
Виртуализация — это не только инструмент администрирования и поддержки хостинга. Все чаще она применяется и для решения обыденных задач. Но в то же время системы виртуализации становятся достаточно многогранными и сложными. Сегодня мы расскажем о четырех основных системах, каждая из которых нашла применение в какой-то области.
Введение
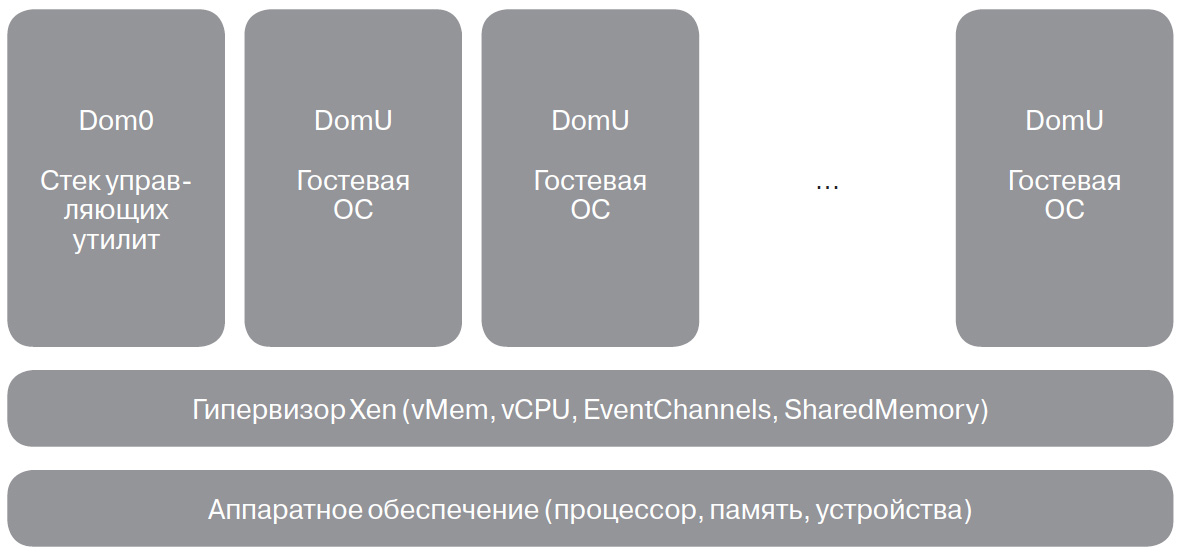
Аппаратная виртуализация в настоящее время перестала быть недостижимой роскошью, доступной только на мейнфреймах, — начиная с 2006 года большинство процессоров средней ценовой категории ее поддерживает. Тем не менее помимо аппаратной поддержки должна быть поддержка программная, которая и обеспечивается гипервизорами. На данный момент существует два основных типа гипервизоров. Они так и именуются: «гипервизор типа 1» и «гипервизор типа 2».
Грань между этими двумя типами достаточно тонка и постепенно стирается. В частности, иногда выделяют третий тип — 1+, который подразумевает сервисную ОС — прослойку между гостевыми ОС и собственно гипервизором, в которой можно эти гостевые ОС запускать и останавливать. В статье будут рассмотрены гипервизоры типа 1 и 1+ — Xen и KVM.
Помимо гипервизоров, существует еще один слой виртуализации — «контейнеры», или, иначе, виртуализация на уровне ОС, хотя виртуализацией это можно назвать лишь с натяжкой. В отличие от «настоящей» виртуализации, контейнеры создают своего рода песочницу со своим пространством имен. Соответственно, накладные расходы на эмуляцию железа попросту отсутствуют. Я рассмотрю две подобные технологии — OpenVZ и LXC.
Xen — выбор облачных хостингов
В Xen 4.4 появился новый режим, объединяющий аппаратную и паравиртуализацию, — то есть прослойка эмулируемого железа отсутствует как таковая, в то же время управление памятью и привилегированные инструкции выполняются в самом ядре гостевой ОС. Режим этот сейчас еще недостаточно отработан, некоторые функции не оттестированы (миграция, проброс оборудования), некоторые и вовсе отсутствуют — в частности, поддержка AMD. Так что если у тебя именно этот процессор — попробовать этот режим пока не получится.

Перейдем к практической части и установим самую последнюю версию XEN. Для этого придется компилировать как Xen, так и ядро. Далее предполагается, что все нужные инструменты и библиотеки уже стоят на компьютере. Сперва соберем Xen:
$ git clone git://xenbits.xen.org/xen.git && cd xen
$ export LC_ALL=en_US.UTF-8 LANG=en_US.UTF-8 LANGUAGE=en
$ ./configure --libdir=/usr/local/lib64 && make -j9
$ sudo checkinstall --pkgname xen --pkgversion 4.5-current-amd64
$ sudo dpkg -i ./xen_4.5-current-amd64-1_amd64.deb
$ sudo update-grub
Затем нужно добавить файл local64.conf в /etc/ld.so.conf.d/ следующего содержания (после чего запустить ldconfig):
/usr/local/lib64
Описывать сборку ядра я особого смысла не вижу, скажу лишь, что для гостевого домена PVH необходимо включить опцию Processor type and features -> Linux guest support -> Support for running as a PVH guest (NEW). Кроме того, в случае самосборного Xen надо добавить файловую систему xenfs в /etc/fstab — в современных дистрибутивах подобное делать, конечно, моветон, но так будет проще всего.
Перейдем к созданию гостевых виртуальных машин. Рассматривать будем стандартный сейчас стек утилит XL и сопутствующие конфиги. Файл xl.conf является глобальным файлом для dom0-хоста, и конфигурация по умолчанию, как правило, в изменении не нуждается. Поэтому перейду сразу к конфигурации гостевого домена (HVM). Первым делом нужно создать файл дискового устройства (хотя можно использовать и существующий раздел). Перейдя в каталог, где будут храниться образы, набираем:
$ dd if=/dev/zero of=disk.img bs=1k seek=4096k count=1
$ dd if=/dev/zero of=disk.img bs=1k count=1 conv=notrunc
Затем создаем конфиг /etc/xen/vm.cfg согласно документации. Запускаем и подключаемся к VNC-серверу, а в конце работы останавливаем:
$ sudo xl create /etc/xen/vm.cfg &
$ gvncviewer localhost &
$ sudo xl destroty VM
Для того чтобы попробовать режим PVH, нужно добавить в конфиг /etc/xen/vm.cfg примерно следующие строчки:
# <...>
pvh=1
extra="console=hvc0 debug kgdboc=hvc0 nokgdbroundup initcall_debug debug"
kernel=/boot/vmlinuz-3.14.0-rc4-current+"
ramdisk="/boot/initrd.img-3.14.0-rc4-current+"
Xen поддерживает множество интересных возможностей. Его используют многие облачные сервисы, такие как Amazon EC2, Rackspace Cloud и другие. Забегая вперед, скажу, что это самая многофункциональная система виртуализации, рассматриваемая в данной статье. Однако его функциональность порой избыточна и подходит не для всех.
KVM — простота и удобство для пользователя
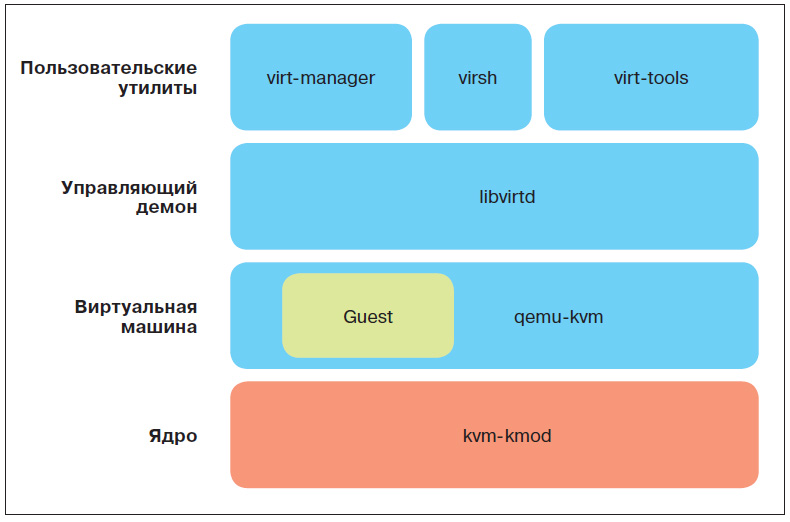
В отличие от Xen, KVM поддерживает только аппаратную виртуализацию и вообще выглядит проще. Поэтому можно часто встретить применение KVM обычными юниксовыми пользователями. KVM поддерживает проброс USB- и PCI-устройств, появившийся относительно недавно. Я не буду расписывать его архитектуру, а сразу перейду к созданию виртуальных машин. Установим нужные пакеты (после этого лучше перезагрузиться) и проверим работоспособность:
$ sudo apt-get install qemu-kvm libvirt-bin ubuntu-vm-builder bridge-utils virtinst
$ virsh -c qemu:///system list
После выполнения последней команды должен появиться список запущенных виртуальных машин. Поскольку у нас никаких виртуальных машин еще нет, он будет пустым. Исправим эту ситуацию.
Первым делом установим систему. Для этого необходимо создать образ диска:
$ qemu-img create -f qcow2 image.qcow2 5G
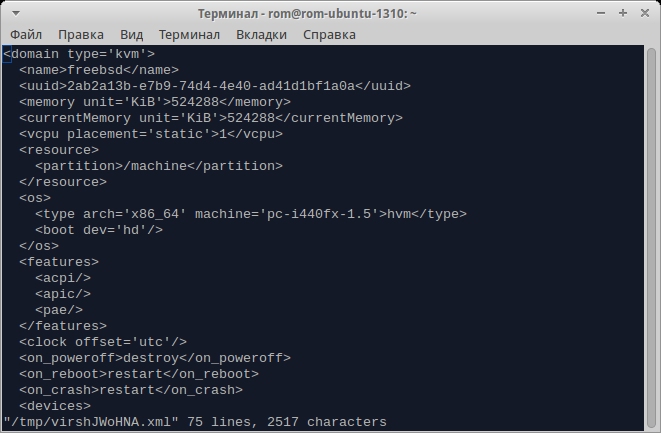
Следом набираем команду, которая создает конфигурационный файл и запускает виртуальную машину, и подключаемся к ней:
$ sudo virt-install --connect qemu:///system -n freebsd -r 512 --disk path=./image.qcow2,format=qcow2 -c /media/rom/DATA/Torrents/freebsd/FreeBSD-10.0-RELEASE-amd64-dvd1.iso --vnc --noautoconsole --os-variant freebsd8
$ gvncviewer localhost
Рассмотрим проброс USB-устройств. Для его осуществления нужно узнать VID и PID пробрасываемого устройства (с помощью команды lsusb) и добавить в конфиг виртуальной машины freebsd.xml следующие строки:
# <...>
<devices>
# <...>
<hostdev mode='subsystem' type='usb'>
<source>
<vendor id='0x0a12'/>
<product id='0x0001'/>
</source>
</hostdev>
</devices>
И перезапустить ее. Настройка проброса PCI-устройств для хостовой системы почти аналогична таковой для Xen. Только вместо установки параметра ядра xen-pciback.hide необходимо подключить пробрасываемое устройство к драйверу pci-stub. При этом помимо номера устройства надо знать еще и его VID/PID, который узнаем с помощью команды lcpci -n. Затем создаем конфиг /etc/modprobe.d/kvm.conf для модуля kvm:
options kvm allow_unsafe_assigned_interrupts=1
Затем выполняем комбинацию команд rmmod kvm / modprobe kvm и добавляем соответствующие строчки в конфиг виртуальной машины freebsd.xml.
Стоит также упомянуть технологию SPICE. Она изначально разрабатывалась в качестве замены VNC для виртуальных машин и не требует наличия сети. В контексте проброса видеокарт SPICE примечательна тем, что позволяет на хостовой машине эмулировать видеокарту и пробрасывать реальную видеокарту на гостевую систему. Однако видеокарта, эмулируемая SPICE, целиком виртуальная и не имеет никакого устройства вывода, поэтому могут возникнуть некоторые сложности. Если же хочется «всего и сразу» — и проброс, и беспроблемное переключение, — можно попробовать пробрасывать не напрямую, а через драйвер VFIO.
INFO
Существуют версии VirtIO-драйверов (для удобства работы с оборудованием и динамического выделения памяти) и для Windows.
LXC — контейнеры для всех и каждого
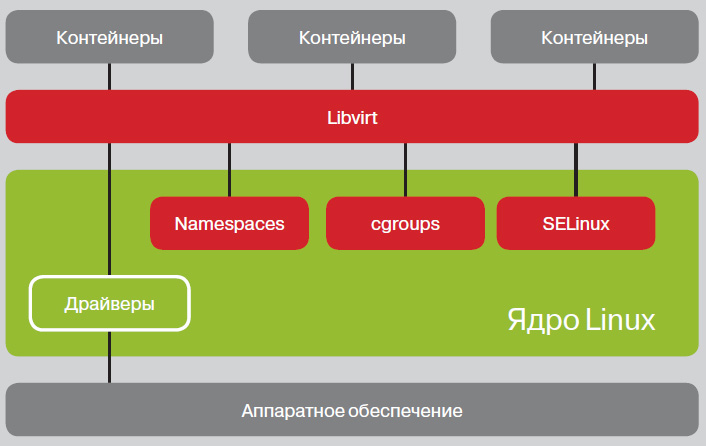
Об архитектуре LXC я писал не так давно, поэтому повторяться смысла нет. Лучше кратко рассказать о создании контейнера и некоторых полезных командах. Наиболее легким способом создать контейнер будет использование команды lxc-create:
$ sudo lxc-create -n ubuntu-container -t ubuntu
Она разворачивает с помощью debootstrap минимальную версию Ubuntu — причем по умолчанию используется та версия дистрибутива, которая стоит на хосте.
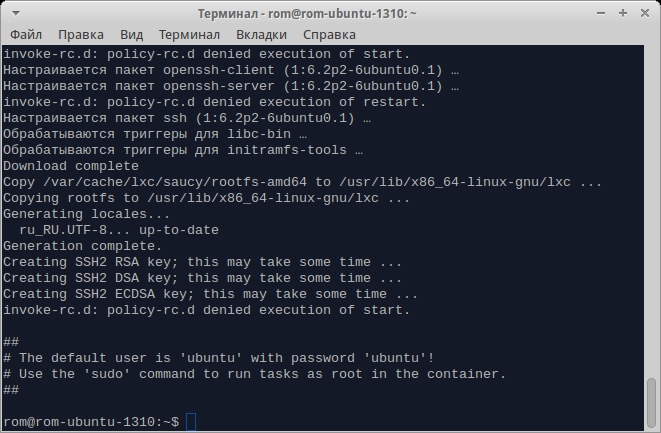
Для запуска же используем другую команду:
$ sudo lxc-start -n ubuntu-container -d
Эта команда запускает контейнер в фоновом режиме. Так что для подключения к нему уже нужно использовать команду lxc-console c тем же параметром. После этого можно работать с контейнером точно так же, как и со свежеустановленной системой. Для нормального завершения работы контейнера используй команду (на хосте) lxc-stop с параметром -s, для «жесткого» — ее же с параметром -k, а для уничтожения остановленного контейнера — lxc-destroy. Параметр имени контейнера обязателен для всех этих команд.
Теперь посмотрим конфиг данного контейнера, который находится в файле /var/lib/lxc/ubuntu-container/config. Он состоит из следующих частей: сеть, терминалы, безопасность (AppArmor) и устройства. Опишу парочку интересных опций, которые можно туда добавить:
- lxc.network.type — тип сети в контейнере. Значения могут быть следующими: veth — в контейнере создается интерфейс и связывается с бриджем на хосте, указываемом в параметре lxc.network.link; vlan и macvlan — аналогично (у последнего имеется несколько опций, но их описание выходит за рамки данной статьи); phys — физический интерфейс (опять же указывается в lxc.network.link);
- lxc.mount — указывает файл (формата fstab), в котором описано, что монтировать в контейнер;
- lxc.cap.drop — capabilities, которые будут отсутствовать в контейнере.
Еще раз отмечу, что LXC — технология крайне молодая. Так, User namespaces в их «завершенном» виде появились только в ядре 3.8, да и то включены они не везде. Однако технология эта уже может применяться для нужд пользователя, например, в прошлом номере мы писали о ее использовании для безопасного веб-серфинга.
OpenVZ — традиционный выбор хостингов
OpenVZ является наиболее старой технологией контейнерной виртуализации на архитектуре PC — его прародитель, Virtuozzo, возник в 2001-м, еще до того, как в Solaris появились зоны и контейнеры.
Стоит рассказать об одной особенности OpenVZ, которой нет в аналогах, — vSwap. Допустим, у контейнера задан лимит памяти и некое приложение превысило его. В обычном случае приложение прибивается ядром и все его данные теряются. vSwap представляет собой оперативную память, замедленную в несколько раз, и при его использовании приложение, если превысит лимит, не прибивается ядром, а терпеливо ждет, когда память освободится.
Основное понятие в OpenVZ — VE (Virtual Environments, виртуальные окружения), аналог контейнеров. Их поддержка обеспечивается патчсетом, добавляющим ко множеству сущностей (процессы, сокеты...) поле VEID, которое идентифицирует контейнер. Стабильная версия данного патчсета на момент написания статьи поддерживала только ядро 2.6.32 (которое является основой для RHEL6-based-дистрибутивов). Это ограничивает его применение данными системами.
Конечно, пакет с OpenVZ-ядром есть и для Debian-based-систем, но RHEL-based предпочтительнее — относительно них и будем рассматривать. К счастью, компилировать ядро и утилиты не нужно — есть уже готовые пакеты. Установим их, добавив предварительно репозиторий, и перезагрузимся на свежеустановленное ядро:
# wget -P /etc/yum.repos.d/ http://ftp.openvz.org/openvz.repo
# rpm --import http://ftp.openvz.org/RPM-GPG-Key-OpenVZ
# yum install vzkernel vzctl vzquota ploop
# reboot
Теперь сделаем контейнер с тем же самым CentOS. Для начала понадобится загрузить шаблон:
# wget -P /vz/template/cache/ http://download.openvz.org/template/precreated/centos-6-x86.tar.gz
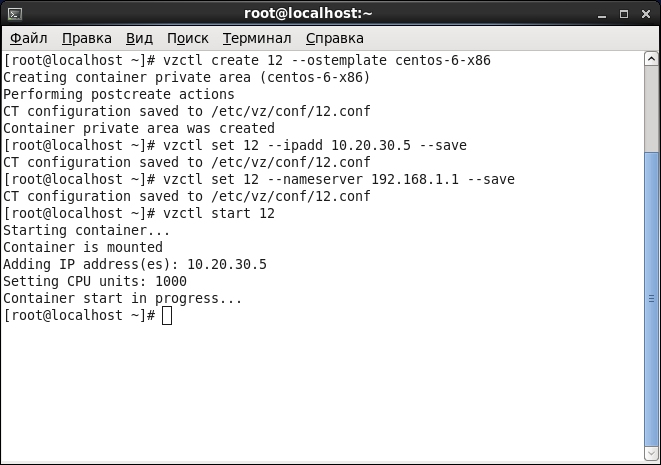
Затем введем собственно команды для его создания и запуска (адреса взяты с потолка):
# vzctl create 12 --ostemplate centos-6-x86
# vzctl set 12 --ipadd 10.20.30.5 --save
# vzctl set 12 --nameserver 192.168.1.1 --save
# vzctl start 12
Для входа в оболочку контейнера нужно набрать команду vzctl enter 12, а для выхода exit — разработчики решили не мудрить с сочетаниями клавиш. Остановка же и уничтожение контейнеров осуществляются с помощью команд vzctl stop и vzctl destroy соответственно — конечно, с указанием его идентификатора.
В целом OpenVZ более зрелое и отработанное решение, чем LXC. Кроме того, оно лучшее по производительности и масштабируемости в силу своей архитектуры. И действительно, огромное количество хостеров предоставляет VPS на его основе.
Proxmox
Proxmox представляет собой Debian-based-дистрибутив, заточенный под управление виртуальными машинами. Основные возможности:
- поддержка как KVM, так и OpenVZ из коробки;
- удобный веб-интерфейс для администрирования с поддержкой RESTful API и прав доступа;
- поддержка GlusterFS (отказоустойчивой кластерной файловой системы, разработанной в Red Hat) для хранения виртуальных машин.
Дистрибутив поставляется бесплатно, а вот в смысле обновлений политика выпускающей компании аналогична таковой у Red Hat — обновления делятся на тестовые и enterprise. Первые бесплатны, на вторые надо оформлять подписку.
Заключение
Технологии обычной и контейнерной виртуализации становятся все более популярными, а грань между ними — все более тонкой. Тем не менее какие-то различия все же есть. В частности, Xen кажется на сегодня самой стабильной системой аппаратной виртуализации, которая к тому же еще и развивается. В пользу Xen говорит еще и то, что его использует такой гигант облачного хостинга, как Amazon. Однако его конкурент, KVM, тоже не стоит на месте — в частности, в последних версиях появилась возможность пробрасывать видеокарту, не имея второй.
В случае контейнеров все сложнее. Официально поддержка технологий для их создания оформилась в ядре относительно недавно и еще сыровата. Аналогичная технология требует накладывания патчей и не поддерживает новые ядра. Но неоспоримым плюсом контейнеров является то, что издержки производительности, связанные с эмуляцией железа / переключением контекстов, отсутствуют.










