
Содержание статьи
За минуту Google обрабатывает около двух миллионов поисковых запросов и отдает пользователям 72 часа видео через YouTube. Twitter за это время сохраняет 278 тысяч твитов, Facebook размещает 2,5 миллиона постов, а Instagram принимает 3600 фото ежесекундно. Если достаточно долго думать об этих цифрах, можно сойти с ума, но веб-сервисы как будто справляются с этим легко и практически не заставляют нас ждать. Как же это работает?
Приведенные цифры могут вызывать зависть даже у тех, кто не понаслышке знаком с понятием highload, однако ничего удивительного в них нет. Все перечисленные сервисы управляются обычными серверами, основанными на самых обычных Linux-дистрибутивах и открытом общедоступном софте (за исключением разве что Google). Вопрос только в том, какие инструменты используются и насколько хороши системные архитекторы.
В этой статье я не буду рассказывать об архитектуре высоконагруженных систем, а вместо этого расскажу о ПО, которое они используют. Какие приложения, почему именно они, и как их использование позволяет поднять общую производительность сервиса.
GFS, BigTable и MapReduce
Пятнадцать лет назад для поддержки высоконагруженных сайтов применялись довольно простые и примитивные по сегодняшним меркам методы. В основном вся оптимизация сводилась к покупке NAS и нескольких серверов, которые использовались для запуска MySQL и веб-серверов. Более крупные компании имели сразу несколько таких конфигураций, располагающихся в разных частях планеты и обслуживающих различные группы клиентов.
В условиях статичных веб-сайтов, низких скоростей и небольшой доли интернетизации такие схемы работали достаточно эффективно и покрывали запросы многих компаний. Однако для Google, которая быстро вышла на международную арену и фактически предлагала один и тот же сервис по всей планете, без возможности логического разделения запросов и данных по каким-либо типам, такая архитектура быстро превратилась в крайне неэффективную.
Google нужна была система, которая позволяла бы обрабатывать большое количество данных с помощью множества серверов по всему миру и сохранять их в одно доступное отовсюду хранилище, при этом чтобы доступ к данным из любой точки был быстрым. Тогдашние средства параллельной обработки и хранения данных для такой задачи не подходили, поэтому пришлось изобретать свое.
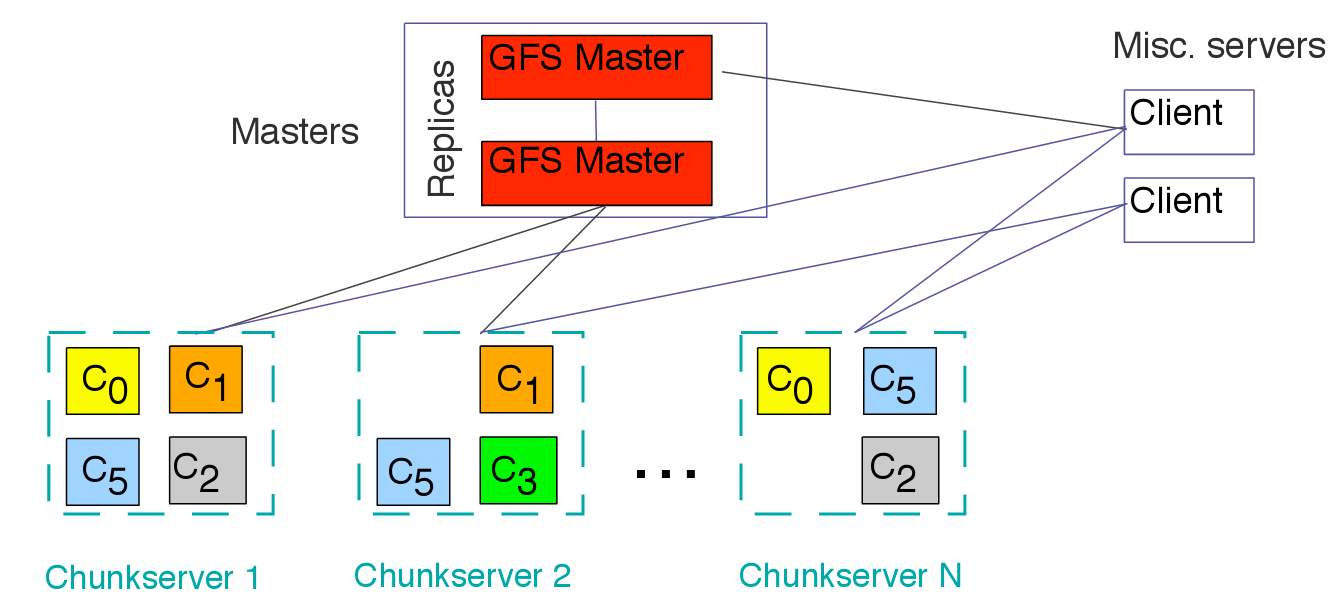
Так появились Google File System, а чуть позже MapReduce и BigTable. Итак, первое звено цепочки: Google File System — распределенная (не путать с кластерной, например Lustre) файловая система, изначально рассчитанная на хранение огромных объемов данных на множестве дешевых серверов, которые могут быть значительно удалены друг от друга. По сегодняшним меркам GFS имеет достаточно простой дизайн: множество серверов хранят данные в чанках размером в 64 Мб, каждый чанк имеет уникальный идентификатор, этот идентификатор вместе с адресом чанка хранится на одном из мастер-серверов, к которому обращается клиент за определенным файлом. Для производительности данные клиенту возвращаются напрямую с чанк-серверов, а для сохранности данных используется избыточность, то есть хранение одних и тех же чанков на трех и более серверах.
В рамках проекта Colossus в 2008 году файловая система была модифицирована с учетом потребностей современного мира: высокая скорость доступа к информации, увеличение количества единиц информации с уменьшением размера каждой из них (твит, пост в Facebook и так далее). GFS 2.0 получила распределенную систему мастер-серверов, по которым с дублированием размазаны все метаданные, теперь она хранит данные в чанках размером 1 Мб и имеет переработанную систему очередей, ориентированную не столько на эффективное использование канала, сколько на скорость отдачи данных.
Поверх GFS работает BigTable и MapReduce. Первая представляет собой своего рода NoSQL базу данных, основное достоинство которой в превосходной масштабируемости и вместимости данных (речь идет о петабайтах). Вторая — это алгоритм распределенной обработки данных, который в Google используется для многих задач, включая извлечение данных из BigTable.
В свое время MapReduce стал настоящим открытием в сфере распределенных систем, так как впервые предлагал такой механизм обработки данных, в котором вся задача от начала и до конца могла быть распараллелена. Там, где другие алгоритмы полагались на параллельные вычисления только частично, разбивая задачу на множество небольших подзадач, результаты которых затем так или иначе приходилось приводить к общему результату на одном сервере, MapReduce позволял эффективно распараллелить всю задачу, и ее результат в уже практически готовом виде возвращался обратно.
В 2006-м, спустя два года после обнародования Google подробностей реализации MapReduce, был опубликован исходный текст открытого клона GFS и MapReduce под названием Apache Hadoop. Его взяли на вооружение Last.fm, Facebook, The New York Times, eBay и тысячи других компаний, а в 2008 году Hadoop установил мировой рекорд производительности сортировки данных, обработав 1 Тб на кластере из 910 узлов за 309 секунд.

Хакер #180. 2014: люди, вирусы, баги, релизы
Presto, или MapReduce от Facebook
Facebook довольно быстро взял на вооружение Hadoop как эффективное средство для выполнения разного рода аналитических запросов, требующих обработки больших объемов данных (основная логика работы осталась основанной на традиционной модели распределенных баз данных), но снабдила его обвеской, известной теперь под именем Apache Hive. Последняя, в частности, позволила писать запросы на специальном диалекте SQL, который затем преобразовывался в распараллеленную MapReduce-задачу.
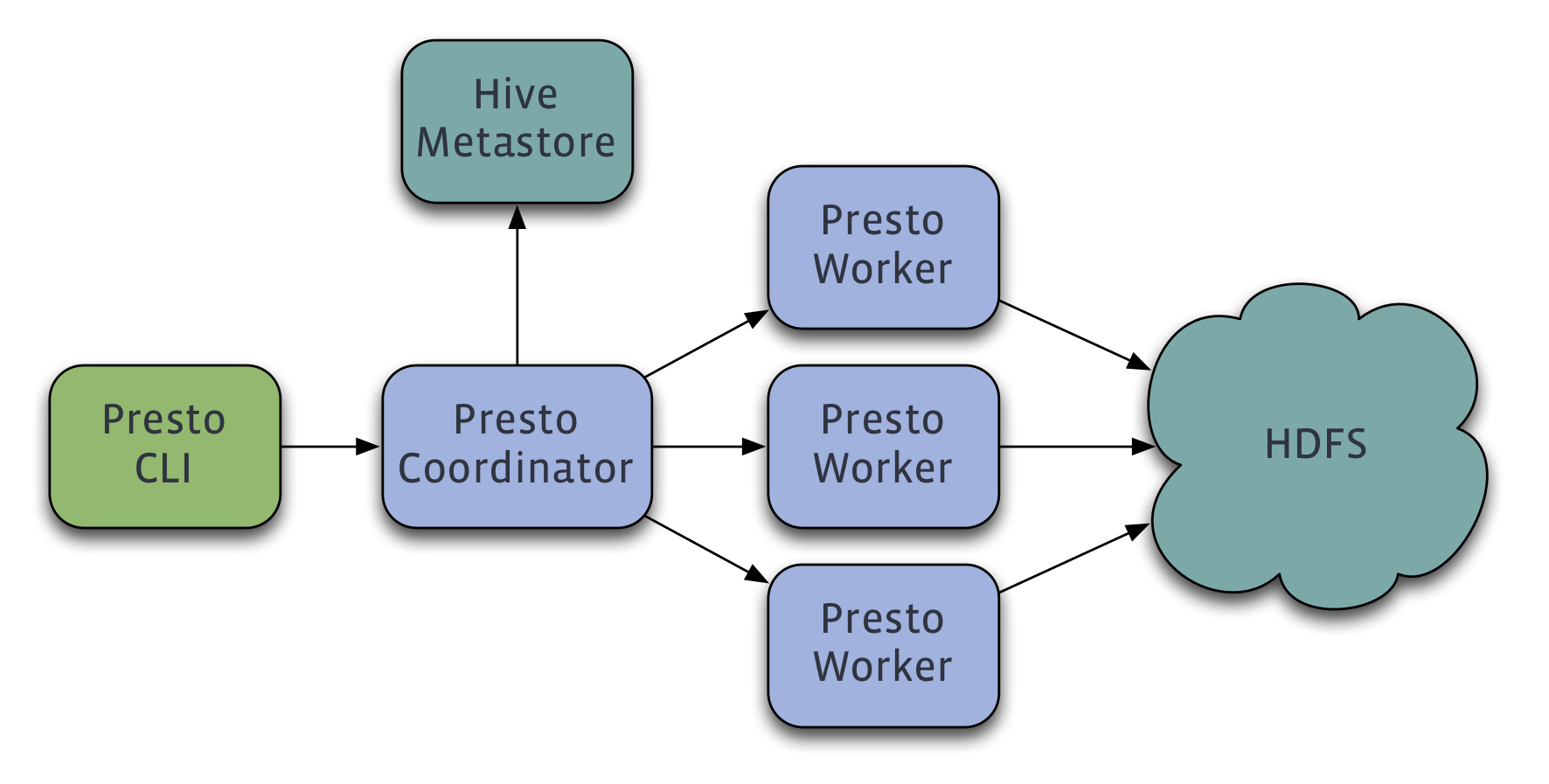
Некоторое время такая связка вполне успешно работала, но из-за неэффективности преобразования SQL в MapReduce-задачи и общих проблем архитектуры ее производительность стала недостаточной, и программисты Facebook начали решать вопрос о замене Hive на более быструю альтернативу. Так появился проект Presto, исходники которого были открыты в конце 2013 года.
По сути, Presto — это распределенный движок SQL-запросов, который разбивает один запрос на множество более мелких, и каждый из низ выполняется параллельно отдельным рабочим потоком в отношении собственного участка данных из БД. Presto не использует MapReduce и не привязан к какой-либо базе данных, но задействует в своей работе компоненты Hive. По словам разработчиков Facebook, производительность движка получилась в десять раз выше по сравнению с Hive/MapReduce, что позволило справиться с быстрой обработкой стремительно растущего количества данных, общий объем которых уже перевалил за 300 Пб.
Apache Cassandra
Кроме идей MapReduce и Google Filesystem в лице Hadoop, Facebook также взял на вооружение идею базы данных BigTable, реализовав ее в виде открытого продукта, который теперь носит имя Apache Cassandra. Как и BigTable и HBase, входящий в состав Hadoop, это распределенная NoSQL база данных с очень высокой степенью масштабируемости и возможностью практически неограниченного роста.
Cassandra основана на полностью распределенной hash-системе Dynamo и задействует разработанную Google модель хранения данных на базе семейства столбцов (ColumnFamily, вложенные хеши). Для хранения данных используется файловая система HDFS (клон GFS) из состава того же Hadoop, а для обеспечения надежности — все тот же гугловский принцип избыточности, при котором данные автоматически реплицируются на несколько узлов, равномерно распределяясь по всему кластеру. Этот же подход служит и для повышения доступности данных: благодаря наличию копий данных на многих узлах нескольких кластеров и дата-центров клиент может получать информацию с географически наиболее близкого узла.
Главное достоинство Cassandra, а также ее собратьев BigTable и HBase — в линейном росте масштабируемости. По сути, это означает, что для базы данных безразлично количество узлов-участников и она одинаково хорошо работает как на двух серверах, так и на тысяче. При этом система переконфигурируется в полностью автоматическом режиме и автоматически подхватывает новые узлы. В качестве языка запросов в Cassandra используется CQL (Cassandra Query Language), своего рода сильно урезанный и упрощенный SQL, не позволяющий выполнять сложные запросы, включающие в себя сортировку и другие постобработки.
В 2009 году код Cassandra был передан фонду Apache и сегодня используется для обслуживания баз данных в таких компаниях, как Adobe, CERN, Cisco, IBM, HP, Comcast, Disney, eBay, Netflix, Sony, Rackspace, Reddit, Digg и Twitter.
PHP в стиле HipHop
Еще одна интересная разработка Facebook — это HipHop, транслятор исходного текста PHP в C++. Транслятор был открыт еще в начале 2010 года и уже тогда использовался для оптимизации почти всех PHP-файлов, выполняющих 90% запросов пользователей.
HipHop появился как ответ на возрастающие нагрузки, с которыми стало все труднее справляться без постоянной закупки дополнительных серверов и усложнения инфраструктуры сервиса. Традиционно с самых первых версий Facebook был основан на PHP и MySQL, что в будущем создало для компании массу проблем с расширяемостью и производительностью. Поскольку выпилить PHP уже не представлялось возможным, возникла идея сделать так, чтобы все можно было переписать на C++ в автоматическом режиме.
Работа над HipHop продолжалась полтора года, за это время программисты смогли переписать почти всю среду исполнения PHP и создать транслятор, способный перевести в C++ почти любой PHP-код за исключением нескольких конструкций, таких как eval(). Как результат, общую нагрузку на CPU удалось снизить примерно на 50% (позже на 70%) и достичь существенной экономии оперативной памяти.
После публикации первой версии HipHop программисты продолжили эксперименты и уже через два года выкатили виртуальную машину Hhvm, которая вместо перевода PHP в представление на C++ исполняет оптимизированный байт-код PHP с использованием JIT. Причиной ее создания послужили технические ограничения, накладываемые на PHP-скрипты, пригодные для транслирования в C++, а также особенности языка, такие как динамическая типизация, которая не позволяет создать эффективный код на основе статического анализа.
Написанный скрипт пропускался через компилятор, сначала транслирующий его в промежуточное абстрактное представление AST (Abstract Syntax Tree), а затем в байт-код HHBC (HipHop bytecode). Байт-код HHBC, в свою очередь, запускался в виртуальной машине в режиме интерпретации либо динамической трансляции в машинные инструкции с помощью JIT-компилятора.
В целом виртуальная машина не смогла вывести скорость исполнения PHP выше уровня первой реализации HipHop, но зато заметно упростила разработку скриптов, которые теперь не нужно модифицировать для получения возможности трансляции в C++. Общее же следствие применения HipHop — возможность снизить затраты на оборудование на 70%.
Memcached и Redis
Любой крупный веб-сервис для повышения производительности так или иначе использует один из способов кеширования данных. Зачастую для выполнения этой задачи служатMemcached и Redis, которые хранят наиболее часто используемые данные в оперативной памяти. Это позволяет избежать лишних и долгих обращений к базе данных и отдавать клиенту ответ настолько быстро, насколько это вообще возможно.
Наиболее известный кеширующий сервер на данный момент — это Memcached, разработанный более десяти лет назад для LiveJournal. Сегодня он используется в большей части высоконагруженных веб-сервисов. По своей сути это довольно простое распределенное хранилище данных (не решусь называть его БД), позволяющее временно сохранять в оперативной памяти множество пар ключ — значение, которые клиент в лице веб-сервиса может в любой момент добавлять и извлекать в обход обращения к базе данных.
Memcached имеет очень простой API, состоящий только из базовых операций вроде установки соединения, добавления, обновления и удаления данных. Поэтому клиент должен сам заботиться о поддерживании кеша в актуальном состоянии, что обычно выливается в работу по принципу «смотрим значение в кеше, если такого нет — обращаемся к базе данных, а при добавлении данных в БД дополнительно помещаем их в Memcached». Сильная сторона такой архитектуры в нулевых простоях сервиса, так как падение или замена Memcached-сервера будет считаться промахом мимо кеша, а сам сервис продолжит свою работу без всяких проблем.
В 2009 году у Memcached появилась серьезная альтернатива под названием Redis. По сути, это все тот же Memcached, но обладающий несколькими важными отличиями. Одно из основных — это возможность хранить не только строки, но и такие типы данных, как массивы, словари, множества и битмапы. Это существенно расширяет область применения кеширования.
Вторая особенность — это поддержка репликации данных на соседние серверы, благодаря чему Redis более масштабируем и устойчив к сбоям, чем Memcached. Размазывание разных данных по многим серверам выполняется так же, как и в Memcached, — на основе значения хеша, которое клиент использует для выбора нужного сервера. Более высокая устойчивость к сбоям также достигается за счет возможности создания снапшотов кеша на диске, который можно восстановить в любой момент.
Ну и последнее: Redis — однопоточный сервер, использующий для работы epoll и kqueue, что делает его более быстрым и масштабируемым в рамках одной машины. Согласно тестам производительности, Redis опережает Memcached не менее чем на 20%. С другой стороны, они оба настолько быстры, что в условиях удешевления серверов это уже не имеет никакого значения.

Varnish
Еще один распространенный способ кеширования данных — это использование HTTP-акселератора Varnish. Обычно он работает как внешний или промежуточный (между Apache и nginx, например) веб-сервер, который кеширует все запрашиваемые страницы, позволяя ускорить отдачу страниц. На динамических веб-сайтах он обычно не используется, но, если сайт достаточно статичный (скажем, СМИ или страница компании), его применение может дать ощутимый прирост скорости отдачи веб-страниц.
Varnish — это прокси-сервер, который, в отличие от Squid и других, изначально создан с целью работы в качестве HTTP-акселератора. По этой причине Varnish имеет более простой дизайн, ограниченную поддержку протоколов (без FTP, SMTP), поддержку балансировки нагрузки (round-robin и случайный выбор) и очень развитый язык написания конфигураций VCL (Varnish Configuration Language), который позволяет тонко настроить прокси под нужды любого веб-сайта.
Как Memcached и Redis, Varnish в основном полагается на хранения кеша в оперативной памяти и в идеале устанавливается на выделенную машину. В условиях небольшого объема RAM он может временно сбрасывать кеш на диск, причем делает это не самостоятельно, а полностью полагается на операционную систему. Так удается избежать оверхеда, который может произойти, когда ОС и приложение начинают одновременно сбрасывать страницы памяти на диск. В целях снижения оверхеда Varnish также хранит логи в оперативной памяти, для их записи на диск используется отдельный поток.
Nginx
Nginx, благодаря своей архитектуре, способен обрабатывать огромное количество запросов, что сделало его очень популярным решением для балансировки загрузки и отдачи статических данных, таких как изображения и JS-скрипты. Обычно nginx выступает в роли фронтенда, который получает запрос от клиента, а затем отдает его одному из бэкенд-серверов либо одной из машин с установленным Varnish, она, в свою очередь, либо возвращает кешированную страницу клиенту, либо обращается для этого к одному из бэкенд-серверов.
В плане балансировки нагрузки возможности nginx достаточно стандартны. По умолчанию используется алгоритм round-robin с возможностью назначения приоритета каждому серверу. Поддерживаются бэкап-серверы, которые будут использованы в случае, если один или несколько основных недоступны. Проверка на доступность также настраивается, есть возможность выбора количества проверок и тайм-аута между ними. Чтобы клиенты всегда работали через один сервер (на котором может быть кеш, актуальный именно для этого клиента), имеется поддержка IP-хешей, на основе которых определяется сервер назначения.
Обычно всего этого вполне хватает, чтобы настроить эффективную систему балансировки нагрузки.
INFO
- Автор Varnish — Пол-Хеннинг Камп (Poul-Henning Kamp), легендарный FreeBSD-хакер, известный как автор Jail, подсистемы ввода-вывода GEOM и части файловой системы UFS2.
- Google File System выросла из проекта BigFiles, авторами которого были Ларри Пейдж и Сергей Брин.
- Идеи BigTable были использованы также в базах данных MongoDB и CouchDB.
Выводы
Все описанные в статье системы (кроме гугловских) абсолютно бесплатны, имеют открытый исходный текст и при достаточном умении могут быть использованы для создания масштабируемых систем, выдерживающих огромные нагрузки. Вопрос лишь в том, стоит ли платить за специализированный софт.







