Содержание статьи
Уже более 13 лет сетевые соединения Linux систем защищает iptables. К сожалению, по мере развития этот пакетный фильтр обрастал серьезными проблемами на функциональном уровне и в дизайне. Взвесив все за и против, разработчики решили отказаться от метода костылей и создали новый файер, имя которому nftables.
Чем не устраивает iptables?
Проект netfilter/iptables был основан в 1998 году и с версии ядра 2.4 используется по умолчанию. Команда разработчиков сохранила основную идею, заложенную еще в ipfwadm, — список правил, состоящих из критериев и действия, которое выполняется, если пакет соответствует критериям. Netfilter разрешал подключать дополнительные модули (ранее архитектура ядра такой возможности не предоставляла). Это позволило очень просто развивать подсистему фильтрации, и со временем появилось большое количество новых функций и модулей. Полноценная поддержка IPv6 появилась только в 2011 году, что, правда, потребовало редизайна netfilter. В результате модуль NAT разделили на два независимых компонента, один из которых включает в себя ядро подсистемы NAT, а второй реализует поддержку протокола третьего уровня. Помимо фильтрации, модули обеспечивают классификацию трафика (вплоть до седьмого уровня OSI), балансировку нагрузки, манипуляцию с пакетами, маршрутизацию и прочее.
Со временем накапливались проблемы на функциональном уровне и в дизайне. Код ядра дублировался, становилось все сложнее его поддерживать и добавлять новые возможности. Обработка некоторых параметров жестко вшита в ядро, модуль нередко обслуживает только свой протокол. Например, за извлечение номера порта UDP и TCP отвечают два разных модуля. Для реализации любой функции в userspace требуется поддержка модулем ядра, это затрудняет разработку, и без пересборки часто не обойтись. Правила загружаются как один большой дамп, в случае изменения правила выгружаются, меняются, и весь набор отправляется обратно. Без учета дополнительных расширений количество опций конфигурирования в ядре уже давно перевалило за сотню.

Хакер #180. 2014: люди, вирусы, баги, релизы
Еще один важный мотив — необходимость сбросить текущий ABI (Application Binary Interface), представляющий собор набор соглашений между программами, библиотеками и ОС, обеспечивающими их взаимодействие на низком уровне. В iptables ABI жестко прописаны специфические для протоколов поля, поэтому расширить его сложно. Как результат, приходится сразу запускать iptables, arptables и ebtables, по существу выполняющие одну работу, но каждый на своем уровне. По общим оценкам дублируется 10 000 строк кода. Учитывая, что все защитные механизмы и цепочки (даже пустые) грузятся изначально и активны, iptables потребляет больше ресурсов, чем реально необходимо.
Пользователям и администраторам управлять большим количеством правил довольно тяжело, трудно с ходу разобраться, что делают все цепочки, правила начинают повторяться, их становится сложно обслуживать и обновлять. Чтобы настроить два разных действия (вроде MARK и ACCEPT), правила приходится дублировать. Каждое расширение имеет свой синтаксис, одни поддерживают диапазоны, отрицание, префиксы, другие — нет.
Журналирование в nftables
Для регистрации событий используется Netfilter, при помощи модулей xt_LOG (регистрирует в syslog) и/или nfnetlink_log. Последний использует демон сбора информации ulogd2, вышедший примерно полтора года назад и способный накапливать данные на уровне отдельных пакетов или потоков и сохранять их, в том числе и в БД.
Механизм журналирования для каждого протокола настраивается через /proc.
# cat /proc/net/netfilter/nf_log
0 NONE (nfnetlink_log)
1 NONE (nfnetlink_log)
2 ipt_LOG (nfnetlink_log,ipt_LOG)
Под номером 2 у нас скрывается IPv4. Меняем на nfnetlink_log:
# echo "nfnetlink_log" >/proc/sys/net/netfilter/nf_log/2
Назначение nftables
Об nftables впервые заговорили в октябре 2008 года на конференции Netfilter Workshop. Задача проекта — заменить подсистемы iptables, ip6table, arptables и ebtables одним решением. Разработкой новой подсистемы пакетной фильтрации стала заниматься та же команда, только под руководством Патрика Мак-Харди (Patrick McHardy). Альфа-версия была представлена в марте 2009 года, хотя до 2012 года проект практически спал.
Дерево патчей состояло из более 100 патчей, которые в конце октября 2013-го были объединены в 17. В стандартную ветку Linux nftables включен с версии 3.13, хотя высокоуровневые инструменты все еще находятся в разработке, а документация, ориентированная на пользователя, отсутствует. Старая и новая подсистемы будут некоторое время сосуществовать рядом, так как nftables еще требует доработки и тестирования. Для обеспечения обратной совместимости предоставляется специальная прослойка, позволяющая использовать iptables/ip6tables поверх инфраструктуры nftables.
В nftables реализована идея, схожая с BPF (Berkeley Packet Filters): правила фильтрации в пространстве пользователя компилируются в байт-код, а затем через Netlink API передаются в ядро. После этого для принятия решения по дальнейшим действиям с пакетом они выполняются с использованием так называемого конечного автомата (pseudo-state machine), который представляет собой простейшую виртуальную машину, выполняющую байт-код.
Виртуальная машина способна манипулировать наборами данных (как правило, IP-адреса), позволяя заменить несколько операций сравнения единым набором поиска. Для принятия решений на основе этих данных могут быть использованы арифметика, битовые операторы и операторы сравнения. Возможен и обратный процесс декомпиляции объектов, позволяющий воссоздать текущую конфигурацию в ядре.
Использование userspace значительно упрощает код ядра и позволяет гораздо проще анализировать и принимать решения по отдельным протоколам. Отсутствует дублирование кода, особенности каждого протокола уже не встраиваются.
Все операции по определению условий и связанных с ними действий выполняются в пространстве пользователя, в ядре производится только базовый набор операций, таких как чтение данных из пакета, сравнение данных. Присутствует поддержка словарного маппинга и поиск по наборам правил (sets), работа которых реализована через хеши и rb-деревья. При этом элементы наборов могут быть заданы в виде диапазонов значений (можно определять подсети).
В качестве базовых блоков по-прежнему используются компоненты netfilter, в том числе существующие хуки, система отслеживания состояния соединений, компоненты организации очередей и подсистема ведения лога. Хотя работа в userspace позволяет получать больше отчетов об ошибках.
Отличается и алгоритм работы фильтра, он сделан более универсальным, теперь разборкой пакета занимаются операторы (expression). Специальный механизм payload expression загружает данные из пакета в один из регистров общего назначения. Базовое смещение, специфичное для протокола, берется из структуры nft_pktinfo и модулей netfilter (IPv4, ARP и так далее). То есть уже нельзя сказать: «сравни IP источника с IP 192.168.0.1», — теперь фильтр «знает», что нужно извлечь определенную часть заголовка, помещает ее в переменную и затем сравнивает с нужным адресом. Обработка пакета несколькими правилами за счет введения так называемого verdict register стала значительно проще. Также легко пропустить ненужные операции, вроде счетчиков, если в них нет необходимости, меньше ресурсов требует поиск и сопоставление с диапазоном.
В итоге простое правило iptables в памяти занимает 112 байта, аналогичное nftables — 24 байта. Проверка пинга "-d 192.168.0.1 -p icmp –icmp-type echo-request" — 152 и 96 байт соответственно.
Улучшенный API позволяет производить инкрементные обновления правил или атомарную замену правила, гарантирующие эффективность и согласованность, без выгрузки/загрузки всего набора в пределах одной транзакции Netlink.
Для взаимодействия kernel <-> userspace nftables API использует особый компонент ядра Netlink, позволяющий через обычный сокет передавать и принимать сообщения, сформированные особым образом. При этом сам Netlink позволяет:
- получать уведомления об изменении сетевых интерфейсов, таблиц маршрутизации и состоянии пакетного фильтра;
- управлять параметрами сетевых интерфейсов, таблицами маршрутизации и параметрами netfilter;
- управлять ARP-таблицей;
- взаимодействовать со своим модулем в ядре.
Именно через Netlink работает утилита iproute2, пришедшая на смену ifconfig и route.
Собственно взаимодействие с кодом, работающим на уровне ядра, возложено на интерфейсные библиотеки libmnl (Netlink), libnftables (userspace Netlink API) и построенный поверх фронтенд, работающий на уровне пользователя. Для формирования правил фильтрации в nftables подготовлена утилита nft, которая проверяет корректность правил и транслирует их в байт-код. Утилита iptables-nftable позволяет использовать правила iptables.
Правила
Конечно, писать низкоуровневые правила пользователи не будут, доступен понятный язык описания. Новый синтаксис правил непохож на iptables, главное отличие — использование иерархических блочных структур вместо линейной схемы. Группировка позволяет легко составлять, читать и понимать настройки без особых пояснений. Синтаксис при этом чем-то напоминает ipfw из FreeBSD.
Язык классификации правил основан на реальной грамматике, при обработке которой используется парсер bison. К сожалению, документация в этом вопросе мало помогает, она просто еще не готова. О возможностях можно судить только по исходному коду nftables и обрывкам информации в специализированных мейл-листах.
Правила могут содержать:
- таблицы — контейнеры для одного семейства протоколов, поддержка мультипротокола не реализована в netfilter, хотя в будущем, вероятно, что-то изменится;
- цепочки (chains) — контейнеры для правил, могут использоваться в действии перехода (jump), но в отличие от iptables цепи не содержат счетчики;
- базовые цепочки (base chains) — особый тип цепи, регистрируются с хуками netfilter, обеспечивая отправную точку для таблиц. Регистрируются при вставке первого правила;
- правила (rules) — атомарная единица, содержащая expressions.
Сами правила выглядят следующим образом. Разрешаем ping (ICMP-сообщения echo-request):
nft add rule filter input icmp type echo-request accept
Теперь разрешаем доступ с подсети 192.168.1.0/24 и IP 192.168.0.10 по SSH, блокируем для всех доступ по 80-му порту и разрешаем все пакеты уже установленного соединения (connection tracking).
nft add rule ip global filter ip daddr {192.168.1.0/24, 192.168.0.10} tcp dport {22} accept
nft add rule ip filter input tcp dport 80 drop
nft insert rule filter input ct state established accept
Счетчики — необязательный элемент в правилах, и, если он нужен, его необходимо активировать. Теперь в одном правиле можно указать сразу несколько действий. Например, подсчитаем количество пакетов, отправленных на 192.168.0.1, и заблокируем соединение:
nft add rule ip filter output ip daddr 192.168.0.1 counter drop
Вместо IP в правилах возможно использование доменного имени:
nft add rule ip6 filter output ip daddr example.org accept
Фильтр интерфейса позволяет указывать правило для конкретного сетевого интерфейса (сетевуха должна присутствовать в системе, иначе правило не будет активным):
nft insert rule filter input meta iif eth0 accept
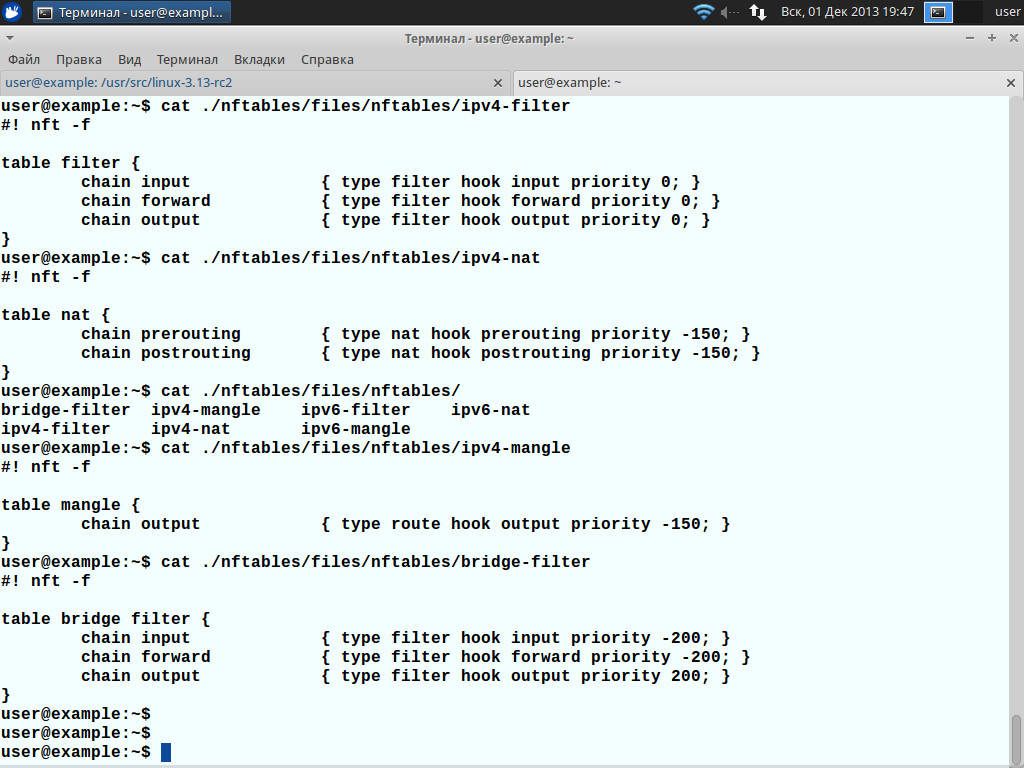
Еще один нюанс. Утилита nft может работать в трех режимах, чем-то напоминая управление в Cisco. Например, все настройки можно указать в файле и затем просто скормить конфиг nft, это очень удобно для переноса рулесетов на несколько ПК. В каталоге files/nftables с исходными текстами уже имеется ряд шаблонов, перед началом использования nftables необходимо выбрать нужные и активировать:
# nft -f files/nftables/ipv4-filter
# nft -f files/nftables/ipv6-filter
Также есть режим командной строки, когда нужная настройка указывается сразу, и интерактивный режим CLI. Перейти в CLI просто:
# nft -i
Теперь можем последовательно давать команды или считывать настройки. Единичные правила группируются в таблице, образуя иерархическую блочную структуру, напоминающую pf и npf.
nft> list table filter -n -a
table filter {
chain output {
table filter hook output priority 0;
ip protocol tcp counter packets 190 bytes 21908
ip daddr 192.168.1.100 drop
}
}
Правило можно вставить в нужную позицию (handle), здесь работают две директивы — add и insert. Первая добавляет правило после указанной позиции, а вторая — перед. Например, чтобы вставить правило перед handle 8, пишем:
nft insert rule filter output position 8 ip daddr 127.0.0.1 drop
Удаляются правила в цепочке при помощи параметра delete:
nft delete rule filter output handle 9
Если не указывать номер правила, то будет очищена вся цепочка. При помощи flush сбрасывается вся таблица:
nft flush table filter
Настройка NAT не сложнее, вначале необходимо загрузить модули:
modprobe nft_nat
modprobe nft_chain_nat_ipv4
modprobe nft_chain_nat_ipv6
Создаем цепочку:
nft add table nat
nft add chain nat post \{ type nat hook postrouting priority 0 \; \}
nft add chain nat pre \{ type nat hook prerouting priority 0 \; \}
И добавляем в нее правила:
nft add rule nat post ip saddr 192.168.1.0/24 meta oif eth0 snat 192.168.1.1
nft add rule nat pre udp dport 53 ip saddr 192.168.1.0/24 dnat 8.8.8.8:53
Первое активирует NAT для всего трафика с 192.168.1.0/24 на интерфейсе eth0, второе перенаправляет весь DNS-трафик на 8.8.8.8.
Установка nftables в Ubuntu
На данный момент единственный выход изучить новинку — это установить nftables самостоятельно. Нам потребуются библиотеки и стандартный набор для сборки ПО:
$ sudo apt-get install autoconf2.13 dh-autoreconf libmnl-dev libmnl0
Библиотеку можно поставить из сырцов, но пока версии, доступной в репозитории, вполне достаточно. Копируем код libnftables и nftables.
$ git clone git://git.netfilter.org/libnftables
$ git clone git://git.netfilter.org/nftables
Сборка в том и другом случае стандартна, переходим в каталог и даем команды:
$ ./autogen.sh
$ ./configure
$ make
$ sudo make install
В некоторых системах (в Ubuntu, например) при конфигурировании nftables следует активировать ряд функций:
$ ac_cv_func_malloc_0_nonnull=yes ac_cv_func_realloc_0_nonnull=yes ./configure
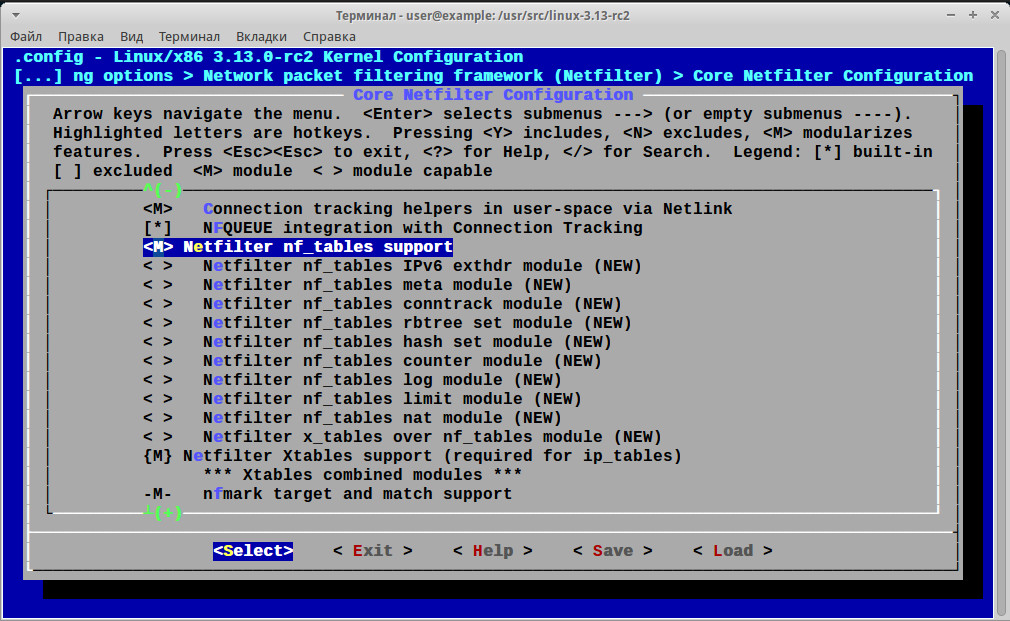
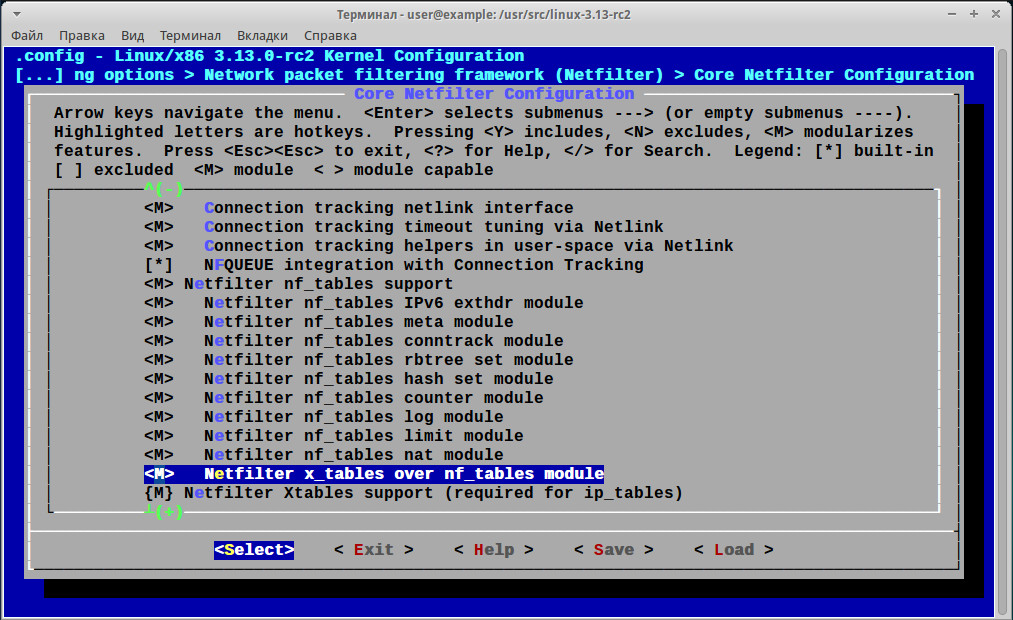
Далее вводим make oldconfig, переходим в Core Netfilter Configuration, где находим специфичные для nftables настройки (их, кстати, на порядок меньше, чем для iptables), собираем ядро.
Пакетный фильтр FF
Джефри Мерки (Jeffrey Merkey) представил в списке рассылки разработчиков ядра Linux код нового специализированного пакетного фильтра FF, предназначенного для блокирования большого числа IP-адресов в сетях с интенсивным трафиком. FF состоит из модуля Linux-ядра и утилиты для управления пакетным фильтром. Представленный пакетный фильтр не отличается такой гибкостью, как iptables, но опережает последний по производительности и потребляет значительно меньше памяти в расчете на один IP.
От ipset новая система отличается тем, что поддерживает блокирование на уровне драйвера e1000. Набор утилит, работающий на уровне пользователя, обеспечивает сохранение БД-адресов на диске с кешированием базы в памяти ядра.
Главная задача FF — защита от DoS/DDoS-атак, блокирование различного флуда и паразитного трафика. В качестве примера представлен код для интеграции разработки с Postfix с целью борьбы с роботами спамеров, выступающий в роли более жесткой системы блокирования для серых списков и RBL-систем.
INFO
До появления iptables для обеспечения возможностей межсетевого экрана в Linux использовались проекты ipchains в Linux 2.2 и ipfwadm в Linux 2.0 (основанный на ipfw из BSD).
Заключение
Пока поддержка nftables не заявлена ни в одном дистрибутиве Linux, хотя это скорее вопрос времени, а учитывая число установок, обе системы еще долго будут сосуществовать рядом. За iptables — большое количество готовых правил, на все случаи, nftables выигрывает более простым дизайном, скоростью работы и понятными правилами.