
Содержание статьи
Мы уже много говорили о том, как написать эксплойт, обойти разные технологии от Microsoft, которые мешают нам эксплуатировать ту или иную дыру. Но сегодня мы будем говорить про то, как искать эти самые дыры. На страницах журнала ты уже не раз встречал термин «фаззинг». Кроме того, мы неоднократно раскрывали суть и значение этой техники. Сегодня мы рассмотрим более прогрессивные виды фаззинга...
Fuzz me baby one more time!
В 138 выпуске нашего любимого журнала (август 2010 года) Step написал статью про фаззинг и ПО, с помощью которого можно этот самый фаззинг осуществлять. Напомню, что этим модным термином принято называть метод тестирования ПО, при котором входные данные (данные могут быть в файле, в сетевом пакете) формируются специально-случайным образом, то есть, фактически, стресс-тест. Если в результате обработки таких данных произошла ошибка, и процесс аварийно завершил свою работу, то можно говорить о том, что процесс фаззинга нашел «что-то».
Дальше это «что-то» анализирует человек и делает вывод о том, что найденное состояние процесса при данном наборе входных данных можно использовать со злым умыслом, то есть исполнить произвольный код. Сами данные могут генерироваться по известному формату, то есть если нам известна спецификация формата, мы можем заранее подготовить кучу входных данных, которые соответствуют формату (структура файла, сетевой протокол на транспортном уровне), но содержат «случайные значения». Например, нам известно, что в какой-то части формата данных идет длина, под которую выделено два байта, а затем содержимое указанной длины:
+----+--------+
|0004|61626364|
+----+--------+
| abcd |
+----+--------+
Зная этот формат, можно сгенерировать множество вариантов:
+----+--------
|FFFF|61626364...
+----+--------
| abcd...
+----+--------
+----+--------+
|0004|25XX25XX|
+----+--------+
| %n%n |
+----+--------+
+----++
|0000||
+----++
| |
+----++
И, возможно, программа, обрабатывающая эти данные, упадет при обработке первого набора... Дальнейший анализ покажет, что причина падения кроется из-за целочисленного переполнения (0xFFFF это у нас «-1») с последующим переполнением буфера в стеке с помощью функции memcpy, что является настоящей уязвимостью, а не просто досадной ошибкой.
char buffer[32000];
short int length=getLen(filename, offset); // length=-1 ~ 0xFFFF
if(length<32000) // -1<32000
char* p = getPointer(filename,offset+4);
memcpy(buffer,p,length); // length==65535
else
ExceptionBoF(length);
Если формат неизвестен или слишком сложен (или просто лень), то можно использовать мутационные алгоритмы для изменения существующих правильных наборов данных. На том же примере:
+----+--------+
|0004|61626364|
+----+--------+
| abcd |
+----+--------+
Мутирует в:
+----+--------+
|0000|61626364|
+----+--------+
| abcd |
+----+--------+
+----+--------+
|00FF|61626364|
+----+--------+
| abcd |
+----+--------+
+----+--------+
|FF00|61626364|
+----+--------+
| abcd |
+----+--------+
Последняя мутация по тем же причинам вызовет переполнение буфера в стеке (0xFF00 - «-256» или «65280» без знака), если после этого будут еще какие либо данные достаточной длины.
I'll crash you!
Ясно, что эффективность фаззинга напрямую зависит от сложности формата входных данных и многообразия подготовленных сэмплов. Если мы говорим об известном формате, то исследователь подготавливает описание этого формата (что может быть очень трудоемко), по которому могут генерироваться данные. Далее, чем больше вариантов будет создано, тем больше вероятность, что мы что-то найдем. В случае, если мы используем мутирующие алгоритмы, важно иметь большое количество «образцов», которые мы будем мутировать и «подсовывать» исследуемому процессу. Очевидно, что мутация – более «дешевое» средство, а генерация – более «полное». У обоих подходов есть свои преимущества и недостатки и, очевидно, что можно как-то усилить эффект (скорость и/или полноту) фаззинга, тем самым повысив показатели падений процесса. Из количества «падений» затем выбираются уникальные, то есть если при трех наборах данных процесс упал по одной и той же «причине», это считается одним уникальным падением. Чем больше число уникальных падений, тем эффективнее фаззер.
More profit...
Как известно, все в этом мире прогрессирует, включая и фаззинг. Казалось бы, простая технология, но исследователи хотят найти большее количество уникальных и эксплуатируемых состояний процесса, поэтому они придумывают новые финтифлюшки и алгоритмы. Так, уже в 2006 году Шаун Эмблитон (Shawn Embleton), Шерри Спаркс (Sherri Sparks) и Райн Каннингхэм (Ryan Cunningham) задались вопросами увеличения производительности. Они справедливо отметили преимущества фаззинга, но и показали его недостатки (отсутствие метрик, неопределенное время фаззинга и т.п.) и разработали свой проект, который уже фаззил с умом. Строил граф (бинарным анализом), от функции получения входных данных, до, например, опасной API (strcpy) и генерировал новые входные данные, смотря при этом, как обходится граф и идет ли он до цели. Задача – откинуть заранее тупиковые наборы данных, которые не приведут к нужному пути. При этом используется генетический алгоритм для генерации новых сэмплов (учитываются предыдущие пробеги и их результат). Так или иначе, ребята, родившие эти идеи и реализовавшие свой проект, уже работают в АНБ :). Более подробно с их идеями можешь ознакомиться на blackhat.com/presentations/bh-usa-06/BH-US-06-Embleton.pdf.
In-Memory Fuzzing
Вернемся к ситуации, когда входной формат разбирать очень лень. Как проводить фаззинг без знания формата и без игры в мутацию существующих данных? Ответ оказался прост – фаззить прямо в процессе. То есть, программа – это набор функций, при получении выходных данных эти функции вызываются, так или иначе обрабатывая входные данные, поэтому можно организовать вызов этих функций напрямую с заранее сгенерированными данными. Таким образом можно сэкономить время на разборе формата и подготовке данных согласно этому формату. Кроме того, это может повысить и скорость самого процесса поиска дыр; так, например, мы обходим ограничения, которые могут быть в программе (например, при сетевом фаззинге мы ограничены скоростью обработки подключения, количеству одновременно разрешенных соединений и т.д.). А если будем перебирать данные уже в самом процессе, обойдя accept, recv, то сможем сразу фаззить нужные нам функции. Поможет нам в этом релиз от CorelanSecurity Team, который можно скачать отсюда – redmine.corelan.be:8800/projects/inmemoryfuzzing/files. На самом деле этого не достаточно, еще нужны Pydasm (therning.org/magnus/archives/278) и Paimei (openrce.org/downloads/details/208/PaiMei). Естественно, нужен интерпретатор Питона и Immunity Debuger (debugger.immunityinc.com/register.html. Кстати, с дистрибом дебагера идет и Питон, так что качать интерпретатор отдельно не надо) c плагином pvefindaddr.py (redmine.corelan.be:8800/projects/pvefindaddr). Как ты уже понял, все будет не так просто, все это шаманство еще надо собрать в следующей последовательности:
- Ставим Иммунити Дебагер с Питоном;
- Качаем pvefindaddr, кидаем в папку PyCommand в (директории дебагера);
- Качаем и инсталим pydasm для Питона 2.5;
- Качаем ПайМэй, распаковываем, идем в папку installers, запускаем установщик;
- Удаляем из папки питона ПейМеевский pydasm – Python25Libsite-packagespydbgpydasm.pyd.
Теперь PyDbg готов к работе с Питоном 2.5. После этого можно пробовать что-нибудь фаззить. Но для начала надо понять, что именно, а точнее, какие функции процесса работают непосредственно с данными.
Напишем простую программку, которая берет из файла параметры через символ-разделитель и копирует в память. Программа будет брать три параметра, каждый из которых обрабатывается отдельной функцией. Уязвимость будет во второй функции – переполнение буфера.
void func1(char* input)
{
char buffer[255];
unsigned int len=strlen(input);
if(len<255)
strcpy (buffer , input);
fputs("FUNC1: done!n",stdout);
}
void func2(char* input)
{
char buffer[255];
strcpy(buffer,input);
fputs("FUNC2: done!n",stdout);
}
void func3(char* input)
{
char buffer[255];
strncpy(buffer,input,254);
fputs("FUNC3: done!n",stdout);
}
Понятно, что уязвимость можно найти просто обыкновенным файл-фаззингом, но представим себе, что первоначально файл сжат или зашифрован, тогда так просто и быстро подсунуть данные в файл не получится. Тогда-то нам и поможет работа прямо в памяти. Подготовим входные параметры в файле input.txt: function_1:function_1:function_3. Наша уязвимая программа (vuln.exe) обработает входные данные и скажет, что все ОК. Начнем искать ошибку в программе с помощью фаззинга. Первым делом получим список функций модуля. Это может сделать pvefindadr. Аттачимся дебагером к процессу, выбираем наш плагин и задаем «functions -o -m vuln.exe». После этого в папке дебагера появится файл functions.txt. В этом файле будет полный список адресов функций нашей программы. Берем этот файлик и копируем рядом с Trace.py. Делаем деаттач дебагером, после чего запускаем Trace.py, который спросит, к чему нам присосаться, и какие данные мы ждем. Ищем в списке наш vuln.exe и выбираем его номер. В качестве данных – «func». После этого повторяем чтение файла в приложении. Трейсер отловит те функции из functions.txt, которые в качестве параметров обрабатывают «function_». Кроме того, он запомнит и точку выхода (RET), а также сдвиг в стеке до параметра (запомни, что первый параметр, как правило – ESP+4, второй, если есть – ESP+8). Сохранит он все это в текстовых файлах new_functions_addrs.txt (адреса входа-выхода) и flow_log.txt (адрес функции и оффсет до параметра). После этого по CTRL+C выходим из трейсера, и можно начинать фаззить :). Прежде всего выберем из flow_log.txt функции, которые будем фаззить (ищем ESP+4 на данные), найдем их точки входа/выхода в new_functions_addrs.txt и создадим файлик breakpoints.txt, где укажем интересующие нас функции. Формат файла получается таким:
0x00401000 0x0040106d ESP+4
0x00401070 0x004010c7 ESP+4
0x004010d0 0x00401125 ESP+4
Запускаем фаззер InMеmoryFuzzer.py и опять повторяем аттач к vuln.exe. Выполнив еще несколько раз чтение входных данных, фаззер каждый раз, как встретит функцию из списка, начнет прямо в памяти менять входной параметр и смотреть, дошла ли она до точки выхода (адреса возврата) или свалилась в исключительную ситуацию (падение). В случае падения создается папка «crashbin» куда скидывается инфа о падении. В итоге прогона видим, что мы перезаписали адрес возврата во второй функции (см. скриншоты и видео на диске). Конечно, данный экземпляр фаззера (InMemoryFuzz) несовершенен, но это лишь начало – в любом случае ресерчер делает фаззер для себя сам, используя существующие проекты и наработки в соответствии с задачами, которые он решает... Так, например, pvefindaddr находит далеко не все функции, поэтому лучше юзать для этого дела IDA. Приятно, что фаззер может делать выводы об ошибке – на скриншоте видно, что во второй функции (00401070) происходит падение при записи в стек. На глаз видно, что это реализация strcpy – побайтовое копирование строки, пока не встретится нулевой байт. Падение произошло, когда был достигнут конец стека. В этом случае управление перейдет на обработчик в исключительной ситуации (фаззер отметил, что десркиптор захвачен нами, так как сравнил значение указателя с данными, которыми он подменял параметр уязвимой функции). Кстати, таким образом мы обойдем и защиту от переполнения буфера (vuln.exe скомпилирован с флагом /GS), ведь security cookie проверяется непосредственно перед выходом из функции, а мы перехватили управление задолго до этого, в процессе копирования строки.
Статистика сэмплов при фаззинге
Для сложного формата файла:
- мутирующим фаззером – из 3*10^6 получается 5*10^3 падений, из них 1-3 эксплуатируемые;
- описывающим протокол – из 1*10^6 получается 15*10^3 падений, из них 6-10 эксплуатируемые;
Для простых форматов файлов:
- мутирующим фаззером – из 1*10^5 получается 150 падений, из них 0-3 эксплуатируемые;
- описывающим протокол – из 1*10^4 получается 150 падений, из них 0-1 эксплуатируемые.
Пример простого фаззинга можно найти на http://sites.google.com/site/felipeandresmanzano. Там продемонстрировано, как с помощью очень простых мутирующих фаззеров добиться очень хороших результатов.
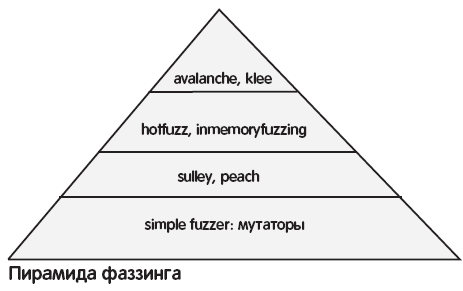
Теперь рассмотрим виды фаззеров, с помощью которых можно добиться практического успеха. Начнем со «стариков».
Sulley и peach
Это очень мощные фаззеры с возможностью описывать протокол для фаззинга. Например, для фаззинга FTP нужен конфиг в 329 строчек, из которых большая часть – описание самого протокола. Для более сложных протоколов конфиг будет огромным, и его составление будет очень трудоемким. Очень актуальное решение предлагает проект hotfuzz (hotfuzz.atteq.com).
Схема его работы на первый взгляд громоздкая, но на самом деле очень простая.

Hotfuzz основан на peach и является его оберткой. Устанавливается без проблем – все модули идут в одном пакете. Его главная особенность состоит в том, что описание протокола, который нужно фаззить, делается не вручную, составляя конфигурационный файл, а с использованием специальной библиотеки tm_export, основанной на tshark (одной из составляющих частей сниффера wireshark). Эта библиотека, используя дамп трафика, формирует дерево – структуру, описывающую протокол. И нам необходимо лишь выбрать поля, которые мы хотим фаззить, и... все! Это существенно упрощает работу – не нужно тратить много времени на составление конфигурационного файла, как это делалось при эксплуатации peach (демонстрационное видео смотри на DVD).
Важно помнить!
Для анализа падений приложения можно использовать разные средства. Чтобы автоматизировать этот процесс, я, например, использую winappdbg.
Я написал простой скрипт, который дергает тестированное приложение в среде winappdbg и в автоматическом режиме может определить эксплуатируемость уязвимости.
Самые умные: avalanche и klee
Рассмотрим avalanche (http://code.google.com/p/avalanche/).
Avalanche может анализировать только клиентские приложения (для случая чтения из сокетов). И приложения, читающие из файлов. Поддержка анализа серверных приложений будет добавлена в следующих версиях, но пока до этого достаточно далеко. Avalanche должен быть установлен и запускаться из той же директории, что и stp и valgrind (и немаловажный нюанс – должны собираться все вместе).
Команды сборки следующие:
$ wget http://avalanche.googlecode.com/files/avalanche-0.2.tar.gz
$ tar -xvf avalanche-0.2.tar.gz
$ cd avalanche-0.2
$ configure --prefix=pwd/inst
$ make
$ make install
и запуска:
$ ./inst/bin/avalanche --filename=samples/simple/seed --debug samples/simple/sample2 samples/simple/seed
Сначала должны быть все опции для Avalanche, а анализируемое приложение и опции для него – в конце. Оружие к бою готово :).
Почему avalanche стоит у верхушки пирамиды? Рассмотрим немного теории об avalanche и динамическом анализе в целом, после чего ты все сам поймешь.
Итак, в недавнее время были предложены различные способы, позволяющие использовать динамический анализ для одновременного нахождения ошибок и входных данных, позволяющих их воспроизводить. Суть этих методов сводится примерно к следующей схеме: вводится понятие символических или помеченных (tainted) данных – данных, полученных программой из внешнего источника (стандартный поток ввода, файлы, переменные окружения и т.д.), тем или иным способом собирается информация обо всех использованиях помеченных данных в программе. Эта информация записывается в виде булевых ограничений на значения помеченных данных (в эти ограничения может попадать информация о переходах, зависящих от помеченных данных, и информация об использованных помеченных данных в потенциально опасных местах программы). Нахождение значений помеченных данных, делающих эти ограничения выполнимыми, может означать либо возможность возникновения ошибки в программе, либо возможность обхода иных, отличных от обойденных во время первого запуска, частей программы.
Avalanche реализует подобный подход на основе открытого фреймворка для динамической интерпретации Valgrind и инструмента для проверки выполнимости ограничений (solver/решатель) STP. Инструмент Avalanche состоит из четырех основных компонент: двух модулей расширения (плагинов) Valgrind – Tracegrind и Covgrind, инструмента проверки выполнимости ограничений STP и управляющего модуля. Tracegrind динамически отслеживает поток помеченных данных в анализируемой программе и собирает условия для обхода ее не пройденных частей и для срабатывания опасных операций. Эти условия при помощи управляющего модуля передаются STP для исследования их выполнимости. Если какое-то из условий выполнимо, то STP определяет те значения всех входящих в условия переменных (в том числе и значения байтов входного файла), которые обращают условие в истину.
В случае выполнимости условий для срабатывания опасных операций, программа запускается управляющим модулем повторно с соответствующим входным файлом для подтверждения найденной ошибки.
Выполнимые условия для обхода не пройденных частей программы определяют набор возможных входных файлов для новых запусков программы. Таким образом, после каждого запуска программы инструментом STP автоматически генерируется множество входных файлов для последующих запусков анализа. Далее встает задача выбора из этого множества наиболее «интересных» входных данных, то есть в первую очередь должны обрабатываться входные данные, на которых наиболее вероятно возникновение ошибки. Для решения этой задачи используется эвристическая метрика – количество ранее не обойденных базовых блоков в программе (базовый блок здесь понимается в том смысле, как его определяет фреймворк Valgrind). Для измерения значения эвристики используется компонент Covgrind, в функции которого входит также фиксация возможных ошибок выполнения. Covgrind – гораздо более легковесный модуль, нежели Tracegrind, поэтому возможно сравнительно быстрое измерение значений эвристики для всех полученных ранее входных файлов и выбор входного файла с наибольшим значением.
Из всего вышесказанного можно сделать вывод: Avalanche – перспективный проект, который реализует обход графа выполняемой программы, что есть достаточно новый подход в анализе качества ПО. Также в этом проекте говорится про тентирование (tainted analysis[2-5]), что, на мой взгляд, является революционным подходом в данном направлении, и в последнее время очень много внимания уделяется именно этому вопросу.
Немного про STP
У STP и у всех bitvector’ных решателей (да и вообще у всех решателей) есть ряд недостатков. Ну, хотя бы то, что они все не поддерживают циклы (loop). Сейчас много работ, посвященных как раз разработке теории и реализации алгебраической формы, которая может быть использована решателем для представления цикла (loop) в САП (control flow graph). Вот ссылки на последние достижения в этой области:
- groups.csail.mit.edu/pag/daikon;
- http://research.microsoft.com/en-us/um/people/sumitg/pubs/vmcai09_cons.pdf
- groups.csail.mit.edu/pag/pubs/annotation-study-fse2002-abstract.html
Немного десерта
Avalanche –это не единственный проект, который реализует прорисовывание графа выполняемой программы в зависимости от входных параметров. Очень похожий проект имеет название KLEE (klee.llvm.org). Но о нем в другой раз – это тема для отдельной статьи.
Полезное
- winappdbg.sourceforge.net/Tools.html
- “Certification of programs for secure information flow” – Dorothy E. Denning and Peter J. Denning. 1977 – Communication of the ACM.
- “A lattice model for secure information flow” – Dorothy E. Denning – 1976 – Communication of the ACM.
- “Dytan: A generic dynamic taint analysis framework” – James Clause, Wanchun Li, and Alessandro Orso. Georgia Institute of Technology.
- “Understanding data lifetime via whole system emulation” – Jim Chow, Tal Garfinkel, Kevi Christopher, Mendel Rosenblum – USENIX – Stanford University.
- “LIFT: A Low-Overhead Practical Information Flow Tracking System for Detecting Security Attacks” - Feng Qinz Ho-seop Kim, Yuanyuan zhou, Youfeng Wu - University of Illinois at Urbana-Champaign.
- www.fuzzing.org
