Содержание статьи
Продукты класса SIEM отличаются от обычных Log-серверов как минимум наличием корреляционного движка, способного превратить огромный поток событий в набор алертов. В данной статье мы рассмотрим некоторые возможности библиотеки Esper, позволяющей реализовать свой корреляционный движок, не уступающий по возможностям подсистемы корреляции промышленным SIEM-решениям, а в чем-то даже превосходящий их.
Esper, принцип работы
Esper представляет собой мощную Java/.NET-библиотеку с открытым исходным кодом, которая служит для сложной обработки событий, называемой производителями SIEM модным словом «корреляция». Помимо самой библиотеки, которую можно использовать в своих Java/.NET-проектах, EsperTech предлагает готовое приложение Esper Enterprise Edition, включающее в себя Web GUI, редактор и отладчик EPL-выражений, REST веб-сервисы, набор адаптеров для событий: CSV, JMS in/out, API, DB, Socket, HTTP.

Для выполнения корреляции в своем приложении необходимо описать типы событий, их поля и правила обработки, всю остальную работу Esper возьмет на себя. Правила обработки событий (statements) описываются с помощью языка EPL (Event Processing Language), который очень похож на SQL, однако сама логика работы Esper принципиально отличается от СУБД. Вместо того чтобы хранить события и периодически выполнять запросы, Esper хранит правила (запросы) и пропускает сквозь них поток событий, словно через решето (или набор решет). Как только условия правил выполняются, библиотека мгновенно отдает результат приложению.
Правила описываются с помощью двух основных способов:
- event patterns — шаблоны событий, которые позволяют выявлять наличие или отсутствие последовательностей или комбинаций событий в потоке или наборах потоков;
- event stream queries — запросы, через которые пропускается поток событий, оставляющие только необходимые по заданным правилам.
Как уже было сказано, Esper работает с непрерывными потоками событий различных типов, например от межсетевого экрана, антивируса, контроллера домена. Esper позволяет крутить эти потоки и события в них, как только захочется: объединять, группировать, фильтровать, дедуплицировать, сортировать, прогонять через различные типы окон (временные, статистические) — в общем, сделать все, чтобы найти врага, выявить аномалию или сорвать куш на бирже. Да-да, Esper используется даже для трейдинга!
Корреляционные правила
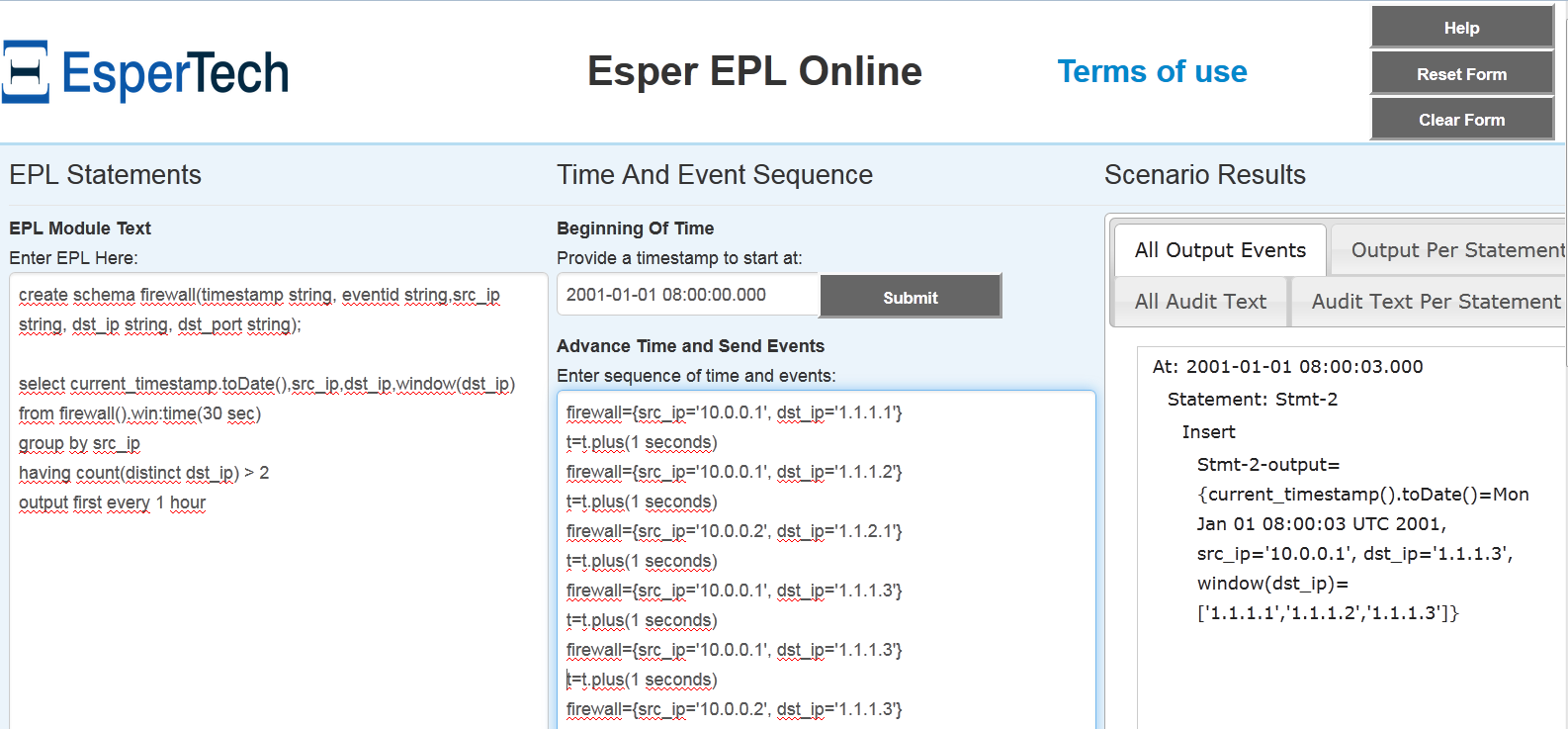
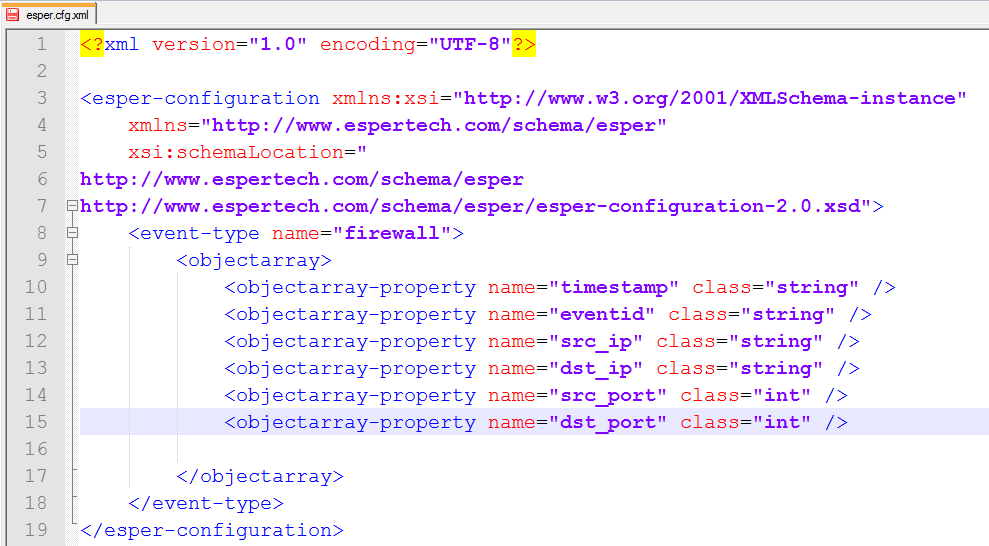
Посмотрим, как Esper может быть полезен в контексте обеспечения ИБ. Представь, что у нас есть источник firewall, который логирует события обо всех соединениях со следующими полями: timestamp (дата время), eventid (код события), src_ip (адрес источника), dst_ip (адрес назначения, src_port (порт источника), dst_port (порт назначения).
Самое время описать первое правило, которое будет детектировать сканирование адресов:
// Детектируем сканирование адресов
select * from firewall.win:time(30 sec)
group by src_ip
having count(distinct dst_ip) > 50
Разберем его подробно: для начала выбираем все поля для событий в потоке источника firewall, далее все события пропускаем через скользящее временное окно, длина которого составляет 30 с. Для событий, находящихся в окне, выполняем группировку по адресу источника и отдаем только те, для которых количество уникальных адресов назначений превышает 50.
Предположим, что в нашей сети есть система мониторинга и сканер уязвимостей с адресами 192.168.1.254 и 192.168.1.253 соответственно. Данные хосты периодически обращаются к большому числу узлов, поэтому добавим в наш запрос фильтр, чтобы исключить ложные срабатывания:
select * from firewall.win:time(30 sec)
where src_ip not in ('192.168.1.254','192.168.1.253')
group by src_ip
having count(distinct dst_ip) > 50
Да, кстати, тут нет ошибки: Esper, в отличие от SQL, допускает применение конструкции where в запросах, содержащих агрегатные функции. Несмотря на то что правило будет работать, более оптимальным был бы запрос с применением фильтра потоков:
// Использование фильтра потока
select * from firewall(src_ip not in ('192.168.1.254','192.168.1.253')).win:time(30 sec)
group by src_ip
having count(distinct dst_ip) > 50
Фильтр потока отсеивает события еще до попадания их в окно, в то время как фильтр where применяется для всех событий, находящихся в окне, после чего считаются агрегатные функции, значения которых отфильтровываются конструкцией having. Чем меньше событий в окне, тем меньше ресурсов мы потребляем.
В случае если в нашу сеть проник зловред, который начнет активно сканировать сеть, правила, созданные выше, сгенерируют много событий, которые завалят почтовый сервер уведомлениями, поэтому добавим конструкцию, оставляющую вывод только первого события в течение часа для каждого источника, на котором сработал запрос:
// Использование фильтра потока
select * from firewall(src_ip not in ('192.168.1.254','192.168.1.253')).win:time(30 sec)
group by src_ip
having count(distinct dst_ip) > 50
output first every 1 hour
Идем дальше. Заворачиваем в наш мегакоррелятор события с антивирусов — назовем этот поток antivirus — со следующими полями: timestamp (дата время), host_ip (адрес хоста), virus_name (имя вируса). Антивирус может регистрировать достаточно много событий, обрабатывать каждое при большом числе компьютеров в сети не хватит ни времени, ни сил, но если хост, на котором сработал антивирус, неожиданно начинает сканировать сеть, то это точно не должно остаться без внимания. Для того чтобы поймать такую активность, нам необходимо скоррелировать сканирование и обнаружение вируса, будем делать это с помощью шаблонов (patterns):
// Помещаем в поток scanning_hosts обнаруженные попытки сканирования
insert into scanning_hosts
select *,window(dst_ip) victims from firewall(src_ip not in ('192.168.1.254','192.168.1.253')).win:time(30 sec)
group by src_ip
having count(distinct dst_ip) > 50
// Используем шаблон для корреляции событий антивируса с попытками сканирования
select current_timestamp.toDate() alert_time,'Critical' severity, host_virus.host_ip, host_scan.victims from pattern[
every host_virus=antivirus -> host_scan=scanning_hosts(src_ip = host_virus.host_ip)
where timer:within(1 minute)
]
group by host_virus.host_ip
output first every 1 hour
С помощью insert into помещаем события, соответствующие попыткам сканирования, в новый поток scanning_hosts. Чтобы при расследовании инцидента сразу видеть, какие хосты были просканированы, то есть содержались во временном окне на момент обнаружения, используем конструкцию window(имя_поля). Далее описываем шаблон с помощью служебного слова pattern, который сработает для каждого события сканирования, следующего за событием антивируса в течение минуты, в случае совпадения адреса завирусованного хоста с адресом из потока сканирующих машин. После выявления данной последовательности событий мы получим текущую дату, критичность, адрес хоста и список потенциальных жертв, которые начал сканировать зараженный хост.
Зачастую не только наличие определенных событий, но и их отсутствие в течение определенного времени требует внимания, поскольку это может свидетельствовать о выходе из строя оборудования, ошибке конфигурирования или атаке. Чтобы не прощелкать момент, когда с межсетевого экрана перестанут приходить логи, создадим еще одно правило с использованием шаблона:
// Обнаруживаем файрвол, который перестал присылать события в течение пяти минут
select * from pattern [every firewall -> (timer:interval(5 min) and not firewall)]
После каждого события из потока firewall Esper будет запускать пятиминутный таймер. Если в течение этого времени не придет еще одно событие, приложение будет об этом уведомлено.
Машина времени
Как мы уже увидели, Esper позволяет достаточно легко обрабатывать события, происходящие в реальном времени, для этого по умолчанию используется внутренний таймер, основанный на системном времени с интервалом в 100 мс. Вместе с этим путем нехитрых манипуляций Esper позволяет взять время под полный контроль. Например, у нас есть журналы файрвола, которые хранятся в архиве, и мы хотим обнаружить те же самые сканирования адресов. Большинство SIEM-систем, представленных на рынке, сложили бы руки, так как они не поддерживают офлайн-корреляцию и используют только текущее время для обработки событий. Благодаря своей гибкости Esper позволяет решить задачу несколькими способами:
- Отправкой в Esper специального сообщения типа CurrentTimeEvent, в которое помещается значение времени из лога, сдвигающее внутренний таймер. Далее засылаем саму запись из журнала, которая прогоняется через запрос, использующий обычное временное окно win:time (период).
- Отправкой в Esper сообщения из лога с полем, содержащим время из журнала в формате unixtime (значение должно быть типа Long). Далее эти сообщения прогоняются через запрос с временным окном win:ext_timed (время_из_лога, период), которое использует внешнее время для своей работы.
Открываем окна нараспашку
В примерах правил, которые мы уже рассмотрели, использовалось скользящее временное окно time. Кроме этого окна, Esper поддерживает ряд других интересных окон. Вот лишь некоторые из них:
- win:length — накапливает заданное число событий;
- win:time_batch — накапливает события в течение заданного интервала, после чего отдает их для обработки;
- win:time_accum — скользящее окно, которое накапливает события до тех пор, пока в течение заданного времени не поступит ни одного события;
- win:keepall — хранит все события, попавшие в окно;
- std:unique — добавляет в окно только последнее событие для уникального значения поля/полей или функции от этих значений, то есть если в параметрах окна мы задаем, что проверять уникальность следует по полю src_ip, то в итоге в окне будут содержаться последние события для каждого src_ip;
- std:groupwin — группирует события по полям или значениям функций от этих полей;
- stat:uni — рассчитывает различные статистические показатели для событий, содержащихся в окне: общую сумму, среднее, стандартное отклонение, дисперсию;
- stat:correl — рассчитывает коэффициент корреляции между двумя параметрами внутри потока;
- ext:time_order — упорядочивает события по времени, даже если старое событие пришло позже, чем новое.
Окна можно комбинировать друг с другом, при этом события из одного окна перетекут в другое. Например, если файрвол передает информацию о количестве байтов, то посчитать общий объем переданных данный, средний объем сессии в течение одного часа и вывести топ-10 можно было бы с помощью следующей цепочки окон:
select src_ip,total,average
from firewall.win:time_batch(1 hour).std:groupwin(src_ip).stat:uni(total_bytes)
group by src_ip
order by total desc
limit 10
Еще одна интересная концепция, которая поддерживается Esper, — именованные окна (Named Windows). Именованные окна являются глобальными и могут использоваться несколькими правилами одновременно. Для примера добавим к нашему тестовому контуру контроллер домена, с которого мы получаем события об аутентификации пользователей с полями login и src_ip. Мы хотим быстро вычислить логин вредителя, сканирующего нашу сеть, и не тратить время на поиск этой информации в логах с контроллера. Так как в сети используется DHCP, мы хотим, чтобы в связке login — src_ip содержались только актуальные данные. Связка login — src_ip может быть полезна для правил, использующих различные потоки событий (межсетевой экран, IDS, прокси-сервер), поэтому создадим именованное окно, которое будет хранить эту связку без ограничения по времени:
create window login-ipWindow.win:keepall()
(src_ip string, login string, string last_seen)
В это окно также будем записывать время последнего входа пользователя (last_seen) с данного IP-адреса.
Начнем наполнять наше окно: для каждого события с контроллера домена (поток activeDirectory) будем выполнять операцию слияния с ранее созданным окном loginIpWindow: в случае наличия в окне поля src_ip, совпадающего с адресом из события контроллера домена, просто обновим метку времени, иначе вставим новую запись:
on activeDirectory(category='Logon') ad
merge loginIpWindow liw
where ad.src_ip = liw.src_ip
when matched
then update set liw.timestamp = ad.timestamp, liw.login=ad.login;
when not matched
then insert select src_ip,login,timestamp
Теперь все готово, чтобы к каждому событию сканирования из ранее созданного потока scanning_hosts прикрутить связанный логин пользователя:
select current_timestamp.toDate(), fw.src_ip, liw.login, liw.last_seen
from scanning_hosts.std:unique(src_ip) as fw
left outer join loginIpWindow as liw
on liw.src_ip = fw.src_ip;
Как видишь, все очень похоже на обычный join, используемый в реляционных СУБД. Единственное, на что стоит обратить внимание, — операция объединения работает с окнами, так как в них аккумулируются данные, именно поэтому для потока scanning_hosts пришлось использовать окно std:unique(src_ip), возвращающее последнее событие для каждого адреса источника из потока.
Подключаем внешние источники
В предыдущем примере мы рассмотрели, как создать динамически формируемый справочник с помощью именного окна, но у Esper за пазухой припрятано еще несколько полезных плюшек. Одна из них — это возможность использования различных внешних источников, которые существенно расширяют возможности движка. Представь, что у нас есть регулярно обновляемый список IP-адресов узлов Tor, который хранится в СУБД, и мы хотим обнаруживать анонимные подключения к нашей сети, используя логи межсетевого экрана. Esper из коробки поддерживает работу с реляционными СУБД и использует кеширование для оптимизации нагрузки. Для работы с СУБД необходимо описать в конфигурации ссылку на СУБД (database-reference) и реализовать класс, возвращающий DataSource. Пусть в СУБД, которую мы назвали в конфиге ref_db, есть таблица tor_nodes с единственной колонкой tornode_ip, содержащей адреса, тогда правило, определяющее подключения из сети Tor, может выглядеть так:
// Обнаруживаем соединения из сети Tor
select * from firewall as fw, sql:ref_db ['select tornode_ip from tor_nodes'] as tor
where fw.src_ip=tor.tornode_ip
Esper не ограничивается поддержкой стандартных СУБД, а позволяет использовать абсолютно любые источники. Для этого необходимо реализовать класс со статическим методом, возвращающим Java-класс, java.util.Map или массив объектов Object[]. Благодаря такой гибкости можно подтягивать данные откуда угодно: из Redis, файлов, веб-ресурсов — в общем, использовать любые источники, с которыми можно работать на Java. Вот так мог бы выглядеть класс, работающий с Redis:
public class RedisLookup {
// Определяем метаданные, метод должен оканчиваться на Metadata
public static Map<String, Class> checkTORMetadata() {
Map<String, Class> propertyNames = new HashMap<String, Class>();
propertyNames.put("isTOR", boolean.class);
return propertyNames;
}
// Проверяем, входит ли IP-адрес в список tor_nodes
public static Map<String,Object> checkTOR(String src_ip) {
Map<String, Object> map = new HashMap<String,Object>();
Jedis redis = new Jedis("127.0.0.1");
redis.connect();
boolean isTor = redis.sismember("tor_nodes", src_ip);
if (isTor){
map.put("isTOR",true);
}
else map.put("isTOR", false);
return map;
}
}
Запрос, который сможет использовать этот класс для выявления коннектов из сети Tor, примет следующий вид:
// Обнаруживаем соединения из сети Tor
select * from firewall, method:RedisLookup.checkTOR(firewall.src_ip) as tor
where tor.isTOR=true
Вот так, приложив немного усилий, можно интегрировать Esper с различными информационными массивами, и это лишь один из немногих примеров расширения функциональности Esper с помощью кастомных модулей.
Заключение
Обработка событий является краеугольным камнем в самых разных областях: трейдинге, антифроде, обнаружении вторжений и аномалий, мониторинге. Все эти области объединяет необходимость сложной обработки событий с минимальной задержкой. Отличным решением для выполнения этой задачи служит библиотека Esper благодаря широким возможностям, простому синтаксису для описания правил и очень хорошей расширяемости. Чтобы попрактиковаться в написании EPL-выражений и увидеть результат их работы, можно воспользоваться веб-приложением. Если тебе интересно, каким образом использовать Esper в своем приложении, обрати внимание на папку с примерами внутри архива с библиотекой или дождись следующего номера, где мы перейдем от теории к практике и создадим наш мегакоррелятор с блек-джеком и прочими плюшками. Как говорится, stay tuned!