

Содержание статьи
- WARNING!
- INFO
- Отключение изменения времени доступа к файлам и оптимизация для SSD-накопителей
- ZFS — дублирование файлов
- Отключение автомонтирования в ZFS
- Сжатие данных
- Автоматическое создание снапшотов в ZFS
- ZFS — комплексный пример
- Дефрагментация Btrfs
- RAID на Btrfs
- Снапшоты Btrfs
- NILFS2 — еще одна файловая система с поддержкой COW
- Facebook и Btrfs
В мире *nix-систем все более популярными становятся файловые системы ZFS и Btrfs. Популярность эта вполне заслуженна — в отличие от своих предшественников, они лишены некоторых проблем и имеют множество неоспоримых достоинств. А не так давно им присвоен статус стабильных. Все это и побудило написать данную статью.
WARNING!
Некоторые описываемые здесь команды способны необратимо уничтожить твои данные. Трижды проверяй введенное, прежде чем нажимать Enter.
Пожалуй, прежде чем перейти к практике, нужно дать некоторые пояснения, что собой представляют файловые системы нового поколения. Начну с ZFS. Эта ФС была разработана для Solaris и в настоящее время, поскольку Oracle закрыла исходный код, форкнута в версию OpenZFS. В дальнейшем под ZFS будет подразумеваться именно форк. Вот лишь некоторые из ключевых особенностей ZFS:
- огромный до невообразимости максимальный размер ФС;
- пулы хранения, которые позволяют объединять несколько разных устройств;
- контрольные суммы уровня файловой системы, при этом есть возможность выбирать алгоритм;
- основана на принципе COW — новые данные не перезаписывают старые, а размещаются в других блоках, что открывает такие возможности, как снапшоты и дедупликация данных;
- сжатие данных на лету — как и в случае с контрольными суммами, поддерживается несколько алгоритмов;
- возможность управлять файловой системой без перезагрузки.
Btrfs начала разрабатываться в пику ZFS компанией Oracle — еще до покупки Sun. Я не буду описывать ее особенности — они в ZFS и Btrfs, в общем-то, схожи. Отличия же от ZFS таковы:
- поддержка версий файлов (в терминологии Btrfs называемых поколениями) — есть возможность просмотреть список файлов, которые изменялись с момента создания снапшота;
- отсутствие поддержки zvol, виртуальных блочных устройств, на которых можно разместить, к примеру, раздел подкачки, — но данное отсутствие вполне компенсируется loopback-устройствами.
Далее будет описана как установка ZFSonLinux, так и некоторые интересные сценарии использования ZFS и Btrfs.
Знакомство с ZFSonLinux
Для установки ZFSonLinux потребуется 64-разрядный процессор (можно и 32, но разработчики не обещают стабильности работы в таком случае) и, соответственно, 64-разрядный дистрибутив с ядром не ниже 2.6.26 — я использовал Ubuntu 13.10. Памяти тоже должно быть достаточно — не менее 2 Гб. Предполагается, что основные пакеты, необходимые для сборки и компиляции модулей и ядра, уже установлены. Накатываем дополнительные пакеты и качаем нужные тарболлы:
$ sudo apt-get install alien zlib1g-dev uuid-dev libblkid-dev libselinux-dev parted lsscsi wget
$ mkdir zfs && cd $_
$ wget http://bit.ly/18CpniI
$ wget http://bit.ly/1cEzO0V
Распаковываем оба архива, но сперва собираем SPL — слой совместимости с Solaris, а уж затем собственно ZFS. Отмечу, что, поскольку мы ставим свежайшую версию ZFSonLinux, DKMS (механизм, позволяющий автоматически перестраивать текущие модули ядра с драйверами устройств после обновления версии ядра) недоступен, и в случае обновления ядра придется собирать пакеты заново вручную.
$ tar -xzf spl-0.6.2.tar.gz
$ tar -xzf zfs-0.6.2.tar.gz
$ cd spl-0.6.2
$ ./configure
$ make deb-utils deb-kmod
Прежде чем компилировать ZFS, нужно поставить хидеры, заодно поставим и остальные свежесобранные пакеты:
$ sudo dpkg -i *.deb
Наконец, собираем и ставим ZFS:
$ cd ../zfs-0.6.2
$ ./configure
$ make deb-utils deb-kmod
$ sudo dpkg -i *.deb
Установку ZFS можно считать завершенной.


Перенос корневой ФС на ZFS с шифрованием и созданием RAIDZ
Предположим, ты хочешь получить безопасную, зашифрованную, но в то же время отказоустойчивую файловую систему. В случае с классическими ФС старого поколения тебе пришлось бы выбирать между шифрованием и отказоустойчивостью, поскольку эти вещи несколько несовместимы. В ZFS, однако, существует возможность «склеить» их между собой. Современная проприетарная реализация этой ФС поддерживает шифрование. Открытая реализация с версией пула 28 это не поддерживает — но ничто не мешает с помощью cryptsetup создать том (или несколько томов) LUKS и уже поверх них разворачивать пул. Что до отказоустойчивости ZFS, поддерживается создание мультидисковых массивов. Технология эта называется RAIDZ. Различные ее варианты позволяют пережить отказ от одного до трех дисков, и она, в силу некоторых особенностей ZFS, свободна от одного из фундаментальных недостатков традиционных stripe + parity RAID-массивов — write hole (ситуация с RAID 5 / RAID 6, когда при активных операциях записи и отключении питания данные на дисках в итоге отличаются).
INFO
Шифрование замедляет работу с данными. Не стоит его использовать на старых компьютерах.
Конечно, проще всего, если у тебя не стоит никакой системы — в этом случае заморачиваться придется меньше. Но живем мы не в идеальном мире, поэтому расскажу о том, как перенести уже установленную систему без раздела /boot на массив RAIDZ поверх томов LUKS.
Перво-наперво нужно создать сам этот раздел — без него перенос будет невозможен, поскольку система банально не загрузится. Предположим для простоты, что на диске имеется единственный раздел с Ubuntu, а хотим мы создать RAIDZ первого уровня (аналог RAID 5, для него требуется минимум три устройства, RAIDZ же больших уровней в домашних условиях смысла делать я не вижу). Создаем с помощью предпочитаемого редактора разделов два раздела — один размером 256–512 Мб, где и будет размещен /boot, и еще один, с размером не меньше текущего корневого, причем последнюю процедуру повторяем на всех трех жестких дисках. Перечитаем таблицу разделов командой
# partprobe /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309
и создадим файловую систему (ext3) на разделе поменьше:
# mke2fs -j /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part2 -L boot
Разумеется, в твоем случае идентификаторы жестких дисков будут другими. Вслед за этим нужно зашифровать раздел, на котором будет находиться том LUKS, и повторить эту процедуру для всех остальных разделов, на которых в конечном счете будет находиться массив RAIDZ:
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part3
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB2fdd0cb1-d6302c80-part1
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB781404e0-0dba6250-part1
Чтобы не запутаться, рекомендую использовать один и тот же пароль. Но если твоя паранойя против — ничто не мешает использовать разные.
Подключаем зашифрованные тома:
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part3 crypto0
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB2fdd0cb1-d6302c80-part1 crypto1
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB781404e0-0dba6250-part1 crypto2
И создаем пул ZFS:
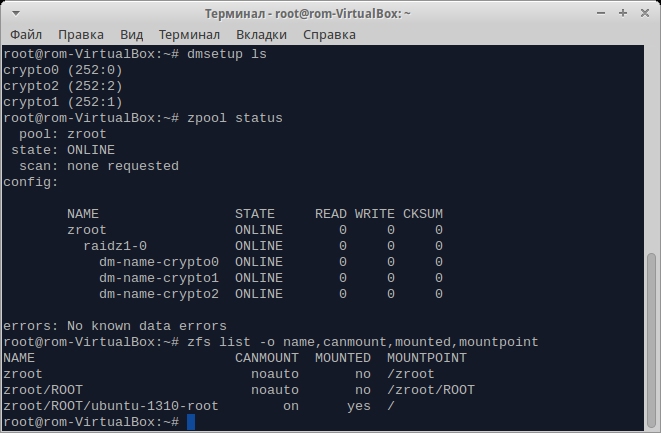
# zpool create -o ashift=12 zroot raidz dm-name-crypto0 dm-name-crypto1 dm-name-crypto2
Следом создаем две вложенные друг в друга файловые системы:
# zfs create zroot/ROOT
# zfs create zroot/ROOT/ubuntu-1310-root
Отмонтируем все файловые системы ZFS и устанавливаем некоторые свойства ФС и пула:
# zfs umount -a
# zfs set mountpoint=/ zroot/ROOT/ubuntu-1310-root
# zpool set bootfs=zroot/ROOT/ubuntu-1310-root zroot
Наконец, экспортируем пул:
# zpool export zroot
Перенос и конфигурация системы
Сначала копируем каталог /boot на нешифрованный раздел, чтобы следом установить туда загрузчик:
# mkdir /mnt/boot
# mount /dev/disk/by-label/boot /mnt/boot
# cp -r /boot/* /mnt/boot/
# umount /mnt/boot
После этого перенесем grub на отдельный раздел /boot, для чего добавим в /etc/fstab cтрочку
# <...>
LABEL=boot /boot ext3 errors=remount-ro 0 0
Монтируем и перегенерируем конфиг grub:
# grub-mkconfig -o /boot/grub/grub.cfg
Для проверки перезагружаемся. Если все нормально, удаляем старое содержимое каталога /boot, не забыв предварительно отмонтировать раздел.
Пришло время клонировать Ubuntu. Весь процесс клонирования описан в полной версии статьи, которую можно найти на сайте ][, здесь же затрону некоторые тонкости, относящиеся к ZFS. Для нормальной загрузки с пула ZFS нужны некоторые скрипты initramfs. К счастью, изобретать их не нужно — они лежат на GitHub. Скачиваем репозиторий (все действия производим в chroot):
# git clone http://bit.ly/1esoc8i
И копируем файлы в необходимые места. Я внес единственную правку: вместо пула rpool поставил zroot. Теперь нужно записать hostid в файл /etc/hostid. Это нужно сделать из-за того, что ZFS портирована с Solaris, и слой совместимости требует его наличия:
# hostid >/etc/hostid
Наконец, нужно сгенерировать initramfs. Ни в коем случае не используй update-initramfs. Он перезаписывает существующий файл, и, если возникнут трудности, загрузиться с нормальной системы будет проблематично. Вместо него используй команду
# mkinitramfs -o /boot/initrd.img-$(uname -r)-crypto-zfs
Раздел /boot должен быть подмонтирован.
Затем нужно добавить пункт меню в grub. По причине достаточно хитрой конфигурации (еще бы: три криптотома, поверх которых расположена не совсем типичная для Linux файловая система) в chroot это сделать не получилось, поэтому выходим из него в основную (пока еще) систему и добавляем примерно такие строчки:
# vi /etc/grub.d/40_custom
menuentry "Ubuntu crypto ZFS" {
# <...>
linux /vmlinuz-3.11.0-14-generic boot=zfs rpool=zroot
initrd /initrd.img-3.11.0-14-generic-crypto-zfs
}
Запускаем update-grub, перезагружаемся, выбираем новый пункт меню и радуемся.
Тюнинг ZFS и полезные трюки c Btrfs
В большинстве случаев домашние пользователи не настраивают свои ФС. Однако параметры по умолчанию ZFS отнюдь не всегда подходят для применения в домашних условиях. Существуют также довольно интересные возможности, использование которых требует определенных навыков работы с данной файловой системой. Далее я опишу как тонкую подстройку ZFS под домашние нужды, так и эти возможности.
В случае же использования Btrfs никаких особых проблем не наблюдается. Тем не менее какие-то тонкости все же имеют место — в особенности если есть желание не просто «поставить и забыть», а задействовать новые возможности. О некоторых из них я и расскажу ниже.
Отключение изменения времени доступа к файлам и оптимизация для SSD-накопителей
Как известно, в *nix-системах каждый раз при обращении к файлам время доступа к ним меняется. Это всякий раз провоцирует запись на носитель. Если ты работаешь одновременно с множеством файлов или у тебя SSD-накопитель, это может оказаться неприемлемым. В классических файловых системах для отключения записи atime нужно было добавить параметр noatime в опции команды mount или в /etc/fstab. В ZFS же для отключения используется следующая команда (конечно, в твоем случае ФС может быть другой):
# zfs set atime=off zroot/ROOT/ubuntu-1310-root
В Btrfs, помимо вышеупомянутой опции noatime, имеется опция ssd и более оптимизирующая ssd_spread. Первая из них начиная с ядра 2.6.31, как правило, устанавливается автоматически, вторая предназначена для дешевых SSD-накопителей (ускоряет их работу).
ZFS — дублирование файлов
При работе с очень важными данными порой возникает пугающая мысль, что отключат электроэнергию или выйдет из строя один из жестких дисков. Первое в российских условиях очень даже возможно, а второе хоть и маловероятно, но тоже случается. К счастью, разработчики ZFS, по-видимому, сталкивались с подобным не раз и добавили опцию дублирования данных. Файлы при этом, если возможно, размещаются на независимых дисках. Предположим, у тебя есть ФС zroot/HOME/home-1310. Для установки флага дублирования набери следующую команду:
# zfs set copies=2 zroot/HOME/home-1310
Более того, если двух копий покажется недостаточно, можно указать цифру 3. В этом случае выполняется тройное резервирование и, если откажут два жестких диска из трех, на которых лежат эти копии, ZFS все равно восстановит их.
Отключение автомонтирования в ZFS
При подключении пула по умолчанию автоматом монтируются все вложенные файловые системы. Это может вызвать некоторый конфуз, поскольку, например, в случае с приведенной выше конфигурацией пользователю не нужен доступ ни к zroot, ни к zroot/ROOT. Существует возможность отключить автомонтирование с помощью двух следующих команд (для данного случая):
# zfs set canmount=noauto zroot/ROOT
# zfs set canmount=noauto zroot
Сжатие данных
ZFS поддерживает также и сжатие данных. На шифрованных томах это имеет смысл разве что для увеличения энтропии (и то не факт), но вообще для медленных носителей сжатие позволяет повысить производительность и может достаточно ощутимо сэкономить место на диске. В то же время сейчас, когда емкость винчестеров уже измеряется терабайтами, экономить место вряд ли кому-то особо нужно, а на производительности и расходе оперативной памяти это сказывается больше. Если же тебе это нужно, включить его можно следующим образом:
# zfs set compression=on zroot/ROOT/var-log
В Btrfs для включения сжатия нужно поставить опцию compress в /etc/fstab.
Автоматическое создание снапшотов в ZFS
Как известно, ZFS позволяет создавать снапшоты. Ручками, однако, их создавать лениво, да и есть вероятность попросту забыть об этом. В Solaris для автоматизации этой процедуры имеется служба Time Slider, но она — вот незадача! — хоть и использует функции ZFS, в ее состав не входит, поэтому в ZFSonLinux ее нет. Но огорчаться не стоит: имеется скрипт для автоматического их создания и для Linux. Скачаем его и установим нужные права:
# wget -O /usr/local/sbin/zfs-auto-snapshot.sh http://bit.ly/1hqcw3r
# chmod +x /usr/local/sbin/zfs-auto-snapshot.sh
Изменим сперва префикс для снапшотов, поскольку по умолчанию он не особо «говорящий». Для этого изменим в скрипте параметр opt_prefix с zfs-auto-snap на snapshot. Затем установим некоторые переменные файловой системы:
# zfs set com.sun:auto-snapshot=true zroot/ROOT/ubuntu-1310-root
# zfs set snapdir=visible zroot/ROOT/ubuntu-1310-root
Первый параметр нужен для скрипта, второй же открывает прямой доступ к снапшотам, что тоже нужно для скрипта.
Теперь можно уже создавать скрипт для cron (/etc/cron.daily/autosnap). Рассмотрим случай, когда нужно создавать снапшоты каждый день и хранить их в течение месяца:
#!/bin/bash
ZFS_FILESYS="zroot/ROOT/ubuntu-1310-root"
/usr/local/sbin/zfs-auto-snapshot.sh --quiet --syslog --label=daily --keep=31 "$ZFS_FILESYS"
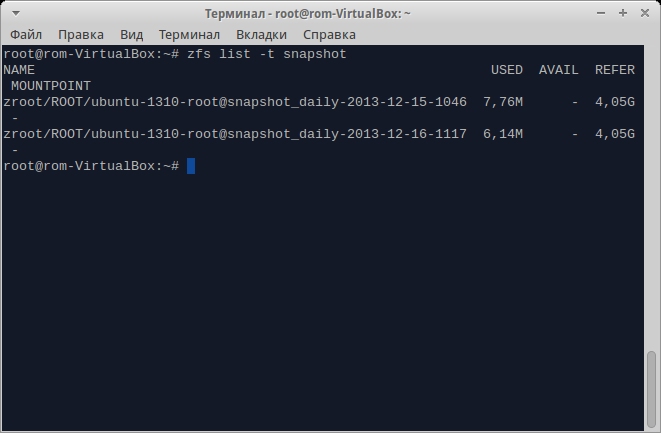
Для просмотра созданных снапшотов используй команду zfs list -t snapshot, а для восстановления состояния — zfs rollback имя_снапшота.
ZFS — комплексный пример
Ниже будут приведены команды, создающие несколько ФС в пуле для разных целей и демонстрирующие гибкость ZFS.
# zfs create -o compression=on -o mountpoint=/usr zroot/ROOT/usr
# zfs create -o compression=on -o setuid=off -o mountpoint=/usr/local /zroot/ROOT/usr-local
# zfs create -o compression=on -o exec=off -o setuid=off -o mountpoint=/var/crash zroot/ROOT/var-crash
# zfs create -o exec=off -o setuid=off -o mountpoint=/var/db zroot/ROOT/var-db
# zfs create -o compression=on -o exec=off -o setuid=off -o mountpoint=/var/log zroot/ROOT/var-log
# zfs create -o compression=gzip -o exec=off -o setuid=off -o mountpoint=/var/mail zroot/ROOT/var-mail
# zfs create -o exec=off -o setuid=off -o mountpoint=/var/run zroot/ROOT/var-run
# zfs create -o exec=off -o setuid=off -o copies=2 -o mountpoint=/home zroot/HOME/home
# zfs create -o exec=off -o setuid=off -o copies=3 -o mountpoint=/home/rom zroot/HOME/home-rom
Дефрагментация Btrfs
Дефрагментация в Btrfs не столь уж необходима, но в отдельных случаях позволяет освободить занятое пространство. Она может быть проведена только на смонтированной системе. Замечу, что доступ к данным во время дефрагментации сохраняется — как на чтение, так и на запись. Для запуска процедуры дефрагментации используй следующую команду:
# btrfs filesystem defrag /
На старых ядрах эта процедура удаляла все COW-копии, такие как снапшоты и дедуплицированные данные, так что, если ты их используешь на ядрах старше 2.6.37, дефрагментация тебе только навредит.
RAID на Btrfs
Как и в случае с ZFS, Btrfs поддерживает многотомные массивы, но в отличие от ZFS называются они классически. На данный момент, однако, поддерживаются только RAID 0, RAID 1 и их комбинация, RAID 5 по-прежнему на этапе альфа-тестирования. Для создания нового массива RAID 10 попросту используй такую команду (с твоими устройствами):
# mkfs.btrfs /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
Ну а если нужно сконвертировать существующую ФС в RAID, то и для этого есть команды:
# btrfs device add /dev/sdb1 /dev/sdc1 /dev/sdd1 /
# btrfs balance start -dconvert=raid10 -mconvert=raid10 /
Первая команда добавляет устройства к файловой системе, вторая же как раз и перебалансирует все данные и метаданные для преобразования этого набора томов в массив RAID 10.
Снапшоты Btrfs
Естественно, Btrfs поддерживает снапшоты — причем помимо обычных снапшотов доступны снапшоты с возможностью записи (более того, они и создаются по умолчанию). Для создания снапшотов используется следующая команда:
# btrfs subvol snap -r / /.snapshots/2013-12-16-17-41
Подробнее о создании снапшотов, как ручном, так и автоматическом, можно прочитать в статье «Подушка безопасности», опубликованной в апрельском номере ][ за 2013 год. Здесь же я расскажу, как при наличии снапшота отследить, какие файлы изменились с момента его создания. Для этого в Btrfs есть так называемое поколение файлов. Возможность эта используется для внутренних целей, но есть команда, позволяющая смотреть список последних изменений — ею и воспользуемся. Сначала узнаем текущее поколение файлов:
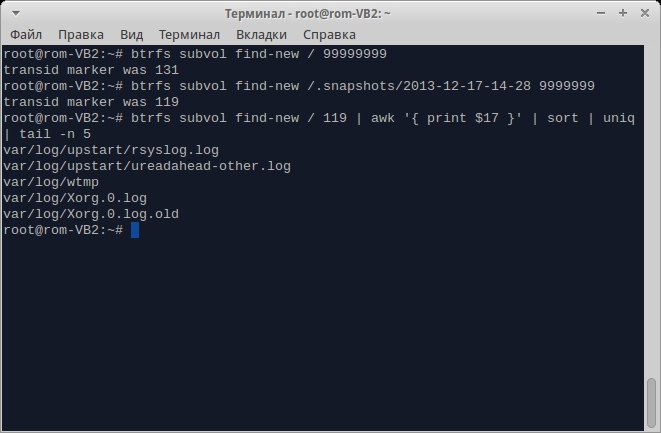
# btrfs subvol find-new / 99999999
Если такого поколения нет (в чем можно практически не сомневаться), выведется последнее. Теперь эту же самую команду выполним над снапшотом:
# btrfs subvol find-new /.snapshots/2013-12-17-14-28 99999999
Если поколения будут отличаться, а они будут, то смотрим, какие же файлы изменялись со времени создания снапшота. В моем случае команда была следующей:
# btrfs subvol find-new / 96 | awk '{ print $17 }' | sort | uniq
NILFS2 — еще одна файловая система с поддержкой COW
Начиная с ядра 2.6.30 в Linux появилась поддержка еще одной ФС — NILFS2. Аббревиатура эта расшифровывается как new implementation of a log-structured file system. Основная особенность данной ФС заключается в том, что раз в несколько секунд в ней автоматически создаются чек-пойнты — примерный аналог снапшотов с одним отличием: спустя какое-то время они удаляются сборщиком мусора. Пользователь, тем не менее, может преобразовать как чек-пойнт в снапшот, в результате чего для сборщика мусора он становится невидимым, так и наоборот. Таким образом, NILFS2 можно рассматривать как своеобразную «Википедию», где фиксируются любые изменения. Из-за этой особенности — писать любые новые данные не поверх существующих, а в новые блоки — она прекрасно подходит для SSD-накопителей, где, как известно, перезапись данных не приветствуется.
Да, NILFS2 не настолько известна, как ZFS или Btrfs. Но в некоторых случаях ее применение будет более оправданным.
Заключение
Может быть, я покажусь субъективным, но ZFS, если ее сравнивать с Btrfs, выигрывает. Во-первых, некоторые возможности Btrfs до сих пор находятся в зачаточном состоянии, несмотря на то, что ей уже более пяти лет. Во-вторых, ZFS, при прочих равных условиях, более обкатана. И в-третьих, как просто инструментов для работы с ZFS, так и ее возможностей больше.
С другой стороны, как бы ни была хороша ZFS, по лицензионным соображениям она вряд ли когда-нибудь будет включена в mainline kernel. Так что, если не появится какой-нибудь еще конкурент, придется пользоваться Btrfs.
Facebook и Btrfs
В ноябре 2013 года лидер команды разработчиков Btrfs Крис Мейсон перешел на работу в Facebook. Это же сделал и Джозеф Бацик, мейнтейнер ветки btrfs-next. Они вошли в состав отдела компании, специализирующегося на низкоуровневых разработках, где и занимаются ныне ядром Linux — в частности, работают над Btrfs. Разработчики заявили также, что Facebook заинтересована в развитии Btrfs, так что причин волноваться у сообщества нет решительно никаких.
Опубликовано в Хакере #181 (02.2014)











