Содержание статьи
Если есть готовые решения, нет смысла изобретать костыли и велосипеды. С особым цинизмом это утверждение доказали авторы криптолокера, который для своих целей пользовался CryptoAPI :). Справедливо оно и для решения нашей сегодняшней задачи — расшифровки капчи (с образовательными целями, разумеется). Вперед, запускаем Visual Studio!
Вступление
Весь процесс предстоящей работы можно условно поделить на несколько этапов:
- скачать картинки;
- убрать шумы и другие искусственные искажения;
- выделить области связанности (символы), сохранить их;
- обучить нейросеть или создать словарь;
- распознать.
В этом нам помогут:
- AForgeNet — библиотеки компьютерного зрения и искусственного интеллекта;
- Tesseract — программа для распознавания текстов;
- Fanndotnetwrapper — обертка .NET нейросети FANN;
- алгоритм поиска связанности CCLA от Omar Gameel Salem.
Исходник на dvd.xakep.ru
Не забудь скачать сабж, он пригодится тебе при прочтении этой статьи. Никакой малвари, никакого экстремизма — только чистая наука, только OCR-технологии, только хардкор!
Подготовительный этап
Запускаем Visual Studio и создаем новый оконный проект на языке C#. Откроем его в проводнике, для того чтобы скопировать туда требуемые файлы.
Начнем с www.aforgenet.com, заходим на сайт и скачиваем архив «AForge.NET Framework-2.2.5-(libs only).zip» по ссылке [Download Libraries Only]. Из него нам понадобятся только следующие библиотеки: AForge.dll, AForge.Imaging.dll, AForge.Imaging.Formats.dll и AForge.Math.dll, другие же можно удалить.
Далее идем на github.com/charlesw/tesseract читать инструкцию по установке Tesseract NuGet Package и языковым дата-файлам. Выяснили, что есть два пути установки пакета NuGet: через консоль или GUI. Проще всего второй вариант, для этого в Visual Studio нашего проекта переходим на вкладку «Сервис -> Диспетчер пакетов NuGet -> Управление пакетами NuGet для решения...». В открывшемся окне переходим на раздел «В сети -> nuget.org», в строке поиска пишем tesseract, и нужный нам пакет «A .Net wrapper for tesseract-ocr» будет первым и единственным в списке. Нажимаем «Установить» и ждем пару секунд, все произойдет автоматически — создадутся новые папки с требуемыми файлами и настройками в проекте. Замечу, что действует этот NuGet Packege только для текущего решения и ничего другого не затронет. В результате мы сможем использовать этот мощный инструмент путем добавления using Tesseract в нужный класс. Остались только готовые языковые пакеты (если таковые потребуются), они находятся тут. Берем только файлы версии 3.02! Копировать их следует в папку «Наш проект\bin\Debug\tessdata», например, у меня тут находятся eng.traineddata, equ.traineddata и другие.
Затем из ресурса code.google.com/p/fanndotnetwrapper/ достаем нейросеть в виде Fann.Net.dll и fanndoubleMT.dll. Кладем их рядом с библиотеками AForgeNet в папке самого проекта.
Последний ингредиент — CCLA лежит тут. Нажимаем «Download ZIP» и в скачанном архиве находим папку ConnectedComponentLabeling, откуда забираем весь проект, или в своем создаем новый класс и копируем в него содержимое из IConnectedComponentLabeling.cs, CCL.cs, Label.cs и Pixel.cs. Когда их код полностью окажется внутри одного класса (с небольшим допилом), ошибок возникать не должно.
Все готово? Тогда последнее. Устанавливаем ссылки на библиотеки AForgeNet и нейросети FANN (References -> Добавить ссылку) для текущего проекта, проверяем, чтобы студия не ругалась на ошибки. Накидываем кнопки, текстбоксы и другие чудеса интерфейса в Form1 на свой вкус, то же самое делаем и с Form2, показанной на картинках.
Да, небольшое дополнение: возможно, что в App.Config тебе придется добавить строку startup useLegacyV2RuntimeActivationPolicy="true", чтобы все это заработало на .NET выше второй версии.
Шаг первый. Скачать captcha
Открывай исходник, который можно взять на dvd.xakep.ru. Открыл? Отлично, он нам понадобится, поскольку в этой статье мы не будем публиковать километры кода, уделив больше времени его пояснению.
Итак, на первом этапе нам нужно в автоматическом режиме заполучить требуемое количество образцов. Создадим метод загрузки картинок в папку на рабочем столе с автоматическим нумерованием файлов и поддержкой прокси. Количество обработанных запросов будем выводить в прогрессбар через event.
Чтобы наша форма не подвисла, создадим новый поток Thread downloadImagesThread. И да, все потоки в этом приложении имеют атрибут IsBackground = true. Если пользователь производит загрузку картинок не в первый раз, то сначала проверяем наличие папки для сохранения картинок и их количество, чтобы нумеровать их далее в правильном порядке. Метод, который выполняет всю работу, имеет сигнатуру void DownloadRemoteImageFile(string getUrl, int num, ArrayList proxy, int timeout), где getUrl — адрес картинки; num — количество запросов к ней. Внутри него цикл for по числу num, а номер итерации передается событию if (NewEvent != null) NewEvent(i + 1), которое ловит наш основной класс и присваивает результат прогрессбару progressBar1.Invoke(new Action(() => { progressBar1.Value = indeX; })), расположенному внизу главного окна. Само сохранение картинки производится стандартно.
Шаг второй. Обработать изображение
Хакер #184. Современный фронтенд
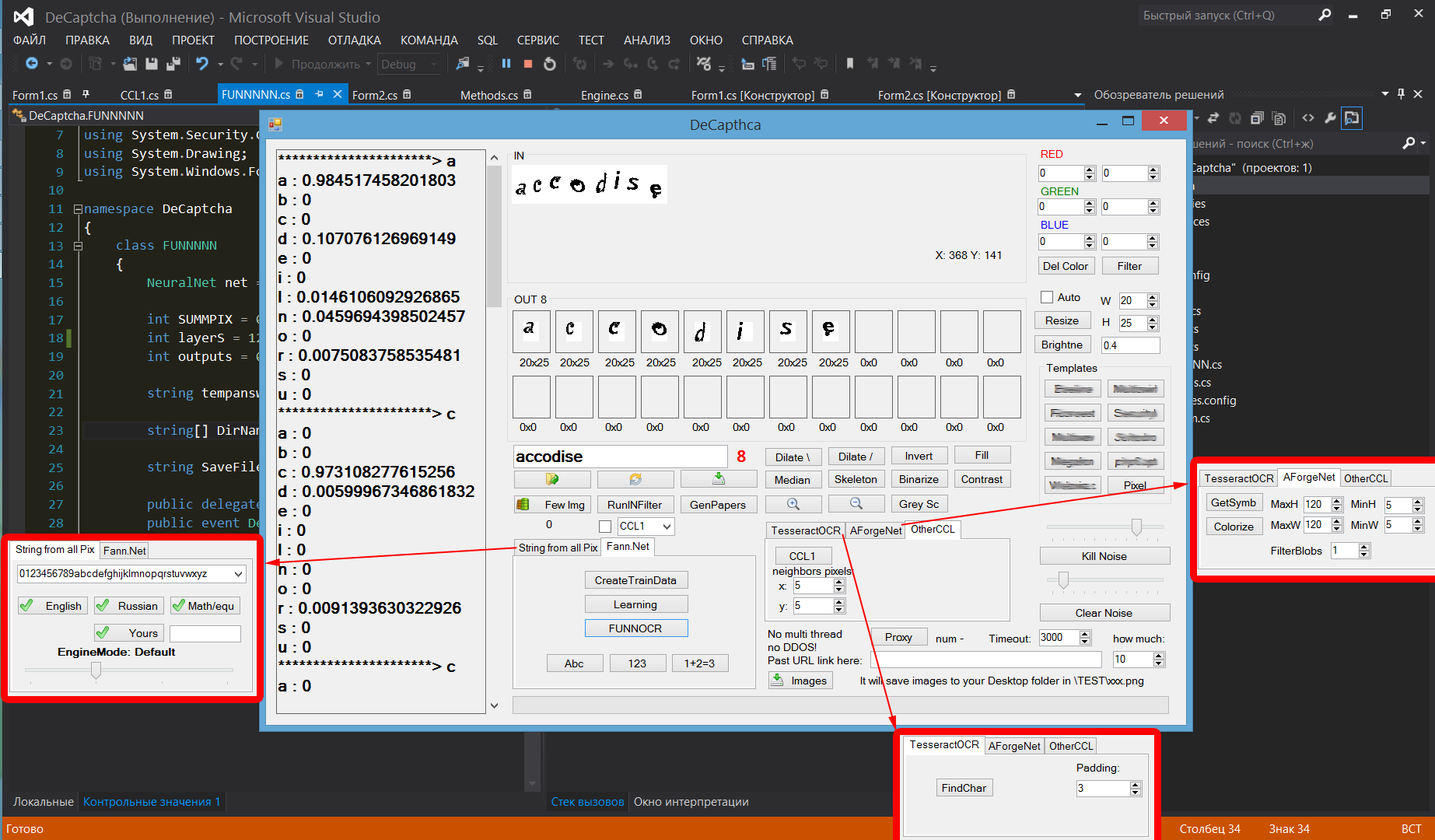
Самый сложный этап, он индивидуален для каждого вида captcha. Мне очень нравятся библиотеки AForgenet, которые очень удобно и эффективно помогают реализовать некоторые фильтры (ColorFiltering, Dilatation, ConservativeSmoothing, CannyEdgeDetector и так далее), большинство кнопок на форме как раз используют этот функционал. Также присутствует возможность указать цвет кликом мыши на нужном участке картинки, сделано это через событие MouseDown на picturebox и передачей координат на картинку для извлечения цвета в pixelColor.
Шаг третий. Выделить символы
Здесь используются три готовых решения, расположенные в нижней правой части главной формы, в элементе Tabs. Первый — это Tesseract OCR с возможностью задания размера отступа для найденных символов. Второй — AForge.net, который принимает параметры максимум и минимум высоты и ширины объектов, которые надо выделить, плюс фильтрация. И третий, он же самый сильный, — OtherCCL принимает два параметра, задающих расстояние между пикселями, которые будут считаться соседями (одним символом). В случае если найденные символы слились, то есть пиксели в них расположены вплотную, надо обрабатывать это событие отдельно. Задать размер, который считается нормальным, и при его превышении разделить слившиеся точки в месте самого слабого соприкосновения и повторить проверку заново. Данная надстройка не была реализована, рассматриваемая мной captcha редко выдавала такой финт.
- Tesseract использует Tesseract.Page page = OCRtesseractengine302.Process(img), далее на этой странице применяется using (var iter = page.GetIterator()). Находим для каждого if (iter.TryGetBoundingBox(PageIteratorLevel.Symbol, out symbolBounds)) значение bool и присваиваем Pix p = iter.GetImage(PageIteratorLevel.Symbol, paddinglevel, out c, out v) уже сам символ, если выражение вернуло true.
- AForgeNet — поиск связанных частей для пользователя реализован проще, создаем BlobCounter bc = new BlobCounter(), затем даем ему картинку Engine.bc.ProcessImage(image) и на выходе ловим прямоугольники Rectangle[] rects = Engine.bc.GetObjectsRectangles(), которые в цикле foreach вырезаем через Crop crop = new AForge.Imaging.Filters.Crop(new Rectangle(rect.Location, rect.Size)) и сохраняем в массив картинок.
- CCL1 ищет соседние пиксели в GetNeighboringLabels(Pixel pix), который циклами for (int i = pix.Position.Y - yYy; i <= pix.Position.Y + yYy && i < _height - yYy; i++) и for (int j = pix.Position.X - xXx; j <= pix.Position.X + xXx && j < _width - xXx; j++) проверяет условие if (i > -1 && j > -1 && _board[j, i] != 0) и в случае true выполняет neighboringLabels.Add(_board[j, i]).
Шаг четвертый. Сохранить символы
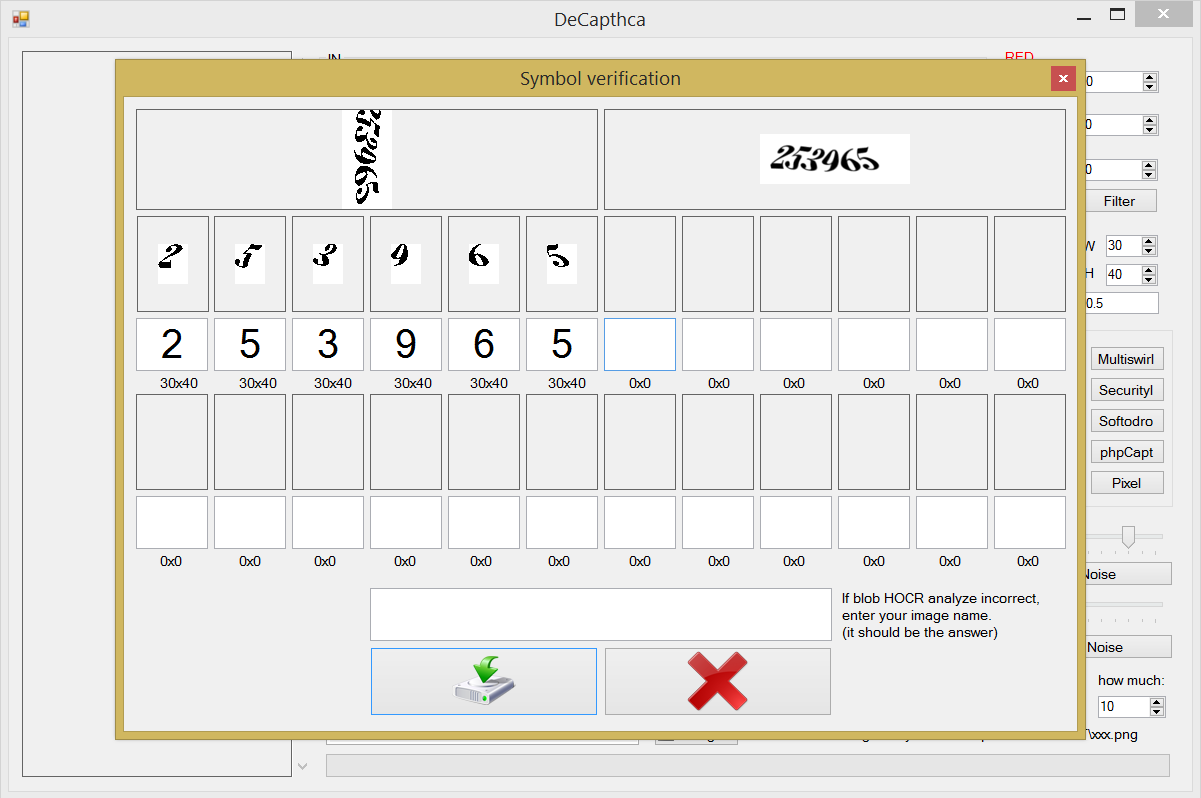
Удобство и лень! Кнопка RunINFilter открывает вторую форму, фильтры в которой применяются уже в автоматическом режиме. Их надо настроить заранее под каждый вид captcha отдельно. Задача формы — применить фильтры, разделить символы, сохранить указанные пользователем или автоматически найденные (Tesseract) связи «буква — картинка» в отдельную одноименную папку. Это означает, что в конце проделанной работы база данных для обучения создается автоматически и может быть использована как для Tesseract, так и для FANN. Но с одним условием: для нейросети все картинки должны быть одного размера, что в данной программе считается тоже одним из фильтров (Resize) и задается в правой части главного окна W/H. И не оставляй много пустого пространства на картинках, это собьет FANN с толку. Допустим, у нас есть 1000 картинок и на некоторых из них много пустого белого цвета; нейросеть будет считать, что это часть буквы, и все другие картинки, где тоже много белого цвета по краям, будут приравниваться к ней. Получим неправильный результат, и все придется начинать заново. Понятно, что буквы бывают разного размера, и, например, а по сравнению с f или даже W оставит белый участок сверху или снизу. Но никто не запрещает приводить их к одному размеру, заведомо искажать/сжимать для себя (а точнее, для нейросети).
Сохранение реализовано циклом по 24 элементам массива картинок, и если содержимое не равно null, то получаем textbox.text под этим элементом и сравниваем с пустой строкой. Если строка не пустая, то проверяем, существует ли папка с таким именем, помещая в него эту картинку. Когда строка пустая или содержит более одного символа, результат сохраняется в папку Garbage. Саму captcha с именем, совпадающим с правильным вводом текста, сохраняем в Images, для последующей возможности автоматизации проверки на процент корректного распознавания. Весь прогресс также отображается на progressBar1.
Шаг пятый. Обучение
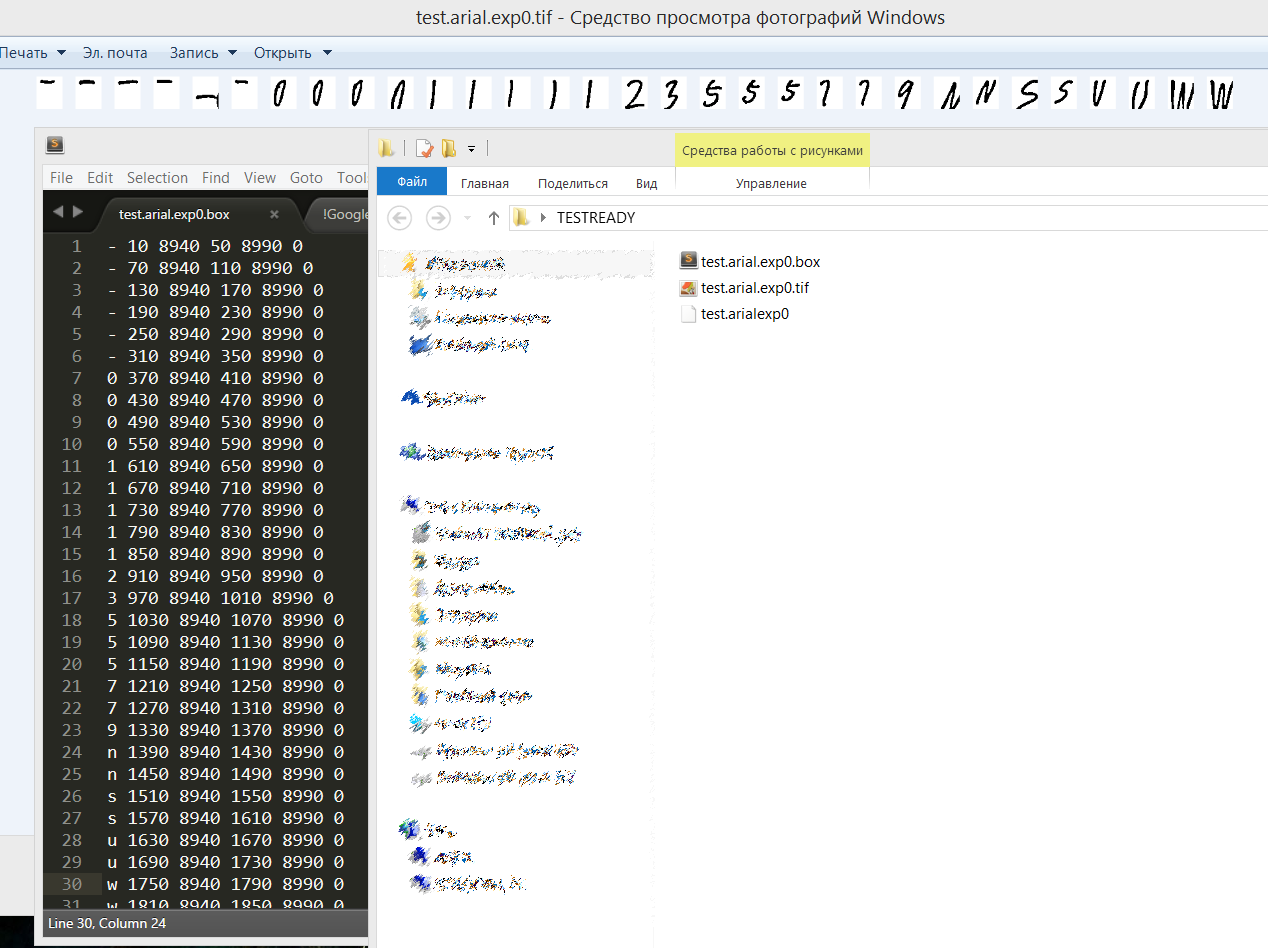
Начнем с Tesseract, для его обучения требуется создать три файла test.arial.exp0.box, test.arial.exp0.tif, test.arial.exp0, где test — имя словаря; arial — имя шрифта; exp0 — номер файла; box — это текстовый файл, где указаны координаты каждого символа, tif — картинка, третий является копией первого. Для их создания предназначена кнопка GenPapers, которая использует следующий код:
List<GenPapers> genpaperlist = new List<GenPapers> { };
GenPapers tempgenpaper = new GenPapers();
string[] dirs = Directory.GetDirectories(Environment.GetEnvironmentVariable("userprofile") + "\\Desktop\\TESTDATA\\");
foreach (var item in dirs)
{
string bb = item.Substring(item.LastIndexOf(@"\") + 1);
if (bb == "Images" || bb == "Garbage") continue;
genpaperlist.Add(new GenPapers { dir = item.ToString(), files = Directory.GetFiles(item.ToString(), "*.png") });
}
for (int i = 0; i < genpaperlist.Count; i++)
{
tempgenpaper = (GenPapers)genpaperlist[i];
using (Graphics g = Graphics.FromImage(BIGbit))
{
foreach (var item in tempgenpaper.files)
{
... *Рисуем
}
}
}
...
public class GenPapers : List<string>
{
public String dir { get; set; }
public String[] files { get; set; }
}
Здесь используется класс GenPapers с двумя полями, первое — имя папки, второе — полный путь для всех картинок внутри этой папки. Далее производится поиск и наполнение объекта genpaperlist данными, после чего в цикле for начинаем работать с каждой директорией в отдельности, рисуя извлеченные данные на большом холсте и попутно записывая координаты для box-файла. Полученный результат требуется задать аргументами к установленному Tesseract в Program Files. Достаточно одного bat-файла, который проведет все действия в автоматическом режиме. Подробная инструкция по обучению находится по адресуcode.google.com/p/tesseract-ocr/wiki/TrainingTesseract3.
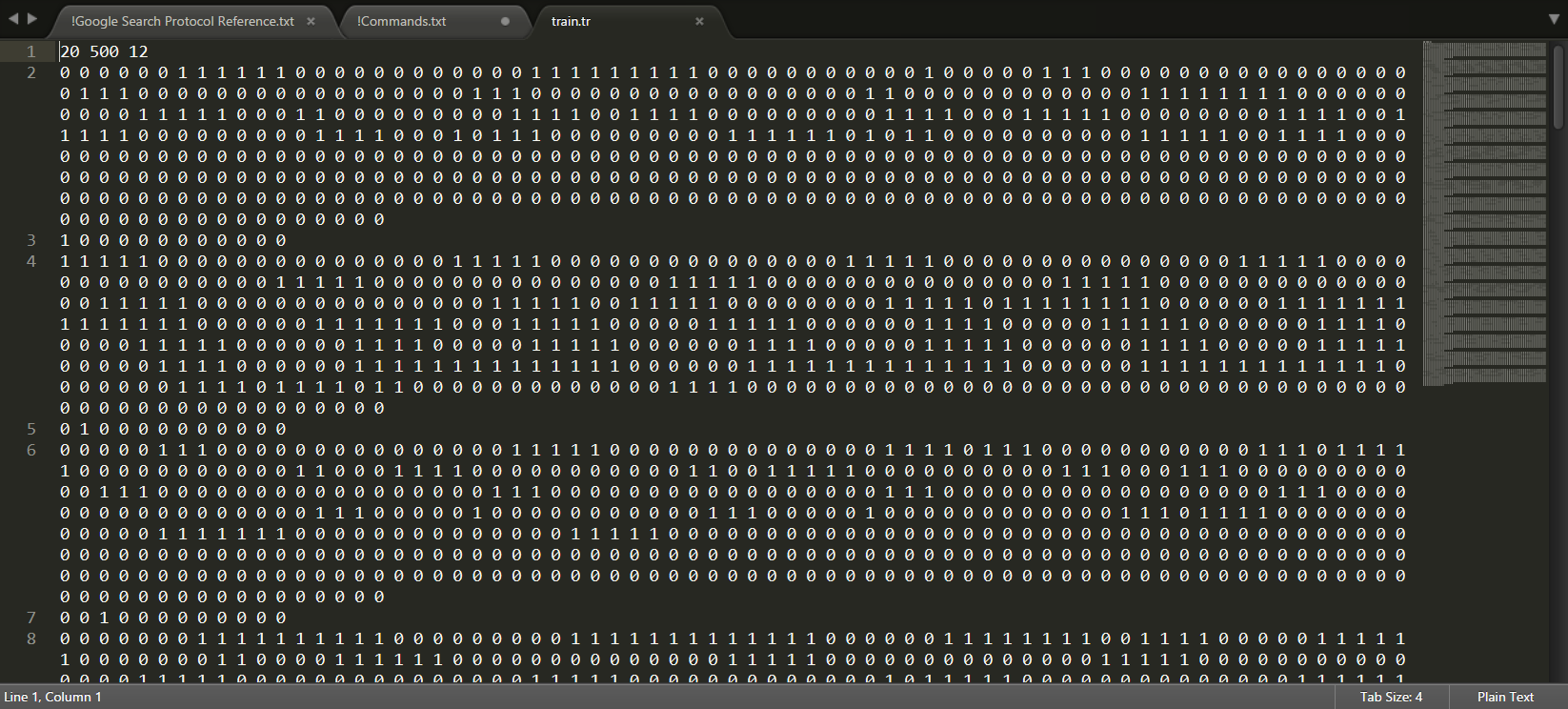
Для обучения нейросети FANN использована часть кода из Tesseract, отличие заключается в том, что мы создаем один текстовый файл train.tr, в котором первая строка — количество картинок, количество точек в каждой (ширина, умноженная на высоту) и количество выходов (букв, которые мы ищем). Сама картинка до всего этого проходит обязательную бинаризацию, для того чтобы выделить всего два состояния каждой точки (1 — черный, 0 — белый цвет), и сохраняется далее в этом же файле во всех следующих строках. Для удобства и возможности использовать разные заранее созданные обученные ann-файлы был создан дополнительный текстовый файл CONFIG.txt. Он состоит из одной строки и указывает количество точек и выходов с их значениями, случайно запустить проверку captcha на другом ann-файле не получится.
string a = File.ReadAllText(SaveFilesPath + "CONFIG.txt");
string[] b = a.Split(' ');
int SumPix = Convert.ToInt32(b[0]);
int Outpt = Convert.ToInt32(b[1].Length);
uint[] layers = { (uint)SumPix, (uint)layerS, (uint)Outpt };
net.CreateStandardArray(layers);
net.RandomizeWeights(-0.1, 0.1);
net.SetLearningRate(0.7f);
TrainingData data = new TrainingData();
data.ReadTrainFromFile(SaveFilesPath + "train.tr");
net.TrainOnData(data, 1000, 0, 0.001f);
net.Save(SaveFilesPath + "FANNLearning.ann");
Получаем конфиг, читаем параметры, число слоев (layers) по рекомендации Википедии задано равным 120, все остальное было выбрано случайным образом или подсмотрено в Сети. Скорость обучения зависит от мощности твоего железа и того, что написано выше. Например, i7-4702MQ при 6500 картинок одним ядром был занят минут 20–30.
Шаг шестой. Распознавание
В заключительном этапе реализовано два подхода, но используется тот, обучение которого было проведено. Tesseract 3.02 и FANN находятся в нижней левой части главного окна. Первый умеет искать по английскому (выбираем символы из выпадающего списка), русскому, Math и словарю пользователя. Поиск словаря происходит автоматически, и в подсказке tooltip высвечиваются все доступные. Второй распознает текст по кнопке FANNOCR и выводит в лог (левая часть окна) результат анализа для каждого выбранного символа. Очень удобно смотреть, почему нейронная сеть выбрала тот или иной выход. Рассмотрим, как это работает в случае нейронной сети.
private string OCR(Bitmap img)
{
...
{
int whx = img.Width * img.Height;
if (SUMMPIX != whx) { /* Выводим ошибку, не сошлось количество пикселей */}
double[] input = GetPix(img);
double[] result = net.Run(input);
if (tempanswer.Length != result.Length) { /* Выводим ошибку, разное количество выходов */}
int maxN = FindMax(result);
answer = Convert.ToString(tempanswer[maxN]);
if (ToLogEvent != null)
ToLogEvent(result, tempanswer, answer);
...
}
}
Получили картинку от public-метода, где реализован net.CreateFromFile(SaveFilesPath + "FANNLearning.ann") и чтение конфиг файла, tempanswer — это переменная, равная b[1], в ней перечислены буквы, которые мы ищем. Сравниваем число пикселей, записываем их в массив и прогоняем через обученный ann, выискивая максимально высокий процент совпадения, затем направляем результат в событие, выбрав один выход и получив букву, закрепленную за ним.
Обсуждаем результаты
Мои результаты тестирования сильно зависели от количества и качества картинок для обучения, а в случае с нейросетью FANN — и от количества выходов тоже. В среднем captcha, поддавшаяся фильтрам, имела ~80% правильного распознавания, тут многое зависит от усидчивости и желания — чему научишь, то и получишь. Главное — это работает.
Заключение
Все описанное в статье можно применить для решения многих других задач. Например, мне при поиске информации для статьи повстречался подробный разбор распознавания образа автомобиля на стоянке. Включай фантазию и Visual Studio! 🙂