Содержание статьи
Обойти HTTPS с помощью proxy (Pretty Bad Proxy)
Решение
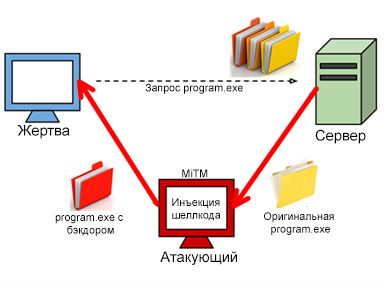
Хотелось бы начать сегодняшний Easy Hack с относительно старой атаки — возможности «обхода» HTTPS в браузере. Если точнее, возможности внедрить свой JavaScript-код в любой сайт, защищенный HTTPS, при условии, что злоумышленник может «вставить» свой прокси в настройках браузера жертвы. Да, эта атака не работает на современных топовых браузерах. Но, во-первых, еще шесть лет назад ей были подвержены все они, а во-вторых, она служит отличным примером основных проблем с HTTPS (SSL). Да и с технологической точки зрения интересна.
WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.Давай представим себе ситуацию, что атакующий может провести на пользователя man-in-the-middle атаку. Причем не просто «находиться» где-то посередине между сервером и пользователем, а быть прокси-сервером для подключения между ними. То есть в настройках браузера/ОС пользователя должен быть указан прокси атакующего. Хотя это может показаться невыполнимым, но на практике есть ряд ситуаций, когда это происходит. Вот самые типовые.
Корпоративная сеть, все пользователи ходят через корпоративный прокси. Мы производим DNS- или ARP-спуфинг и подменяем официальный прокси на свой. Также есть автоматическое включение прокси с использованием технологии WPAD (Web Proxy Autodiscovery Protocol), которая по умолчанию активирована в Windows-системах («Автоматическое определение настроек» в IE).
Далее. Почему нам так важно именно стать прокси-сервером? Дело заключается в уникальности работы через них. Если при обычном подключении по SSL данные идут напрямую и, не считая первых SSL-пакетов, там все зашифровано, то c прокси добавляется еще один шаг, который не зашифрован.
Итак, по RFC, для работы по HTTPS через прокси был придуман дополнительный метод — CONNECT. Когда пользователь пытается подключиться по HTTPS к серверу, его браузер сначала посылает запрос плейн-текстом на прокси такого вида:
CONNECT defcon-russia:443 HTTP/1.1
Host: defcon-russia

Прокси же пытается подключиться по указанному IP и порту и, если все хорошо, отвечает:
HTTP/1.0 200 Connection established
При этом он не обрывает подключение (TCP), а начинает просто пересылать весь трафик от пользователя на сервер. То есть отсюда и далее идет обычное подключение по SSL. Теория, я думаю, ясна. Перейдем к самой уязвимости, которая была в браузерах.
Проблема была в том, что браузер обрабатывал ответ прокси (например, ошибку при подключении) в контексте домена сайта, к которому он подключался. И что еще круче — JavaScript тоже работал! Прокси-серверу ничего не стоило вернуть браузеру ошибку со своим JS и из него получить те же куки, например.
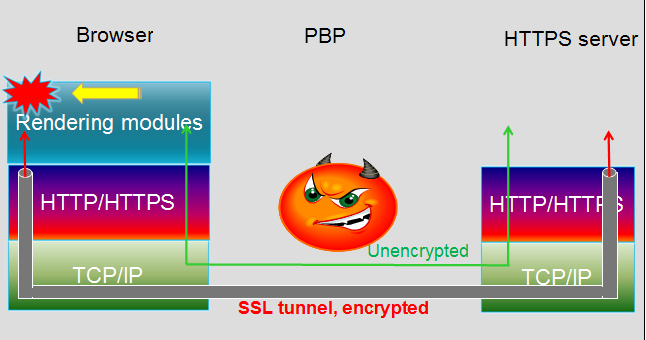
Хотелось бы подчеркнуть здесь, что фактически ничто не нарушало само HTTPS-соединение. Оно как было зашифровано и нетронуто, так и осталось. Проблема была уровнями выше — в same origin policy (SOP) браузера, по которому все было вполне корректно: вне зависимости от того, откуда пришли данные, если origin тот же, значит, и доступ есть. Причем разработчики разрешали вывод ошибок от proxy из хороших побуждений — чтобы у пользователя была возможность видеть кастомную информацию о причинах ошибки подключения.
Прокачать Kali Linux
Решение
Я думаю, ты в курсе, что Offensive Security значительно переосмыслили свой знаменитый пентестерско-хакерский дистрибутив BackTrack и конкретно его переделали. Как минимум, теперь он называется Kali, и в качестве основы взяли Debian (раньше был Ubuntu). Также ядро теперь первой свежести, а не какой-нибудь LTS. По моему мнению, проблем только добавилось, но, думаю, у них были веские аргументы для перемен. Но задача не об этом.
Как это ни странно, Kali создавался как дистрибутив, на котором было бы предустановлено и настроено все необходимое ПО для наших с тобой дел. Но и сторонних тулз оооочень много, и они систематически обновляются и меняются. Получается, когда мы скачиваем Kali, уверен, нам чего-то да не хватит из предустановленного арсенала. И возникает потребность в установке дополнительных приложений, причем из сырцов. Это может стать очень приличным геморроем, особенно если возникают конфликты различных версий библиотек, языков. А кроме того, все это надо еще и обновлять… Также есть целый ворох проблем в виде необходимости патчить разного рода VM Tools, чтобы они таки заработали под ядрышком 3.12.
Но наше же дело — ломать, а не ПО ставить. А потому рекомендую воспользоваться скриптами, которые помогут тебе автоматизировать вышеупомянутые задачи.
Во-первых, это небольшой скриптец-инсталлятор — Lazy-Kali. Он дает возможность накачать ряд прикольных тулз (Unicornscan, Smbexec, Flash, Nautilus, Xssf, Ettercap 0.7.6, PwnStar и другие), а также удобненький интерфейс для обновления всех основных систем/тулз.
Во-вторых, я хотел бы тебе презентовать набор скриптов для комфортной работы Kali Linux от коллеги по DSec’у — @090h (пользуясь положением, передаю ему слова: «Ты — крутан :)»).
Данный набор скриптов полезен при первичной установке Kali для инстала большого количества софта в автоматическом режиме, также имеется скрипт для быстрого тюнинга. Ну и для любителей покопаться со всякими железками на ARM/MIPS есть возможность быстрого разворачивания тулчейнов под нужную архитектуру.
Перечислять все не имеет смысла — по исходникам все понятно. В общем, очень рекомендую. Взять можно здесь.
Для тех, кому скриптов мало и хочется большего, есть хорошая связка Vagrant + Packer, которая позволяет запилить себе виртуалочку Kali в автоматическом режиме. Шаблоны для виртуалки лежат рядом.
Определить IP-адрес, используя WEBRTC
Решение
Не так давно в браузеры пришла технология WebRTC (Web Real-Time Communication). Суть ее заключается в том, чтобы дать браузерам встроенную универсальную возможность, то есть без плагинов, осуществлять звонки, видеоконференции, передачу данных. Логично, что она возложена на специальный API в JS. И понятное дело, что возможность эта сможет потеснить Skype, например.
Сейчас эта технология поддерживается уже всеми топовыми браузерами (IE c 10-й версии). И даже есть примеры интеграции и использования технологии (если интересно — посмотри на хабре).
С другой стороны, у этой технологии для наших целей также есть кое-что. А именно — возможность получить IP-адрес системы. Заходит к тебе кто-то на сайт, а ты можешь узнать его IP, только используя возможности JavaScript’а. Причем, что очень важно, не IP-адрес NAT’a (вай-фай роутера или другого девайса) или IP прокси, а именно конкретного хоста в его подсети. К тому же можно получить IP-адреса всех сетевых интерфейсов. Никаких warning’ов при этом не отображается. Все тихо и незаметно.
Если кратко, то причина этой новой возможности JS в том, что хотя WebRTC и является P2P-технологией, но для нахождения хостов, для подключений между друг другом используется дополнительный сервер. Так вот, для обмена данными для подключения также был придуман протокол — SDP (Session Description Protocol). Для подключения в SDP, наряду с другой информацией, передаются и IP-адреса. Надеюсь, что не ошибся :).
Так что мы фактически приходим к тому, что наши внутренние IP уже не являются приватной информацией. Можно только надеяться, что потом для доступа к этому API потребуется подтверждение от пользователя.
PoC можно найти здесь.
Получить DNS имени по IP или rDNS
Решение
Это еще одна задачка, относящаяся к сбору информации об атакуемой сети. В данном случае мы опять-таки используем возможности DNS. Казалось бы, что тут вообще можно получить? Имеем мы, например, имя сервера нашей жертвы, резолвим его и получаем IP-адрес. Далее резолвим обратно из IP-адреса — смотрим получившееся имя. Иногда оно может отличаться от того, что было. Вдобавок к этому можно провести обратный резолв (из IP в доменное имя) и для соседних серверов, чтобы расширить attack surface… С этими задачками может и nslookup/dig справиться. Идейно здесь должно все быть понятно. Но мне бы хотелось обратить твое внимание именно на механизмы, которые используются при этом. Эти тонкости помогут тебе для определения количества серверов — «соседей» по хостингу.
Итак, у нас есть имя домена жертвы и его IP-адрес. Что же происходит при обратном резолве IP-адреса (nslookup 55.66.55.33)? По твоему запросу твой DNS-сервер пытается найти PTR-запись для этого IP-адреса. При этом DNS-сервер, который ответит тебе на запрос, будет другой, а не тот, что вернет обычные записи (MX, A, TXT…). Звучит странновато, но если пронаблюдать последовательность, то становится понятно.
Во-первых, для резолва IP-адресов действует обычный подход (иерархия). Для того чтобы сделать их валидного вида, просто создана специальная зона «.in-addr.arpa» и обратная последовательность IP-адреса. Например, 223.19.109.62.in-addr.arpa для 62.109.19.223.
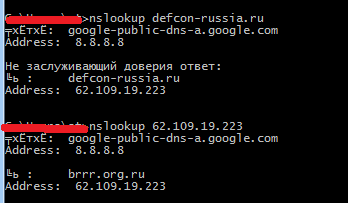
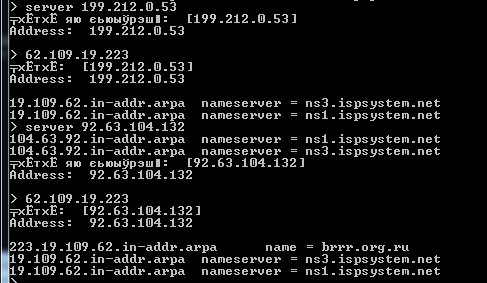
Далее, когда ты просишь свой DNS-сервер сделать обратный резолв, то он повторяет классический проход по иерархии. Сначала отправляет запрос на сервер один из рутовых DNS-серверов (a.root-servers.net, например). Тот отвечает именем сервера, ответственного за эту зону. Например, за 62.in-addr.arpa отвечает tinnie.arin.net. То есть мы увидим здесь один из основных регистраторов. Теперь мы делаем запрос уже к нему. Его ответ будет уже решающим.
Мы получим имя DNS-сервера, ответственного за диапазон IP-адресов. Это может быть провайдер или организация, то бишь автономная система (AS). Сам диапазон IP мы можем запросить через стандартную команду whois. У этого сервера мы можем напрямую запросить все PTR-записи по всему диапазону IP.
Таким образом, я думаю, теперь все встает на свои места. PTR-записи находятся на DNS-сервере, ответственном за диапазон IP, а не DNS доменной зоны. Резолв же идет стандартным путем по иерархии.
Кстати, в продолжение прошлых тем про спуфинг email’ов, могу добавить, что некоторые почтовые серверы не желают получать почту с хостов без PTR-записи. Говорят, данный способ спасает от спама. Эта проблема решабельна — купить сервак с PTR-записью очень просто/дешево. Так что нас это не остановит, но знать о потенциальных проблемах желательно.
Собрать информацию с помощью dnsenum
Решение
Итак, задачка выше, наверное, была одной из последних про сбор инфы через DNS. В Easy Hack’е за последние несколько лет были описаны все основные методы по recon’у. Во всяком случае, других я пока что не знаю :).
Но с другой стороны, большая части информации была связана именно с методами, их причинами, и в качестве примеров приводились «точечные» инструменты — dig/nsloolup. Для понимания работы это то, что нужно. Но для пентестерских будней необходимы более быстрые и автоматизированные инструменты. Примером такой штуки служит dnsenum. Он входит в поставку Kali/BackTrack.
Списочек того, что он умеет делать:
- собирать A-, NS-, MX-записи;
- выполнять AXFR (трансфер зоны) для DNS-серверов;
- получать поддомены по гуглу;
- брутфорсить поддомены;
- производить реверс-запросы по диапазону из whois’а.
Не могу сказать, что эта тулза лучшая среди конкурентов (а аналогов много). Гуглохакинг, например, не очень, но все-таки она хороша, быстра и проста. Так что если еще не подобрал себе что-то — попробуй ее.
Спрятать JavaScript в GIF/BMP и обойти CSP
Решение
В последних версиях современных браузеров появилась такая интересная технология — CSP (content security policy). Недавно в «Хакере» была хорошая статья на эту тему, так что в подробности CSP я вдаваться не буду, а лишь напомню основные моменты.
Итак, задача, стоящая перед CSP, — это снизить последствия от XSS-уязвимостей (и не только их). Сервер в ответе добавляет HTTP-заголовок, в котором указывает, с каких доменов разрешена подгрузка JavaScript’ов, картинок, CSS-стилей. К тому же по умолчанию запрещается исполнение inline JS скриптов. Таким образом, даже если хакер может внедрить на страницу произвольный HTML, то яваскрипт payload нельзя будет подгрузить с хакерского ресурса. Мне это чем-то напоминает DEP как механизм защиты памяти: по сути, это ограничение того, какой код может исполняться, а какой — нет.
Хотя технология и подвергается критике. Мне кажется, что она приносит приличный ряд трудностей при эксплуатации XSS’ок, иногда совсем сводя возможность эксплуатации на нет. А как-никак XSS — самая распространенная уязвимость веб-приложений. Главное, не считать CSP «серебряной» пулей, которая решит все проблемы. CSP отлично себя может показать на небольших и «целостных» сайтах, требующих высокого уровня защищенности. Например, на сайтах интернет-банкинга.
Но наша цель — это обход CSP. Что же мы можем сделать? Если мы вспомним, что CSP указывает, откуда скрипты могут быть загружены и исполнены, то получается, туда нам и надо подгрузить наш скрипт. Как же это сделать?
Один из вариантов следующий. На многих сайтах сейчас есть возможность залить свои картинки, и если домен, куда попадают картинки, также входит в скоуп CSP, то мы получаем простой способ обхода CSP. Загружаем на атакуемый сайт свою картинку, которая в то же время является и валидным JavaScript-файлом, и в XSS ссылаемся на нее.
Теперь глубже. Как же это возможно? Здесь есть несколько основополагающих факторов. Во-первых, вспомним, что когда мы подгружаем JS через script src=, то браузер игнорирует тип получаемого файла, то есть заголовок «Content-Type: image/gif», который отдается сервером при загрузке gif-картинки. Фактически это может быть любой файл. Во-вторых, браузер будет его парсить как JS. Получается, главное — чтобы файл был валидным JS-ником. Таким образом, делаем вывод, что мы можем обойти CSP при подгрузке любого типа файла (почти), если внутри спрятать валидный JS.
Но достаточно часто на сервере тип файла проверяется при загрузке. А потому встает задача и обойти фильтр, то есть получить одновременно и валидный JS, и валидную картинку при этом.
На самом деле это не очень трудно (в конце топика ты легко сможешь сделать это сам). Но вот Saumil Shah на конференции добился еще большего. Для GIF и BMP он смог и сделать валидный JS-файл, и сохранить возможность визуализации картинки. Техника называется imajs.
Если мы подключаем такую картинку через <img src=file.gif> — она отображается, если через <script src=file.gif>, то исполняется браузером.
Для начала давай посмотрим на формат GIF-файла. Он имеет такую структуру:
- Сигнатурка и версия картинки — GIF89a.
- Заголовки, определяющие характеристики картинки (первый из которых — ширина картинки).
- Данные самой картинки.

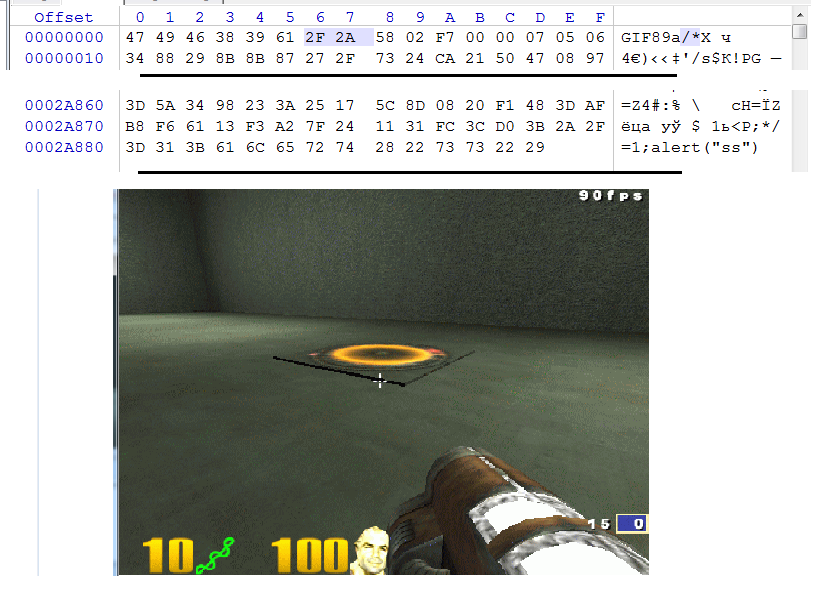
Тут все ясно. Теперь давай вспомним, что для исполнения GIF’ки она должна быть валидным JS. Иначе script src откажется работать. Для этого мы сделаем трюк: запихнем почти весь GIF в JS многострочный комментарий (/коммент/), а в конец файла запихнем наш JS-пейлоад. Логично, но все же мы лишаемся валидности GIF’ки. Здесь нужна более тонкая хирургия, а именно:
- Сначала идет GIF89a.
- Далее в два байта, указывающих ширину картинки, пишем 0x2f 0x2a (в шестнадцатеричном виде). Фактически это символы /*, которые определяют начало многострочного комментария. И в то же время это валидная ширина картинки — 10799.
- В конец картинки мы дописываем 0x2a 0x2f, то есть */ — конец коммента.
- Далее нам надо «закрыть» GIF89a для JS-парсера, для чего мы пишем =1; — то есть мы заставляем JS-парсер думать, что GIF89a — это переменная в JS.
- Так как мы выбрались за рамки рисунка, мы можем писать наш атакующий JavaScript-пейлоад.
В итоге JS-парсер видит следующее:
GIF89a/*весь_gif_тут*/=1;alert(“любой payload”);…
Аналогичный подход работает и для BMP.

Думаю, стоит еще отметить: даже несмотря на то, что мы выставляем столь некорректную ширину картинки, из-за «умности» библиотек обработки изображений отображается она правильно.
Также хотелось бы назвать скрипт, который может сгенерить GIF/JS-файлы. К сожалению, сейчас у него есть проблемы— GIF’ка получается битой.
Обойти urlencode для IE
Решение
Продолжим тему XSS. Как ты знаешь, для того, чтобы получить XSS, нам необходимо, чтобы наш контент с яваскриптом попал на страницу атакуемого сайта.
Чаще всего при этом нам необходимо вывалиться из какого-то HTML-тега и начинать свой. То есть нам часто нужны спецсимволы, такие как двойная кавычка и «символ-без-названия» (<,>). Здесь важно отметить, что в различных языках программирования обычно есть функции, которые позволяют закодировать такие символы (HTML-энкод).
Но давай взглянем на сам формат URL’ов.
scheme://[login[:password]@](host_name|host_address)[:port][/hierarchical/path/to/resource[?search_string][#fragment_id]]
Я здесь представил общий вид, но нас конкретно интересует path, search_sting — как раз в основном в них мы проводим атаки.
По RFC вроде прописано, что спецсимволы должны быть закодированы с помощью процента и код символа в шестнадцатеричном виде (%22 для кавычки). В зависимости от браузера перечень символов, которые подлежат кодированию, а также часть URL’а, где это правило применяется, значительно отличается.
Хотелось бы подчеркнуть, что когда на серверной стороне мы в скрипте получаем данные, то работаем уже с раскодированными данными. То есть “print $GET['anyvar'];” выдает двойную кавычку как кавычку, а не как %22.
С другой стороны, есть ряд функций и ситуаций, когда на вывод попадают именно данные в виде, который был передан на сервер. Например, вывод ошибок некоторых веб-серверов содержит запрос в нераскодированном виде.
Вот в этой ситуации и может ошибиться разработчик. Он знает, что выводит данные от пользователя, но так как вывод происходит без раскодирования, то он не боится XSS. Он полагает, что стандарты и «защита» на уровне браузера ее предотвратят. Вот здесь нам и может помочь знание тонкостей браузеров.
Во-первых, fragment_id — почти никакой браузер не кодирует его. Хотя это и понятно, так как эти данные на сервер не отправляются.
Далее, search_sting (она же query string) — здесь все интересно. Такие веселые символы, как <, >, ”, не кодируются браузером IE, в отличие от других. То, что нам и надо! По этому поводу был приличный флейм в full disclosure, что это бага IE, которая ставит всех в опасное положение. Не знаю уж, к чему там все пришло, но последние версии IE все еще имеют такую особенность, и, похоже, MS менять ничего не планирует.
Ну и последний момент. Находка (Сергею Белову — спасибо за это :)) с рабочего проекта. Оказывается, что когда браузер IE редиректится с какого-то сайта по указанию заголовка Location, то он не производит URL-кодирование символов. Таким образом мы получаем возможность передавать спецсимволы не только в query string, но еще и в path (пути к ресурсу). Chrome, FF этой особенности не имеют.
Кстати, если тебя интересуют какие-то виды атак или технологии, о которых бы ты хотел узнать, — пиши на почту.
Спасибо за внимание и успешных познаний нового!