
Проблема управления большим количеством систем далеко не нова, но особенно острой она стала при распространении кластеров и облачных сервисов. Для ее решения появились разнообразные инструменты, и каждый делает это по-своему. Synctool, разработанная для голландского фонда SURFsara, обеспечивающего суперкомпьютеры для учебных заведений, ориентирована в первую очередь на кластеры. Но гибкость утилиты позволяет использовать ее практически в любой ситуации, а благодаря ее простоте долгого изучения не потребуется.
СМ-системы
*nix-системы изначально оснащаются средствами удаленного управления, а сам способ хранения и формат конфигурационных файлов позволяет быстро распространять обновленную версию настроек простым копированием на узел. До определенного количества систем такая схема вполне годится. Когда же серверов не один десяток, без специального инструмента не справиться. Вот здесь и появляется интерес к системам управления конфигурацией, позволяющим настраивать серверы не руками, а программным способом. Системы настраиваются быстро и с меньшим количеством возможных ошибок, админ получает отчет. Также СМ-система умеет следить за всеми изменениями сервера, поддерживая нужную конфигурацию.
Прародителями СМ-систем стал CFEngine, созданный в 1993 году норвежским ученым Марком Бургесом из университета города Осло. На сегодня существует уже большое количество систем: Chef, Puppet, SaltStack, CFEngine, Ansible, Bcfg2, synctool и другие. Каждая изначально проектировалась под определенные задачи и выделяется своими особенностями, в большинстве случаев используется собственный язык настройки, при помощи которого описывается конфигурация узлов, доступны разные механизмы абстракции и стили управления. Одни (декларативные) описывают состояние узлов, другие (императивные) позволяют контролировать процесс внедрения изменений. Чтобы освоить любую из них, потребуется некоторое время. И это не значит, что выбранная СМ-система будет идеально подходить под все задачи, так что все придется начинать сначала.
Возможности synctool
Разрабатывать утилиту управления конфигурацией для синхронизации кластеров synctool начал в 2003 году Валтер де Йонг (Walter de Jong), эксперт голландского фонда SURFsara, и с тех пор она используется в реальной работе на больших вычислительных узлах. Ее главный плюс — здравый смысл, то есть ничего нового изучать не придется: synctool, по сути, просто надстройка над привычными инструментами и практиками *nix. В ней нет языка сценариев, при необходимости использовать язык оболочки или любой скриптовый, и целью не ставится автоматизировать абсолютно все аспекты администрирования систем. Основная задача synctool — обеспечить синхронизацию и аутентичность конфигурационных файлов. То есть она не предназначена для полной установки системы, хотя может использоваться для быстрого конфигурирования новых узлов.
Для этого создается репозиторий файлов, а мастер-узел периодически их сверяет с остальными нодами. Если обнаружены различия (например, разная контрольная сумма или время создания), производится обновление, после чего запускается специальная команда synctool-client. Кстати, вполне возможно выполнять synctool-client на узле вручную, в этом случае будет проверяться только локальная копия репозитория. Синхронизация с хранилищем на мастер-сервере не производится, здесь инициатором всегда выступает главный узел.
Предусмотрено три режима работы: предупреждение об отклонениях, автоматическое обновление или безусловное обновление файлов. Узлы могут управляться индивидуально, быть частью одной или нескольких логических групп или все вместе. Группы могут быть вложенными.
Возможно расширение функционала при помощи самописных плагинов-скриптов. При этом нет никаких ограничений на используемый язык. Сценарии могут быть связаны с файлами для выполнения действий после обновления файла, шаблоны файлов могут генерироваться на лету (например, подставляться IP), специальный тип файлов, заканчивающийся на .post, позволяет задавать команды, которые выполнятся при обновлении файла (например, перезапустить сервис). Скрипты могут иметь определенную группу свойств.
Для распространения файлов используется SSH (аутентификация с использованием SSH-ключей или hostbased), и непосредственно копирование производится при помощи rsync. Никакие агенты на управляемые системы устанавливать не нужно.
Работает synctool в интерактивном режиме. В комплекте идет несколько специально разработанных команд, упрощающих конкретные задачи, их легко использовать в сочетании с другими инструментами. Например, dsh позволяет выполнять команды сразу на нескольких узлах. Хотя параметров у утилит много, набор основных функций очень небольшой и во всем легко разобраться.
Установка synctool
Написана synctool на Python, поэтому установка проблем не вызывает. В качестве зависимостей указаны Python, SSH (лучше OpenSSH 5.6+), rsync и ping. Все это обычно уже есть в дистрибутивах. SSH лучше настроить на беспарольную аутентификацию, иначе придется подтверждать учетные данные, в Сети есть достаточно руководств по этому вопросу. Единственный момент — все утилиты подключаются к удаленной системе от имени root, а, например, в Ubuntu по умолчанию такой учетной записи нет. Чтобы не править исходники, лучше рут все же завести, не забыв разрешить ему подключаться по SSH. В целях безопасности также следует ограничить sshd только интерфейсом внутренней сети (ListenAddress в sshd_config), ведь «светящийся» 22-й порт — это приманка для ботов. Далее скачиваем архив с официального сайта, распаковываем и выполняем
$ sudo ./setup.sh -fЕсли запустить setup.sh без ключа -f, будет произведена dry run, то есть проверка без установки. По умолчанию устанавливается в каталог /opt/synctool, лучше оставить как есть. Если он все-таки не подходит, то, чтобы изменить его, добавляем параметр --installdir. Внутри будет образовано несколько подкаталогов. Скрипты (их девять) находятся в synctool/bin (по большому счету почти все являются ссылками на synctool/sbin), его желательно сразу добавить в PATH, чтобы было проще работать.
$ sudo nano /etc/profile
PATH=$PATH:/opt/synctool/bin
export PATHПосле чего перелогинимся. Клиентское ПО на узлах, как говорилось выше, ставить не нужно. Мастер-узел автоматически устанавливает и обновляет synctool на нодах. Исполняемые файлы, необходимые для них, находятся в synctool/sbin, который синхронизируются с узлами каждый раз при запуске утилиты synctool.
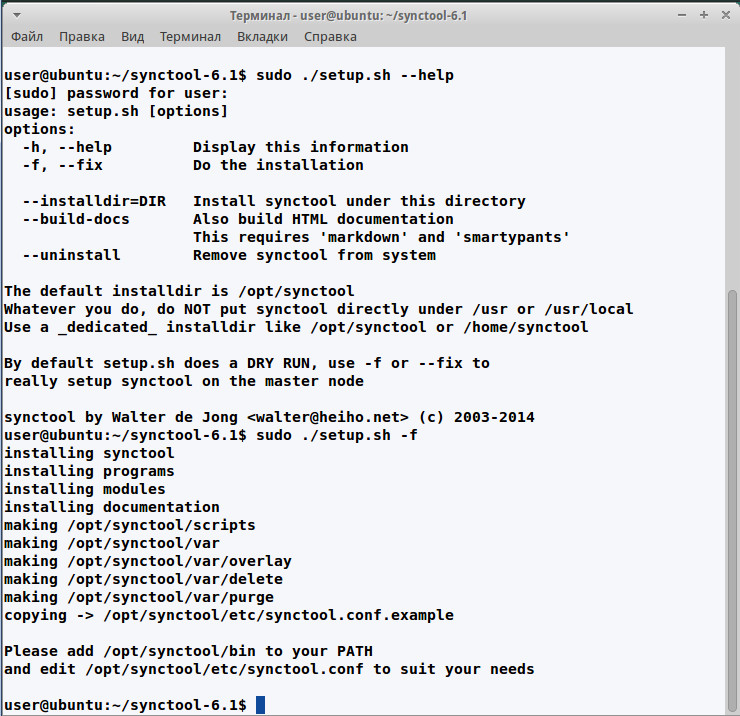

Конфигурационный файл synctool
Прежде чем приступить к работе, необходимо настроить synctool. Все установки указываются в конфигурационном файле /opt/synctool/etc/synctool.conf, в котором описывается, как выглядит кластер (узлы, группы, роли) и как synctool может с ними связаться, плюс журналирование, бэкап и прочее. Изначально нет необходимости пробовать создавать сложную систему из разветвленных групп, это обычно путает, а конфигурацию можно позже в любой момент перестроить, окончательно разобравшись. В комплекте поставки идет пример synctool.conf.example, который можно использовать в качестве заготовки. Параметров не очень много, все они расписаны в документации, хотя в некоторых случаях и недостаточно внятно. Тем более что вариантов написания некоторых может быть несколько и постоянно добавляются новые. Остановлюсь только на основных.
Первым делом необходимо сказать synctool, какой узел будет за главного. Для этого в параметре master указывается его полное доменное имя.
master n1.cluster.orgИмя можно получить при помощи synctool-config --fqdn. Зависимость всей структуры от одного узла — это не очень хорошо с точки зрения надежности, необязательный параметр slave позволяет определить дополнительные, куда будет отправляться полная копия репозитория. Сами узлы задаются при помощи параметра node, после которого указывается имя узла или узлов, группы, как связаться и параметры синхронизации.
node <имя> <группа> [ipaddress:<IP адрес/DNS>] [hostname:<fqdn имя>] [hostid:<filename>] [rsync:<yes/no>]Имя узла — любой буквенно-цифровой символ, причем имя необязательно должно указывать на хостнейм или соответствовать записи в DNS, то есть в его качестве можно использовать любую информацию, удобную для понимания. Но без каких-то других указаний synctool будет искать узел по имени через DNS. Для удобства можно прописать алиас в /etc/hosts, но в этом случае придется контролировать два файла, что чревато ошибками. Поэтому разработчики предлагают свой вариант. Если прописанное имя невозможно определить через DNS или по другим причинам (например, работа в автономном режиме), IP-адрес или хостнейм узла указывается при помощи необязательных параметров ipaddress и hostname.
Узел может входить в состав нескольких групп, но важность групп соответствует их порядку перечисления (т.е. первая главная). Спецификатор hostid используется в том случае, когда одно имя может иметь несколько узлов, поэтому для определения текущего используется файл, размещенный на целевом узле. Какая нода ответит при доступе к файлу, та и будет проверяться на обновление.
По умолчанию synctool синхронизируется со всеми узлами. Но в некоторых случаях в этом нет необходимости (например, узлы используют общеe хранилище NFS), установка rsync:no позволит запретить синхронизацию с этим узлом.
Так как в файле обязательно должен быть описан каждый узел, а кластер может содержать их сотни, предоставлена возможность задавать имена и параметры при помощи диапазона:
node node[1-9] ubuntu ipaddress:node[1]-cluster1
node node[10-19] ubuntu ipaddress:192.168.1.[10]В случае если планируется синхронизировать при помощи synctool и мастер-узел, он также определяется через параметр node, но разработчики не рекомендуют такой метод синхронизации.
В терминах synctool узлы собираются в группы, но, говоря о группе, фактически подразумевают свойства узла. Ключевое слово group определяет составные группы, объединяющие несколько подгрупп в единую группу:
group <groupname> <subgroup> [..]Если подгруппы еще не существуют, они автоматически определяются как новые/пустые группы. Имя узла также можно использовать в качестве группы. Встроенная группа All позволяет применять настройки ко всем узлам. Кроме этого, файл может содержать и ряд других полезных параметров: ignore (позволяет исключить узлы или группы), colorize (раскрашивает вывод), include (подключает внешний файл с настройками; при разветвленной структуре, которой управляют несколько админов, это очень удобно).
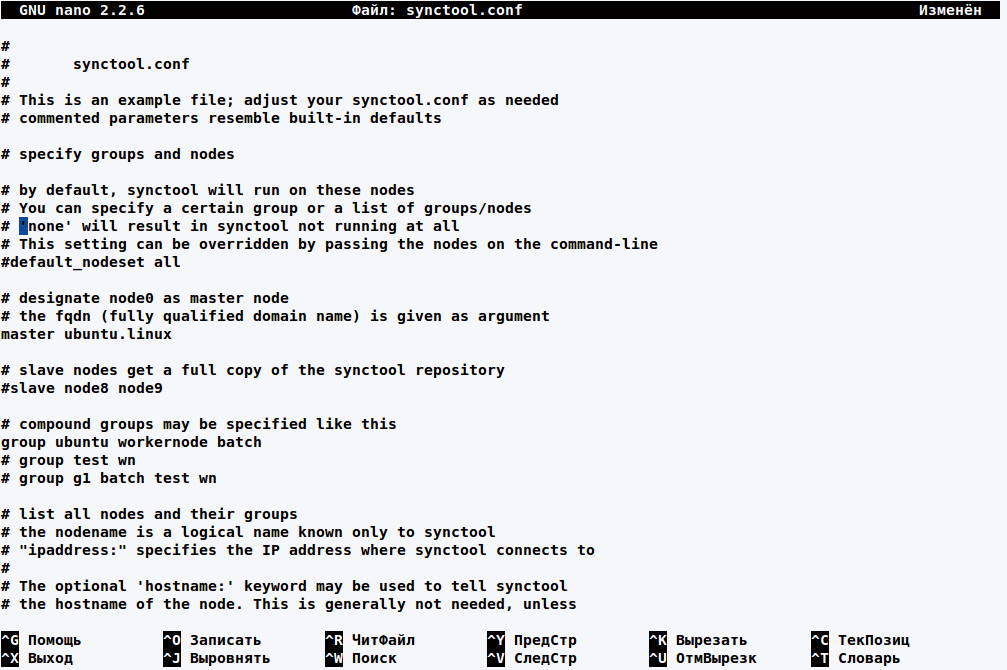
Для проверки файла используется команда synctool-config. Список узлов можно проверить при помощи параметра -l:
$ sudo synctool-config -l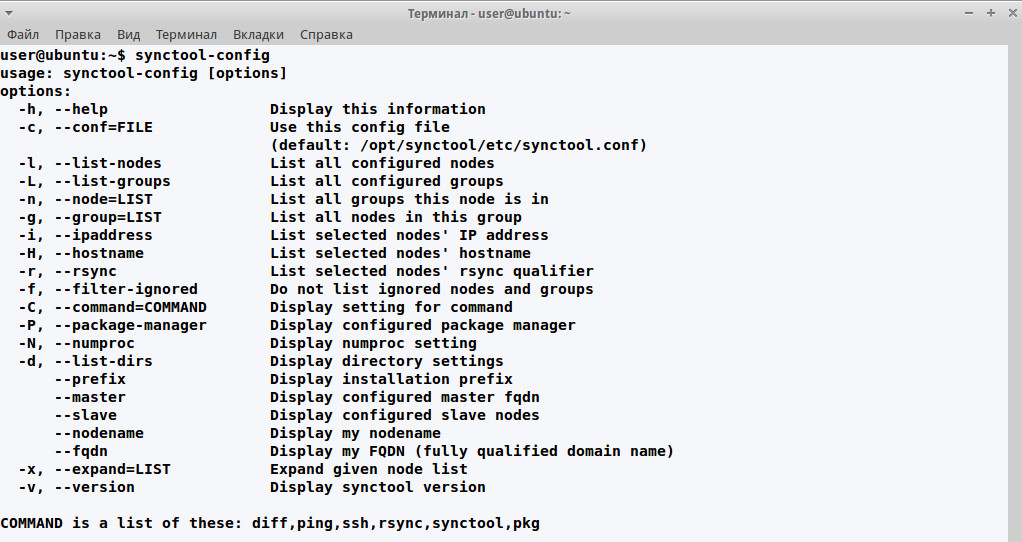
Теперь, когда есть минимальные установки, можно попробовать запустить synctool на удаленном узле:
$ sudo synctool -n node1В ответ получим отзыв ноды, который означает, что все работает. Можем попробовать запустить задачу на всех узлах:
$ sudo synctool
DRY RUN, not doing any updatesКаждый узел, прописанный в файле, должен ответить. Теперь осталось нагрузить его работой. Забегая вперед, скажу об одной особенности, о которой нужно помнить: утилита synctool, запущенная глобально, требует опцию -f (--fix), иначе она будет запущена в режиме проверки dry run. Это позволяет спасти от случайных ошибок.
$ sudo synctool -fЕсли указываются какие-то параметры, то -f использовать обычно не нужно.
Файлы и каталоги synctool
Файлы, которые следует синхронизировать, располагаются в строго определенных каталогах, имеющих свое назначение:
- /opt/synctool/var/overlay — файлы, которые должны быть скопированы на целевые узлы, при отсутствии или обнаружении разницы между файлом в репозитории и клиенте;
- /opt/synctool/var/delete — файлы, которые должны быть удалены. Для этого достаточно просто поместить пустой файл с нужным именем;
- /opt/synctool/var/purge — каталоги, которые копируются на целевые системы «как есть» без сравнения; если файл на конечной системе отсутствует, он удаляется;
- /opt/synctool/scripts — каталог со скриптами, которые могут быть выполнены на конечной системе при помощи команды dsh.
В synctool имя логических групп совпадает с названием каталога или является расширением каталога/файла, размещенного в подкаталогах overlay. В настройках по умолчанию все файлы должны иметь расширение. Например, каталог overlay/all содержит файлы, предназначенные для всех систем (хотя разработчики рекомендуют держать его пустым). Как вариант, можно просто добавить расширение _all к имени файла. Здесь проще показать на примере:
- overlay/all/etc._group1/ — файлы в каталоге /etc получат ноды, входящие в группу group1;
- overlay/all/etc/hosts._group2 — файл /etc/hosts для группы group2;
- overlay/all/etc/hosts._all — файл /etc/hosts для всех;
- overlay/group3/etc/hosts._all — файл /etc/hosts для всех узлов группы group3.
Символические ссылки тоже используются при синхронизации, с расширением группы они будут показывать в «пустоту», но на конечной системе они будут показывать на нужный файл. Например, /etc/motd является ссылкой на файл file, который на мастер-сервере имеет имя file._all. То есть ссылка работать не будет, но после копирования и разыменования все будет работать как нужно.
overlay/all/etc/motd._all -> file
overlay/all/etc/file._allВероятно, первое время с группами и расширениями придется немного повозиться, чтобы понять систему именования. В случае ошибки в имени synctool выдаст что-то вроде there is no such group.
Теперь, когда хранилища заполнены, можем провести синхронизацию. Параметров у synctool много. Например, нам нужно синхронизировать отдельный узел:
$ synctool -n node1
node1: DRY RUN, not doing any updates
node1: /etc/issue updated (file size mismatch)Или отдельный файл:
$ synctool -n node1 -u /etc/issueОпция --diff позволяет просмотреть различия между файлами, в том виде, как выводит их одноименная утилита.
$ synctool -n node1 --diff /etc/issue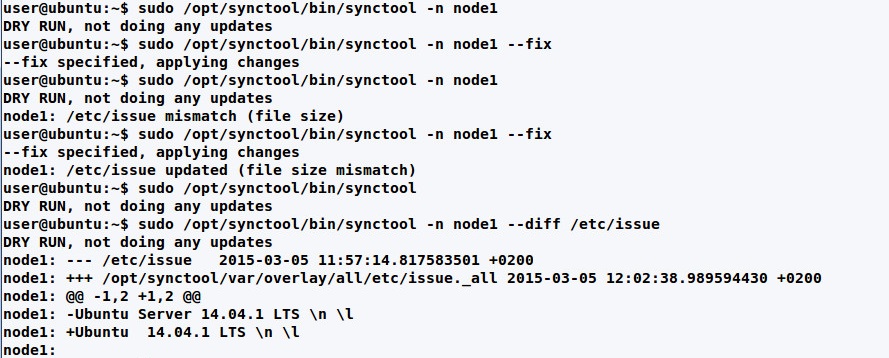
В отличие от overlay, файлы в purge не используют расширения групп, поэтому synctool копирует все поддерево и удаляет любые файлы на целевом узле, отсутствующие в исходном дереве. Таким образом, purge идеально подходит для начального изменения конфигурации или глобальной перестройки серверов. После изменения конфигурационного файла следует перезапустить сервис. Synctool для этого предлагает простой механизм: все команды, которые необходимо выполнить после копирования, заносятся в файл с расширением post. Например, у нас в репозитории есть конфигурационный файл веб-сервера Apache:
overlay/all/etc/apache/apache.conf._allДля перезапуска сервиса создаем файл overlay/all/etc/apache/apache.conf.post такого содержания:
service apache2 reloadи делаем его исполняемым:
$ sudo chmod +x apache.conf.postВ примере скрипт не имеет расширения групп, а значит, будет актуален для всех. Но при необходимости выполнять различные действия на узлах можно его использовать (apache.conf.post_ubuntu). Post-скрипт по умолчанию выполняется в том же каталоге, в котором размещается конфигурационный файл. Параметры некоторых конфигурационных файлов могут генерироваться динамически (например, прописывается IP-адрес узла), можно для каждой ноды загрузить файл индивидуально, но, если систем много, это будет не очень весело. Для генерации подобных конфигурационных файлов используются шаблон — файл с расширением _template. В паре к нему идет _template.post-скрипт, который запускает специальную утилиту synctool-template для генерации файла конфигурации на удаленной системе. Во время работы _template.post-скрипт вычисляет значение переменной и экспортирует ее через функцию export (имя переменной может быть любое, или их может быть несколько):
export VALUE
/opt/synctool/bin/synctool-template "$1" >"$2"В шаблоне в нужное место просто вставляем @VALUE@. Утилита synctool-template получит значение переменной и запишет в файл.
Утилиты synctool
В поставке synctool идет несколько утилит. Их имена начинаются на dsh и synctool. Первые позволяют выполнять некоторые операции на удаленных системах, вторые относятся непосредственно к работе различных составляющих synctool. Часть из них вспомогательная, и их обычно не приходится запускать вручную. А вот некоторые интересны. Названия нод и групп берутся из synctool.conf, поэтому для выполнения требуется минимум параметров. Например, dsh-ping позволяет проверить, какие из узлов отвечают. Если ввести без параметров, то будут опрошены все системы:
$ dsh-pingВсе утилиты synctool имеют сходные опции, поэтому почти все сказанное о dsh касается и остальных. Например, -q и -a позволяют сделать вывод менее болтливым, опция -v, наоборот, дает подробный вывод.
Но самая приметная из первого списка — это собственно dsh, представляющая собой некий командный менеджер, позволяющий выполнять команды и скрипты на группе узлов:
$ dsh uptimeили на отдельном узле и группе:
$ dsh -n node1 ifconfig
$ dsh -g ubuntu dateСоздав скрипт в каталоге scripts, мы можем его легко выполнить на любом узле (задавать полный путь не требуется):
$ dsh -g ubuntu script.sh
После запуска процесс выполнения на всех узлах начинается параллельно. В некоторых случаях в этом нет необходимости, поэтому можно ограничить количество процессов при помощи --numproc, а -z позволяет указать задержку между командами для разных узлов. Запуск только одного процесса за один раз:
$ dsh --numproc=1 uptimeТо же, но с пятисекундной задержкой:
$ dsh -z 5 uptimeМенеджер пакетов dsh-pkg является фактически универсальной оберткой над всеми популярными инструментами для установки приложений в Linux и BSD, так что можно управлять любым из них, используя только одну команду и набор аргументов. Это полезно, когда в группе работают узлы с разными ОС. По умолчанию менеджер определяется автоматически, но в некоторых случаях его можно задать вручную в synctool.conf:
package_manager apt-getИспользуя dsh-pkg, очень просто произвести любые операции на удаленных системах:
$ sudo dsh-pkg -n node1 --list
$ sudo dsh-pkg -g ubuntu --install wget
$ sudo dsh-pkg --update
$ sudo dsh-pkg -upgradeПоследние две команды обновят списки пакетов и установят обновления на всех системах.
Вывод
Назвать synctool сложной нельзя — чтобы разобраться с базовыми возможностями, достаточно поэкспериментировать пару часов. Как результат, получим удобный и надежный инструмент управления большим количеством серверов.












