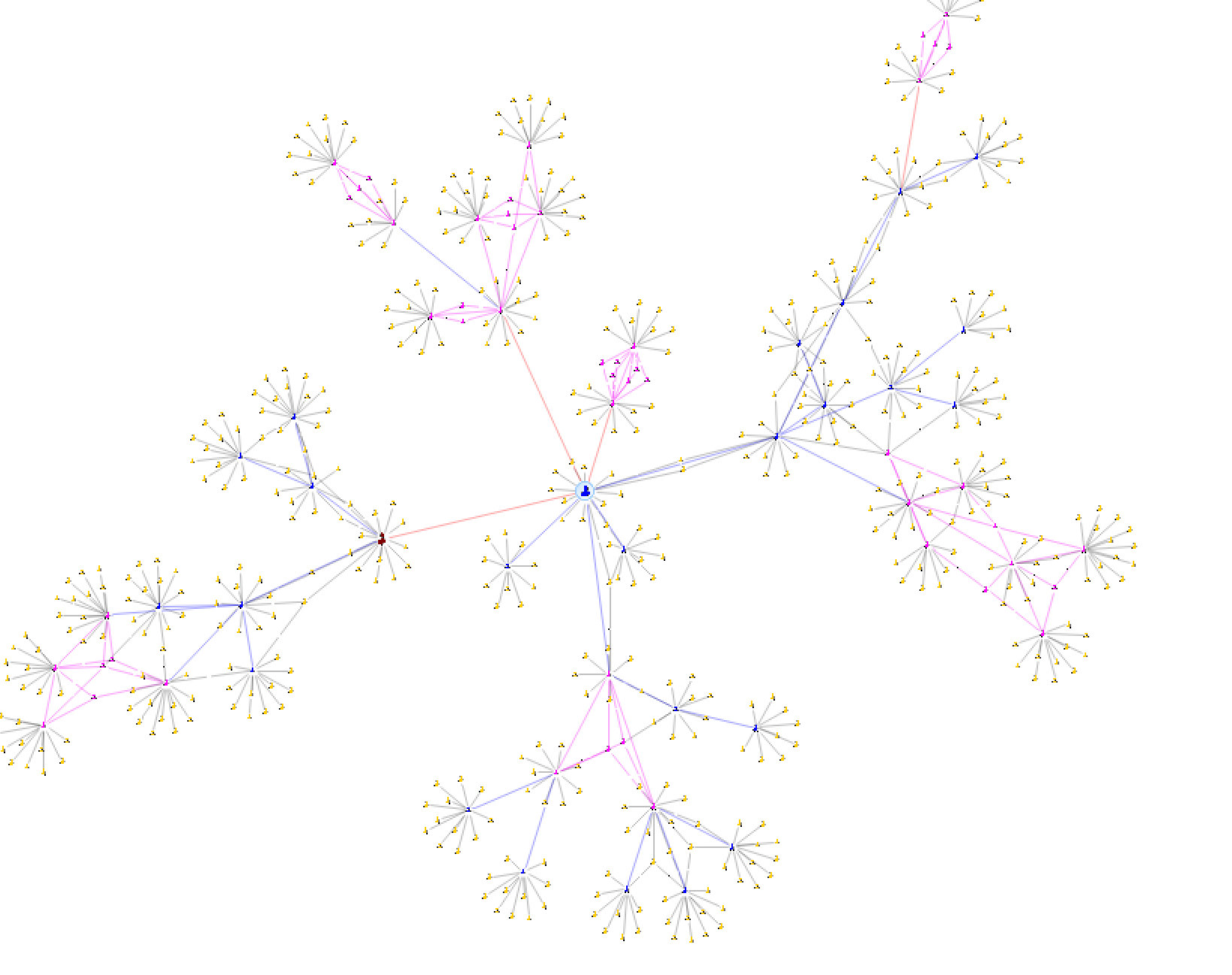
1. Поиск узлов с максимальной «промежуточностью»
Промежуточность определяется как количество раз, когда вершина встречается в кратчайших путях между любыми другими вершинами. Чем больше промежуточность элемента, тем на большее число кусочков распадется граф, если этот элемент убрать. Применительно к соцсетям — это тот аккаунт, через который можно транслировать мнение на наибольшее число обособленных сообществ. Вершина графа с наибольшей промежуточностью на рисунке выше легко прослеживается — узел в самом центре. В первую очередь проведем углубленный анализ именно таких вершин.
2. Поиск кластеров
Кластерный анализ позволяет найти тесно связанные группы узлов — по сути, распространителей, у которых больше всего общих друзей. Такие группы обозначим на схеме сиреневым. Далее ищем, что связывает аккаунты, составляющие каждый из кластеров. Возможно, это члены одной группы или жители одного города, учащиеся одного учебного заведения и подобное. Это даст информацию о том, какие социальные группы первыми подхватили новость.
3. Нетипичное распространение
Применительно к социальной сети нехарактерна ситуация, когда у двух соседних распространителей отсутствуют общие друзья. Такое распространение зачастую говорит о том, что новость искали специально для дальнейшего распространения.
Таким образом, по совокупности признаков предполагаем, имела ли место информационная атака, а по кластерам и ключевым узлам — кто за ней стоит.
Заключение
Способ отображения информации об инциденте играет важнейшую роль в восприятии и, как следствие, понимании и установлении причин и обстоятельств инцидента — в основных задачах расследования. В ряде случаев наиболее эффективный для восприятия способ отображения — представление информации в виде графа. Такой способ использовался и в докомпьютерную эпоху, но после распространения компьютеров приобрел новые преимущества, так как устранял ограничения, связанные с количеством отображаемой информации, скоростью построения и сложностью сокрытия от посторонних глаз. Кроме того, в электронном виде проще применять математику на графах.
Использование графов типично при расследованиях, связанных с социальными сетями или банковскими транзакциями, и других расследованиях, в рамках которых изучаются связи однородных элементов. В статье рассмотрены кейсы с отображением на графе разнородных элементов, информация о которых получена из различных источников.
Впрочем, не все так радужно. В значительном числе случаев построение графа окажется избыточным шагом. Мы периодически сталкиваемся с применением графовых моделей там, где в них нет необходимости, поскольку решить задачу другими инструментами куда проще. Графы, как и любой другой инструмент, стоит использовать там, где они будут эффективны. Но, увы, не всегда сразу понятно, принесет ли пользу построение графа. Тем не менее рекомендую попробовать: это интересно, эстетично и, как правило, нравится руководству. 🙂
