


Содержание статьи
- Что такое фаззинг
- Простой способ
- Запускаем ядро
- Разбираемся со вводами
- [Не] автоматизируем
- Готово
- Способ получше
- Собираем покрытие
- Ловим баги
- Автоматизируем
- Все вместе
- Навороченные идеи
- Вытаскиваем код в юзерспейс
- Фаззим внешние интерфейсы
- За пределами API-aware-фаззинга
- Структурируем внешние вводы
- Помимо KCOV
- Собираем релевантное покрытие
- За пределами сбора покрытия кода
- Собираем корпус вводов
- Ловим больше багов
- Итоги и советы
- Выводы
info
Статья написана редакцией «Хакера» по мотивам доклада «Фаззинг ядра Linux» Андрея Коновалова при участии докладчика и изложена от первого лица с его разрешения.
Когда я говорю об атаках на USB, многие сразу вспоминают Evil HID — одну из атак типа BadUSB. Это когда подключаемое устройство выглядит безобидно, как флешка, а на самом деле оказывается клавиатурой, которая автоматически открывает консоль и делает что‑нибудь нехорошее.
В рамках моей работы по фаззингу такие атаки меня не интересовали. Я искал в первую очередь повреждения памяти ядра. В случае атаки через USB сценарий похож на BadUSB: мы подключаем специальное USB-устройство и оно начинает делать нехорошие вещи. Но оно не набирает команды, прикидываясь клавиатурой, а эксплуатирует уязвимость в драйвере и получает исполнение кода внутри ядра.
За годы работы над фаззингом ядра у меня скопилась коллекция ссылок и наработок. Я их упорядочил и превратил в доклад. Сейчас я расскажу, какие есть способы фаззить ядро, и дам советы начинающим исследователям, которые решат заняться этой темой.
Что такое фаззинг
Фаззинг — это способ искать ошибки в программах.
Как он работает? Мы генерируем случайные данные, передаем их на вход программе и проверяем, не сломалась ли она. Если не сломалась — генерируем новый ввод. Если сломалась — прекрасно, мы нашли баг. Предполагается, что программа не должна падать от неожиданного ввода, она должна этот ввод корректно обрабатывать.
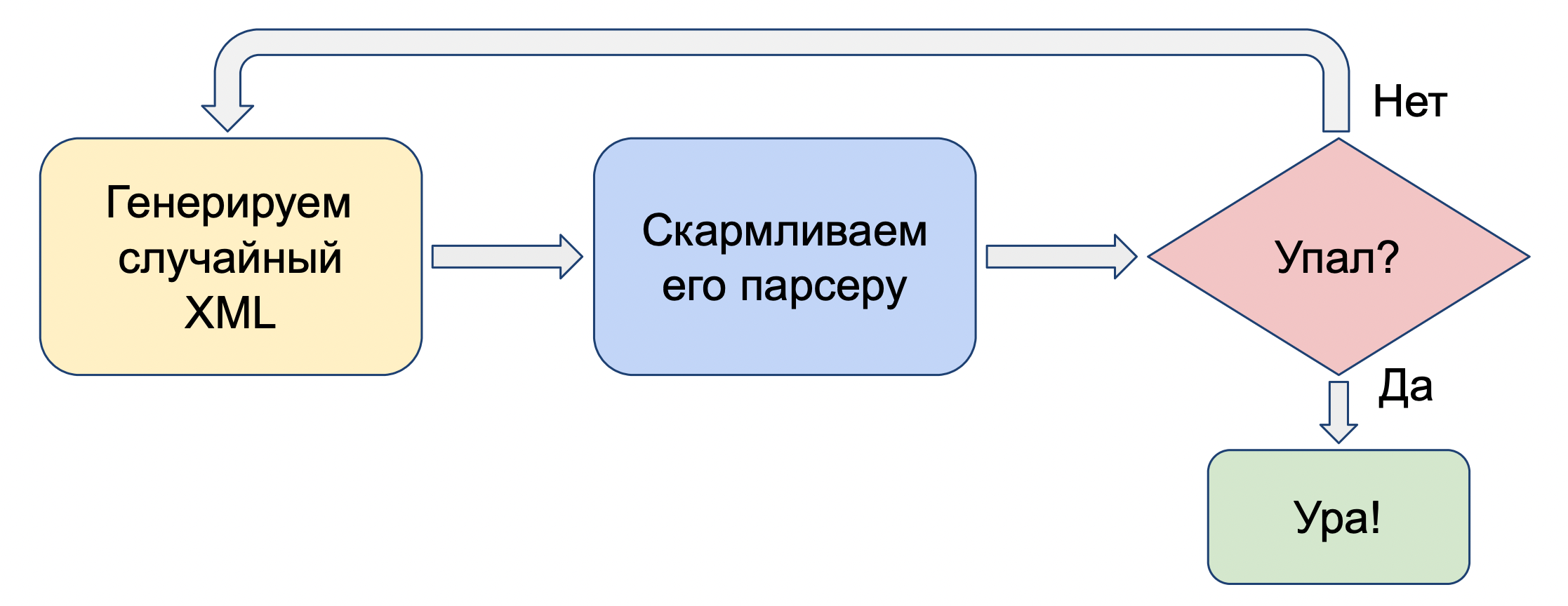
Конкретный пример: мы берем XML-парсер и скармливаем ему случайно сгенерированные XML-файлы. Если он упал — мы нашли баг в парсере.
Фаззеры можно делать для любой штуки, которая обрабатывает входные данные. Это может быть приложение или библиотека в пространстве пользователя — юзерспейсе. Это может быть ядро, может быть прошивка, а может быть даже железо.
Когда мы начинаем работать над фаззером для очередной программы, нам нужно разобраться со следующими вопросами:
- Как программу запускать? В случае приложения в юзерспейсе — запустить бинарник. А вот запустить ядро или части прошивки так просто не выйдет.
- Что служит входными данными? Для XML-парсера входные данные — XML-файлы. А, например, браузер и обрабатывает HTML, и исполняет JavaScript.
- Как входные данные программе передавать? В простейшем случае данные передаются на стандартный ввод или в виде файла. Но программы могут получать данные и через другие каналы. Например, прошивка может получать их от физических устройств.
- Как генерировать вводы? «Вводом» будем называть набор данных, переданный программе на вход. В качестве ввода можно создавать массивы рандомных байтов, а можно делать что‑нибудь более умное.
- Как определять факт ошибки? Если программа упала — это баг. Но существуют ошибки, которые не приводят к падению. Пример: утечка информации. Такие ошибки тоже хочется находить.
- Как автоматизировать процесс? Можно запускать программу с новыми вводами вручную и смотреть, не упала ли она. А можно написать скрипт, который будет делать это автоматически.
Сегодня мы говорим о ядре Linux, так что в каждом из вопросов мы можем мысленно заменить слово «программа» на «ядро Linux». А теперь давай попробуем найти ответы.
Простой способ
Для начала придумаем ответы попроще и разработаем первую версию нашего фаззера.
Запускаем ядро
Начнем с того, как ядро запускать. Здесь есть два способа: использовать железо (компьютеры, телефоны или одноплатники) или использовать виртуальные машины (например, QEMU). У каждого свои плюсы и минусы.
Когда запускаешь ядро на железе, то получаешь систему в том виде, в котором она работает в реальности. Например, там доступны и работают драйверы устройств. В виртуалке доступны только те фичи, которые она поддерживает.
С другой стороны, железом гораздо сложнее управлять: разливать ядра, перезагружать в случае падения, собирать логи. Виртуалка в этом плане идеальна.
Еще один плюс виртуальных машин — масштабируемость. Чтобы фаззить на большем количестве железок, их надо купить, что может быть дорого или логистически сложно. Для масштабирования фаззинга в виртуалках достаточно взять машину помощнее и запустить их сколько нужно.

Учитывая особенности каждого из способов, виртуалки выглядят как лучший вариант. Но давай для начала ответим на остальные вопросы. Глядишь, мы придумаем способ фаззить, который не привязан к способу запуска ядра.
Разбираемся со вводами
Что является входными данными для ядра? Ядро обрабатывает системные вызовы — сисколы (syscall). Как передать их в ядро? Давай напишем программу, которая делает последовательность вызовов, скомпилируем ее в бинарь и запустим. Всё: ядро будет интерпретировать наши вызовы.

Теперь разберемся с тем, какие данные передавать в сисколы в качестве аргументов и в каком порядке сисколы вызывать.
Самый простой способ генерировать данные — брать случайные байты. Этот способ работает плохо: обычно программы, включая то же ядро, ожидают данные в более‑менее корректном виде. Если передать им совсем мусор, даже элементарные проверки на корректность не пройдут, и программа откажется обрабатывать ввод дальше.
Способ лучше: генерировать данные на основе грамматики. На примере XML-парсера: мы можем заложить в грамматику знание о том, что XML-файл состоит из XML-тегов. Таким образом мы обойдем элементарные проверки и проникнем глубже внутрь кода парсера.
Однако для ядра такой подход надо адаптировать: ядро принимает последовательность сисколов с аргументами, а это не просто массив байтов, даже сгенерированных по определенной грамматике.
Представь программу из трех сисколов: open, который открывает файл, ioctl, который совершает операцию над этим файлом, и close, который файл закрывает. Для open первый аргумент — это строка, то есть простая структура с единственным фиксированным полем. Для ioctl, в свою очередь, первый аргумент — значение, которое вернул open, а третий — сложная структура с несколькими полями. Наконец, в close передается все тот же результат open.
int fd = open("/dev/something", …);ioctl(fd, SOME_IOCTL, &{0x10, ...});close(fd);Целиком эта программа — типичный ввод, который обрабатывает ядро. То есть вводы для ядра представляют собой последовательности сисколов. Причем их аргументы структурированы, а их результат может передаваться от одного сискола к другому.
Это все похоже на API некой библиотеки — его вызовы принимают структурированные аргументы и возвращают результаты, которые могут передаваться в следующие вызовы.
Получается, что, когда мы фаззим сисколы, мы фаззим API, который предоставляет ядро. Я такой подход называю API-aware-фаззинг.
В случае ядра Linux, к сожалению, точного описания всех возможных сисколов и их аргументов нет. Есть несколько попыток сгенерировать эти описания автоматически, но ни одна из них не выглядит удовлетворительной. Поэтому единственный способ — это написать описания руками.
Так и сделаем: выберем несколько сисколов и разработаем алгоритм генерирования их последовательностей. Например, заложим в него, что в ioctl должен передаваться результат open и структура правильного типа со случайными полями.
[Не] автоматизируем
С автоматизацией пока не будем заморачиваться: наш фаззер в цикле будет генерировать вводы и передавать их ядру. А мы будем вручную мониторить лог ядра на предмет ошибок типа kernel panic.
Готово
Всё! Мы ответили на все вопросы и разработали простой способ фаззинга ядра.
| Вопрос | Ответ |
|---|---|
| Как запускать ядро? | В QEMU или на реальном железе |
| Что будет входными данными? | Системные вызовы |
| Как входные данные передавать ядру? | Через запуск исполняемого файла |
| Как генерировать вводы? | На основе API ядра |
| Как определять наличие багов? | По kernel panic |
| Как автоматизировать? | while ( |
Наш фаззер представляет собой бинарник, который в случайном порядке вызывает сисколы с более‑менее корректными аргументами. Поскольку бинарник можно запустить и на виртуалке, и на железе, то фаззер получился универсальным.
Ход рассуждений был простым, но сам подход работает прекрасно. Если специалиста по фаззингу ядра Linux спросить: «Какой фаззер работает описанным способом?», то он сразу скажет: Trinity! Да, фаззер с таким алгоритмом работы уже существует. Одно из его преимуществ — он легко переносимый. Закинул бинарь в систему, запустил — и все, ты уже ищешь баги в ядре.
Способ получше
Фаззер Trinity сделали давно, и с тех пор мысль в области фаззинга ушла дальше. Давай попробуем улучшить придуманный способ, использовав более современные идеи.
Собираем покрытие
Идея первая: для генерации вводов использовать подход coverage-guided — на основе сборки покрытия кода.
Как он работает? Помимо генерирования случайных вводов с нуля, мы поддерживаем набор ранее сгенерированных «интересных» вводов — корпус. И иногда, вместо случайного ввода, мы берем один ввод из корпуса и его слегка модифицируем. После чего мы исполняем программу с новым вводом и проверяем, интересен ли он. А интересен ввод в том случае, если он позволяет покрыть участок кода, который ни один из предыдущих исполненных вводов не покрывает. Если новый ввод позволил пройти дальше вглубь программы, то мы добавляем его в корпус. Таким образом, мы постепенно проникаем все глубже и глубже, а в корпусе собираются все более и более интересные программы.

Этот подход используется в двух основных инструментах для фаззинга приложений в юзерспейсе: AFL и libFuzzer.
Coverage-guided-подход можно скомбинировать с использованием грамматики. Если мы модифицируем структуру, можем делать это в соответствии с ее грамматикой, а не просто случайно выкидывать байты. А если вводом является последовательность сисколов, то изменять ее можно, добавляя или удаляя вызовы, переставляя их местами или меняя их аргументы.
Для coverage-guided-фаззинга ядра нам нужен способ собирать информацию о покрытии кода. Для этой цели был разработан инструмент KCOV. Он требует доступа к исходникам, но для ядра у нас они есть. Чтобы включить KCOV, нужно пересобрать ядро с включенной опцией CONFIG_KCOV, после чего покрытие кода ядра можно собирать через /.
info
KCOV позволяет собирать покрытие кода ядра с текущего потока, игнорируя фоновые процессы. Таким образом, фаззер может собирать релевантное покрытие только для тех сисколов, которые он исполняет.
Ловим баги
Теперь давай придумаем что‑нибудь получше для обнаружения багов, чем выпадение в kernel panic.
Паника в качестве индикатора багов работает плохо. Во‑первых, некоторые баги ее не вызывают, как упомянутые утечки информации. Во‑вторых, в случае повреждения памяти паника может случиться намного позже, чем произошел сам сбой. В таком случае баг очень сложно локализовать — непонятно, какое из последних действий фаззера его вызвало.
Для решения этих проблем придумали динамические детекторы багов. Слово «динамические» означает, что они работают в процессе исполнения программы. Они анализируют ее действия в соответствии со своим алгоритмом и пытаются поймать момент, когда произошло что‑то плохое.
Для ядра таких детекторов несколько. Самый крутой из них — KASAN. Крут он не потому, что я над ним работал, а потому, что он находит главные типы повреждений памяти: выходы за границы массива и use-after-free. Для его использования достаточно включить опцию CONFIG_KASAN, и KASAN будет работать в фоне, записывая репорты об ошибках в лог ядра при обнаружении.
info
Больше о динамических детекторах для ядра можно узнать из доклада Mentorship Session: Dynamic Program Analysis for Fun and Profit Дмитрия Вьюкова (слайды).
Автоматизируем
Что касается автоматизации, то тут можно придумать много всего интересного. Автоматически можно:
- мониторить логи ядра на предмет падений и срабатываний динамических детекторов;
- перезапускать виртуальные машины с упавшими ядрами;
- пробовать воспроизводить падения, запуская последние несколько вводов, которые были исполнены до падения;
- сообщать о найденных ошибках разработчикам ядра.
Как это все сделать? Написать код и включить его в наш фаззер. Исключительно инженерная задача.
Все вместе
Возьмем эти три идеи — coverage-guided-подход, использование динамических детекторов и автоматизацию процесса фаззинга — и включим в наш фаззер. У нас получится следующая картина.
| Вопрос | Ответ |
|---|---|
| Как запускать ядро? | В QEMU или на реальном железе |
| Что будет входными данными? | Системные вызовы |
| Как входные данные передавать ядру? | Через запуск исполняемого файла |
| Как генерировать вводы? | Знание API + KCOV |
| Как определять наличие багов? | KASAN и другие детекторы |
| Как автоматизировать? | Все перечисленные выше штуки |
Если опять‑таки спросить знающего человека, какой фаззер ядра использует эти подходы, тебе сразу ответят: syzkaller. Сейчас syzkaller — это передовой фаззер ядра Linux. Он нашел тысячи ошибок, включая эксплуатируемые уязвимости. Практически любой, кто занимался фаззингом ядра, имел дело с этим фаззером.
info
Иногда можно услышать, что KASAN является неотделимой частью syzkaller. Это не так. KASAN можно использовать и с Trinity, а syzkaller — и без KASAN.
Навороченные идеи
Использовать идеи syzkaller — это крепкий подход к фаззингу ядра. Но давай пойдем дальше и обсудим, как наш фаззер можно сделать еще более навороченным.
Вытаскиваем код в юзерспейс
Мы обсуждали два варианта, как запустить ядро для фаззинга: использовать виртуалки или железки. Но есть еще один способ: можно вытащить код ядра в юзерспейс. Для этого нужно взять какую‑нибудь изолированную подсистему и скомпилировать ее как библиотеку. Тогда ее можно будет пофаззить с помощью инструментов для фаззинга обычных приложений.
Для некоторых подсистем это сделать несложно. Если подсистема просто выделяет память с помощью kmalloc и освобождает ее через kfree и на этом привязка к ядерным функциям заканчивается, тогда мы можем заменить kmalloc на malloc и kfree на free. Дальше мы компилируем код как библиотеку и фаззим с помощью того же libFuzzer.
Для большинства подсистем с этим подходом возникнут сложности. Требуемая подсистема может использовать API, которые в юзерспейсе попросту недоступны. Например, RCU.
info
RCU (Read-Copy-Update) — механизм синхронизации в ядре Linux.
Еще один минус этого подхода в том, что если вытащенный в юзерспейс код обновился, то его придется вытаскивать заново. Можно попробовать этот процесс автоматизировать, но это может быть сложно.
Этот подход использовался для фаззинга eBPF, ASN.1-парсеров и сетевой подсистемы ядра XNU.
Фаззим внешние интерфейсы
Данные из юзерспейса в ядро могут передаваться через сисколы; о них мы уже говорили. Но поскольку ядро — это прослойка между железом и программами пользователя, у него есть также входы и со стороны устройств.

Другими словами, ядро обрабатывает данные, приходящие через Ethernet, USB, Bluetooth, NFC, мобильные сети и прочие железячные протоколы.
Например, мы послали на систему TCP-пакет. Ядро должно его распарсить, чтобы понять, на какой порт он пришел и какому приложению его доставить. Отправляя случайно сгенерированные TCP-пакеты, мы можем фаззить сетевую подсистему с внешней стороны.
Возникает вопрос: как доставлять в ядро данные со стороны внешних интерфейсов? Сисколы мы просто звали из бинарника, а если мы хотим общаться с ядром по USB, то такой подход не пройдет.
Доставлять данные можно через реальное железо: например, отправлять сетевые пакеты по сетевому кабелю или использовать Facedancer для USB. Но такой подход плохо масштабируется: хочется иметь возможность фаззить внутри виртуалки.
Здесь есть два решения.
Первое — это написать свой драйвер, который воткнется в нужное место внутри ядра и доставит туда наши данные. А самому драйверу данные мы будем передавать через сисколы. Для некоторых интерфейсов такие драйверы уже есть в ядре.
Например, сеть я фаззил через TUN/TAP. Этот интерфейс позволяет отправлять в ядро сетевые пакеты так, что пакет проходит через те же самые пути парсинга, как если бы он пришел извне. В свою очередь, для фаззинга USB мне пришлось написать свой драйвер.
Второе решение — доставлять ввод в ядро виртуальной машины со стороны хоста. Если виртуалка эмулирует сетевую карту, она может сэмулировать и ситуацию, когда на сетевую карту пришел пакет.
Такой подход применяется в фаззере vUSBf. В нем использовали QEMU и протокол usbredir, который позволяет с хоста подключать USB-устройства внутрь виртуалки.
За пределами API-aware-фаззинга
Ранее мы смотрели на сисколы как на последовательности вызовов со структурированными аргументами, где результат одного сискола может использоваться в следующем. Но не все сисколы работают таким простым образом.
Пример: clone и sigaction. Да, они тоже принимают аргументы, тоже могут вернуть результат, но при этом они порождают еще один поток исполнения. clone создает новый процесс, а sigaction позволяет настроить обработчик сигнала, которому передастся управление, когда этот сигнал придет.
Хороший фаззер для этих сисколов должен учитывать эту особенность и, например, фаззить из каждого порожденного потока исполнения.
О сложных подсистемах
Есть еще подсистемы eBPF и KVM. В качестве вводов вместо простых структур они принимают последовательность исполняемых инструкций. Сгенерировать корректную цепочку инструкций — это гораздо более сложная задача, чем сгенерировать корректную структуру. Для фаззинга таких подсистем нужно разрабатывать специальные фаззеры. Навроде фаззера JavaScript-интерпретаторов fuzzilli.
Структурируем внешние вводы
Представим, что мы фаззим ядро со стороны сети. Может показаться, что фаззинг сетевых пакетов — это та же генерация и отправка обычных структур. Но на самом деле сеть работает как API, только с внешней стороны.
Пример: пусть мы фаззим TCP и у нас на хосте есть сокет, с которым мы хотим установить соединение извне. Казалось бы, мы посылаем SYN, хост отвечает SYN/ACK, мы посылаем ACK — все, соединение установлено. Но в полученном нами пакете SYN/ACK содержится номер подтверждения, который мы должны вставить в пакет ACK. В каком‑то смысле это возврат значения из ядра, но с внешней стороны.
То есть внешнее взаимодействие с сетью — это последовательность вызовов (отправок пакетов) и использование их возвращаемых значений (номеров подтверждения) в следующих вызовах. Получаем, что сеть работает как API и для нее применимы идеи API-aware-фаззинга.
Про USB
USB — необычный протокол: там все общение инициируется хостом. Поэтому даже если мы нашли способ подключать USB-устройства извне, то мы не можем просто так посылать данные на хост. Вместо этого нужно дождаться запроса от хоста и на этот запрос ответить. При этом мы не всегда знаем, какой запрос придет следующим. Фаззер USB должен учитывать эту особенность.
Помимо KCOV
Как еще можно собирать покрытие кода, кроме как с помощью KCOV?
Во‑первых, можно использовать эмуляторы. Представь, что виртуалка эмулирует ядро инструкция за инструкцией. Мы можем внедриться в цикл эмуляции и собирать оттуда адреса инструкций. Этот подход хорош тем, что, в отличие от KCOV, тут не нужны исходники ядра. Как следствие, этот способ можно использовать для закрытых модулей, которые доступны в виде бинарников. Так делают фаззеры TriforceAFL и UnicoreFuzz.
Еще один способ собирать покрытие — использовать аппаратные фичи процессора. Например, kAFL использует Intel PT.
Стоит отметить, что упомянутые реализации этих подходов экспериментальные и требуют доработки для практического использования.
Собираем релевантное покрытие
Для coverage-guided-фаззинга нам нужно собирать покрытие с кода подсистемы, которую мы фаззим.
Сборка покрытия из текущего потока, которую мы обсуждали до сих пор, работает для этой цели не всегда: подсистема может обрабатывать вводы в других контекстах. Например, некоторые сисколы создают новый поток в ядре и обрабатывают ввод там. В случае того же USB пакеты обрабатываются в глобальных потоках, которые стартуют при загрузке ядра и никак к юзерспейсу не привязаны.
Для решения этой проблемы я реализовал в KCOV возможность собирать покрытие с фоновых потоков и программных прерываний. Она требует добавления аннотаций в участки кода, с которых хочется собирать покрытие.
За пределами сбора покрытия кода
Направлять процесс фаззинга можно не только с помощью покрытия кода.
Например, можно отслеживать состояние ядра: мониторить участки памяти или следить за изменением состояний внутренних объектов. И добавлять в корпус вводы, которые вводят объекты в ядре в новые состояния.
Чем в более сложное состояние мы заведем ядро во время фаззинга, тем больше шанс, что мы наткнемся на ситуацию, которую оно не сможет корректно обработать.
Собираем корпус вводов
Еще один способ генерации вводов — сделать это на основе действий реальных программ. Реальные программы уже взаимодействуют с ядром нетривиальным образом и проникают глубоко внутрь кода. Сгенерировать такое же взаимодействие с нуля может быть невозможно даже для очень умного фаззера.
Я видел такой подход в проекте Moonshine: авторы запускали системные утилиты под strace, собирали с них лог и использовали полученную последовательность сисколов как ввод для фаззинга с помощью syzkaller.
Ловим больше багов
Существующие динамические детекторы неидеальны и могут не замечать некоторые ошибки. Как находить такие ошибки? Улучшать детекторы.
Можно, к примеру, взять KASAN (напомню, он ищет повреждения памяти) и добавить аннотации для какого‑нибудь нового аллокатора. По умолчанию KASAN поддерживает стандартные аллокаторы ядра, такие как slab и page_alloc. Но некоторые драйверы выделяют здоровенный кусок памяти и потом самостоятельно его нарезают на блоки помельче (привет, Android!). KASAN в таком случае не сможет найти переполнение из одного блока в другой. Нужно добавлять аннотации вручную.
Еще есть KMSAN — он умеет находить утечки информации. По умолчанию он ищет утечки данных ядра в юзерспейс. Но данные могут утекать и через внешние интерфейсы, например по сети или по USB. Для таких случаев KMSAN можно доработать.
Можно делать свои баг‑детекторы с нуля. Самый простой способ — добавить в исходники ядра ассерты. Если мы знаем, что в определенном месте всегда должно выполняться определенное условие, — добавляем BUG_ON и начинаем фаззить. Если BUG_ON сработал — баг найден. А мы сделали элементарный детектор логической ошибки. Такие детекторы особенно интересны в контексте фаззинга eBPF, потому что ошибка в eBPF обычно не приводит к повреждению памяти и остается незамеченной.
Итоги и советы
Давай подведем итоги.
Глобально подходов к фаззингу ядра Linux три:
- Использовать юзерспейсный фаззер. Либо берешь фаззер типа AFL или libFuzzer и его переделываешь, чтобы он звал сисколы вместо функций юзерспейсной программы. Либо вытаскиваешь ядерный код в юзерспейс и фаззишь его там. Эти способы прекрасно работают для подсистем, обрабатывающих структуры, потому что в основном юзерспейсные фаззеры ориентированы на мутацию массива байтов. Примеры: фаззинг файловых систем и Netlink. Для coverage-guided-фаззинга тебе придется подключить сборку покрытия с ядра к алгоритму фаззера.
- Использовать syzkaller. Он идеально подходит для API-aware-фаззинга. Для описания сисколов и их возвращаемых значений и аргументов он использует специальный язык — syzlang.
- Написать свой фаззер с нуля. Это отличный способ разобраться, как работает фаззинг изнутри. А еще с помощью этого подхода можно фаззить подсистемы с необычными интерфейсами.
Советы по syzkaller
Вот тебе несколько советов, которые помогут добиться результатов.
- Не используй syzkaller на стандартном ядре со стандартным конфигом — ничего не найдешь. Много людей фаззят ядро руками и с помощью syzkaller. Кроме того, есть syzbot, который фаззит ядро в облаке. Лучше сделай что‑нибудь новое: напиши новые описания сисколов или возьми нестандартный конфиг ядра.
- Syzkaller можно улучшать и расширять. Когда я делал фаззинг USB, я сделал его поверх syzkaller, написав дополнительный модуль.
- Syzkaller можно использовать как фреймворк. Например, взять часть кода для парсинга лога ядра. Syzkaller умеет распознавать сотню разных типов ошибок, и эту часть можно переиспользовать в своем фаззере. Или можно взять код, который управляет виртуальными машинами, чтобы не писать его самому.
Как понять, что твой фаззер работает хорошо? Очевидно, что если он находит новые баги, то все отлично. Но вот что делать, если не находит?
- Проверяй покрытие кода. Фаззишь конкретную подсистему? Проверь, что твой фаззер дотягивается до всех ее интересных частей.
- Добавь искусственные баги в подсистему, которую фаззишь. Например, добавь ассертов и проверь, что фаззер до них дотягивается. Этот совет отчасти повторяет предыдущий, но он работает, даже если твой фаззер не собирает покрытие кода.
- Откати патчи для исправленных багов и убедись, что фаззер их находит.
Если фаззер покрывает весь интересующий тебя код и находит ранее исправленные ошибки — скорее всего, фаззер работает хорошо. Если новых ошибок нет, то либо их там действительно нет, либо фаззер не заводит ядро в достаточно сложное состояние и его надо улучшать.
И еще пара советов:
Пиши фаззер на основе кода, а не документации. Документация может быть неточна. Источником истины всегда будет код. Я на это натолкнулся, когда делал фаззер USB: ядро обрабатывало другое подмножество протоколов, чем описанное в документации.
В первую очередь делай фаззер умным, а уже потом делай его быстрым. «Умный» означает генерировать более точные вводы, лучше собирать покрытие или что‑нибудь еще в таком роде, а «быстрый» — иметь больше исполнений в секунду. Насчет «умный» или «быстрый» посмотри статью и дискуссию.
Выводы
Создание фаззеров — инженерная работа. И основана она на инженерных умениях: проектировании, программировании, тестировании, дебаггинге и бенчмаркинге.
Отсюда два вывода. Первый: чтобы написать простой фаззер — достаточно просто уметь программировать. Второй: чтобы написать крутой фаззер — нужно быть хорошим инженером. Причина, по которой syzkaller имеет такой успех, — в него было вложено много инженерного опыта и времени.
Надеюсь, я скоро увижу новый необычный фаззер, который напишешь именно ты!
www
Еще больше ссылок и материалов — в моей коллекции и телеграм‑канале LinKerSec.
