Содержание статьи
Есть у меня одна слабость — я люблю разные системы мониторинга. То есть для меня идеальна ситуация, когда можно посмотреть состояние каждого компонента системы в любой момент времени. С реалтаймом все более-менее понятно: можно агрегировать данные и выводить их на красивый дашборд. Сложнее обстоят дела с тем, что было в прошлом, когда нужно узнать разные события в определенный момент и связать их между собой.
Задачка на самом деле не такая уж тривиальная. Во-первых, нужно агрегировать логи с совершенно разных систем, которые зачастую не имеют ничего общего между собой. Во-вторых, нужно привязывать их к одной временной шкале, чтобы события можно было между собой коррелировать. И в-третьих, нужно эффективно устроить хранение и поиск по этому огромному массиву данных. Впрочем, как это обычно бывает, о сложной части уже позаботились до нас. Я пробую несколько разных вариантов и поэтому сделаю мини-обзор того, с чем уже успел поработать.
Онлайн-сервисы
Самый простой вариант, который на первых порах отлично работал для меня, — использовать облачный сервис. Подобные инструменты активно развиваются, предоставляют поддержку все большего количества технологических стеков и подстраиваются по специфику отдельных IaaS/PaaS’ов вроде AWS и Heroku.
Splunk
Про этот сервис писал в колонке и я, и недавно Алексей Синцов. Вообще говоря, это не просто агрегатор логов, а мощная система аналитики с многолетней историей. Поэтому задачка собрать логи и агрегировать их для дальнейшей обработки и поиска — для него плевое дело. Существует более 400 различных приложений, в том числе более ста в области IT Operations Management, которые позволяют собирать информацию с твоих серверов и приложений.
loggly
Этот сервис уже специально заточен для анализа журналов и позволяет агрегировать любые виды текстовых логов. Ruby, Java, Python, C/C++, JavaScript, PHP, Apache, Tomcat, MySQL, syslog-ng, rsyslog, nxlog, Snare, роутеры и свитчи — неважно. Бесплатно можно собирать до 200 Мб в день (что немало), а ближайший платный тариф начинается от 49 долларов. Работает очень здорово.
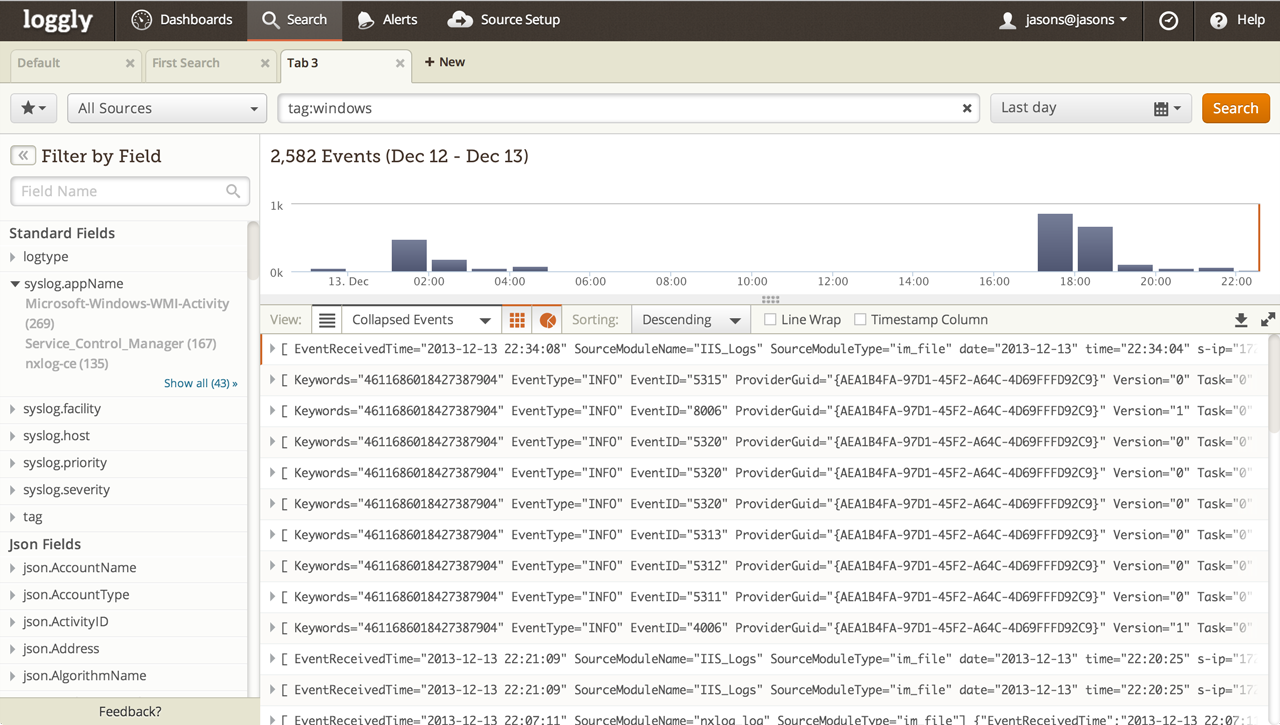

PaperTrail
Отличный сервис, который агрегирует логи приложений, любые текстовые журналы, syslog и прочее. Что интересно: с агрегированными данными можно работать через браузер, командную строку или API. Поиск осуществляется простыми запросами вроде «3pm yesterday» (получить данные со всех систем в три часа ночи за вчерашний день). Все связанные события будут сгруппированы. Для любого условия можно сделать алерт, чтобы вовремя получить предупреждения (изменились настройки в конфигах). Для хранения логов можно использовать S3. В первый месяц дают 5 Гб бонусом, дальше бесплатно предоставляется только 100 Мб в месяц.
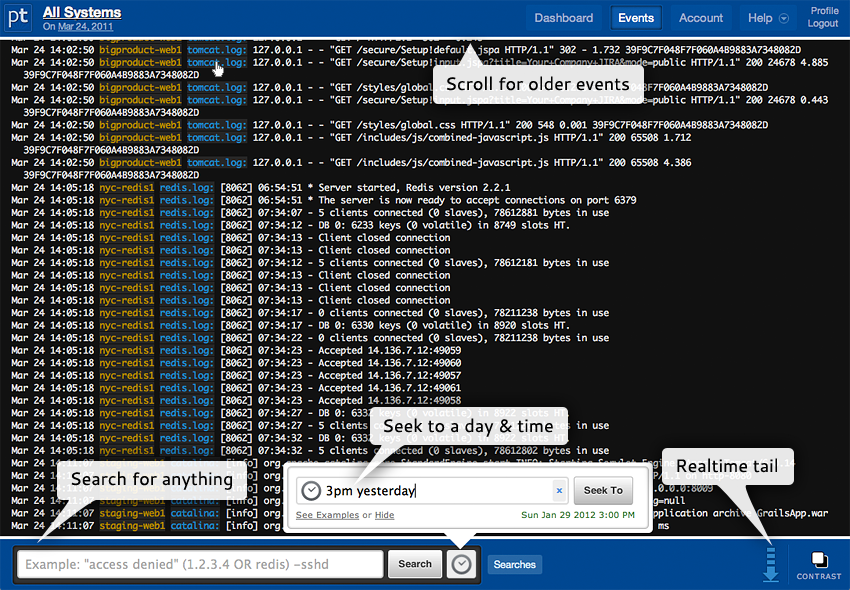
Logentries
Еще один неплохой сервис для сбора данных, позволяющий собирать до гигабайта логов в месяц бесплатно. А возможности все те же: мощный поиск, tail в режиме реального времени (выводится все, что «прилетает» из логов на текущий момент), хранение данных в AWS, мониторинг PaaS, IaaS и популярных фреймворков, языков. На бесплатном тарифе можно хранить данные за семь дней.
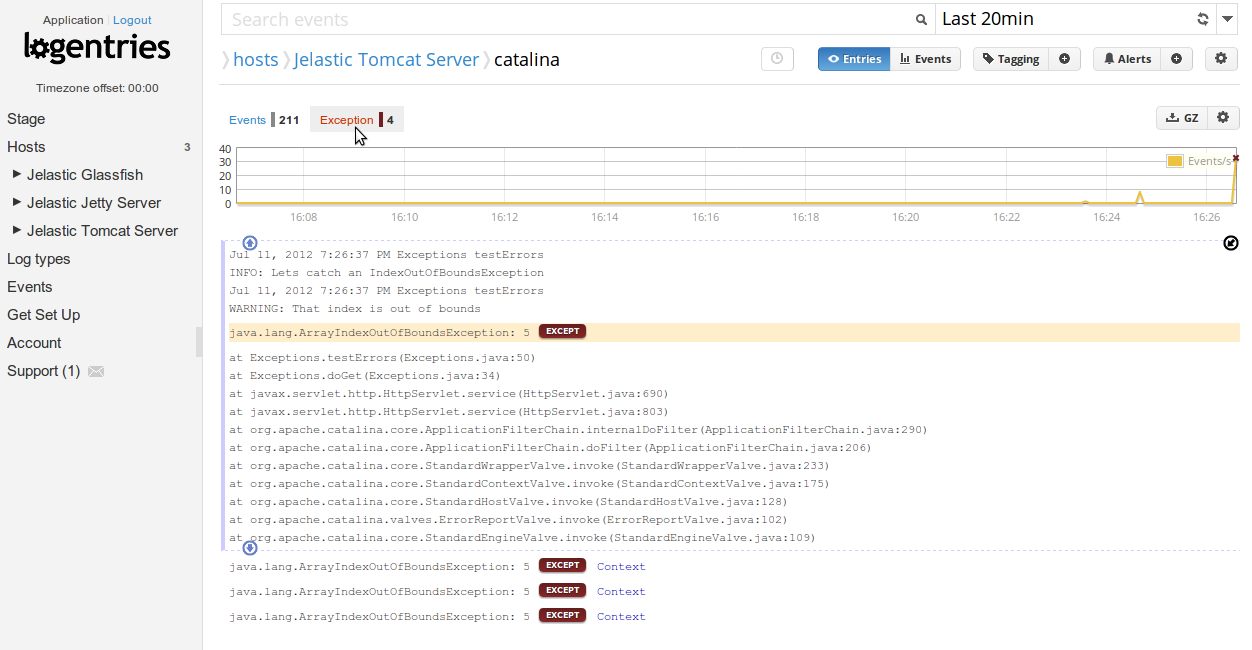
NewRelic
Да, этот сервис не совсем для сбора логов. Но если стоит вопрос о мониторинге производительности серверов и приложений, то это один из лучших вариантов. Причем в большинстве случаев с ним можно работать бесплатно, чем мы долгое время и пользовались в редакции для мониторинга приложений и статуса серверов.
Развернуть все у себя
Мои эксперименты с онлайн-сервисами закончились, когда данных стало так много, что за их агрегацию пришлось бы платить трехзначные суммы. Впрочем, оказалось, что развернуть подобное решение можно и самому. Тут два основных варианта.
logstash
Это открытая система для сбора событий и логов, которая хорошо себя зарекомендовала в сообществе. Развернуть ее, конечно, несложно — но это уже и не готовый сервис из коробки. Поэтому будь готов к багам в скупой документации, глюкам модулей и подобному. Но со своей задачей logstash справляется: логи собираются, а поиск осуществляется через веб-интерфейс.
Fluentd
Если выбирать standalone-решение, то Fluentd мне понравился больше. В отличие от logstash, которая написана на JRuby и поэтому требует JVM (которую я не люблю), она реализована на CRuby и критические по производительности участки написаны на C. Система опять же открытая и позволяет собирать большие потоки логов, используя более 1500 различных плагинов. Она хорошо документирована и предельно понятна. Текущий вариант сборщика логов у меня развернут именно на Fluentd.
Впервые опубликовано в Хакер #03/182