Содержание статьи
В прошлых уроках мы говорили о том, как писать программы так, чтобы их можно было запустить в нескольких экземплярах и тем самым выдерживать большую нагрузку. В этом уроке мы поговорим о еще более интересных вещах — как использовать для построения технической архитектуры знания о бизнес-логике продукта и как обрабатывать данные тогда, когда это нужно, максимально эффективно используя аппаратную инфраструктуру.
Отложенные вычисления
Когда пользователь вводит запрос на сайт, необходимо дать ему ответ, и для этого сначала придется проделать соответствующую работу. Скажем, если человек сделал модификационный запрос (например, создал новый пост), то вам предстоит провернуть огромный объем работы. Недостаточно просто положить пост. Нужно обновить счетчики, оповестить друзей, разослать электронные уведомления. Хорошая новость: делать все сразу необязательно.
Тот же самый Facebook после того, как вы публикуете новый пост, делает еще одиннадцать разных вещей — и это только то, что видно снаружи невооруженным глазом. Причем все эти операции исполняются в разное время. Например, электронное письмо с уведомлением можно послать вообще минут через десять. Этот принцип мы и возьмем на вооружение. Любой маленький сайт по мере роста нагрузки сталкивается с тем, что, оказывается, больше нельзя делать все необходимые операции синхронно в функции обработки самого модификационного запроса. В противном случае пользователь не получит моментальный ответ.
Современные языки веб-программирования часто не позволяют в явном виде реализовать такой трюк, поскольку в них не предусмотрена возможность делать что-либо после ответа. Однако есть и исключения. В популярном веб-сервере Apache существует более десяти стадий обработки запроса, включая трансляцию URI, авторизацию, аутентификацию и собственно обработку запроса. Сюда же входят и стадии, которые выполняются уже после того, как ответ пользователю отправлен. Некоторые фреймворки (например, mod_perl) позволяют перехватить эти стадии и повесить на них ваши собственные функции. Можно передать в эти функции данные для обработки и спокойно обрабатывать их уже после того, как пользователь получил ответ.
Асинхронная обработка
Однако иногда описанного выше подхода с постобработкой данных недостаточно. Действия, которые надо совершить с ними, могут занимать слишком много времени, а ресурсы веб-сервера небезграничны.
В таком случае помогает следующий архитектурный паттерн — сохраните данные в некое промежуточное хранилище, а затем обработайте их с помощью отдельного асинхронного процесса. Термин «асинхронность» означает в общем случае разнесенность во времени. То есть данные собираются сейчас, а обрабатываются тогда, когда будет удобно.
Например, очень часто асинхронно обсчитывается статистика уникальных посетителей — раз в день, как правило по ночам, в часы наименьшей загрузки, запускается скрипт, который берет весь массив данных, накопленных за день, обрабатывает их и сохраняет уже в другом виде. Такой подход применяется при разработке баннерных сетей, счетчиков и других подобных проектов. Часто в часы наименьшей нагрузки выполняются и различные обслуживающие процедуры: оптимизация баз данных, бэкапы.
Обратите внимание — мы уже используем наше знание о бизнес-процессах в проекте. Мы знаем, что детальную статистику за день пользователи готовы подождать, и учитываем этот факт при проектировании архитектуры проекта. Более углубленное использование этих знаний мы с вами разберем дальше.
Очереди
Рассмотрим подробнее инструменты, позволяющие отложить на потом те вещи, которые «не горят». Одно из уже упоминавшихся решений — промежуточное хранилище. Но существует целый класс однотипных задач, для которых хотелось бы, чтобы это хранилище обладало определенными свойствами. Это уже не просто данные для обработки — тут важен порядок, важна очередность.
Для подобных целей используют инструмент, называемый очередями, — особый вид хранилища, поддерживающий логику FIFO (первый вошел — первый вышел). Получаются очереди сообщений и очереди задач, которые надо делать. Например, вместо того чтобы слать e-mail, можно поместить в очередь задачу: «Послать e-mail». Какой-то фоновый скрипт, который запущен, вытянет из очереди новый запрос. «О, надо послать e-mail. Сейчас пошлю его».
Очереди — довольно продвинутый и часто встречающийся инструмент. Например, даже когда пользователь в Windows кликает мышкой на кнопку в приложении, то приложение не принимается немедленно обрабатывать это событие (ведь в этот момент приложение может быть занято другим действием). Операционная система присылает приложению сообщение, содержащее описание совершенного пользователем действия. Сообщение ставится в очередь и будет обработано в порядке поступления. В результате если вы два раза кликните мышкой на два разных пункта меню, то сначала откроется одно, потом другое.
Для использования очередей есть ряд инструментов, один из наиболее популярных сейчас — RabbitMQ (www.rabbitmq.com), написанный на Erlang'е. Причем несмотря на колоссальные возможности по обслуживанию очередей сообщений, начать использовать его крайне просто. Практически для любого языка программирования (PHP, Python, Ruby и так далее) есть готовые библиотеки.
В крупных веб-системах могут использоваться одновременно десятки очередей: очередь на отправку электронной почты, очередь для обновления счетчиков, очередь для обновления френдлент пользователей.
По большому счету очереди — это пример межсервисной коммуникации, когда один сервис (публикация поста) ставит задачи другому сервису (рассылка электронной почты). Рассмотрим это подробнее на конкретном примере.
Пример премодерируемой социальной сети
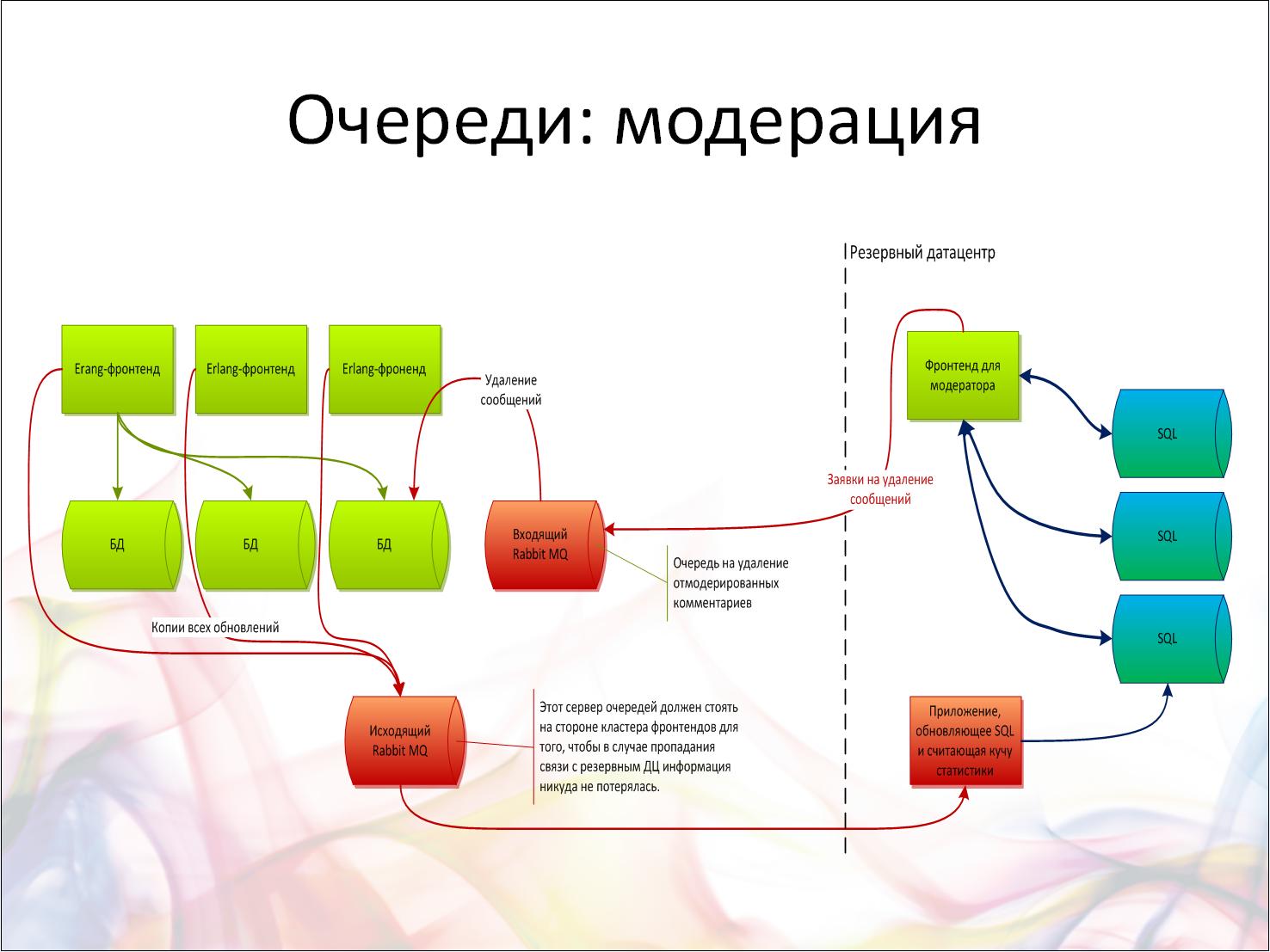
Рассмотрим пример большого проекта социальной сети уровня Facebook. Пользователи пишут посты в огромном количестве, генерируются гигантские объемы различных операций. Но допустим, что это не просто Facebook, а социальная сеть с премодерацией всех сообщений. Задача стала еще сложнее — что делать?
Разработчики посмотрели: посты храним так, комментарии храним так. Всё в разных табличках, может быть даже в базах данных разного вида. Например, этих баз и табличек десять. Неужели модераторский софт должен будет ходить по десятку баз данных, вытаскивать обновления за последние пять минут из всех этих табличек? Объединять все изменения в один большой список и показывать модератору? А что, если модераторов несколько? А если данных очень много?
Вот тут на помощь и приходят очереди. Любой постинг приводит не только к добавлению сообщения в большую базу данных (где оно будет жить постоянно), но и к его попаданию в некую модераторскую систему. Взаимодействие сервисов позволяет навести тут порядок.
Нижний красный блок на слайде — это исходящий сервер очередей RabbitMQ, который получает сообщение. Этот сервер кем-то слушается с той стороны, и в результате приходящие данные перегруппировываются и уже складываются в другую базу данных или в другое место, специально предназначенное для модерации. Например, они группируются, и вместо модерации может идти, например, аналитическая система. Сам бог велел входящие данные преобразовывать, чтобы потом было удобно их обрабатывать и решать данную конкретную узкую задачу.
Но вернемся к нашему примеру. Все эти сообщения каким-то образом просматриваются, и, так как схема базы данных заточена под модерацию, это происходит легко и просто. Нам что-то не нравится — удаляем это сообщение, и запрос точно так же уходит обратно, в другую очередь: «Это сообщение из тех, что ты мне прислал, удали». Есть такой же разборщик, который берет эту задачу c удаленным сообщением, ищет, где же оно там все-таки лежит, и удаляет.
Мы получили классический пример использования очереди.
Неконсистентность данных
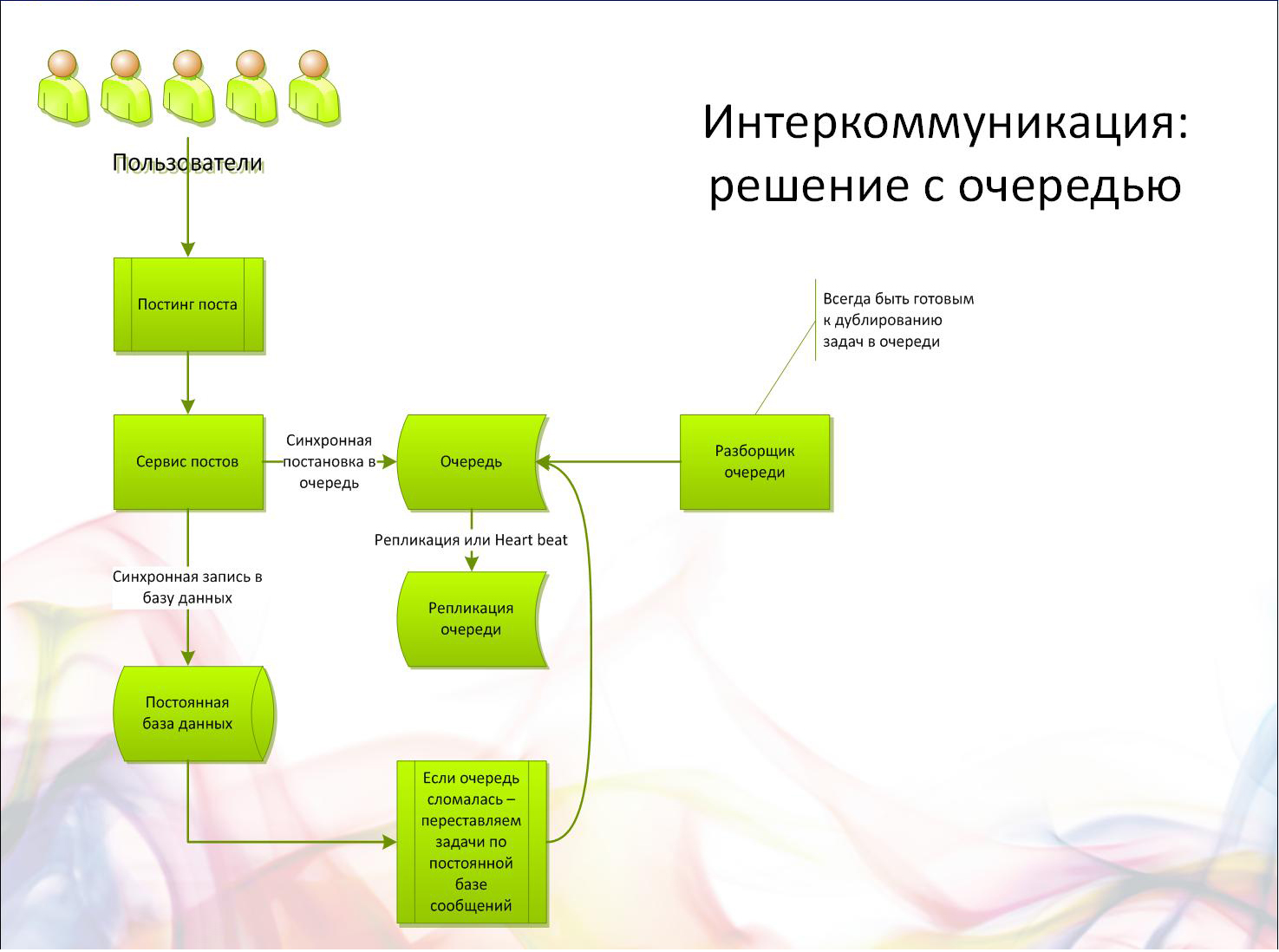
Здесь возникают недостатки, характерные для любой системы, которая хранит данные в двух местах. Любая проблема с оборудованием, с выполнением этой сложной функциональности — и возникает неконсистентность данных. Например, сообщение попало в основную базу, но не было добавлено в очередь. Сообщение прошло модерацию, но оно реально удалено не было, потому что очередь, ответственная за хранение сообщений на удаление, вышла из строя.
Чтобы избежать этого, нужно писать программу таким образом, чтобы при повторном ее выполнении она доходила до конца. Этот принцип называется идемпотентностью — повторное действие не изменит наши данные, если в первый раз все было сделано правильно. Увы, это далеко не всегда можно применить. Другое решение — логическое логирование действий. Создается некий блокнот, например файл, хранящийся на каком-то надежном носителе. Программы при выполнении оставляют там записи вида: «Я успел сделать то, то и то, но еще не успел сделать вот это» и «Я собираюсь сделать это». Если что-то пошло не так, подобный отчет позволит понять, на каком этапе произошел сбой, и исправить положение.
Алгоритм проектирования архитектуры
Рассмотрим решение нашей проблемы, исходя из конкретных условий бизнес-логики. Сначала составляем варианты использования проекта (Use cases), функциональное описание, в нашем случае — основные веб-сервисы. Описываем, что конкретно делает пользователь на той или иной странице. Например, страница news feed пользователя:
- загружаются десять последних объектов-записей по времени объектов, опубликованных всеми пользователями, на которых подписан пользователь;
- для каждой из записей поднимается информация о пользователе-авторе (имя, аватар и ссылка на профиль);
- для каждой из записей на странице поднимаются три последних комментария, по каждому комментарию поднимается аватар и имя пользователя.
Отдельного упоминания заслуживает обсуждение потенциальных сценариев дальнейшего развития проекта. Например, сейчас нет обновления комментариев без перезагрузки, а потом будет — такую возможность нужно предусмотреть еще на этапе начального проектирования. Далее по этим описаниям планируются потоки данных с расчетом потенциальных объемов, требований к скорости в каждом случае. Важно также проговорить потенциальную степень деградации данных.
Например, у нас ожидается тридцать миллионов зарегистрированных пользователей в новой потенциальной социальной сети. По аналогии с существующими сетями предположим, что в день на сайт будет заходить ⅕ зарегистрированных пользователей, то есть шесть миллионов пользователей. Какое количество записей делает в день пользователь? Этот вопрос требует исследования, но допустим, что в среднем три сообщения в день кто-то больше, кто-то меньше. На практике большинство будет заходить на сайт только для чтения чужих сообщений, поэтому сократим в пять раз — пусть пишет по три сообщения каждый пятый пользователь.

Получается 3,6 миллиона записей в сутки. У каждого пользователя 100 подписчиков, то есть (если мы остаемся на схеме уведомлений об изменениях) 360 миллионов уведомлений в сутки.
С учетом пикового характера веб-трафика получаем 10 тысяч уведомлений в секунду — это может быть проблемой! Мы видим такую цифру и понимаем, что нам придется рассылать уведомления не в реальном времени.
Чтобы рассчитать объемы данных, допустим, что половина сообщений текстовые, а половина — графические. Размер текстового сообщения в среднем 200 байт, графического — 100 килобайт. Итого в день мы генерируем данных на 360 мегабайт текстовых сообщений и на 180 гигабайт графики. Это немало, и очевидно, что мы не можем просто положить тексты в SQL базу данных и делать по ней выборки. Максимум — мы можем делать выборки по некоей упрощенной информации, например таблицам с идентификаторами.
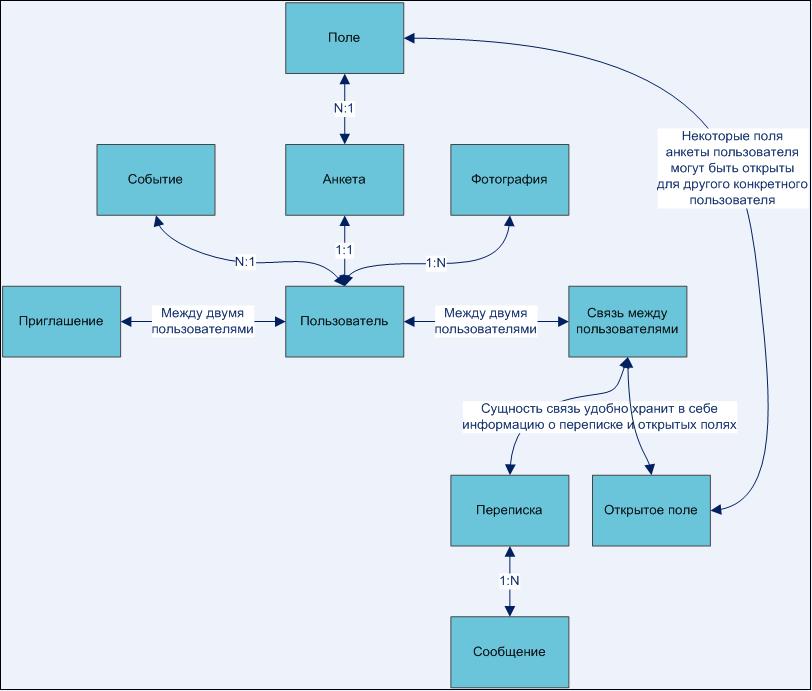
На этом этапе можно и нужно проговорить сущности и связи между ними. Например, как на приведенном рисунке. Это пример из реального проекта простой социальной сети, разработанной нашей компанией.
Здесь же мы проговариваем вопросы деградации, для этого продакт-менеджер должен ответить нам на следующие вопросы:
- Страшно ли, если запись друга появится в news feed пользователя не моментально, а через пять секунд? А если через десять? Через минуту? Через час? Какова допустимая задержка?
- Сколько последних записей мы выводим на одной странице? Десять? Двадцать? Могу ли я перейти к более старым записям?
- Должны ли новые записи появляться на странице без перезагрузки?
- Должны ли новые комментарии к записям, находящимся на странице, появляться без перезагрузки страницы?
- Страшно ли, если записи будут подгружаться пользователю постепенно, не сразу, сначала одна, потом еще пять, а потом вдруг раз — и загрузилась запись где-то в середине.
Здесь же мы прописываем скорость работы страницы (в нашем случае не более 0,2–0,5 секунды, например) и проговариваем какие-то особенности использования модуля. Например, в нашем случае с news feed это может быть: 99% пользователей просматривают ленту своих записей на одну-три страницы назад (обычно до последней прочитанной записи). Архив просматривается крайне редко. Можем ли мы как-нибудь использовать эту особенность? Нам не надо показывать пользователю сразу всю страницу, мы можем показать ему пару записей и, пока он смотрит на них, подгружать остальные.
Вот тут надо понаблюдать за работой конкурентов, например того же Facebook. Алгоритм работы примерно такой:
- сначала загружается обвязка;
- затем происходит запрос идентификаторов записей для данной news feed;
- затем в цикле, начиная от самых старых, запрашиваем подробности про записи.
Эту схему можно упростить — например часть данных в виде JSON загружать заранее при загрузке страницы. Если посмотреть страницы Facebook, вы увидите только JavaScript, все данные представлены в виде JSON-массивов. Это очень удобно — просто сделать AJAX-обновление страницы без перезагрузки.
Далее нужно сформулировать дополнительные технические требования к отказоустойчивости и скорости всей системы и отдельных веб-сервисов. Наконец, для каждого из веб-сервисов, исходя из конкретных особенностей данных и требований к каждому компоненту, проектируем архитектуру и подбираем технологии. Многие технологии имеют аналоги, и среди кластера технологий выбор стоит делать на основе предпочтений команды разработчиков. Что умеют, на том и надо работать.
Итак, у нас есть довольно существенный поток данных, обладающих, однако, определенными особенностями. Похоже, что стоит разделить сами записи и структуру news feed’ов.
Не все данные нужно показывать сразу, успокоил нас продакт-менеджер и дал пару минут, чтобы поместить новое сообщение пользователя во френдленты его друзей. Строго говоря, это может быть и не так исходя из бизнес-логики проекта. В этом случае мы с вами выбрали бы другую архитектуру для системы хранения френдлент.
При обсуждении продакт-менеджер сказал нам также, что рассылку почтовых уведомлений мы можем отложить на потом. Мы рассчитали объем задач, прикинули систему хранения для очереди и приступили к реализации.
Строго говоря, использование серверов очередей не обязательно. Не умеете работать с RabbitMQ? Ничего страшного — используйте паттерн «Очереди», но храните список задач в обычном MySQL.
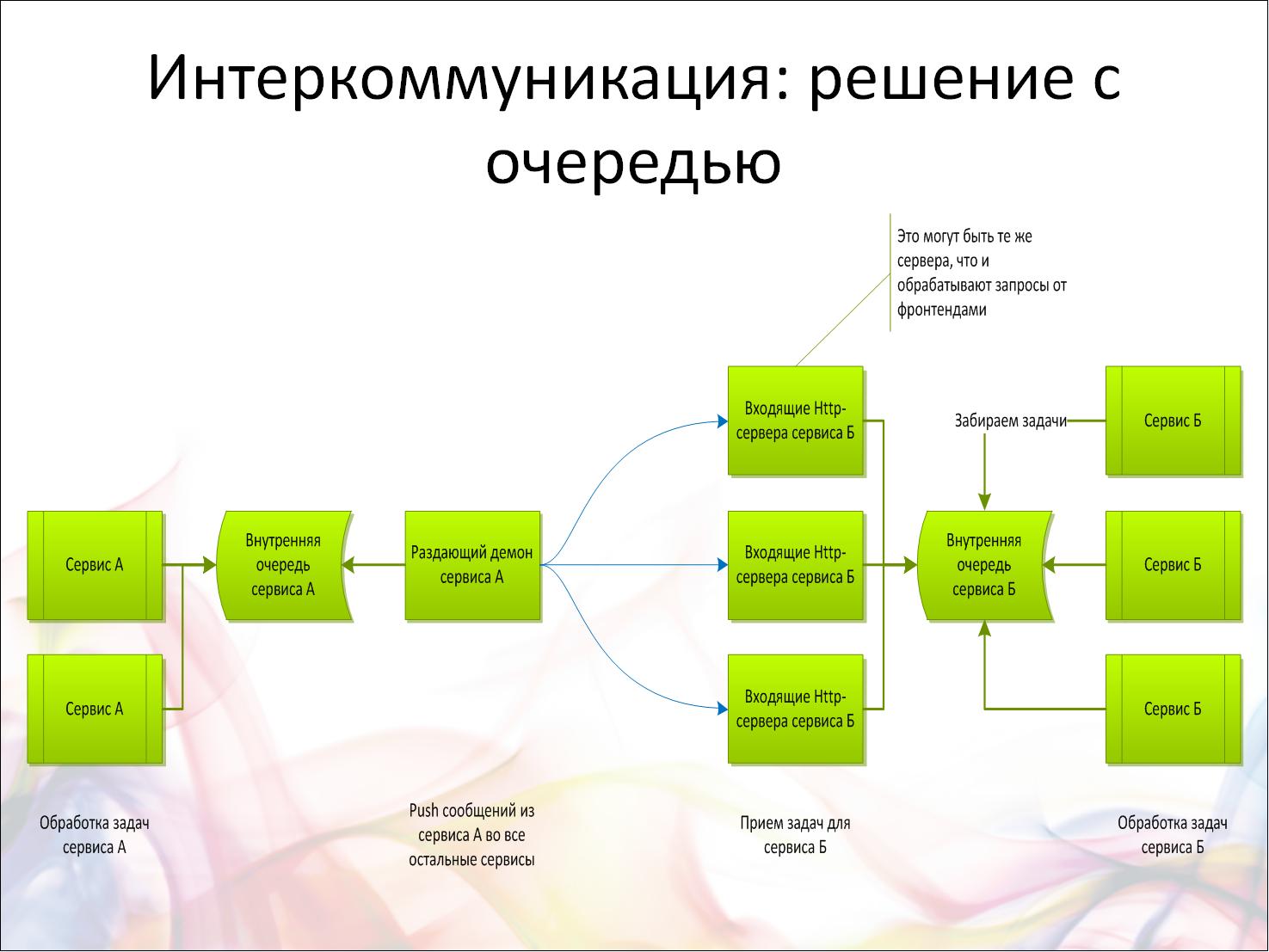
Использование очередей для достижения надежности Усложним задачу из примера с почтовыми рассылками. Итак, воркеру, обслуживающему почтовые рассылки, нужно разослать 25 писем. Три послали, на четвертом закончилось место на диске. Хлоп, сломалось! Если вы пишете синхронную рассылку в едином PHP-коде, то у вас из-за отвалившегося почтовика может возникнуть 500-я ошибка для пользователя. Это вообще неприемлемо.
Это важный аспект — с помощью очереди сообщений можно позволить сломаться какому-то куску вашей системы. Например, в одном из проектов, который мы разрабатывали, запись в базу шла через очередь сообщений. Это было очень удобно. Можно было для решардинга и других обслуживающих операции выключить один из кусков базы данных на какое-то время. Все это время у нас тупо росла очередь сообщений и что-то не записывалось. Потом, когда базу чинят и снова подключают, очередь рассасывается.
Таким образом, очередь сообщений позволяет вам еще и функционально развязать куски всей вашей экосистемы и позволить кому-то сломаться на время без общей деградации.
На рисунке изображено два сервиса, которые полностью независимы друг от друга. Поломка одного не приводит к поломке другого. Допустим, сервису А нужно отправить что-нибудь в сервис Б. Он ставит задачу во внутреннюю очередь сервиса А. Раздающий демон (своего рода выходные ворота сервиса А) разбирает внутреннюю очередь и рассылает запросы вовне.
Входные ворота сервиса Б принимают запрос и пишут его во внутреннюю очередь сервиса Б. Воркеры сервиса Б обрабатывают задачи из внутренней очереди. Подобная система не только практически неубиваема, она еще и восстанавливается после сбоя без потери данных :). Может сложиться впечатление, будто это нечто запредельное, но это не так. В крупных банковских системах подобные архитектуры встречаются на каждом шагу. Да и в веб-системах можно использовать что-то похожее для достижения независимости сервисов друг от друга.
В качестве резюме
Итак, мы изучили один из самых мощных паттернов в проектировании веб-систем — использование очередей.
Под очередями сообщений в проектировании веб-проектов могут пониматься две разные вещи. Во-первых, способ отложить задачу «на потом». Нам надо сделать что-то, но пользователю надо ответить прямо сейчас. Мы выходим за рамки PHP’шного «запрос — ответ» и делаем что-то чуть позже, чем отдали ответ.
Во-вторых, речь может идти о так называемой общей шине данных. У нас возникает межсервисная коммуникация, которая помогает разнести вызовы между сервисами, сделать их разными по времени и унифицировать общение между разными сервисами.
Удачи! В следующем номере самое сложное — масштабирование баз данных.