Формат PDF стал очень популярен с развитием интернета и распространением электронной документации, и тем, кто имеет дело с текстами, приходится подбирать инструментарий, чтобы открывать файлы в этом формате и работать с ними. Сторонникам *nix есть из чего выбирать.
Чтение PDF
PDF-файлы достаточно сложны по своей структуре, они могут содержать текст, графику, вложения, иметь сжатие и шифрование, поэтому современные версии формата невозможно прочитать при помощи стандартных команд Linux, cat, less или обычного текстового редактора вроде vi. Для просмотра и извлечения информации необходимо использовать специальную программу.
Сам Adobe также выпускает версию Adobe Reader для UNIX, но она давно не обновлялась и вряд ли представляет какой-то интерес. В большинстве дистрибутивов Linux по умолчанию установлена какая-то из программ для чтения PDF-файлов, поэтому проблем с этим нет. В Ubuntu и клонах это одна из лучших и в то же время очень простых программ Evince, разрабатываемая в рамках проекта GNOME, но она отлично работает и с любым другим оконным менеджером. Evince поддерживает просмотр — PDF, DjVu, TIFF, PostScript, DVI, XPS, SyncTex, Сomics Books (cbr, cbz, cb7, cbt) и презентации в формате ODP. Открывает зашифрованные документы PDF. Реализован поиск по документу, несколько вариантов отображения структуры документа (древовидная, миниатюры страниц и другие), что позволяет быстро найти нужную. Для PDF и DVI можно выделить нужный фрагмент текста и скопировать его в буфер обмена, произвольный участок страницы сохраняется в картинку. Есть возможность установки закладок, запуска в режиме презентации и полноэкранном, вывод по одной или по две страницы, зуминг и поворот страницы. Каждый документ открывается в новом окне; если их много, это бывает неудобно. В целом весьма хороший просмотрщик для PDF-файлов, не сильно требующий ресурсов.

В репозитории можно найти еще несколько альтернатив. Наиболее современный из них — универсальный просмотрщик документов от проекта KDE Okular, кроме PDF поддерживающий PostScript, DjVu, CHM, XPS, ePub, CHM и некоторые другие форматы. По функциям он превосходит Evince, больше всяких возможностей по просмотру и навигации, есть даже настройки производительности, позволяющие установить оптимальный режим вывода документа в зависимости от мощности компьютера.
Плюс целый ряд легких просмотрщиков с минимальным интерфейсом, но не уступающих функционально, — ePDFviewer, XPDF, MuPDF, Zathura и другие. Например, Zathura и MuPDF вообще не имеют кнопок, управляются при помощи клавиш (все они описаны в man), а программы весят меньше сотни килобайт и летают даже при загрузке больших документов. В Zathura возможно сохранить текущую страницу в графический файл или сохранить изображение в буфер обмена.
Просмотр в консоли
С графической средой в общем все понятно, но бывает, что PDF-файл нужно прочитать в консоли, а ничего под рукой нет. Здесь два варианта — специальный просмотрщик, использующий framebuffer, и конвертирование файлов в другой формат (текстовый или HTML). Для первого случая нам понадобится просмотрщик изображений через фреймбуфер fbi и один из вьюверов PDF — fbgs (Framebuffer Ghostscript Viewer), который входит в состав пакета fbi или аналогов — FBPDF, JFBPDF. Кроме PDF, fbgs поддерживает и DjVu. Принцип работы прост — из страниц документа автоматически генерируется изображение, которое и выводится в консоль. Но нужно учесть, что работает этот способ для реальной консоли, в эмуляторе терминала запуск приведет к ошибке. Установка:
$ sudo apt-get install fbiДля просмотра пользователь должен быть добавлен в группу video:
$ sudo usermod -a -G video userТеперь можно смотреть:
$ fbgs file.pdfНекоторое время придется подождать, пока будут сгенерированы изображения.
Конвертация PDF
В большинстве программ с GUI PDF поддерживается при помощи библиотеки poppler, которая, в свою очередь, базируется на коде популярного просмотрщика xpdf. Кроме собственно библиотеки, проект предлагает 11 консольных утилит для работы с PDF-файлами, которые позволяют конвертировать PDF во всевозможные форматы (текст, HTML, PPM, PS, PNG, JPEG, SVG) и извлекать заголовок, вложения, рисунки и шрифты. Конвертеры pdftohtml и pdftotext как раз подходят для чтения файлов в консоли. В Ubuntu, как правило, эти утилиты уже установлены. Если выполнить, не указав имя выходного файла, или вывести на стандартный вывод, то в текущем каталоге будет создан файл с аналогичным именем и расширением txt или html, который затем можно открыть в любом редакторе или консольном браузере (например, Links или ELinks). Или просто прочитать:
$ pdftotext -layout file.pdf - | moreК слову, файловый менеджер Midnight Commander в некоторых дистрибутивах позволяет просматривать PDF-файлы. За это отвечает скрипт /usr/lib/mc/ext.d/doc.sh (описывается в /etc/mc/mc.ext). Если его просмотреть, то увидим, что по умолчанию файл конвертируется в текстовый как раз при помощи pdftotext и затем выводится на экран. Хотя возможны и другие варианты, поэтому стоит заглянуть в doc.sh.
Утилиты из poppler покрывают почти все основные форматы для конвертирования и некоторой обработки PDF-файлов. Так, PDF-файлы могут содержать вложения, утилита pdfdetach позволяет просмотреть их список и извлечь:
$ pdfdetach -list file.pdf
$ pdfdetach -saveall file.pdfАналогично одной командой извлекаются изображения.
$ pdfimages file.pdf images/Чтобы узнать информацию о встроенных шрифтах, следует запустить утилиту pdffonts.
В контексте можно вспомнить о SWFTools, содержащем несколько конвертеров в формат SWF (Small Web Format), включая PDF2SWF. Единственный момент, что пакет SWFTools в Ubuntu и некоторых других дистрибутивах не включает утилиту pdf2swf, поэтому ее приходится устанавливать из исходников:
$ pdf2swf in.pdf out.swfВ итоге получен SWF-файл, открыв который в веб-браузере или проигрывателе увидим периодически сменяющие друг друга страницы документа. Можно обработать лишь часть документа, указав номера избранных страниц с помощью опции --pages:
$ pdf2swf --pages 1,3-6 in.pdf out.swfЕсли не указать имя выходного файла, результат попадет в stdout. Параметр -C позволяет сгенерировать дополнительный HTTP-заголовок, что пригодится при размещении файла на веб-сервере.
Еще одна полезная утилита, распространяемая под Artistic License, — QPDF представляет собой конвертер PDF, позволяющий производить различные преобразования: оптимизацию для веба, шифрование/дешифрование, верификацию файлов, а также слияние и разделение. С ее помощью также можно создать PDF-файл программным способом, QPDF берет на себя все синтаксическое представление объектов, создание перекрестных ссылок таблицы, шифрование, линеаризацию и другие детали синтаксиса.
При обновлении версии Adobe Extension Level, которое используется при создании PDF-файлов в облаке компании Adobe, часто первое время невозможно такие файлы прочитать на программах, отличных от Adobe Reader. Здесь как раз и выручает QPDF (и некоторые другие утилиты обзора), достаточно снять с файла шифрование, и вопрос с чтением снимается. Смотрим свойства документа при помощи pdfinfo из комплекта poppler:
$ pdfinfo in.pdf | grep -i encrypted
Encrypted: yes (print:no copy:no change:no addNotes:no algorithm:AES-256)Снимаем шифрование:
$ qpdf --decrypt in.pdf out.pdf
$ pdfinfo in.pdf | grep -i encrypted
Encrypted: noТеперь с чтением проблем точно не будет. Если файл защищен паролем, то его следует указать при помощи параметра --password.
Объединение и разделение PDF
При работе с PDF очень часто возникает задача сборки файлов из частей отдельных документов или изменения отдельных параметров, таких как размер листа или ориентации (книжная или альбомная). Несложные скрипты позволяют сделать все нужное буквально одной командой, но для начала следует разобраться с базовыми утилитами.
Утилиты pdfseparate и pdfunite из poppler позволяют извлекать отдельные страницы и объединять документы. Причем среди других описанных далее они самые простые в использовании, так как не имеют большого количества опций, и с их работой легко разобраться. Например, извлекаем страницы с 10-й по 20-ю и сохраняем их в отдельный документ:
$ pdfseparate -f 10 -l 20 file.pdf file-%d.pdfВ имени переменная %d обязательна, так как pdfseparate умеет сохранять страницы только в отдельные файлы. Вместо него будет подставлен номер страницы, то есть в нашем случае получим файлы с именем file-10.pdf ... file-20.pdf. Если все же нужен единственный документ, то на помощь приходит pdfunite. Соберем страницы 10 и 11 в один документ:
$ pdfunite file-10.pdf file-11.pdf sample.pdfУ QPDF очень много параметров и возможностей, это практически универсальная утилита для обработки файлов формата PDF, причем многие операции выполняются одной командой. Например, можем сохранить в отдельный файл нужные страницы одного или нескольких источников:
$ qpdf in.pdf --pages in1.pdf 1-5 in2.pdf 20-31 -- out.pdfВ результате получим файл, собранный из полного документа in.pdf и указанных страниц документов in1.pdf и in2.pdf. Диапазон можно задавать через дефис или перечислить страницы через запятую. Возможен и реверс при помощи конструкции z-№страницы. Добавив параметр --linearize, сгенерируем оптимизированные для веба файлы. Специальный QDF-режим (--qdf) позволяет создавать PDF-файлы, которые затем можно редактировать в обычном текстовом редакторе, то есть без сжатия и шифрования, нормализованный и со специальными метками. Правда, и размер такого файла как минимум в два раза больше.
Иногда нужно просто сравнить две версии PDF-файла — текст, рисунки, вложения. Здесь помогут две прекрасные утилиты: diffpdf и comparepdf. В самом простом случае:
$ comparepdf file1.pdf file2.pdfНа выходе получим отличие. Если файлы одинаковы, то команда ничего не выдаст (опция «-v 2» сделает ее чуть болтливей). Diffpdf представляет собой GUI-программу, позволяющую произвести постраничную сверку документа. В случае отсутствия расхождения, после запуска будут показаны пустые поля.
$ diffpdf file1.pdf file2.pdf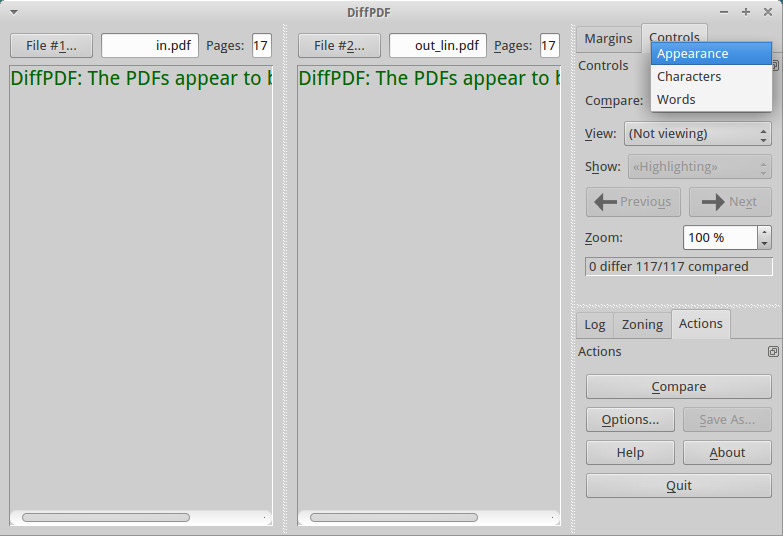
При необходимости в diffpdf можно задать диапазоны проверки. Это полезно, если, например, в документ добавлена страница, а поэтому постраничная проверка после нее точно покажет несоответствие.
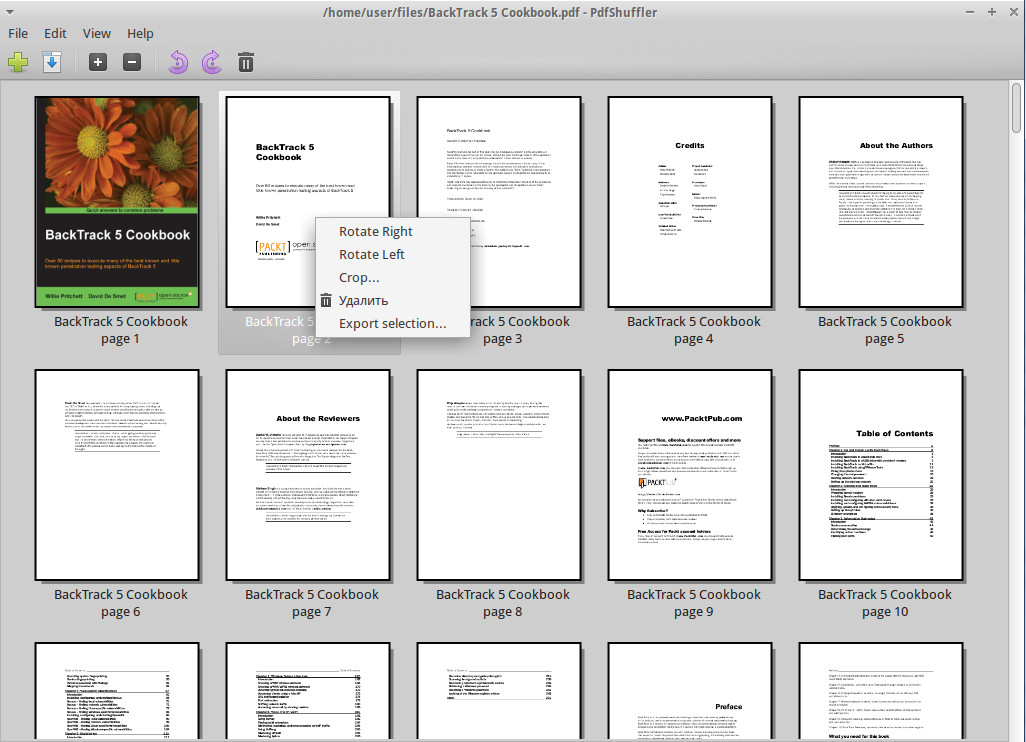
Не всем пользователям нравится разбираться с многочисленными параметрами и экспериментировать, некоторые предпочитают просто выбрать нужные операции в GUI. Нет проблем. PDF-Shuffler — небольшое Python-GTK приложение к Python-библиотеке pyPdf, предоставляющей все функции для работы с PDF: извлечение, слияние, обрезку, шифрование/дешифрование и прочее. Программа есть в репозитории дистрибутивов:
$ sudo apt-get install pdfshufflerИнтерфейс не локализован, но все, что требуется после запуска, — это кинуть файлы в окно программы, а после того, как будут отображены все страницы документа, при помощи меню удаляем, обрезаем, поворачиваем, экспортируем нужные. Если требуется произвести операцию с несколькими страницами сразу, то просто отмечаем их при нажатой клавише Ctrl, после чего сохраняем результат в новый документ. Быстро и очень удобно. Правда, как видим, PDF-Shuffler использует далеко не все возможности библиотеки, нет, например, оптимизации и шифрования/дешифрования, нельзя производить другие преобразования вроде изменения размера листа. Поэтому полностью консольные утилиты он не заменяет. Кстати, pyPdf, на котором базируется PDF-Shuffler, уже не развивается и сегодня в дистрибутивах, бывает, замещается форком PyPDF2, который полностью совместим с оригиналом плюс содержит несколько новых методов.
Среди альтернатив PDF-Shuffler можно выделить PDF Mod, легкое, очень простое в использовании приложение с локализованным интерфейсом, которое позволяет извлекать, удалять страницы, изменять их порядок, поворачивать, объединять несколько документов, экспортировать изображения в выбранной странице и редактировать информацию в заголовке документа (названия, ключевые слова, автор). Поддерживаются закладки. PDF Mod есть в репозитории:
$ sudo apt-get install pdfmod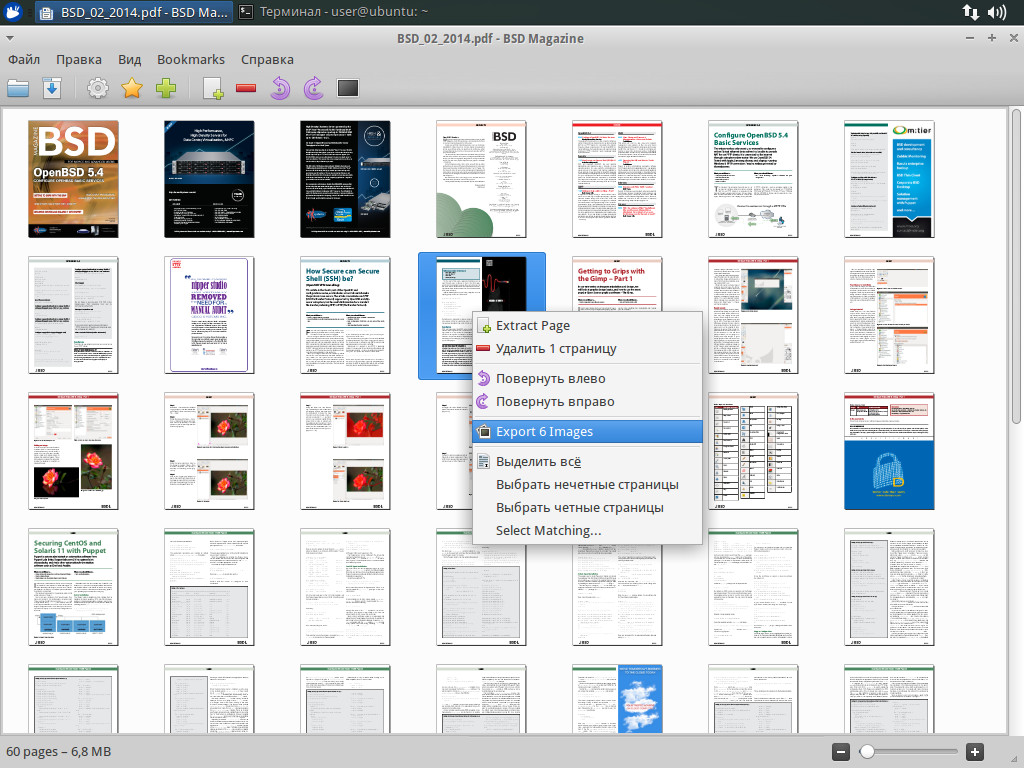
Кросс-платформенная утилита PDFsam — PDF Split And Merge, написанная на Java, умеет объединять, разрезать и поворачивать документы PDF. А в режиме burst генерирует из страниц PDF отдельные файлы. В репозитории далеко не самая последняя и весьма глючная версия. Новые релизы уже лишены многих недостатков, поэтому лучше ставить с официального сайта, но придется немного покомпилировать, так как без оплаты разработчики предлагают только сборку под Win и исходные тексты.
Редактирование PDF
PDF сам по себе сложный формат, предназначенный для издательской продукции, требующий специальных инструментов для создания и редактирования. И *nix-пользователям есть из чего выбирать. Создать PDF-документ можно в Open/LibreOffice, а чтобы получить возможность редактирования, следует установить расширение Oracle PDF Import Extension. Кроме этого, доступны специальные приложения — PDFedit, Scribus и Master PDF Editor. Среди них Scribus — очень мощное приложение со множеством функций, требующее времени на освоение.
Master PDF Editor — весьма простой инструмент, распространяемый бесплатно для некоммерческого использования. PDFedit позволяет производить любые операции по внесению исправлений в PDF-документы. Встроенные средства дают возможность редактировать текст и графику, но не дружат с таблицами. Возможна автоматизация при помощи ECMAScript-скриптов. К сожалению, PDFedit, использующий Qt 3, в текущей версии Ubuntu убран из-за отсутствия поддержки пакета libqt3-mt, а попытка установки не всегда удачна. Версия на Qt 4 пока находится в стадии разработки.
Утилита PDFtk
В контексте работы с PDF утилиту PDFtk Сида Стюарда (Sid Steward) хотелось бы выделить особо. Это даже не утилита, а комбайн «все в одном», позволяющий разделить или объединить несколько документов в один, расшифровать/зашифровать PDF-файл, добавить или удалить вложения, заполнить формы, восстановить поврежденные документы и многое другое. Вообще, разработчики предлагают несколько решений, основа всех — консольная утилита PDFtk Server, о которой речь дальше. Для пользователей Win разработчики предлагают GUI. Плюс доступны еще две утилиты: GNU Barcode Plus PDF для генерации штрих-кода в PDF-файл и платный STAMPtk, генерирующий водяные знаки и колонтитулы в PDF-файле. Пакет PDFtk уже есть в репозиториях дистрибутивов, поэтому с установкой проблем нет. Вместе с командой следует указать имя входных и выходного файла (поддерживается маска), команду и параметры. Всего поддерживается 18 команд, все они описаны в документации. Приведу лишь несколько примеров, достаточных для понимания сути работы с PDFtk. Например, команда cat позволяет объединить несколько файлов в третий — outfile.pdf:
$ pdftk in1.pdf in2.pdf cat output out.pdfЕсли файлов много, то проще собрать их в одном каталоге и использовать маску *.pdf. Отдельные страницы вырезаются просто указанием их номеров после cat:
$ pdftk in.pdf cat 10-20 output page3.pdfПричем, если файлов несколько, для каждого задаются свои страницы, при необходимости меняется ориентация.
$ pdftk A=in1.pdf B=in2.pdf cat A1east B2-20even output out.pdfВ примере из документа in1.pdf будет извлечена первая страница, которая будет повернута на 90 градусов. Со второго документа извлекаются только четные страницы в диапазоне 2–20. Четность возможно указать как even (четный) или odd (нечетный), поворот указывается как north, south, east, west, left, right или down. Последнюю страницу документа можно указать при помощи ключевого слова end. Диапазон указывается или прямо, как в примере, или реверсно (например, end-1). Чтобы разложить PDF на страницы, используется команда burst.
$ pdftk in.pdf burst output out%03d.pdfВ результате получим несколько документов вида out001.pdf. Иногда нужно подправить метаданные, оставленные в PDF другой программой. При помощи PDFtk это сделать легко. Для начала извлекаем исходные данные:
$ pdftk in.pdf dump_data output metadata.txtТеперь открываем и правим metadata.txt в текстовом редакторе, после чего загружаем обратно:
$ pdftk in.pdf update_info metadata.txt output incopy.pdfДешифровка PDF, о которой мы говорили выше, дело одной команды:
$ pdftk secured.pdf input_pw password output unsecured.pdfВосстановление PDF:
$ pdftk broken.pdf output fixed.pdf
Вывод
На самом деле это далеко не все утилиты для работы с PDF-файлами. Практически не затронут вопрос генерации PDF из различных источников. Но большинство решений легко найти в репозитории. Преобразование через PostScript дает еще большие возможности по управлению содержимым.