

Содержание статьи
А уходя от лукавых аналогий, можно назвать вот такие причины:
- Удобство в работе. Да, как ни странно, работать с инструментами терминала оказывается не менее, а иногда и более удобно, чем с супер-IDE, создатели которой решили за тебя, что и как ты должен делать в своем проекте. Не веришь? В далеком 2008 году я стал участником нежданного эксперимента. Мы с моим коллегой занимались тогда портированием на Python и C кода, написанного специалистом-«предметником» в Matlab. Мой коллега писал в Eclipse, я — в Notepad++, запуская в консоли интерпретатор Python или make. Для автоматического тестирования мы оба использовали набор контрольных примеров. Квалификация, работоспособность, рвение обоих программистов были сопоставимы, прибавим к этому еще желание обогнать соперника. В итоге ни один из нас не показал превосходства в скорости разработки или качестве кода. IDE — не серебряная пуля, серебряной пули нет.
- Мобильность при смене проекта или области деятельности. Это я опять сужу по себе. Три года назад я сделал большой проект на Qt под RHEL. Сегодня занимаюсь Embedded, а инструменты все те же: screen, vim, ctags, coreutils, make.
- Долгосрочные перспективы. Судьба проекта не должна быть связана с судьбой IDE. Где былое доминирование Delphi или Eclipse? Многие в опенсорсе стараются не зависеть от конкретной IDE, особенно проприетарной.
- Опенсорсные проекты. Впрочем, кажется, я уже это говорил. Включая (на минуточку!) и AOSP — Android Open Source Project. Кто владеет приемами разработки без IDE — берет и работает. Кто не владеет — строчит на форумы «Мужики, помогите, СРОЧНО ОЧЕНЬ НАДО импортировать AOSP в xyzStudio!11».
- Работа на слабом железе. Современные IDE «как не в себя» кушают память, процессор, требуют для комфортной работы гигантских размеров монитор, а лучше — «дайте два». Это не проблема, пока ты сидишь в уютном офисе в эргономическом кресле за большим и чистым столом. Это проблема, когда ты работаешь в командировке в тьмутаракани, в кабине внедорожника, или в салоне самолета, или в вагоне электрички с 10-дюймовым субноутбуком на коленях.
- Удаленная работа над проектом. Да, конечно, тут есть альтернативы: TeamViewer, TigerVNC. Со своими, конечно, проблемами.
- Психологический аспект. Повышает уверенность в своих силах, «а я, оказывается, не просто мышевод-клаводав, я же настоящий хацкер, итить!».
Screen (или Tmux)
Первый инструмент, который мы рассмотрим, — screen. Он играет ту же роль, что оконный менеджер в мире GUI: управляет несколькими приложениями, позволяя переключаться с одного на другое. В консольной вселенной такие инструменты называются терминальными мультиплексорами. Пожалуй, из всех оконных менеджеров ближе всего к screen будет легендарный ratpoison, позволяющий обходиться одной лишь клавиатурой, без мыши.
Управляют screen с помощью хоткеев. Но раз приложений несколько, а клавиатура одна, надо «дать понять» системе, к кому именно мы обращаемся: к самому терминальному мультиплексору или к приложению. Поэтому все команды screen предваряются аккордом (клавиатурным сочетанием) Ctrl^a. Наиболее распространенные команды привязаны к горячим клавишам, для менее частых нужно перейти в командную строку screen командой : (то есть нажать Ctrl^a, а затем :).
Пример: запускаем screen, видим баннер с предложением нажать пробел или ввод для продолжения работы. Воспользуемся любезным предложением — баннер исчезает, мы снова в терминале. Открываем в Vim (про него будет дальше) файл main.cpp.
vim main.cpp
Мы редактируем файл main.cpp. Ctrl^a, затем Ctrl^c. Мы опять в терминале, а куда пропал Vim? Ничего никуда не пропало, данная комбинация клавиш открывает новый терминал («окно» в терминологии screen). Для возвращения в предыдущий терминал, где открыт Vim, нажимаем Ctrl^a, затем еще раз Ctrl^a.
Не хотелось бы превращать статью в сборник переводов man’ов, поэтому приведу здесь только самые нужные в повседневной практике команды и аккорды (здесь и далее, говоря о screen, начальный аккорд Ctrl^a я для краткости буду опускать):
Ctrl^c— открыть новое окно;Ctrl^a— переключиться в предыдущее окно. Аналогичную функцию в мире GUI выполняет клавиатурная комбинацияAlt^Tab. Очень удобна, чтобы переключаться туда-сюда между парой окон, например редактором и командной строкой (впрочем, нормальный консольный редактор позволяет выполнять команды командной строки еще проще);x— заблокировать screen (для разблокировки придется ввести пароль);k— закрыть текущее окно (меня эта команда не раз выручала, когда в текущем окне зависало в томной задумчивости подключение к очередной железке по SSH или Telnet);"— открыть список окон, чтобы переключиться в одно из них;'— ввести имя окна, в которое хочешь переключиться (про то, как задать имя окна, чуть ниже);?— вывести справку. В общем, мало чем отличается от горячих клавиш оконного менеджера или IDE;Esc— перейти в режим копирования. Я использовал эту штуку исключительно для пролистывания содержимого окна, чтобы посмотреть, а что там было N строк назад. Выход из режима копирования — по нажатиюEsc(без предшествующегоCtrl^a);S— (NB! заглавная буква) разделить экран на две половины (два «региона» в терминологии screen). Текущее окно остается в верхнем регионе, в нижнем изначально ничего нет вообще, но, переключившись в этот регион поTab, можно назначить ему одно из уже открытых окон или открыть новое;Tab— переключение («по кругу») между регионами;Q— закрыть все регионы, кроме текущего. При этом регионы закрываются, но сами окна остаются, и в них можно переключаться;X— закрыть текущий регион.

Регион можно еще раз разделить напополам, потом еще, и так до тех пор, пока будет хватать высоты экрана.
Высоту регионов можно регулировать, например нижний урезать до двух строк для ввода, а все остальное отдать для вывода какой-нибудь программы, работающей в режиме мониторинга. Операция эта не настолько частая, чтобы заводить для нее отдельную клавиатурную комбинацию, поэтому для нее используется команда resize, которая вводится в командной строке screen: :resize размер-в-строках.
Можно задать увеличение/уменьшение размера, для этого вводим число со знаком + или -: :resize +10 увеличит размер текущего региона на десять строк, :resize -5 уменьшит размер региона на пять строк.
Если тебе чуть-чуть повезло и у тебя достаточно свежая версия screen, то можно разделить экран по горизонтали клавишей |. На самом деле для современных растянутых по горизонтали мониторов это даже более удобно. Можно комбинировать деление экрана по горизонтали и вертикали, но это, по моему опыту, уже не очень-то нужно.
Чуть выше я говорил, что окну можно назначить имя. Делается это командой :title имя. У меня сейчас обычно «живут» окна с именами src (тут открыт Vim с исходным кодом), uart (подключение к подопытному девайсу по последовательному порту), adb (подключение к подопытному девайсу по ADB), build (запуск сборки). При переключении по клавише ' полное имя вводить не нужно, достаточно набрать первые буквы (sr, ua, ad, bu).
Ну и чтобы закончить со screen, упомяну про отключение. Screen завершается, когда закрывается последнее из его окон. Кроме того, можно выйти из screen, оставив все окна работающими в фоне, командой :detach (также на эту команду по умолчанию назначена клавиша d). Позднее к этому сеансу screen можно будет подключиться снова. Обычно такая фича полезна при работе с удаленной машиной.
И совсем напоследок: случается, что мантейнеры дистрибутива или пользователь конкретной системы меняют одну или несколько клавиатурных комбинаций по умолчанию (в моем опыте была чехарда с клавишей X при переходе с RHEL6 на Debian). Смотри конфигурационные файлы screenrc и, конечно, кури доки (специально для РКН: я в переносном смысле).
Vim: великий и могучий
Кстати, почему Vim, а не Emacs? Поклонники последнего могут закидать меня гнилыми помидорами, но вот не пошел он у меня почему-то, хотя я и старался. Кроме того, по моему субъективному опыту, Vim, точнее его предок, Vi, идет «из коробки» на большинстве современных Linux-систем: встроенных, настольных, серверных. Приятно везде чувствовать себя как дома.
Интерфейс Vim модальный (отец современного UI Джеффри Раскин переворачивается в гробу) и может находиться в двух режимах (вообще-то их больше, но нам пока хватит этих двух): режиме вставки и командном режиме.
После запуска Vim будет в командном режиме: все введенное с клавиатуры считается командами. Самые распространенные команды привязаны к различным клавиатурным комбинациям, менее частые вводятся в командной строке (в терминологии Vim это считается отдельным режимом и называется режимом командной строки).
Перейти в режим вставки из командного режима можно разными способами, самый простой из которых — нажатие i; перейти в режим командной строки из командного режима можно только нажатием :. Выход обратно в командный режим — по нажатию Esc или Ctrl^[.
Сразу бросается в глаза, что создатели Vim считают основным командный режим. При этом большая часть вводимых команд — составные, то есть состоят (или могут состоять) из нескольких частей: числа повторов, действия и позиции.
Возьмем, например, команду d (delete). daw (запоминается мнемоникой delete-a-word) удаляет слово в позиции курсора; причем d — действие (delete), а aw — позиция. 3daw удаляет три слова, начиная с позиции курсора; обращаем внимание на цифру 3 в начале — это, как ты уже, конечно, догадался, число повторов. 4dl удаляет четыре знака, начиная с позиции курсора; 4 — число повторов, d — delete, l — перемещение курсора вправо (в командном режиме Vim для перемещения курсора можно использовать не только курсорные клавиши стандартной PC-клавиатуры, но и команды h, j, k и l).
Да, работать в Vim надо учиться, примерно так же, как учатся играть на пианино, запоминая сочетания клавиш и доводя работу пальцев до автоматизма. Но когда изучишь... Можно, например, сравнить различные способы правки в Vim и в «обычном» текстовом редакторе. Удаление слова в позиции курсора: в Vim — daw, в «обычном» редакторе — переместить руку на мышь, двойным кликом выделить слово, вернуть руку на клавиатуру, нажать Backspace. Удаление текста в позиции курсора до конца строки: в Vim — D, в «обычном» текстовом редакторе — переместить руку на мышь, нажать левую кнопку, удерживая, довести до конца строки, вернуть руку на клавиатуру, нажать Backspace. Поменять местами соседние символы в позиции курсора: в Vim — xp, в «обычном» текстовом редакторе... ну, ты понял.
Чем иногда бывает удобен «мышиный» интерфейс, так это возможностью быстро переместить курсор в середину текста: щелк — и готово. Но и тут Vim есть чем ответить: команды перемещения в конец слова, предложения, абзаца, быстрое перемещение по номеру строки (:номер-строки), переход по поиску (/шаблон). В качестве шаблона поиска может использоваться и точное совпадение, и регулярное выражение. Регулярные выражения в Vim действительно хороши, лучше, по-моему, только регулярки Perl.
В режиме вставки функционирует ненавистный сердцу каждого олдскульного программера автокомплит, вызываемый по нажатию Ctrl^p. Да, Vim — всего лишь текстовый редактор, а не компилятор, и того, кто привык к IntelliSense в какой-нибудь ass-studio, он, мягко говоря, разочарует. С другой стороны, для грамотного программера, который привык думать и читать доки, а не слепо доверять подсказкам IDE, проблемы это не составит.
Vim поддерживает концепции областей экрана, аналогичных регионам screen (в терминологии Vim эти области называются окнами), вкладок (тут объяснять ничего не требуется) и буферов — не обязательно имеющих визуальное представление, возможно отображение на множество вкладок или окон.
По-настоящему крутая возможность Vim — интеграция с утилитами командной оболочки:
:! имя-утилиты— вызвать нужную утилиту и отобразить ее вывод. При этом обеспечивается полноценная работа с интерактивными утилитами, например git:
:r! имя-утилиты— вызвать нужную утилиту и вставить ее вывод в позицию курсора. Очень хороша для работы с find и grep.
Например, мы хотим найти в исходниках ядра Linux все файлы, которые имеют какое-либо отношение к mmc:
:vnew
:r! find linux -name '*mmc*' -type f
Если этот «файлнайдись» тебе не совсем понятен:
find— стандартная утилита командной оболочки, ищущая файлы по заданным критериям;linux— имя каталога, в котором нужно искать (если не задано, то текущий каталог);-name— критерий поиска (по имени);'*mmc*'— шаблон поиска;-type— еще один критерий поиска (поиск по типу файла);f— искать только обычные файлы, то есть исключить каталоги, специальные файлы и прочее.
Теперь ПК с полминуты пошуршит диском и вставит в окно с полторы сотни файлов.
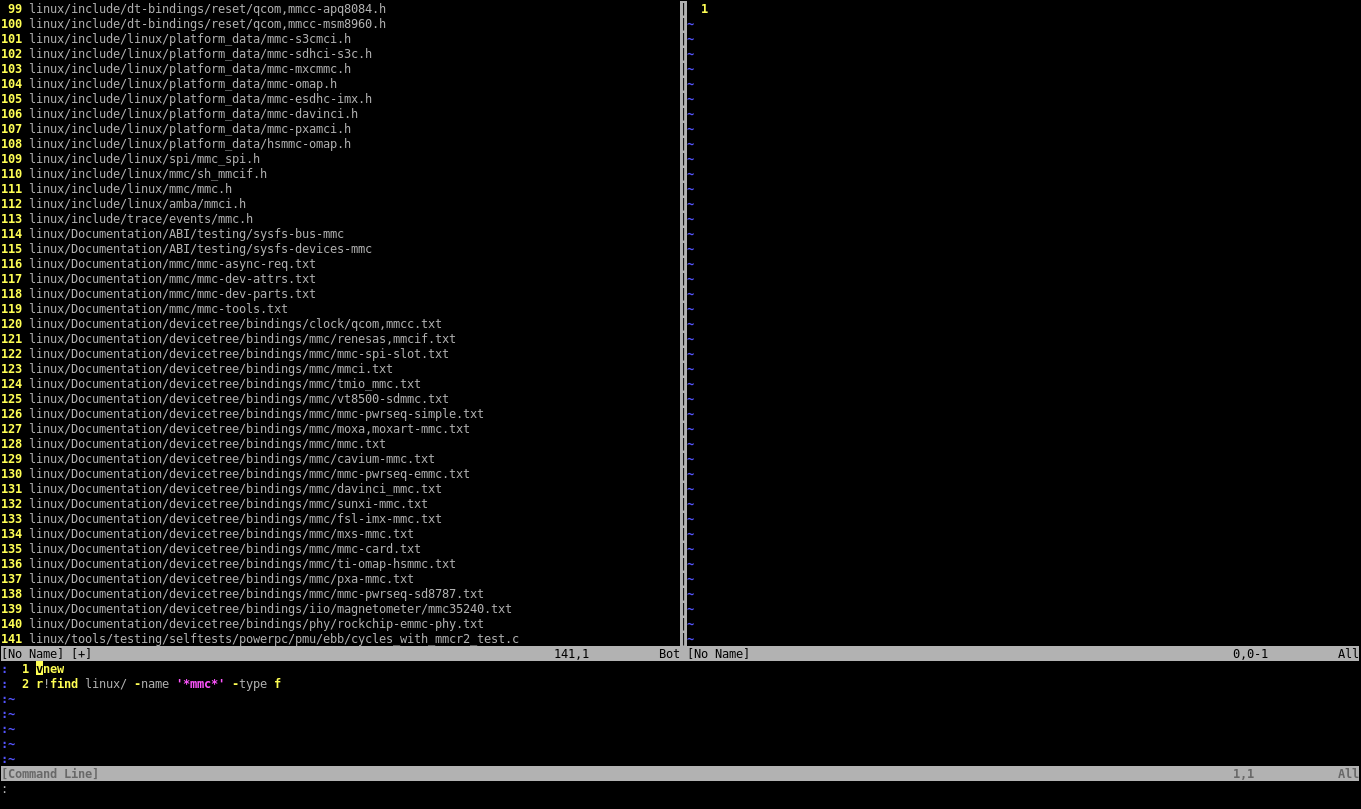
Сразу же можем удалить из списка файлы из каталогов Documentation и tools:
:115,142d
Это уже режим командной строки. Вот объяснение «на пальцах» конкретно этой команды: d, очевидно, означает delete, то есть удалить (строку); 115,142 — начальный и конечный адреса применения команды. В качестве адреса может использоваться номер строки или регулярное выражение.
:44 — переходим в строку с нужным номером, теперь нажимаем gf (легко запомнить: go-file).
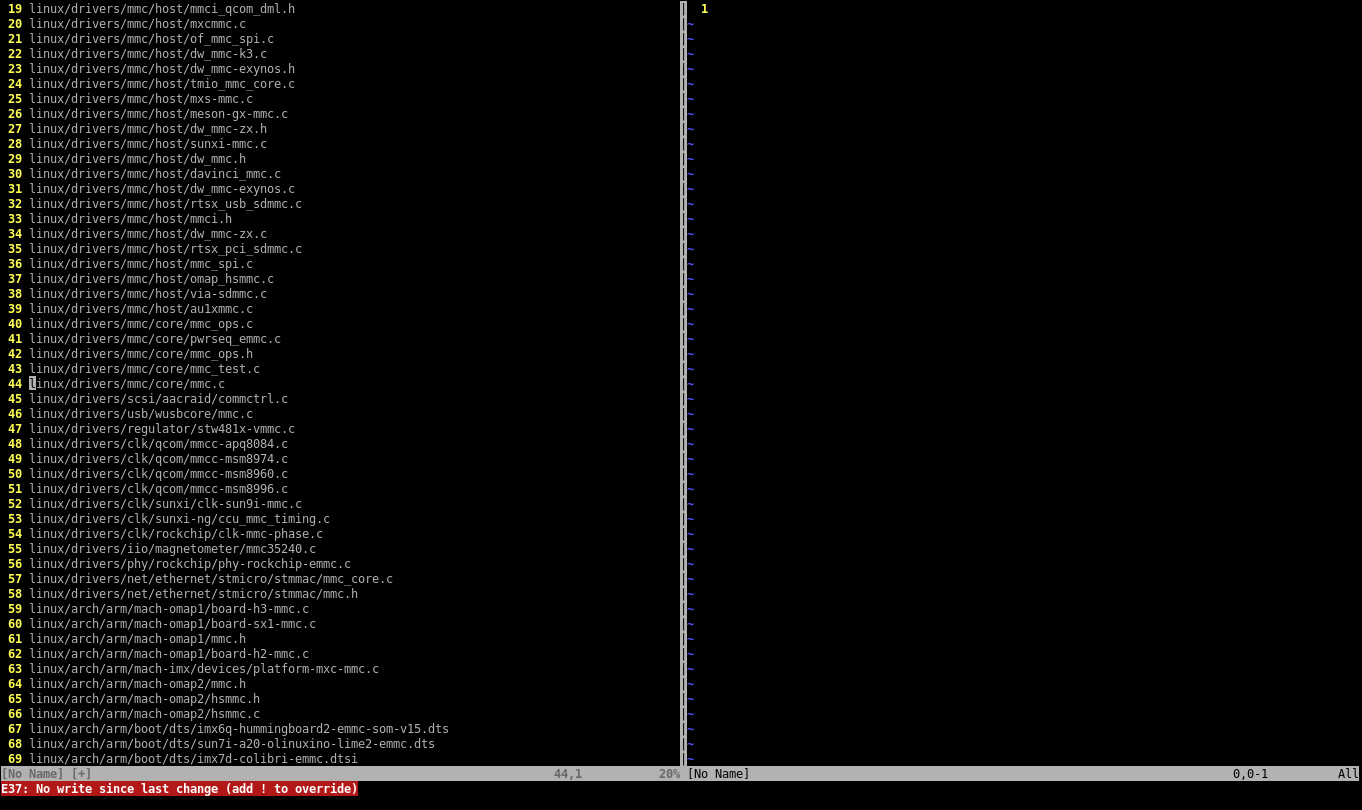
И Vim пишет, что файл был изменен, поэтому перейти нельзя. Печаль... По умолчанию Vim не разрешает переключать окно на отображение другого буфера, если текущий буфер в этом окне был изменен. Но это контролируется командой командной строки Vim :set hidden. Выполняем, снова пробуем gf. Порядок!
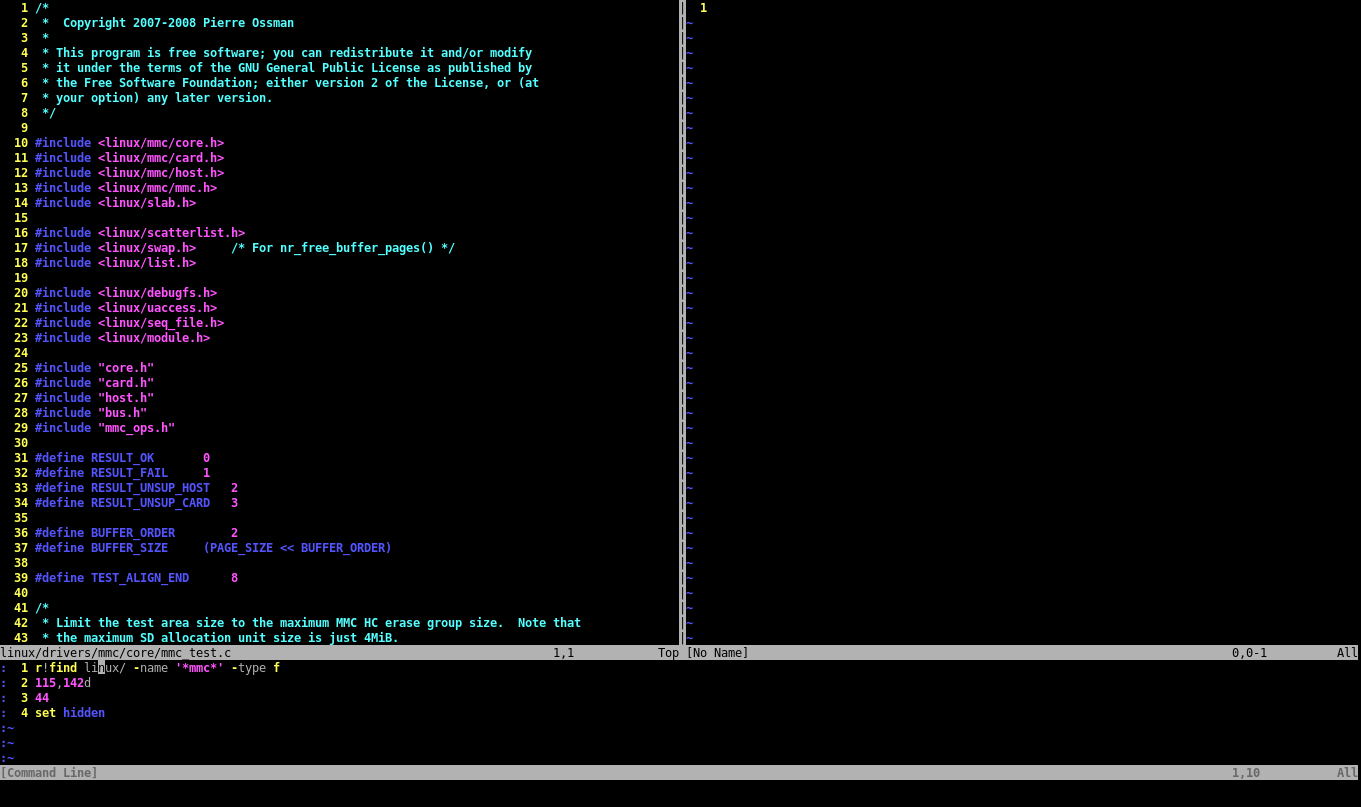
Теперь, предположим, мы хотим найти все места, где используются функции из целевого файла. Для этого возьмем утилиту командной оболочки grep, а ее результат прочитаем в новое окно Vim:
:vnew
:r!egrep -Rne '\bmmc_(select_card|deselect_cards|set_dst|go_idle|send_op_cond|set_relative_addr|send_(csd|status|cid)|spi_(read_ocr|set_crc)|bus_test|interrupt_hpi|(can|get)_ext_csd|switch_status|switch|(start|stop)_bkops|flush_cache|cmdq_(enable|disable))\b' --include '*.h' --include '*.c'
Да, еще одна регулярка (без них в наше время программисту никуда), по которой утилита egrep ищет в файлах лексемы mmc_select_card, mmc_deselect_card, ну и так далее. Для ускорения процесса (лексемы могут найтись и в составе исполняемых файлов, но вряд ли это то, что нам нужно) используются опции --include, они указывают утилите egrep искать только в файлах, имена которых соответствуют шаблону. Кстати, с опцией --include надо быть очень аккуратным: тебе могут попасться имена файлов на C++ с расширениями .cpp, .hpp, .cxx, .hxx, и даже .c++ (да, никогда бы не поверил, если бы сам не увидел).
Ну хорошо, а если, изучая исходники, ты обнаружил неизвестную функцию и хочешь посмотреть ее определение? В большинстве IDE для этого ты кликаешь с зажатым Ctrl. Vim делает то же по нажатию Ctrl^]. Правда, ему в этом требуется помощь утилиты ctags. Утилита ctags создает файл с именем tags — индекс функций, глобальных переменных, определений классов, структур, макросов... Короче, всего, что надо. По нажатию Ctrl^] Vim читает файл tags, ищет в нем местоположение лексемы, находящейся под курсором, после чего открывает в текущем окне нужное место нужного файла.
Прекращая «дозволенные речи» ©, традиционно рекомендую читать доки (в Vim есть встроенный help, вызываемый из режима командной строки :help) и другую литературу. По Vim написано уже много отличных статей, в том числе и на ][акере, и книг. «Практическое использование Vim» Дрю Нейла, пожалуй, лучшая из всех, которые мне попадались.
Конвейеры
Ты наверняка слышал про «философию UNIX», которая учит нас, что программа должна делать только одно дело, зато хорошо. Для решения сложных задач небольшие специализированные приложения нужно соединить между собой и заставить взаимодействовать.
Есть три типовых способа взаимодействия программ в командной оболочке: стандартные потоки ввода-вывода, аргументы командной строки и переменные окружения. При запуске программа разбирает аргументы и переменные окружения, настраивая в соответствии с ними свое поведение, после чего читает данные со стандартного входа (а иногда еще из некоторых других файлов на диске) и выводит результаты в стандартный выход. «В любой непонятной ситуации» © программа выводит сообщение об ошибке в стандартный поток ошибок. Для соединения программ командная оболочка предоставляет нам следующие средства:
- конвейер, он же пайп (pipe), он же «палка», соединяет стандартный выход одной программы со стандартным входом другой программы;
- подстановка команды, считывает стандартный выход программы и превращает его в строку;
- подстановка процесса, представляет стандартный вход или стандартный выход программы в виде временного файла, который другая программа может открыть для чтения или записи;
- присвоение переменной окружения значения отдельно для запуска программы. Переменная окружения не сохранит присвоенное значение после завершения программы, так что ты не рискуешь нарваться на нежелательные эффекты, связанные с изменением контекста.
Из всех утилит, которыми GNU облагодетельствовали человечество, программисту чаще всего нужны следующие:
find— поиск файлов, соответствующих одному или нескольким критериям;grep— фильтрация строк в тексте по регулярному выражению;awk— обработка текста табличного формата;- узкоспециализированные утилиты:
curl,wget,vim,git,netcat,hexdump.
Ладно, это все теория, пора и к практике. Первый случай — применение конвейера. Выше мы уже видели пример чтения стандартного выхода утилиты find в Vim. Вот те же самые Фаберже, вид сбоку:
$ find linux -name 'mmc*.[hс]' -type f | vim -
Конвейер (символ |) разделяет две команды — find и vim. Лучше будет сказать, что он их соединяет! Стандартный выход утилиты find — список найденных в каталоге linux файлов, имена которых начинаются с mmc и заканчиваются суффиксом .h или .c, — передается на стандартный вход Vim. Да, у Vim тоже есть стандартный вход. В качестве аргументов командной строки Vim обычно получает имена файлов, но сейчас там символ -, что означает «прочитать все данные со стандартного входа» (кстати, подобное обозначение понимают многие утилиты).
Хорошо, но список файлов сам по себе нам, скорее всего, не нужен. Как правило, нам требуется открыть эти файлы в текстовом редакторе:
$ vim -p -- $(find linux -name 'mmc*.[hc]' -type f)
Это уже пример подстановки команды. Утилита find генерирует нужные нам имена файлов. А выражение $(...), окружающее find, — это и есть подстановка команды, подставляющая стандартный выход find в качестве параметров командной строки Vim. Опция -p при вызове Vim означает, что найденные файлы нужно открывать в отдельных вкладках, а опция -- — что опций больше не будет и за ней следуют только имена файлов. Число вкладок в Vim ограничено десятью, так что, если команда find найдет слишком много файлов, будет видна только часть из них, остальные не отобразятся (но на них можно переключиться при необходимости, :help buffers Vim тебе в помощь).
Внимательный читатель скажет, что так делать нельзя, ведь имена файлов или каталогов могут содержать пробелы, табуляцию или переводы строки. Допустим, файл с именем mmcugly.h находится в каталоге с именем my ugly (внимание на пробел!), тогда в выводе команды find среди прочего появится my ugly/mmcugly.h. Vim, увы и ах, воспримет это как два разных (несуществующих) файла: один с именем my, другой с именем ugly/mmcugly.h.
Формально оно, конечно, так, но, как правило, такие имена не используют даже те программисты, которые пишут комментарии кириллицей, а идентификаторы транслитом.
Следующий пример. Допустим, проект находится под контролем Git (ты ведь регулярно используешь Git, правда ведь?) и ты хочешь открыть все файлы, которые были изменены:
$ vim -p $(git status -s -uno | awk '{print $2}')
Опять подстановка команды, точнее конвейера из двух команд. git status -s -uno, как тебе должно быть известно, выводит состояние файлов проекта; опция -s указывает краткий формат вывода, то есть в виде таблицы, в которой первая колонка содержит состояние файла, а вторая колонка — имя файла; опция -uno указывает игнорировать файлы, которые не находятся под контролем git, — это чтобы Vim не пришлось открывать многочисленные артефакты сборки проекта (да, при правильно сделанном .gitignore это не очень актуально). Вторая, awk '{print $2}', считывает построчно вывод первой и из каждой строки выводит только вторую колонку. Ну а то, как подстановка команды передает все это Vim в качестве аргументов командной строки, пояснять, я думаю, не нужно (про возможные «нетрадиционные» имена файлов уже говорилось выше).
Одна из самых важных утилит — grep. Она настолько важна, что даже породила в профессиональном арго глагол «грепать». Grep проводит поиск по регулярному выражению, а нюансы ее использования заключаются в том, где она ищет и как выводит результат. По умолчанию grep ищет совпадения с регулярным выражением в строках, которые читает из стандартного входа, но нам это не очень-то интересно. Гораздо полезнее способность grep рекурсивно обходить содержимое каталога, находя совпадения в файлах. Вот, например:
$ egrep -Rne '\bmmc_select_card\b' linux --include '*.h' --include '*.c' | vim -
Нет, это не дежавю, кое-что похожее мы видели раньше, только тогда grep вызывался из командной строки Vim, а сейчас мы делаем то же самое средствами командной оболочки. Пожалуй, более удобный вариант для получения списка файлов выглядит немного иначе:
$ egrep -Rle '\bmmc_select_card\b' linux --include '*.h' --include '*.c' | vim -
Опция -l указывает grep выводить только имена файлов, при этом поиск в файле завершается после первого же совпадения, чтобы не дублировать результаты.
Кое-кто предпочитает вместо списка файлов сразу же видеть фрагменты кода:
$ egrep -Rne '\bmmc_select_card\b' linux -C 3 --include '*.h' --include '*.c' | vim -
Здесь задействована интересная опция -C, которая предписывает grep вывести не только строчку с совпадением, но и контекст (в данном случае — три строки сверху и три снизу от строки, совпавшей с регулярным выражением).
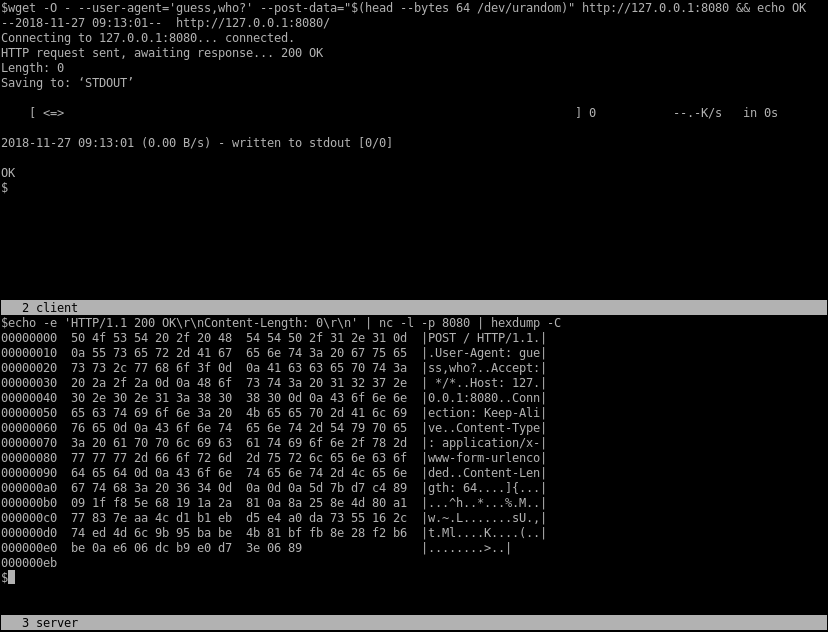
Ну и чуть-чуть о сетевых приложениях. Вот еще один реальный случай из практики. Имеется небольшая программка, которая отсылает POST-запрос на HTTP-сервер. Как можно посмотреть отправляемые запросы и вообще отладить взаимодействие с сервером «на коленке»? Восторженный школяр предложит поднять lighttpd с самописным CGI-скриптом или замутить сервер на Python Tornado. Начитавшийся Бека и Мартина пурист будет горой стоять за стенд с моками. Программист-минималист сделает все гораздо проще, в одну строчку в консоли:
$ echo -e 'HTTP/1.1 200 OK\r\nContent-Length: 0\r\n' | nc -l -p 8080 | hexdump -C
И все. Если ты еще незнаком с замечательной утилитой nc (netcat, не путать с Norton Commander), то самое время познакомиться. Netcat позволяет установить соединение и передать данные по TCP, UDP или даже через Unix Domain Sockets. Здесь она запускается как TCP-сервер (об этом говорит опция -l), который прослушивает порт 8080 (опция -p), выводит принятые по сети данные на свой стандартный выход и передает в сеть данные, принятые по стандартному входу. А на стандартный вход у него поступает стандартный выход команды echo, производящий вполне корректный ответ на POST-запрос.
Поскольку POST-запрос в данном конкретном примере мог содержать двоичные данные, стандартный выход netcat перенаправляется на стандартный вход утилиты hexdump. hexdump выводит двоичные данные, поступающие на ее стандартный вход, в удобочитаемой форме на свой стандартный выход. Удобочитаемая форма у каждого своя, и hexdump поддерживает разные форматы представления. Формат, задаваемый опцией -C, пожалуй, самый удобный и общеупотребительный, так что даже удивительно, что он не является форматом по умолчанию.
Внимательный читатель снова может заметить, что мы тут занимаемся явным шулерством: отправка запроса и ответа никак не синхронизированы, и наш «однострочник» посылает ответ в тот момент, когда запрос еще полностью не прочитан. Да, это так! Конечно, скрипт можно еще доработать, но стоит ли оно того? У каждого инструмента свое предназначение. Описанная техника проста, незатейлива и применима в самых простых случаях. А nginx «своими руками, за пять минут, из г... и палок, без регистрации и SMS» никто и не обещал.
Как видишь, конвейер и подстановка команды — это, пожалуй, самые частые приемы в практике программиста-консольщика. Подстановка процесса... Помнится, как-то один раз она меня и в самом деле выручила, но подробности уже, увы, стерлись из памяти.
Что же до присвоения переменной, то лично мне оно чаще всего требовалось, чтобы отлаживать на встраиваемых платформах подпиленные руками суровых русских кулхацкеров системные библиотеки. Например, нам нужно отладить доработанную библиотеку libc на устройстве с файловой системой «только для чтения». Пересобирать и перезаливать прошивку? Еще чего! При помощи adb/netcat/tftp/как-нибудь-еще заливаем libc.so в каталог /tmp, к которому примонтирована tmpfs. Ну и делаем вот так:
$ LD_LIBRARY_PATH=/tmp тестовое-приложение
Здесь мы задаем запуск нашего тестового приложения в окружении, с особо установленной переменной LD_LIBRARY_PATH. Переменная окружения LD_LIBRARY_PATH задает каталог, в котором система будет искать динамические библиотеки прежде всего (в данном случае — каталог /tmp). Таким образом, при запуске тестовое приложение будет использовать нашу версию динамической библиотеки libc.so, находящуюся в каталоге /tmp.
Loving make — making love
Все кодеры делятся на три категории: те, кто ничего не знает о make, те, кто пишет make-файлы, и те, кто уже не пишет make-файлы. Принадлежащие к двум последним категориям могут смело пропустить парочку абзацев.
make — утилита, которая выполняет сборку приложения, — лежит в основе процесса сборки большинства открытых (и, наверное, кое-каких закрытых) проектов. Включая, например, AOSP или Buildroot. Да, прошивка твоего телефона и твоего роутера собраны при ее непосредственном участии (если ты, конечно, не член секты джобстеров).
Философия make проста, как грабли: артефакты сборки (например, исполняемый файл приложения), называемые в терминологии make целями, зависят от файлов и других артефактов сборки (например, .o-файлов). Зависимость может иметь свои зависимости (.o-файл зависит от .c-файла), и так ad infinitum. Чтобы из зависимости получить цель, нужно выполнить набор действий — рецепт. Make сравнивает временные отметки файлов целей и зависимостей: если цель новее любой из своих зависимостей, то make считает, что ничего делать не нужно. Проверка, естественно, выполняется рекурсивно, то есть проверяются зависимости зависимостей, зависимости зависимостей зависимостей — ну, ты понял. Просто и незатейливо и не слишком защищено от хаков: например, если поменять файл с исходным кодом, а потом выполнить команду touch для цели, make все равно будет думать, что сборка уже выполнена.
В принципе, имя цели может быть произвольным, но исторически сложился набор правил именования: например, цель, выполняющая действия по умолчанию, обычно называется all, цель, выполняющая установку, — install, цель, выполняющая очистку рабочего каталога от артефактов сборки, — clean.
Цели, зависимости и рецепты описываются в специальных конфигурационных файлах, называемых make-файлами. По умолчанию make ищет в текущем каталоге make-файлы с предопределенными именами GNUMakefile, makefile и Makefile. Как правило, используется последний вариант имени (в документации make рекомендуется именно он). Но иногда некоторым хочется странного — и в ход идут make-файлы с нестандартными именами, типа Makefile.windows.wix. Как правило, такие файлы запускаются из какого-нибудь скрипта или другого make-файла, но, если уж приперло, можно задать утилите make имя make-файла при помощи make -f имя-файла.
Только что узнавший о make обычно кидается писать собственные make-файлы под любые свои нужды. И... быстро бросает: синтаксис make неудобоварим (чего стоит хотя бы требование использовать строго Tab’ы для выделения тела рецепта), да и не все задачи на свете укладываются в схему цели — зависимости — рецепт. Большую часть make-файлов сейчас пишут не люди, а кодогенераторы: qmake, cmake, autotools. Они умеют обращаться с разными платформами, версиями компиляторов. А make-файлы — воспринимай их как низкоуровневый язык вроде ассемблера: уметь разбираться в нем весьма полезно, но делать это приходится лишь изредка. Чаще же всего программист-консольщик просто запускает сборку, а make «просто работает».
Во время работы make выводит в свой стандартный выход каждую выполняемую им команду и перенаправляет туда же ее стандартный выход. Иногда это удобно: видно, что машина и ее хозяин не дурака валяют (тут будет картинка «Почему не работаете? — Так ведь компилируется!»), но чаще мешает: в потоке сообщений make легко пропустить предупреждение компилятора. Для — к сожалению! — многих больших опенсорсных проектов это несущественно: предупреждения о сужающих преобразованиях, неиспользуемых переменных и сравнении беззнаковых типов со знаковыми там сыплются как горох, и с этим трудно что-либо поделать, но вот для своего выстраданного и вылизанного кода всегда хочется (и у хорошего кодера не только хочется, но и можется) получить кристальную чистоту рядов кода. Некоторые используют перенаправление: make > /dev/null . При этом стандартный выход уходит прямиком в «черную дыру» /dev/null, а предупреждения, выводимые в стандартный поток ошибок, остаются на месте и прекрасно видны. Но на этот случай у make есть опция -s : make -s позволяет добиться ровно того же эффекта.
Впрочем, при компиляции программ на C++ (ну и иногда на C) порой не спасает даже это: компилятор, споткнувшись на одной ошибке, вываливает на программиста целый пучок сообщений о самых разнообразных непонятках (как-то читал у Майерса, как одна опечатка вызвала у компилятора 200-строчный «крик о помощи»), а релевантно из сообщений только первое, ну а остальные... Самое приличное, что про них можно сказать, — так это то, что их следует просто проигнорировать. Помогут в этом конвейер и утилита head:
$ make 2>&1 >/dev/null | head
Здесь мы перенаправляем стандартный поток ошибок в стандартный выход, а сам стандартный выход — в /dev/null. Утилита head читает со своего стандартного входа и перенаправляет на свой стандартный выход небольшое (по умолчанию — десять) число строк, отбрасывая все последующие.
Пожалуй, последняя из полезных опций команды make — опция -C. Аналогичная опция (иногда даже с тем же именем) есть у git, tar и еще некоторых утилит, и означает она «выполнить утилиту в указанном рабочем каталоге»: make -C новый-рабочий-каталог. Например, в проекте, состоящем из нескольких подпроектов, выполнить сборку одного из них. Увы, в больших проектах вроде Buildroot такой «ручной закат солнца» обычно «не стреляет» — сборка подпроекта, как правило, требует еще и установки кучи переменных окружения, например пути к компилятору и библиотекам для целевой платформы. Если мы посмотрим, как в том же AOSP реализованы команды сборки вроде mma, мы увидим, что они ровно это и делают, после чего вызывают make -C.
Ну и о целях. В качестве аргумента make принимает имена целей, которые требуется собрать (если никаких аргументов не задано, то в качестве цели берется первая цель, встретившаяся в make-файле, обычно она имеет имя all). Цели выполняются в том порядке, в каком они заданы в аргументах make. Например, make clean all означает сначала выполнить clean, а потом all (а никак не «очистить все», как иногда почему-то считают).
Кастомные команды — зло
Кастомные команды — классная штука. Можно сделать набор повторяющихся действий, чтобы выполнять цугом. Скрипты для пересборки проекта с разными параметрами, для разворачивания на рабочей системе в разных вариантах, для push’а исходников в репозиторий, «горячей» подмены библиотек и исполняемых файлов на отладочной платформе. Или нет?
- Написать годный shell-скрипт непросто, особенно если он делает что-либо нетривиальное. Например, действия в случае сбоя — целая проблема. Просто завершение с сообщением об ошибке не вариант, очень желательно вернуть систему в исходное состояние, не переваливая на пользователя задачу удалять временные файлы и каталоги, уничтожать запущенные процессы и подобное.
- Твой скрипт, если он действительно полезен, может использоваться на разных машинах с разными дистрибутивами, разными конфигурациями. Например, он использует picocom для подключения к встраиваемой системе по UART. Ты уверен, что у твоего коллеги, который будет пользоваться твоим скриптом, установлен picocom? А если нет? А если твой скрипт переедет на новый релиз твоей любимой ОС и (внезапно!) окажется, что там поменялись имена устройств (привет, em1, прощай, eth0) или какую-нибудь из используемых утилит заменили на «стильную-модную-молодежную» (привет, ip, прощай, ifconfig)? Самый цимес еще и в том, что, скорее всего, от твоего скрипта будет требоваться работа и на новой, и на старой платформах.
- Как только ты начинаешь работать с кастомными командами, ты уже работаешь не в Linux, а в своей, особой среде (назовем ее, скажем, «Болгенос»). Ты привыкаешь работать именно в ней, с ее особыми командами, и любой переход — на новую систему или на машину коллеги — протекает на редкость болезненно, потому что там уже нет твоих замечательных команд my-super-build.sh или mysuperdeploy. Зато есть какие-то bld.sh и dply.bash — что за черт?
В общем, «используй то, что под рукою, и не ищи себе другое» ©. Изучай команды Linux, которые работают на большинстве систем. Пользуйся возможностями, которые предоставляет командная оболочка: автодополнением по Tab’у, поиском по истории команд, вставкой параметров предыдущих команд. Учись слепой печати, в XXI веке этот навык по степени важности стоит в одном ряду с умениями считать и читать.
Конечно, иногда кастомные команды нужны. И тогда имеет смысл сделать их частью проекта, хорошо задокументировать и положить под контроль версий. И число их должно быть минимальным.
Посмотри, как поступили разработчики AOSP с кастомными командами mmm, mma и прочими. В Qt для сборки нужны всего три кастомные команды — qmake, lupdate, lrealease. И всё. Qmake генерирует makefile, и дальнейшая сборка производится при помощи make.
«И запомни, Люк» ©: хороший программист большую часть времени читает, а не пишет. Лихорадочно повторяющийся ввод одних и тех же команд — первый признак того, что что-то пошло не так. Снова.
Заключение
Как мы увидели, программирование в консоли не требует сверхспособностей и доступно для понимания любому разработчику. При этом вместо громоздкого станка-IDE, предназначенного для решения задач, предусмотренных ее автором, способом, предусмотренным ее автором, ты используешь маленький, но гибкий набор инструментов, которые можешь комбинировать в самых разных сочетаниях.
