
Содержание статьи
В современных дистрибутивах Linux существует достаточно средств для изолированного запуска приложений. Некоторые из них известны с давних пор, а некоторые — относительный новодел. Но у каждого решения есть свои преимущества и недостатки.
Введение
Вообще, даже обычная модель безопасности *nix-систем, при условии правильно выставленных прав доступа, способна защитить от многих проблем. Об этом говорит хотя бы тот факт, что в Android до последнего времени в качестве песочницы использовалась именно она (да впрочем, и сейчас, после внедрения SELinux, основная нагрузка лежит на старой модели) — при том, что Android не является дистрибутивом Linux в общепринятом смысле и Google мог использовать что-то другое. Тем не менее в некоторых случаях данная модель бесполезна.
- Первый и самый главный случай — когда программа работает только от суперпользователя. В этом случае, разумеется, стандартная модель неприменима, поскольку на пользователя root по умолчанию она не распространяется.
- Второй случай — когда программа получена из недоверенного источника. Конечно, применение бритвы старика Оккама говорит о том, что отнюдь не все программы из неизвестных мест вредны. Но перестраховка никогда не была бесполезна, и недавнее появление банковского трояна для Linux еще больше это подтверждает.
- Ну и наконец, третий случай — дополнительная обертка вокруг критичных приложений, через которые в теории возможна угроза безопасности.
Далее будут рассмотрены средства изолированного запуска приложений, а также их плюсы и минусы, в частности насколько трудно «совершить побег» из него и насколько их применение сказывается на быстродействии запускаемого приложения.
Chroot
Способ изолирования окружения с помощью chroot известен еще со времен UNIX V7, где и появился данный системный вызов. Я не буду описывать конкретные методы его применения — об этом писали уже неоднократно, и смысла пересказывать, какие команды нужны для его развертывания, я не вижу (разве что коснусь проблемы запуска графических приложений в нем). Вместо этого сосредоточусь на его преимуществах и недостатках.
Неоспоримое преимущество chroot — он есть везде, даже в таких древних дистрибутивах, о которых сейчас уже никто и не помнит. В случае крайней необходимости можно сконфигурировать нечто, отдаленно напоминающее защищенную систему даже на основе ядер 2.2. Но именно что «отдаленно напоминающее» — поскольку больше преимуществ у этого способа изоляции, по сути, и нет.
Недостатки… к ним можно отнести, например, сложность развертывания. Для запуска того же Apache в chroot нужно разбираться с кучей библиотек, конфигурационных файлов и файлов устройств, от которых он зависит. Но, допустим, для быстрого развертывания нужных библиотек можно использовать debootstrap, для файлов устройств и псевдофайловых систем — попросту пробросить в chroot-окружение нужные каталоги командой mount --bind… вот только для целей именно изоляции без создания в этом окружении непривилегированного пользователя толк будет нулевой. В этом и заключается основной недостаток chroot.
Все дело в том, что из поддерева chroot достаточно легко выйти. Для этого, помимо очевидного пути (монтирования файла из каталога /dev), есть также способ «двойного chroot». Суть его заключается в следующем: программа создает директорию, делает в нее вызов chroot(), но перед этим она запоминает fd текущего каталога. После этого она делает системный вызов fchdir(), в качестве параметра которого используется запомненный ранее fd. По сути, на этом процедуру выхода из поддерева можно считать выполненной — необходимо лишь перейти к фактическому корню и сделать chroot() уже в него.
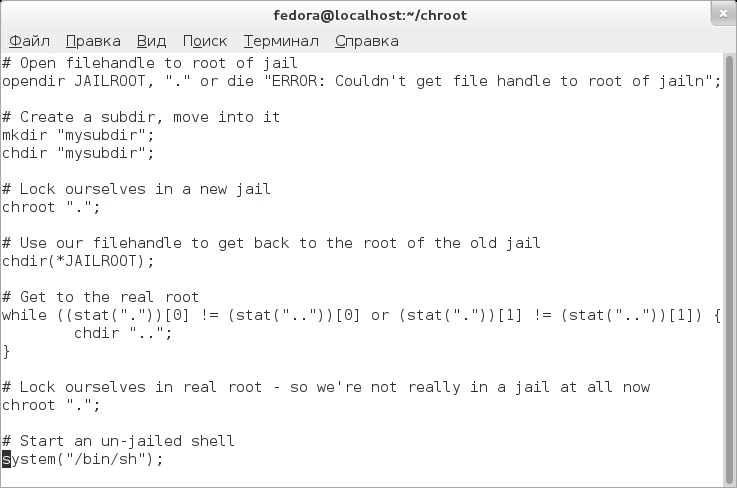

Хакер #180. 2014: люди, вирусы, баги, релизы
Что же касается запуска графических приложений, то, во-первых, перед изменением корня нужно разрешить доступ к X-серверу, что и делает следующая команда:
$ xhost +localhost
А во-вторых, уже после вызова chroot, экспортировать переменную DISPLAY, значение которой нужно узнать заблаговременно:
$ export DISPLAY=":0.0"
Несмотря на все его недостатки, chroot (как и его примерный аналог, fakeroot) незаменим для «честной» сборки некоторых приложений. Также без его помощи производить восстановительные работы на сломанной системе было бы гораздо сложнее.
INFO
Для усиления безопасности chroot, в принципе, можно использовать патчсет GRSecurity, но это имеет смысл делать, только если ядро очень старое и не поддерживает более новые механизмы изоляции.
SELinux
Данный фреймворк безопасности был разработан в NSA, который нынче стал притчей во языцех. Я не буду больше здесь писать об NSA, поскольку статья все же посвящена технической части, замечу лишь, что, если что-то разработано в недрах подобных контор, это вовсе не значит, будир есть какие-то недекларированные возможности, — разработка-то велась для себя. В то же время, в силу относительной сложности SELinux, я не могу гарантировать, что таких возможностей там стопроцентно нет.
Первым делом вспомним, что такое SELinux. Как правило, когда упоминают SELinux, рядом же упоминают MAC — мандатный контроль доступа, то есть модель управления доступом, основанная на «метках» — грифах секретности. Однако в случае с SELinux это не совсем верно. Он позволяет гораздо больше, чем обычный MAC. Фактически SELinux реализует архитектуру FLASK — Flux Advanced Security Kernel, которая основана на идее Type Enforcement (TE, иногда переводится как «принудительное присвоение типов»). Суть идеи в том, что каждому объекту (файлу ли, каталогу или даже сетевому соединению) или субъекту (в качестве которого выступает тот или иной процесс) принудительно присваивается контекст безопасности. В общем случае в SELinux данный контекст выглядит так (для файлов и каталогов его можно посмотреть с помощью команды ls -Z):
unconfined_u:object_r:user_home_t:s0
Элементы контекста безопасности разделяются двоеточиями. Разберемся, что они означают (четвертый элемент не имеет никакого отношения к тематике данной статьи, и его мы касаться не будем).
- Первый элемент (в примере выше unconfined_u) — пользователь SELinux, который определен в политике. Каждому пользователю SELinux может быть сопоставлен обычный пользователь. И да, «пользователь SELinux» и «обычный пользователь» — разные вещи.
- Следом идет роль, также определяемая в политике. Каждому пользователю SELinux может быть сопоставлена одна или несколько ролей, одна из которых будет основной, а остальные вспомогательными.
- Третий же элемент — тип. Это основной элемент в контексте безопасности, который и используется чаще всего. В частности, он используется и в утилите sandbox, которая предназначена для изолированного запуска приложений. Опять же определенный в политике, он задает, что именно субъект может делать вообще, путем указания тех или иных операций.
- Утилита sandbox использует для своих целей еще и пятый элемент, который обычно не отображается. Но о нем мы поговорим чуть позже.
Мы добрались до утилиты sandbox — по сути, фронтенду, написанному на Python. Фронтенд этот, помимо того что парсит командную строку, во-первых, вызывает утилиту seunshare для биндинга временного домашнего каталога и установки для выполняемого в песочнице файла нужного контекста, а во-вторых, по необходимости вызывает скрипт sandboxX.sh для запуска отдельного экземпляра X-сервера.
Часть контекста формируется динамически — в том числе возможно указать тип песочницы. В частности, для браузеров нужно использовать тип sandbox_web_t, а для сетевых приложений вообще — sandbox_net_t. Помимо этого, для того чтобы песочницы не пересекались, утилита sandbox случайным образом указывает в контексте метки MCS — по идее, они должны использоваться для разделения на категории, но в реальной жизни данная возможность задействуется крайне редко.
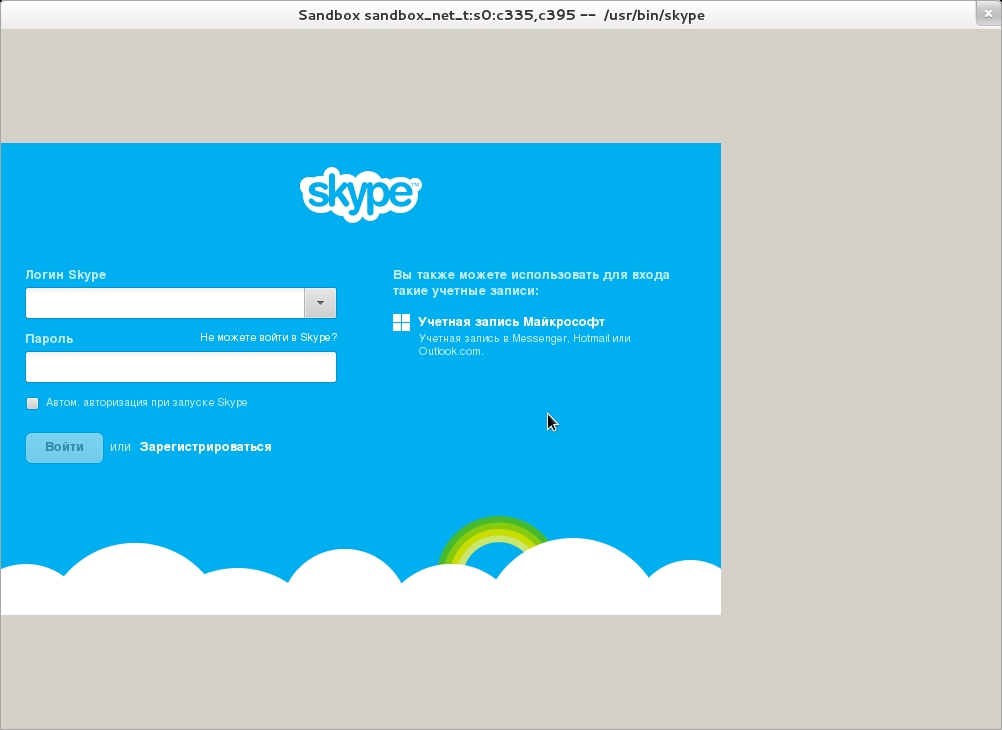
Для примера рассмотрим запуск Skype 4.2 в песочнице SELinux для Fedora 17. Не будем касаться процедуры установки, а сразу попробуем его запустить. Сперва создаем каталоги для песочницы:
$ mkdir ~/skype_home ~/skype_tmp
И пытаемся запустить Skype:
$ sandbox -H ~/skype_home/ -T ~/skype_tmp/ -X -t sandbox_net_t skype
Однако он выругается о недостаточных разрешениях на библиотеку libQtWebKit. Чтобы этого не происходило, нужно исправить контекст:
# semanage fcontext -a -t textrel_shlib_t '/usr/lib/libQtWebKit.so.4.10.1'
# restorecon -v '/usr/lib/libQtWebKit.so.4.10.1'
Но и этого недостаточно — после очередной попытки запуска SELinux снова выругается, и нам ничего не останется, как сгенерировать свой модуль политики и установить его (по желанию можно его и посмотреть):
# grep skype /var/log/audit/audit.log | audit2allow -M Skype42_sandbox_execmod
# semodule -i Skype42_sandbox_execmod.pp

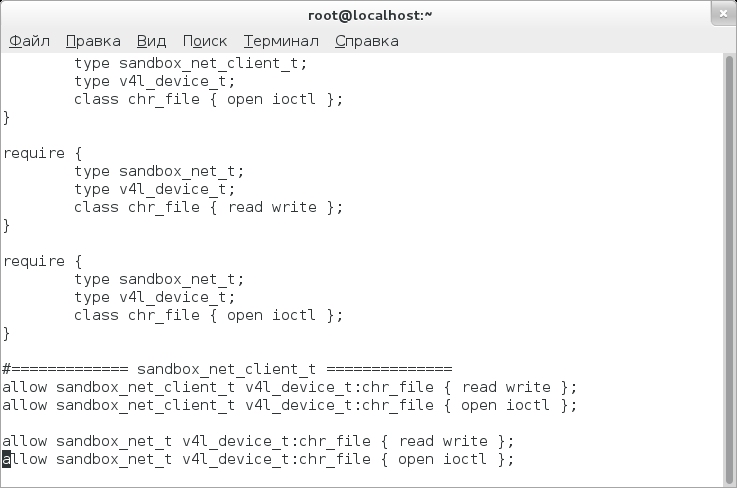
После этого Skype заработает, но с оговорками. Я не буду здесь писать о визуальных эффектах и прочих неудобствах с графикой — для разговора по Skype это некритично. Но вот тот факт, что при видеозвонках другая сторона не видит видео, хотя и понятен (мы же запускаем его в песочнице), но довольно огорчителен. Что еще обиднее, стандартные правила, генерируемые с помощью audit2allow, неработоспособны. После долгой возни в конечном итоге получились примерно такие правила (файл Skype42_sandbox_v4l.te):
module Skype42_sandbox_v4l 1.0.1;
require {
type sandbox_net_client_t;
type v4l_device_t;
class chr_file { read write };
}
require {
type sandbox_net_client_t;
type v4l_device_t;
class chr_file { open ioctl };
}
require {
type sandbox_net_t;
type v4l_device_t;
class chr_file { read write };
}
require {
type sandbox_net_t;
type v4l_device_t;
class chr_file { open ioctl };
}
#============= sandbox_net_client_t ==============
allow sandbox_net_client_t v4l_device_t:chr_file { read write };
allow sandbox_net_client_t v4l_device_t:chr_file { open ioctl };
allow sandbox_net_t v4l_device_t:chr_file { read write };
allow sandbox_net_t v4l_device_t:chr_file { open ioctl };
Откомпилируем и загрузим этот модуль:
# checkmodule -M -m -o Skype42_sandbox_v4l.mod Skype42_sandbox_v4l.te
# semodule_package --module Skype42_sandbox_v4l.mod --outfile Skype42_sandbox_v4l.pp
# semodule -i Skype42_sandbox_v4l.pp
После очередного запуска Skype увидит камеру.
Разберем теперь плюсы и минусы данной песочницы. Плюсы, если сравнивать с chroot, несомненно, имеются. Так, налицо большая безопасность при меньшем времени развертывания. Посуди сам: для запуска программы в chroot нужно набрать 3–5 команд, для запуска же в песочнице SELinux в общем случае достаточно одной команды, которая, ко всему прочему, еще и отключает все capabilities данного процесса — то есть ограничивает приложения, даже будучи запущенной из-под root.
Но и минусы тоже есть. Самый главный — эта утилита входит в состав только Fedor’ы, RHEL и клонов. Во-вторых, при попытке запустить какое-нибудь приложение — даже, казалось бы, не слишком экзотическое — этот sandbox попросту отказывается его запускать, что мы и видели в случае со Skype. Настройка же SELinux, на основе которого сделано это средство изоляции, — вещь достаточно трудоемкая и при неправильном выполнении может ослабить безопасность и повысить риск побега из песочницы. Последнее особенно верно в том случае, если бездумно выполнять команду audit2allow в связке с semodule -i. Вывод: всегда читай генерируемые правила и, если не уверен в приложении, а правила кажутся тебе подозрительными, не запускай его.
Ну а если говорить об SELinux в целом, безусловно, при должном конфигурировании он обеспечивает весьма высокий уровень защиты. К сожалению, создавать его политики без понимания того, как все это работает и что от чего зависит, бесполезно — уровень безопасности от этого не возрастет. Однако по большому счету это и не понадобится, поскольку в состав дистрибутивов, его использующих, уже включены политики с сотнями типов и возможностью управлять некоторыми их параметрами.
AppArmor
AppArmor (ранее назывался SubDomain) был по большей части выпестован Novell — несмотря на то что его изначально разрабатывала совсем другая компания. Сейчас AppArmor включен по умолчанию в Ubuntu, однако его профили для большинства приложений неактивны. В отличие от SELinux, в текущих стабильных версиях нет аналога команды sandbox, что, тем не менее, не мешает применять его для изолированного запуска приложений, предварительно написав профиль. В отличие от политик SELinux, профили AppArmor предоставляются прямо в текстовом виде и достаточно просты. Условно файл профиля можно разделить на несколько частей:
- инклуды — чтобы не писать одинаковые строчки в десятки профилей, их выделяют в один файл и уже его включают по необходимости в профили. В одном из них, <tunnables/global>, находятся некоторые переменные, общие для всех профилей, а в <abstractions/base> находятся те директивы, которые по большей части верны для всех приложений, такие, например, как разрешение чтения каталога
/libи/usr/lib; - параметры доступа приложения к сети — к примеру, может ли приложение использовать raw-сокеты, или ему доступен только ограниченный набор протоколов;
- capabilities — список тех возможностей, которые может использовать приложение, даже будучи запущенным из-под root;
- список файлов, к которым программа имеет доступ, и права доступа к ним;
- если приложение может запускать другие программы, есть возможность выбирать, запустятся ли они с теми же привилегиями, что и то приложение, которое запустило, или под профилем специально для них, или, наконец, под локальным профилем, который описан в том же файле, что и профиль запускающего приложения.
В качестве примера опишу включение профиля для Firefox (который по умолчанию отключен) и разберу, какие именно ограничения он накладывает:
$ sudo rm /etc/apparmor.d/disable/usr.bin.firefox
$ sudo /etc/init.d/apparmor restart
Первая команда удаляет симлинк на файл профиля (соответственно, при необходимости его можно восстановить), а вторая перечитывает все файлы AppArmor.
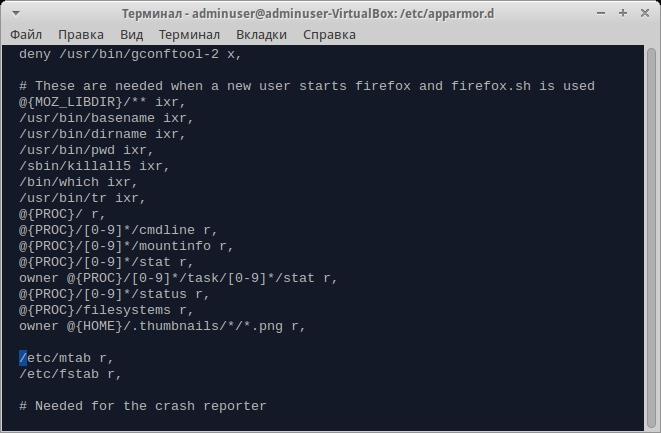
Ограничения же, хоть и довольно жестки, вполне приемлемы для повседневной работы. Запускать разрешается строго ограниченный набор программ. К таковым относятся, например, /bin/uname или /bin/ps. В инклудах разрешено запускать Java и клиенты электронной почты. Файлы можно загружать только в папку ~/Downloads (это не относится к расширениям — они находятся рядом с конфигами самого браузера, куда он может писать без ограничений).
В целом, если не считать отсутствия специальной команды для запуска недоверенных приложений и необходимости писать профили, AppArmor производит впечатление дружелюбного, насколько это возможно для подобных целей, средства изоляции приложений, обеспечивающего, тем не менее, достаточно высокий уровень защиты. Из минусов можно отметить слабую поддержку ограничения сетевых соединений и некоторых других ресурсов. Еще один минус заключается в том, что, поскольку ограничения к файлам задаются по именам (а не в расширенных атрибутах, как это реализовано в SELinux), имеется возможность обойти их через жесткие ссылки. Однако, на мой взгляд, это наиболее оптимальное средство изоляции из уже рассмотренных по соотношению удобство использования / безопасность.
LXC и Arkose
Механизм LXC, который можно назвать усовершенствованным chroot, появился относительно недавно и, хотя для промышленного применения пока еще сыроват, для домашних пользователей вполне сгодится. Здесь я не буду описывать, как создавать контейнеры, коснусь лишь внутренней архитектуры.
По сути, LXC не является самостоятельной технологией. Это объединение двух разных механизмов — namespaces и cgroups. Namespaces (пространства имен) позволяют, в частности, разграничить область видимости процессом других процессов (пространство имен pid) и скрывать точки монтирования (пространство имен mount). Последнее, кстати говоря, и является аналогом chroot, так что де-факто, даже если бы LXC был основан только на пространствах имен, у него бы все равно была большая гибкость. Но помимо пространств имен, LXC использует еще и cgroups для контроля ресурсов — процессорного времени и памяти. Пространства имен стоит описать чуть подробнее. Всего их шесть, о двух из них мы уже упомянули, расскажу об оставшихся:
- UTS — если коротко, позволяет задавать раздельные hostname;
- IPC — позволяет изолировать некоторые механизмы межпроцессной коммуникации, такие как SysV IPC и очереди сообщений POSIX;
- Network — предоставляет возможность изоляции сетевых ресурсов — интерфейсов, таблицы маршрутизации, портов и прочего;
- User — изолирует диапазон UID и GID. Иными словами, в общем пространстве имен процесс может иметь один UID/GID, а в своем собственном может быть совершенно другой. А если учитывать, что начиная с ядра 3.8 данные пространства имен может создавать даже непривилегированный процесс, это открывает интересную возможность: будучи в общем пространстве имен непривилегированным приложением, в своем собственном можно производить некоторые операции, ранее доступные только суперпользователю.
Как LXC является фронтендом для пространств имен и cgroups, так и Arkose является фронтендом для LXC. Гибкость настройки при его использовании минимальная, но для большинства случаев запуска приложений в песочнице вполне подходит. Работает он так: на основе заданных опций генерируется конфиг для LXC и уже затем этот конфиг передается собственно в команду запуска контейнеров. Для действий с файлами вне домашнего каталога используется AUFS — файловая система COW, а для домашнего каталога есть возможность как использовать виртуальный, так и пробросить реальный. Замечу, что при запуске приложений с root-привилегиями их capabilities никак не ограничиваются (хотя LXC это позволяет), и, таким образом, для запуска неизвестных приложений Arkose не годится. А вот для запуска, например, браузера (в качестве дополнительного слоя защиты) его возможностей достаточно.
Плюсы у LXC (но не Arkose) достаточно весомы. Во-первых, возможность довольно гибко конфигурировать контейнеры, во-вторых, безопасность, сравнимая, пожалуй, с безопасностью AppArmor. А если рассматривать те цели, для которых он предназначен, а не только изоляцию запуска какого-то одного конкретного приложения, то он быстрее, чем виртуализация, даже аппаратная, — эмулировать-то ничего не требуется. Минусы — технология нуждается в обкатывании. И возможно, я покажусь параноиком, но из-за сложности реализации есть ненулевая вероятность нахождения багов — так что использовать контейнеры с root-доступом, пускай даже он будет сильно урезан, — плохая идея. Для Arkose же верно примерно то же самое — только гибкая конфигурация его, увы, невозможна, да и в последних версиях Ubuntu он работает кривовато.
WWW
- Механизм изоляции в Solaris: bit.ly/180rElj
- FreeBSD Jail — усовершенствованный chroot: bit.ly/9Qvms8
Заключение
В статье были описаны отнюдь не все возможности изоляции приложений. Критерием выбора служила распространенность той или иной технологии. Но даже среди них есть из чего выбрать. Кроме того, их можно совмещать.
С точки зрения соотношения безопасность / удобство использования AppArmor выглядит самым оптимальным вариантом. Следом за ним идет Arkose, а уж затем — команда sandbox SELinux. Chroot же для обеспечения безопасности использовать, конечно, можно, но смысла большого нет. Ну а если нужна именно безопасность, то тут подойдет комбинация SELinux и LXC — разумеется, если у тебя есть время и желание все это настраивать. Выбор за тобой.
Еще песочниц? Их есть у нас
Помимо средств изоляции в Linux, описанных в статье, есть еще парочка песочниц, о которых хотелось бы упомянуть:
- Seccomp-bpf — плод скрещивания песочницы seccomp, известной аж с 2005 года, и BPF, изначально предназначенного для работы с пакетами. Сам по себе seccomp запрещал все системные вызовы, кроме четырех — read(), write(), sigreturn() и exit(), что в абсолютном большинстве случаев делало его применение бессмысленным. Скрещивание же с BPF дало возможность очень гибко фильтровать параметры сисколлов, что позволяет самому задать рамки, за которые процесс не сможет выйти. Однако эта песочница на данный момент не имеет нормального фронтенда — программисты сами должны писать фильтры для своего приложения, что сильно ограничивает ее применение.
- Virt-sandbox разрабатывается теми же людьми, что и утилита sandbox. Однако, в отличие от нее, базируется она на основе технологий виртуализации. На данный момент поддерживается KVM и контейнеры LXC, но в теории она может поддерживать все системы виртуализации, доступные через libvirt, то есть, например, VirtualBox. Основная проблема в скорости запуска и развертывании образа диска, но, по уверениям разработчиков, запуск /bin/false с помощью этой утилиты занимает всего шесть секунд. Вместо образа диска используется тот же самый метод, что и в Arkose, — файловая система Copy-on-Write AUFS.






