Рано или поздно любая проверенная временем технология приходит к своему закату и должна быть утилизирована в пользу более современной и совершенной. Это произошло с 16-битными процессорами, ЭЛТ-мониторами, в данный момент это происходит со стационарными ПК и в ближайшем будущем произойдет с ноутбуками и смартфонами. Но в этой статье я хочу поговорить не о железе, а о софте, о том, как он видоизменяется прямо сейчас и какие технологии будущего мы можем ожидать уже в ближайшие несколько лет.
Долгая дорога из ring 0
Микроядерные операционные системы когда-то провозгласили идею вынесения в пространство пользователя любых не привязанных к железу компонентов ОС. Это должно было обезопасить систему от сбоев и обеспечить ей настоящую гибкость конфигурирования и простоту замены компонентов. Однако достигалось все это за счет достаточно резкого повышения системных требований; производительность такой ОС оказывалась на 10–15% ниже ОС с монолитным ядром, поэтому о микроядре быстро забыли, и оно нашло свое место в нише промышленных систем (привет QNX), для которых устойчивость к сбоям была важнее производительности.
О преимуществах микроядра, однако, не забыли, и много позже его отдельные черты начали проявляться и в классических монолитных ядрах. Ярчайшим примером стал интерфейс FUSE, позволяющий создавать файловые системы в юзерспейс и нашедший свое место в Linux и FreeBSD. Также в несколько извращенном виде модель микроядра была реализована в технологии RUMP из NetBSD, которая позволила вынести из ring 0 урезанное минималистичное ядро с нужным функционалом (в том числе отдельным драйвером). Но самым необычным оказалось решение группы разработчиков из FreeBSD унести из ядра весь TCP/IP-стек.
В декабре 2013-го небезызвестный в среде FreeBSD Роберт Ватсон вместе с группой исследователей представил реализацию веб-сервера Sandstorm, интересной фишкой которого стал встроенный TCP/IP-стек, работавший напрямую с драйвером сетевого адаптера. Разработка носила экспериментальный характер и предназначалась для доказательства эффективности такой модели, что и было продемонстрировано в сравнительных тестах производительности.
Преимущество, однако, достигалось вовсе не за счет вынесения сетевого стека в пользовательское пространство (сам этот факт никаких плюсов не давал), а благодаря реализации двух идей:
- обход стороной множества слоев абстракций, существующих в ядре и накладывающих необоснованные издержки на процесс отправки и получения пакетов;
- создание минималистичного оптимизированного для решения конкретной задачи сетевого стека.
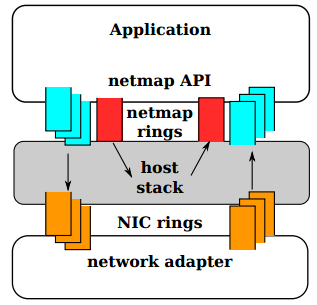
Первая идея была реализована с помощью фреймворка для отправки и получения пакетов netmap, уже включенного в состав FreeBSD. Netmap представляет собой быстрый и высокопроизводительный интерфейс прямого доступа к буферу сетевого адаптера в обход сетевого стека, подобный таким интерфейсам, как raw sockets, Berkley Packet Filter (BPF) или интерфейс AF_PACKET, но изначально созданный для обеспечения высокой скорости доступа.
Его реализация схожа с механизмом прямого доступа к видеопамяти Linux framebuffer, однако если последний предоставляет прямой доступ видеопамяти адаптера графического, то здесь речь идет о сетевом адаптере. Так же как и в случае с FB, приложение, пожелавшее использовать netmap для работы с сетевой картой, сначала должно отобразить устройство netmap (/dev/netmap) в оперативную память (mmap), а затем записать в него цепочку пакетов в сыром виде и запросить операцию их отправки:
# Открываем устройство netmap
open("/dev/netmap")
# Переводим сетевую карту в режим netmap
ioctl(fd, NIOCREG, arg)
# Отображаем в память
mmap(..., fd, 0)
# Далее идут операции записи...
# Отправка
ioctl(fd,NIOCTXSYNC)
Примерно так же происходит прием пакетов. При этом все пакеты должны быть записаны в сыром виде, а это значит, что для реализации полноценных сетевых приложений необходим сетевой стек, который будет работать поверх netmap. Основной профит здесь кроется как раз в комбинации невероятно производительного netmap, способного отправить один пакет всего за 70 циклов процессора, и оптимизированного сетевого стека, который в случае отдельно взятого приложения может быть простым и заточенным на решение только определенных задач.


Именно так был реализован Sandstorm. Фактически это не только HTTP-сервер, но и Ethernet, и TCP/IP-стек в одном флаконе, оптимизированный для отправки файлов небольшого размера. Это красноречивая демонстрация пресловутого пути UNIX, когда приложение выполняет только одну функцию, но выполняет максимально хорошо. Согласно проведенным тестам, Sandstorm легко обходит nginx на Linux и FreeBSD, создавая гораздо более низкую нагрузку на процессор и обеспечивая удвоенную, а порой и утроенную пропускную способность.
INFO
На одном ядре процессора с частотой 900 МГц netmap способен осуществлять быстрый форвардинг 14,88 миллиона пакетов в секунду, что соответствует предельной скорости передачи фреймов Ethernet в канале 10 Гбит/с.
В Linux версий 2.2 и 2.4 существовал простой внутриядерный HTTP-сервер (khttpd), высокая производительность которого достигалась за счет снижения количества переключений контекста и копирований буферов.
К слову сказать, netmap и Sandstorm далеко не первыми реализуют идею высокопроизводительного прямого доступа к сетевому адаптеру. Подобную технику используют программный роутер Click или генератор трафика pkt-gen, работающие в режиме ядра. Идея экспорта буфера сетевой карты в юзерспейс была частично реализована в BSD PFRING и Linux PACKETMMAP, но вместо самого буфера они предоставляют доступ к специальной области памяти, содержимое которой во время отправки копируется в буфер адаптера. В отличие от них netmap реализует идею zero-copy, когда после записи пакетов в память не происходит лишних, снижающих производительность копирований. Существуют также техники прямого доступа к сетевому адаптеру из пространства пользователя, но они требуют специальных драйверов для каждого адаптера, так как netmap работает со стандартными.
Кесарю кесарево
Выпущенный компанией Google в 2008 году браузер Chrome за два года своего существования перевернул все представления о том, как должен выглядеть веб-обозреватель XXI века. На смену тяжеловесному дизайну с множеством функций пришли идеи простоты, скорости и безопасности. Кроме минималистичного интерфейса и пресловутого JIT-компилятора V8, Chrome отличался особой многопроцессорной системой рендеринга веб-страниц и исполнения плагинов, которая позволяла браузеру выжить в любых условиях — даже тогда, когда Firefox и Opera падали от ошибок во Flash-плеере и реализации JS- и HTML-движка.
Поначалу такой дизайн воспринимался скорее как proof of concept, идея ради идеи — браузер обретал защиту от редких случаев краха, но при этом возникал ряд определенных проблем, в том числе слишком большая прожорливость к процессорным ресурсам и памяти. Однако чем дальше продвигался веб на пути превращения в операционную систему XXI века, тем яснее становилось, что идея многопроцессности не просто имеет право на существование, а должна быть неотъемлемой частью любого современного браузера.
Mozilla задумалась о переходе на многопроцессную модель еще в 2009 году (проект Electrolysis), но подошла к ней немного с другой стороны. Для Mozilla переход на новый дизайн был направлен скорее на улучшение отзывчивости тяжеловесного написанного на XUL интерфейса, чем на безопасность. Их идея в первую очередь состояла не в разделении обработки содержимого каждой вкладки отдельным процессом, а в разделении интерфейса и HTML-движка, так, чтобы их можно было разнести на разные процессорные ядра, увеличив таким образом общую скорость работы и отзывчивость браузера.
В ходе работы над проектом выяснилось, что идея настолько трудна в реализации и масштабна, что легче его свернуть и попытаться использовать другие методы оптимизации. В 2011 году разработчики заморозили проект на неопределенный срок и сфокусировали свои усилия на других областях. В частности, был пересмотрен код обслуживания внутренних баз данных (давняя проблема Firefox), оптимизирован сборщик мусора, а опыт в области многопроцессной обработки использован для вынесения плагинов в отдельные процессы.
На два года об идее распараллеливания как будто бы забыли, но работа продолжалась, и ее результат был представлен публике в декабре 2013 года в виде ночных сборок Firefox с полным разделением кода интерфейса и движка обработки веб-страниц. В сущности, новая архитектура была построена по принципу «кесарю кесарево»: один процесс занимался созданием интерфейса и всех относящихся к нему компонентов, а второй рисовал на холсте результат обработки веб-страниц. В конце результаты обоих процессов передавались внутреннему композитору, который сводил картинку воедино и выводил на экран.
Как уже было сказано, речи об обработке содержимого каждого таба в отдельном процессе не шло, за все табы по-прежнему отвечал один процесс. Тем не менее новая архитектура позволила решить сразу несколько проблем. Благодаря возможности разнести процессы на разные ядра браузер стал заметно быстрее, особенно отзывчивость на действия пользователя. Также браузер стал устойчивее к сбоям: при падении движка рендеринга сам браузер остается работать даже несмотря на то, что все вкладки становятся недоступными (согласен, противоречивое преимущество).
В будущем планируется разнесение обработки каждой страницы по отдельным процессам так же, как это сделано в Chrome. Кроме явного преимущества в виде защиты от сбоев и безопасности, такое новшество должно привести к оптимизации управления памятью: если каждая страница будет иметь собственный процесс, все утечки этого процесса будут нивелированы после ее закрытия, а общая фрагментация памяти снизится за счет ее четкого разделения между процессами.
На момент написания этой статьи новая функциональность еще не была активирована даже в ночных сборках и для ее включения было необходимо включение опцииbrowser.tabs.remote на странице about:config.
Децентрализованное телевидение
Много лет назад, когда для загрузки фильма в DVD-качестве через torrent-сети требовалось по меньшей мере два часа, я всегда включал в клиенте опцию приоритетной загрузки более близких к началу файла чанков, так что через час фильм уже можно было начинать смотреть, а его остальные части загружались во время просмотра. Сегодня, когда скорость в 60 мегабит стала стандартной даже в провинции, такой метод потерял свою актуальность, но дал жизнь новой технологии — децентрализованному Live-вещанию.
В марте 2013 года компания BitTorrent Inc., отвечающая за развитие одноименного протокола и клиента uTorrent, показала миру новый протокол BitTorrent Live, который использует принципы работы децентрализованных P2P-сетей для организации потокового вещания видео в режиме реального времени. На основе уже существующего BitTorrent они создали новый протокол, который использует ту же идею получения и раздачи частей данных с разных узлов с тем исключением, что теперь речь идет не о конкретном файле, а о постоянном потоке данных, точнее, его небольшом актуальном в данный момент участке.
INFO
Интересно, что всего за два месяца до анонса протокола стриминга видео BitTorent Inc. представила технологию BitTorrent Sync для синхронизации данных нескольких удаленных машин между собой.
Для эффективной работы такая система требует от узлов достаточно высоких (но обычных для нынешнего времени) скоростей и низких задержек, но зато позволяет создать по-настоящему демократичную домашнюю систему вещания, которая не требует широкого канала для эффективной раздачи на множество клиентов. Более того, в отношении BitTorrent Live действует обратное правило: чем больше людей будет смотреть вещание, тем выше будет его доступность и суммарная пропускная способность. Каждый узел здесь выступает в качестве ретранслятора.
К сожалению, на момент написания статьи техническая информация о протоколе была недоступна (кроме невнятного текста патента), поэтому мы не можем узнать, каким образом ее создатели решили такие проблемы, как малое количество сидеров на первом этапе раздачи, или как в условиях множественных копирований чанков между узлами удается достичь низких задержек при получении видео. Тем не менее клиентское ПО уже доступно для ПК под управлением Windows, Ubuntu Linux и OS X, можно использовать его в том числе для организации ретрансляции RTMP-потока и на собственной шкуре оценить возможности протокола.
Также стоит отметить, что идея децентрализованной передачи потоковых данных сама по себе далеко не нова, и первым более-менее успешным примером такой системы был Tribler, спонсированный Евросоюзом и впоследствии использованный для создания технологии Ace Stream (в девичестве BitTorrent Stream), которая к сегодняшнему дню стала уже достаточно популярной. По сути, это всего лишь надстройка над протоколом BitTorrent.
Launchd для FreeBSD
В 2010 году Леннарт Поттеринг представил первую версию системного менеджера systemd, одной из самых примечательных особенностей которого была система параллельного запуска сервисов при старте системы, основанная не на зависимостях между компонентами и целями, а на зависимостях ресурсов. Позже systemd оброс огромным количеством другой функциональности и превратился в объект насмешек, но архитектурно он остался прежним. И этой своей архитектурой он обязан ни много ни мало компании Apple — их системному менеджеру launchd, используемому в OS X.
Именно в launchd впервые появился функционал, позволивший systemd стать стандартом даже несмотря на все свои противоречия. Его разработчики выдвинули, не побоюсь этого слова, гениальную идею использовать заранее созданные UNIX-сокеты системных сервисов для заблаговременного запуска системных служб (демон syslog, например, зависит вовсе не от cron, а от его UNIX-сокета, к которому он подключается при запуске, поэтому предварительное создание этого сокета позволяет запустить syslog и cron одновременно). Именно в launchd, хоть и не впервые, появилась идея объединить в одном демоне службы init, inetd, atd, crond и watchdogd, что позволило скоординировать автоматический запуск служб при подключении к ним по сети, запуск при старте, по расписанию и отслеживание состояния служб в одном демоне и объединить их интерфейсы управления. Launchd позволил скоординировать запуск разрозненных системных служб и сделать этот процесс действительно быстрым.
Компания Apple открыла код launchd еще в 2005-м, и тогда же были предприняты первые попытки портировать его в FreeBSD. Это взял на себя студент Тайлер Круа и в рамках программы Google Summer of Code создал наполовину работоспособный порт. После этого о проекте успешно забыли, но в конце 2013 года автор решил продолжить начатое и запустил проект Open Launchd, в рамках которого планируется довести имеющийся код до рабочего состояния и опубликовать его в системе портов.
Что может дать launchd пользователям FreeBSD? Все то же, что systemd дает линуксоидам, а именно рекордно быструю загрузку системы, возможности гибкого контроля за работой демонов, автоматический запуск демона только тогда, когда он действительно нужен (например, когда на его сетевой порт приходит запрос или в нем нуждается другой демон) и унифицированный интерфейс управления. В отличие от простых и лаконичных ini-файлов, используемых в systemd, launchd полагается на конфигурационные файлы в формате XML — что разработчики и пользователи, скорее всего, не примут ни в каком виде, однако никто не мешает сделать собственный формат конфигурационных файлов.
Пока работа по портированию находится в начальной стадии, но она идет, и, возможно, через год-другой системой уже можно будет пользоваться для загрузки хотя бы домашних систем. Если, конечно, Тайлер вновь все не бросит.
Смерть иксам
Первая версия сервера X Window появилась на свет еще в 1983 году как система удаленного запуска графических приложений для тонких клиентов. С тех пор прошло уже тридцать лет, но архитектура иксов практически не поменялась. Это все то же ПО для тонких клиентов, способное удовлетворить современные запросы только благодаря огромному количеству расширений, дополнений и костылей. По мнению специалистов, X.org в своем современном виде представляет собой огромный кусок запутанного кода, большая часть которого висит мертвым грузом и не выпиливается только потому, что для его распутывания потребовалось бы колоссальное количество времени.
На протяжении последних двадцати лет предпринималось множество попыток полностью заменить иксы, но все они проваливались либо из-за того, что сторонние разработчики отказывали в поддержке, либо предложенные варианты не соответствовали предъявляемым требованиям. Скооперироваться и начать работу над заменой, удовлетворяющей всех, удалось только несколько лет назад со стартом проекта Wayland, участие в котором приняли ключевые разработчики самого X.org.
Стабильной версии Wayland, тем не менее, достиг только в прошлом году и на текущий момент до сих пор остается экспериментальным вариантом, поверх которого может работать лишь небольшое количество софта, не говоря уже о полноценных графических окружениях вроде KDE, GNOME и Xfce. Зато полтора года назад начали корпеть над окружением Hawaii, изначально рассчитанным исключительно на Wayland без привязки к иксам.
25 декабря разработчики представили пригодную для использования версию Hawaii 0.2, построенную на тулките Qt5, который уже давно портирован на Wayland. Окружение включает в себя классический рабочий стол в стиле Windows с собственным менеджером окон (композитным сервером) Green Island, меню приложений, системой уведомлений, хранителем экрана, движком тем и поддержкой многомониторных конфигураций.
В качестве дополнительных инструментов в рамках проекта разрабатываются также приложение для настройки параметров системы, библиотека для упрощения разработки приложений Fluid, файловый менеджер Swordfish, менеджер для работы с архивами, просмотрщик изображений EyeSight, видеопроигрыватель Cinema, эмулятор терминала, набор обоев и пиктограмм. Собственными глазами все это можно увидеть, установив дистрибутивMaui или скомпилировав Hawaii из исходников.
В качестве веб-браузера в дополнение к Hawaii отлично подойдет ozone-wayland, версия браузера Chromium для Wayland, подготовленная разработчиками из компании Intel. Странное название данного браузера — это отсылка к слою абстракции Ozone, который Chromium использует для вывода картинки. Ozone, в частности, позволяет легко переносить браузер и его производные на сторонние графические системы.
Вместо выводов
По своей природе мир Open Source очень консервативный. Все мы до сих пор пользуемся технологиями, изобретенными еще отцами-основателями UNIX и каким-то образом дожившими до наших дней. Монолитное ядро, структура файловой системы, набор команд, файлы устройств, графическая подсистема — все это оттуда. Многие из этих технологий пережили своих создателей, и это показатель правильности их реализации. Однако всему свой срок, и без изменений двигаться дальше нельзя. Я до сих пор искренне опечален смертью ОС Plan9, которая должна была прийти на смену UNIX, но зато я могу порадоваться, когда на свалку выбрасывают уже никуда не годный кусок кода под названием X-сервер, а систему инициализации System V заменяют на что-то действительно современное. UNIX прекрасен, но старики не живут вечно.