Содержание статьи
- Как управлять ресурсами, доступными для контейнера (процессор, память)?
- Что такое линковка контейнеров и почему она хуже DNS discovery?
- Можно ли управлять Docker через веб-интерфейс?
- Я слышал, что вместо docker exec лучше использовать SSH. Почему?
- У меня сложная настройка с зависимостями между контейнерами, поэтому --restart мне не подходит
- Периодически некоторые мои контейнеры наполняются зомби-процессами. Почему так происходит?
- Почему, собирая образ с помощью Dockerfile, я получаю толстый слоеный пирог?
- Docker поддерживает различные механизмы сборки контейнера из слоев. В чем их различия?
- Расскажите подробнее про Docker Machine, Swarm и Compose
- Выводы
Мы узнали, что такое Docker, как он работает и какие преимущества может дать. Однако на пути использования этого мощного инструмента у тебя может возникнуть ряд вопросов, и ты столкнешься с трудностями, которые сложно решить без знания архитектурных деталей Docker. В этом FAQ мы попытались собрать ответы на наиболее частые вопросы и решения для самых серьезных проблем Docker.
Как управлять ресурсами, доступными для контейнера (процессор, память)?
В случае с памятью все просто — ты можешь указать максимальный объем памяти, который будет доступен контейнеру:
$ sudo docker run -d -m 256m ubuntu-nginx /usr/sbin/nginxС процессором все несколько сложнее. Docker полагается на механизм cgroups для ограничения ресурсов процессора, а он оперирует понятием веса, которое может быть от 1 до 1024. Чем выше вес группы процессов (в данном случае контейнера), тем больше шансов у нее получить процессорные ресурсы. Другими словами, если у тебя будет два контейнера с весом 1024 и один с весом 512, то первые два будут иметь в два раза больше шансов получить ресурсы процессора, чем последний. Это нечто вроде приоритета. Значение по умолчанию всегда 1024, для изменения используется опция -c:
$ sudo docker run -d -c 512 ubuntu-ssh /usr/sbin/sshd -DТакже доступна опция --cpuset, с помощью которой контейнер можно привязать к определенным ядрам процессора. Например, если указать --cpuset="0,1", то контейнеру будут доступны первые два ядра. Просмотреть статистику использования ресурсов можно с помощью команды docker stats:
$ sudo docker stats Имя/ID-контейнераЧто такое линковка контейнеров и почему она хуже DNS discovery?
Линковка контейнеров — это встроенный в Docker механизм, позволяющий пробрасывать информацию об IP-адресе и открытых портах одного контейнера в другой. На уровне командной строки это делается так:
$ sudo docker run -d --name www --link db:db www /usr/sbin/nginxДанная команда запускает контейнер www с веб-сервером nginx внутри и пробрасывает внутрь него инфу о контейнере с именем db. При этом происходит две вещи:
- В контейнере www появляется ряд переменных окружения, таких как DB_PORT_8080_TCP_ADDR=172.17.0.82, DB_PORT_8080_TCP_PORT=1234 и DB_PORT_8080_TCP_PROTO=tcp, по три на каждый открытый порт в контейнере db. Эти переменные можно использовать в файлах конфигурации и скриптах, чтобы связать контейнер www с db.
- Файл /etc/hosts контейнера www автоматически обновляется, и в него попадает информация об IP-адресе контейнера db (в данном примере строка 172.17.0.82 db). Это позволяет использовать хостнейм вместо айпишника для обращения к контейнеру db из контейнера www.
Казалось бы, это именно то, что нужно, и без всяких заморочек со SkyDNS. Но данный метод имеет ряд проблем. Первая: обновление записей в /etc/hosts происходит только один раз, а это значит, что, если после перезапуска контейнер db получит другой IP-шник, контейнер www его не увидит (возможно, когда ты читаешь эти строки, проблема уже исправлена). Вторая: хостнеймы видны только изнутри слинкованного контейнера (адресата), поэтому для доступа в обратную сторону, а также из хост-системы и тем более с другой машины все так же придется использовать IP-адреса. Третья: при большом количестве контейнеров и связей между ними настройка с помощью --link чревата ошибками и очень неудобна. Четвертая: линковка не имеет побочного эффекта в виде балансировки нагрузки.
Можно ли управлять Docker через веб-интерфейс?
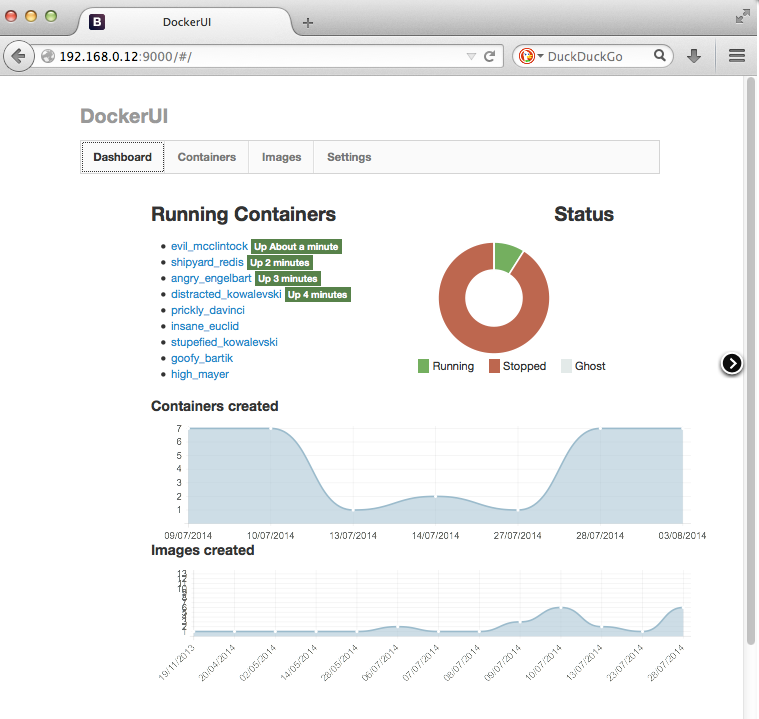
Официального GUI для Docker не существует. Однако можно найти несколько интересных проектов, решающих эту проблему. Первый — это DockerUI, очень простой веб-интерфейс, распространяемый в виде Docker-образа. Для установки и запуска выполняем такую команду:
$ sudo docker run -d -p 9000:9000 --privileged \
-v /var/run/docker.sock:/var/run/docker.sock dockerui/dockeruiСам интерфейс будет доступен по адресу http://IP-dockerd:9000. В случае необходимости подключиться к другому хосту с запущенным dockerd просто указываем его адрес:порт с помощью опции -e:
$ sudo docker run -d -p 9000:9000 --privileged \
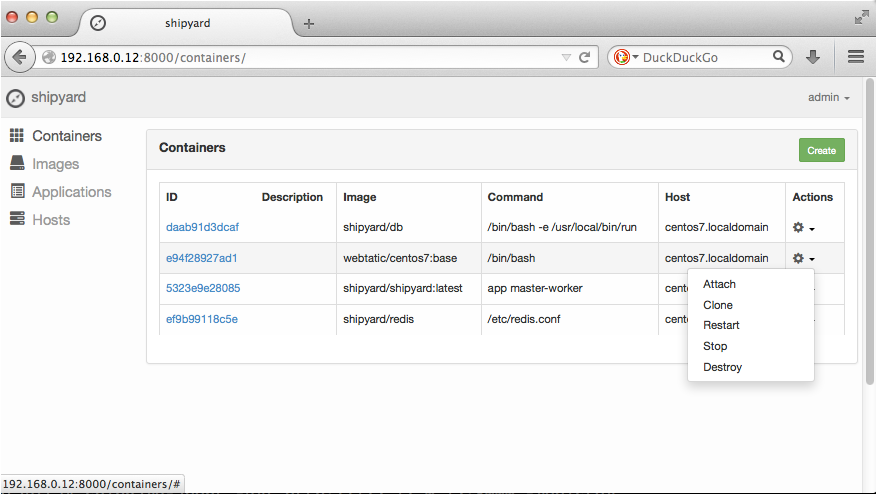
dockerui/dockerui -e http://127.0.0.1:2375Другой вариант — это Shipyard, включающий в себя такие функции, как аутентификация, поддержка кластеров и CLI. Основное назначение интерфейса — управление кластерами из множества Docker-хостов. Как и в предыдущем случае, установка очень проста:
$ sudo docker run -it -p 8080:8080 -d --name shipyard \
--link shipyard-rethinkdb:rethinkdb shipyard/shipyardВеб-интерфейс будет доступен на порту 8080, юзер admin, пароль shipyard.

Я слышал, что вместо docker exec лучше использовать SSH. Почему?
В небольших проектах docker exec вполне справляется со своей задачей и никакого смысла в использовании SSH нет. Однако SSH дает ряд преимуществ и решает некоторые проблемы docker exec:
- Во-первых, SSH не имеет проблемы «повисших процессов», когда по какой-то причине при выполнении docker exec клиент Docker убивается или падает, а запущенная им команда продолжает работать.
- Во-вторых, для выполнения команды внутри контейнера клиент Docker должен иметь права root, чего не требует клиент SSH. Это вопрос не столько удобства, сколько безопасности.
- В-третьих, в Docker нет системы разграничения прав на доступ к контейнерам. Если тебе понадобится дать кому-то доступ к одному из контейнеров с помощью docker exec, придется открывать полный доступ к docker-хосту.
INFO
Доступ к Docker можно получить из контейнера. Достаточно пробросить внутрь него UNIX-сокет:
$ sudo docker run -it -v /var/run/docker.sock:/var/run/docker.sock\
nathanleclaire/devboxУ меня сложная настройка с зависимостями между контейнерами, поэтому --restart мне не подходит
В этом случае следует использовать стандартную систему инициализации дистрибутива. В качестве примера возьмем сервис MySQL. Чтобы запустить его внутри Docker на этапе инициализации Red Hat, CentOS и любого другого основанного на systemd дистрибутива, нам потребуется следующий unit-файл (mysql меняем на имя нужного контейнера):
[Unit]
Description=MySQL container
Author=Me
After=docker.service
[Service]
Restart=always
ExecStart=/usr/bin/docker start -a mysql
ExecStop=/usr/bin/docker stop mysql
[Install]
WantedBy=local.targetКопируем его в каталог /etc/systemd/system/ под именем docker-mysql.service и активируем:
$ sudo systemctl enable docker-mysqlВ Ubuntu та же задача выполняется немного по-другому. Создаем файл /etc/init/docker-mysql.conf:
description "MySQL container"
author "Me"
start on filesystem and started docker
stop on runlevel [!2345]
respawn
script
/usr/bin/docker start -a mysql
end scriptА далее отдаем команду Upstart перечитать конфиги:
$ sudo initctl reload-configurationА теперь самое главное. Чтобы поставить другой сервис в зависимость от этого, просто создаем новый конфиг по аналогии и меняем строку After=docker.service на After=docker-mysql.service в первом случае или меняем строку start on filesystem and started docker на start on filesystem and started docker-mysql во втором.
Периодически некоторые мои контейнеры наполняются зомби-процессами. Почему так происходит?
Это одна из фундаментальных проблем Docker. В UNIX-системах в зомби превращается некорректно остановленный процесс, завершения которого до сих пор ждет родитель, — процесса уже нет, а ядро все равно продолжает хранить о нем данные. В нормальной ситуации зомби существуют недолго, так как сразу после их появления ядро пинает родителя (сигнал SIGCHLD) и тот разбирается с мертвым потомством. Однако в том случае, если родитель умирает раньше ребенка, попечительство над детьми переходит к первичному процессу (PID 1) и разбираться с зомби, в которых могут превратиться его подопечные, теперь его проблема.
В UNIX-системах первичный процесс — это демон init (или его аналог в лице Upstart или systemd), и он умеет разбираться с зомби корректно. Однако в Docker, с его философией «одно приложение на один контейнер» первичным процессом становится то самое «одно приложение». Если оно порождает процессы, которые сами порождают процессы, а затем умирают, попечительство над внуками переходит к главному процессу приложения, а оно с зомби (если они появятся) справляться совсем не умеет (в подавляющем большинстве случаев).
Решить означенную проблему можно разными способами, включая запуск внутри контейнера Upstart или systemd. Но это слишком большой оверхед и явное излишество, поэтому лучше воспользоваться образом phusion/baseimage (на основе последней Ubuntu), который включает в себя минималистичный демон my_init, решающий проблему зомби-процессов. Просто получаем образ из Docker Hub и используем его для формирования образов и запуска своих приложений:
$ sudo docker pull phusion/baseimage
$ sudo docker run -i -t phusion/baseimage:latest /sbin/my_init /bin/topКроме my_init, baseimage включает в себя также syslog-ng, cron, runit, SSH-сервер и фиксы apt-get для несовместимых с Docker приложений. Плюс поддержка скриптов инициализации, которые можно использовать для запуска своих сервисов. Просто пропиши нужные команды в скрипт и положи его в каталог /etc/my_init.d/ внутри контейнера.
Почему, собирая образ с помощью Dockerfile, я получаю толстый слоеный пирог?
Команда docker build собирает образ из инструкций Dockerfile не атомарно, а выполняя каждую команду по отдельности. Работает это так: сначала Docker читает команду FROM и берет указанный в ней образ за основу, затем читает следующую команду, запускает контейнер из образа, выполняет команду и делает commit, получая новый образ, затем читает следующую команду и делает то же самое по отношению к сохраненному в предыдущем шаге образу. Другими словами, каждая команда Dockerfile добавляет новый слой к существующему образу, поэтому стоит избегать длинных списков команд вроде таких:
RUN apt-get update
RUN apt-get upgrade
RUN apt-get install nginxА вместо этого писать все одной строкой:
RUN apt-get update &&\
apt-get upgrade &&\
apt-get install nginxНу и в целом не особо увлекаться составлением длинных Dockerfile. Кстати, в Docker есть лимит на количество слоев, и он равен 127. Это искусственное ограничение, введенное с целью не допустить деградации производительности при большом количестве слоев и не позволить админам использовать саму идею слоев не по назначению.
Docker поддерживает различные механизмы сборки контейнера из слоев. В чем их различия?
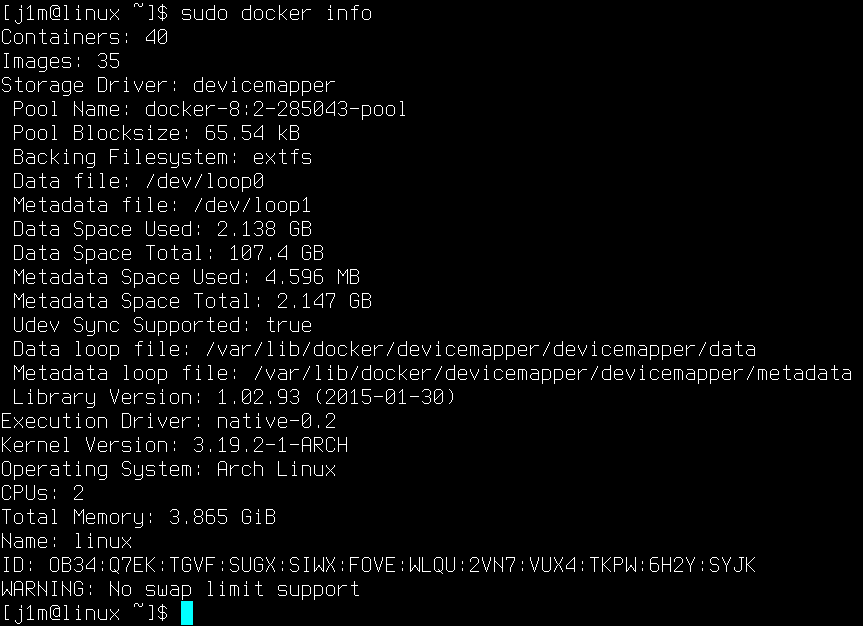
Текущая версия Docker (1.5.0) поддерживает пять различных механизмов для сборки файловой структуры контейнера из слоев: AUFS, Device Mapper, BTRFS, overlay и VFS. Посмотреть, какая технология используется в текущий момент, можно с помощью команды docker info, а выбрать нужную — с помощью флага -s при запуске демона. Различия между технологиями следующие:
- AUFS — технология, применявшаяся в Docker с первых дней существования проекта. Отличается простотой реализации и очень высокой скоростью работы, однако имеет некоторые проблемы с производительностью при открытии громоздких файлов на запись и работе в условиях большого количества слоев и каталогов. Огромный минус: из мейнстримовых дистрибутивов доступна только в ядрах Debian и Ubuntu.
- Device Mapper — комплексная подсистема ядра Linux для создания RAID, шифрования дисков, снапшотинга и так далее. Главное преимущество в том, что Device Mapper доступен в любом дистрибутиве и в любом ядре. Недостаток — что Docker использует обычный заполненный нулями файл для хранения всех образов, а это приводит к серьезным проседаниям производительности при записи файлов.
- Btrfs — позволяет реализовать функциональность AUFS на уровне файловой системы. Отличается высокой производительностью, но требует, чтобы каталог с образами (/var/lib/docker/) находился на Btrfs.
- Overlay — альтернативная реализация функциональности AUFS, появившаяся в ядре 3.18. Отличается высокой производительностью и не имеет ярко выраженных недостатков, кроме требования к версии ядра.
- VFS — самая примитивная технология, опирающаяся на стандартные механизмы POSIX-систем. Фактически отключает механизм разбиения на слои и хранит каждый образ в виде полной структуры каталога, как это делает, например, LXC или OpenVZ. Может пригодиться, если есть проблема вынесения часто изменяемых данных контейнера на хост-систему.
По умолчанию Docker использует AUFS, но переключается на Device Mapper, если поддержки AUFS в ядре нет.
Расскажите подробнее про Docker Machine, Swarm и Compose
Это три инструмента оркестрации, развиваемых командой Docker. Они все находятся в стадии активной разработки, поэтому пока не рекомендуются к применению в продакшене. Первый инструмент, Docker Machine позволяет быстро развернуть инфраструктуру Docker на виртуальных или железных хостах. Это своего рода инструмент zero-to-Docker, превращающий ВМ или железный сервер в Docker-хост. Бета-релиз Machine уже включает в себя драйверы для двенадцати различных облачных платформ, включая Amazon EC2, VirtualBox, Google Cloud Platform и OpenStack.
Главная задача Machine — позволить системному администратору быстро развернуть кластер из множества Docker-хостов без необходимости заботиться о добавлении репозиториев, установке Docker и его настройке; все это делается в автоматическом режиме. Разработчикам и пользователям Machine также может пригодиться, так как позволяет в одну команду создать виртуальную машину с минимальным Linux-окружением и Docker внутри. Особенно это полезно для юзеров Mac’ов, так как они могут не заморачиваться с установкой Docker с помощью brew или boot2docker, а просто выполнить одну команду:
$ sudo docker-machine create -d virtualbox devВторой инструмент, Docker Swarm позволяет добавить в Docker поддержку кластеров из контейнеров. С помощью Swarm можно управлять пулом контейнеров, с автоматической регулировкой нагрузки на серверы и защитой от сбоев. Swarm постоянно мониторит кластер, и, если один из контейнеров падает, он проводит автоматическую ребалансировку кластера с помощью перемещения контейнеров по машинам.
Swarm распространяется в виде контейнера, поэтому создать новый кластер с его помощью можно за считаные секунды:
$ sudo docker pull swarm
$ sudo docker run --rm swarm createРаботая со Swarm, ты всегда будешь иметь дело с сервером Swarm, а не с отдельными контейнерами, которые теперь будут именоваться нодами. На каждой ноде будет запущен агент Swarm, ответственный за принятие команд от сервера. Команды будут выполнены сразу на всех нодах, что позволяет разворачивать очень большие фермы однотипных контейнеров.
Третий инструмент, Docker Compose (в девичестве fig) позволяет быстро запускать мультиконтейнерные приложения с помощью простого описания на языке YAML. В самом файле можно перечислить, какие контейнеры и из каких образов должны быть запущены, какие между ними должны быть связи (используется механизм линковки), какие каталоги и файлы должны быть проброшены с хост-системы. К примеру, конфигурация для запуска стека LAMP из примера в предыдущей статье будет выглядеть так:
web:
image: example/www
command: /usr/sbin/httpd -DFOREGROUND
links:
- db
volumes:
- /root/html:/var/www/html
db:
image: example/mysql
command: /usr/bin/mysqld_safe --bind-address=0.0.0.0Все, что нужно сделать для его запуска, — просто отдать такую команду:
$ sudo docker-compose upНо что более интересно — ты можешь указать, сколько контейнеров тебе нужно. Например, ты можешь запустить три веб-сервера и две базы данных:
$ sudo docker-compose scale web=2 db=3Выводы
При работе с Docker ты столкнешься со множеством других более мелких проблем и у тебя возникнет множество вопросов по реализации той или иной конфигурации. Однако на первых порах этот FAQ должен помочь.
Несколько простых советов
- Всегда выноси часто изменяемые данные на хост-систему. Логи, базы данных, каталоги с часто меняющимися файлами — все это не должно храниться внутри контейнера (во-первых, усложняется администрирование, во-вторых, при остановке контейнера данные потеряются). В идеале контейнер должен содержать только код, конфиги и статичные файлы.
- Не лепи новые слои при каждом изменении настроек или обновлении софта внутри контейнера. Используй вместо этого Dockerfile для автоматической сборки нового образа с обновлениями и измененными конфигами.
- Вовремя вычищай завершенные и давно не используемые контейнеры, чтобы избежать возможных конфликтов имен.
- По возможности используй SkyDNS или dnsmasq. Их несложно поднять, но они способны сэкономить уйму времени.
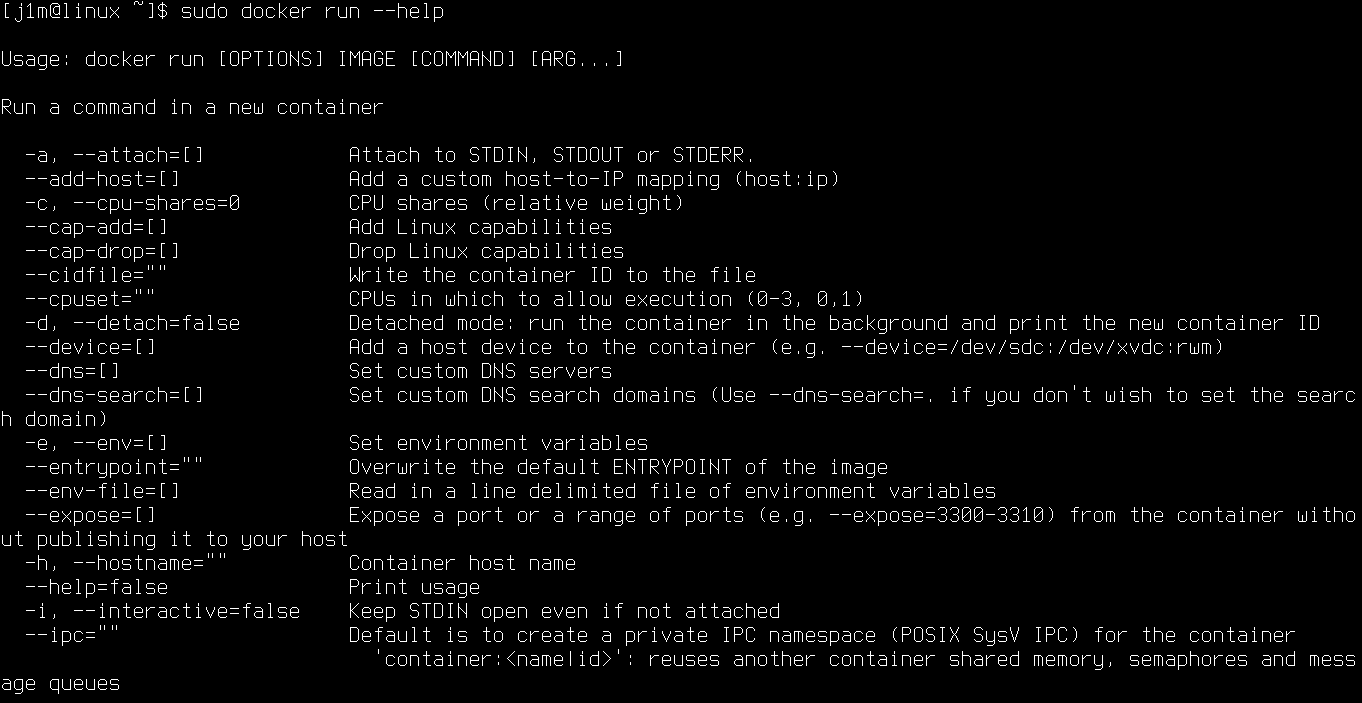
- Внимательно изучи хелп по команде run (docker run --help), там много интересного и полезного.
Шпаргалка по командам Dockerfile
- FROM <имя-образа> — какой образ использовать в качестве базы (должна быть первой строкой в любом Dockerfile).
- MAINTAINER <имя> — имя мантейнера данного Dockerfile.
- RUN <команда> — запустить указанную команду внутри контейнера.
- CMD <команда> — выполнить команду при запуске контейнера (обычно идет последней).
- EXPOSE <порт> — список портов, которые будет слушать контейнер (используется механизмом линковки).
- ENV <ключ> <значение> — создать переменную окружения.
- ADD <путь> <путь> — скопировать файл/каталог внутрь контейнера/образа (первый аргумент может быть URL).
- ENTRYPOINT <команда> — команда для запуска приложения в контейнере (по умолчанию /bin/sh -c).
- VOLUME <путь> — пробросить в контейнер указанный каталог (аналог опции -v).
- USER <имя> — сменить юзера внутри контейнера.
- WORKDIR <путь> — сменить каталог внутри контейнера.
- ONBUILD [ИНСТРУКЦИЯ] — запустить указанную инструкцию Dockerfile только в том случае, если образ используется для сборки другого образа (с помощью FROM).