Содержание статьи
DDoS-атаки стали настоящим бичом современного интернета. С ними борются как организационными методами (о которых писали в журнале, и не раз), так и техническими. Последние, как правило, либо неэффективны, либо достаточно дороги. Ребята из NatSys Lab решили попробовать сделать open source средство для защиты от DDoS-атак на веб-приложения. Посмотрим, что у них получилось.
Введение
Open source средства для защиты от DDoS (IPS), такие, например, как Snort, работают на принципе DPI, то есть анализируют весь стек протоколов. Они, тем не менее, не могут контролировать установление и завершение TCP-соединений, поскольку находятся для этого на слишком высоком уровне в сетевом стеке Linux и не являются ни серверной, ни клиентской стороной. Из-за этого возможен обход данных IPS. Прокси-серверы же участвуют в установлении соединения, но защитить от крупных DDoS не могут по причинам их относительной медлительности — поскольку работают они на том же самом принципе, что и атакуемые серверы. Для них желательно если не столь же хорошее оборудование, как на бэкенде, то достаточное, чтобы выдерживать большие нагрузки.
В NatSys Lab решили пойти по пути kHTTPd и TUX — реализовать фреймворк для работы с HTTP в режиме ядра. Пока что этот фреймворк находится в стадии альфа-версии, однако к середине 2015 года обещают выпустить релиз. Тем не менее, чтобы понять принципы работы и поиграться, достаточно и прототипа, который вполне работоспособен.
Установка и настройка
Для сборки Tempesta нужно иметь исходники ядра 3.10.10 с необходимыми инструментами. Скачиваем исходники самого проекта:
$ git clone https://github.com/natsys/tempesta.git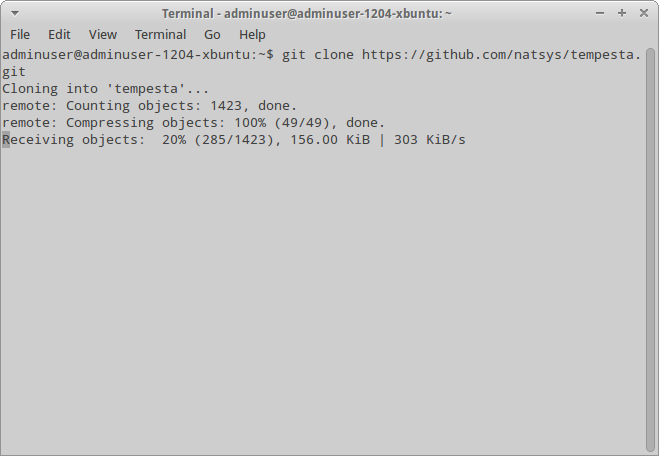

Копируем патч и накладываем его:
$ cp tempesta/linux-3.10.10.patch linux-3.10.10/
$ cd linux-3.10.10
$ patch -p1 < linux-3.10.10.patchВключаем нужные возможности — так, должны быть включены опции CONFIG_SECURITY и CONFIG_SECURITY_NETWORK, отключены все прочие LSM-возможности, такие как SELinux и AppArmor, и параметр Warn for stack frames larger than в подменю kernel hacking установлен в 2048. Затем собираем/устанавливаем ядро:
$ make nconfig
$ CONCURENCY_LEVEL=5 fakeroot make-kpkg --initrd --append-to-version=-tempesta kernel_image kernel_headers
$ sudo dpkg -i ../linux-image-3.10.10-tempesta_3.10.10-tempesta-10.00.Custom_amd64.deb ../linux-headers-3.10.10-tempesta_3.10.10-tempesta-10.00.Custom_amd64.deb
$ sudo shutdown -r now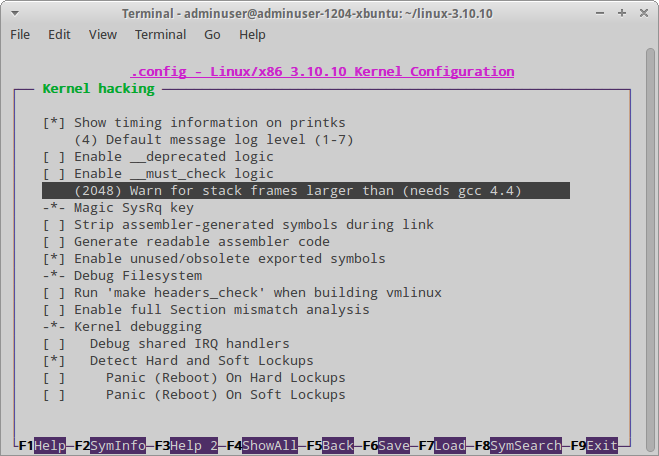
После перезагрузки уже можно собирать и сам Tempesta. Для этого переходим в каталог, куда мы клонировали его, и набираем следующую команду:
$ make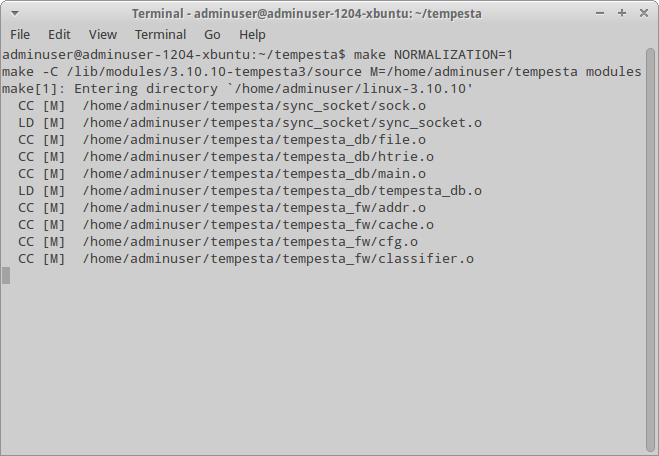
INFO
Аргумент NORMALIZATION=1, указанный команде make при сборке модулей Tempesta, включает возможность нормализации HTTP-трафика.
После сборки можно, конечно, уже и запускать, но сперва давай посмотрим конфигурационный файл. Пример его находится в etc/tempesta_fw.conf. Разберем, что в нем есть:
# Указываем бэкенд, куда будут направляться запросы. Допустимо указывать несколько бэкендов — каждый в отдельной строке
backend 127.0.0.1:8080;
# Порт (и при необходимости адрес), который используется самим Tempesta. Опять же допустимо использовать несколько адресов/портов
listen 80;
listen [::0]:80;
# Настройки кеширования — включено/отключено. В случае если защищаемый бэкенд находится на том же сервере, что и Tempesta, его лучше отключить
cache on;
# Каталог, где хранится кеш. Путь к нему абсолютен и не должен заканчиваться слешем. Кроме того, если в пути есть пробелы и спецсимволы, его необходимо заключать в кавычки
cache_dir /opt/tempesta/cache;
# Размер кеша. Измеряется в килобайтах и должен быть кратен 4096
cache_size 262144;Кроме данного конфигурационного файла, в этом же каталоге есть файл tfw_sched_http.conf, в котором, собственно, и находятся правила маршрутизации HTTP и содержимое которого должно, по идее, быть включено в предыдущий — но, по всей видимости, его вынесли, чтобы в дальнейшем в модуле диспетчера добавить возможность его обработки. Посмотрим на его синтаксис:
# Обязательная строка с именем модуля
sched_http {
# Группы бэкендов. Бэкенды должны быть заданы и в предыдущем конфиге. Внутри группы балансировка осуществляется путем алгоритма round-robin
backend_group static_content {
backend 192.168.1.19;
backend 192.168.1.20:8080;
}
backend_group im {
backend 192.168.1.21;
}
backend_group main {
backend 192.168.1.5;
}
# Правила маршрутизации. Задаются в следующем виде:
# rule be_group field operator pattern
# где be_group — определенная выше группа бэкендов, field — поле HTTP-заголовка, сравниваемое с pattern, используя оператор operator. Список возможных полей:
# uri — часть uri HTTP-запроса, содержащая путь и строку запроса
# host — имя хоста либо из uri, либо из заголовка Host. Первое приоритетнее
# host_hdr — только заголовок Host
# hdr_conn — поле Connection заголовка HTTP-запроса
# hdr_raw — любое другое поле, имя которого указано в pattern
# operator может быть либо eq — полное соответствие с pattern, либо prefix — соответствие на начало строки
# Если запрос не удовлетворяет текущему правилу, он проверяется на соответствие следующему
rule static_content uri prefix "/static";
rule static_content host prefix "static.";
rule im uri prefix "/im";
rule im hdr_raw prefix "X-im-app: ";
rule main uri prefix "/";
}Как уже было сказано, эти два файла по отдельности неработоспособны — их нужно объединить в один, для чего используем команду
$ cat tempesta_fw.conf tfw_sched_http.conf > tfw_main.confНаконец, запускаем:
# TFW_CFG_PATH="/home/adminuser/tempesta/etc/tfw_main.conf" ./tempesta.sh startОстанавливаем аналогично аргументом stop.
ModSecurity
Модуль представляет собой WAF для Apache и обеспечивает следующие возможности:
- мониторинг и контроль доступа в реальном времени;
- виртуальный патчинг — технология устранения уязвимостей без изменения уязвимого приложения. Поддерживается гибкий язык для составления правил;
- логирование всего HTTP-трафика;
- оценка безопасности веб-приложения
и многое другое.
ModSecirity может быть сконфигурирован и как reverse proxy, и как плагин к Apache.
Архитектура
Стоит коснуться и внутренней архитектуры проекта.
Общие сведения
Прежде чем разбираться с данным фреймворком, вспомним, как работает аналогичное ПО. Практически все современные HTTP-серверы используют сокеты Беркли, у которых, несмотря на их функциональность, есть две основные проблемы. Первая — чрезмерная перегруженность функциями. То есть, допустим, чтобы ограничить количество подключенных клиентов, нужно, во-первых, разрешить входящее соединение с использованием accept(), затем узнать адрес клиента, используя getpeername(), проверить, есть ли этот адрес в таблице, и закрыть соединение. Это занимает больше шести переключений контекста. Вторая же проблема заключается в том, что операция чтения из сокета асинхронна фактическому получению пакетов TCP, что еще больше увеличивает количество переключений контекста.
Чтобы решить эту проблему (а также проблему передачи данных из пространства ядра в пространство пользователя), разработчики Tempesta перенесли HTTP-сервер в стек TCP/IP, который, как известно, находится в режиме ядра. Отличие от аналогичных проектов заключается в том, что Tempesta не использует дисковый кеш — все хранится в оперативной памяти.
Цели проекта Tempesta таковы:
- Создание фреймворка со всеобъемлющим контролем над уровнями стека TCP/IP от сетевого и выше для получения гибких и мощных систем классификации и фильтрации трафика.
- Работа в качестве части стека TCP/IP для эффективной обработки «коротких» соединений, как правило используемых при DDoS-атаках.
- Тесная интеграция с подсистемами Netfilter и LSM, что опять же полезно для выделения и фильтрации больших ботнетов.
- Высокопроизводительная обработка HTTP-сессий и функциональность кеширующего прокси для снижения нагрузки на бэкенд.
- Нормализация пакетов HTTP и их пересылка бэкенду для предотвращения разницы интерпретаций на бэкенде и на данной IPS.
Tempesta представляет собой помесь кеширующего обратного (reverse) HTTP-прокси и брандмауэра с динамическим набором правил. Реализован он в виде нескольких модулей ядра. В частности, были разработаны синхронные сокеты, которые не используют дескрипторы файлов (как это реализовано в сокетах Беркли), поскольку работают они в режиме ядра. Соответственно, уменьшаются и накладные расходы. Потребовалось также внести некоторые изменения и в другие части ядра, что, к слову, улучшило контроль над TCP-сокетами для специально подготовленных модулей ядра. Все входящие пакеты обрабатываются в «нижних половинках» обработчиков прерываний. Это увеличивает частоту попадания нужных данных в кеш CPU и позволяет блокировать входящие пакеты и соединения на самых ранних стадиях.
Tempesta имеет модульную структуру, что дает ему большую гибкость. Поддерживаются следующие типы модулей:
- классификаторы — как следует из названия, позволяют классифицировать трафик и получать статистическую информацию;
- детекторы — определяют и обрабатывают случаи перегрузки бэкенда;
- диспетчеры запросов — распределяют HTTP-запросы по нескольким бэкендам;
- универсальные модули для обработки HTTP-пакетов.
Несмотря на то что изначально Tempesta не разрабатывался как WAF, поддержку такой возможности реализовать нетрудно.
Обработка пакетов и соединений
При получении пакета первым делом вызывается функция ip_rcv()/ipv6_rcv(), он проверяется обработчиками Netfilter. Если он эти обработчики проходит, то передается дальше, в функции tcp_v4_rcv()/tcp_v6_rcv(). Колбэки TCP-сокетов вызываются гораздо позже, тем не менее существуют обработчики, связанные с безопасностью, которые вызываются напрямую из этих функций, — к таковым относится, например, security_sock_rcv_skb(). Эти обработчики и используются Tempesta для регистрации собственных колбэков фильтров и классификаторов для уровня TCP. Синхронные сокеты же обрабатывают TCP на более высоком уровне.
Сетевая подсистема Tempesta работает целиком в контексте отложенных прерываний без использования каких-либо вспомогательных потоков. Входящие пакеты обрабатываются так быстро, как это вообще возможно, — они едва успевают покидать кеш CPU. HTTP-кеш находится целиком в оперативной памяти (загружается он в нее с диска совершенно отдельным от сетевой подсистемы), что, таким образом, избавляет от медленных операций и позволяет обрабатывать все HTTP-запросы в одном SoftIRQ. Некоторые пакеты могут быть переданы процессу режима пользователя, осуществляющему классификацию, которая не требует высокой срочности. HTTP-сообщение может состоять из нескольких пакетов. До тех пор пока оно не будет обработано целиком, его не передадут бэкенду.
Если HTTP-запрос не будет обработан кешем, его отправят бэкенду. Все операции, связанные с данным действием, будут произведены в том же самом SoftIRQ, который получил последнюю часть запроса. Tempesta обрабатывает два типа соединений: подключения от него к серверам бэкенда и подключения клиентов к самому кеширующему серверу. Обработка их (как и обработка пакетов) происходит с помощью все тех же синхронных сокетов.
Tempesta поддерживает пул постоянных соединений с бэкендами. Их постоянство обеспечивается стандартными запросами HTTP keep-alive. Если соединение разрывается, оно восстанавливается — таким образом, при клиентском запросе фронтенд не будет всякий раз устанавливать новое соединение (что, как правило, занимает довольно длительное время), а использует уже готовое.
Если обнаруживается вредоносное соединение, оно попросту убирается из хеш-таблицы соединений и очищаются все соответствующие структуры данных. Клиенту при этом не посылается ни FIN-, ни RST-пакета. Также при этом генерируются правила фильтра, чтобы в дальнейшем этот клиент нас не тревожил.
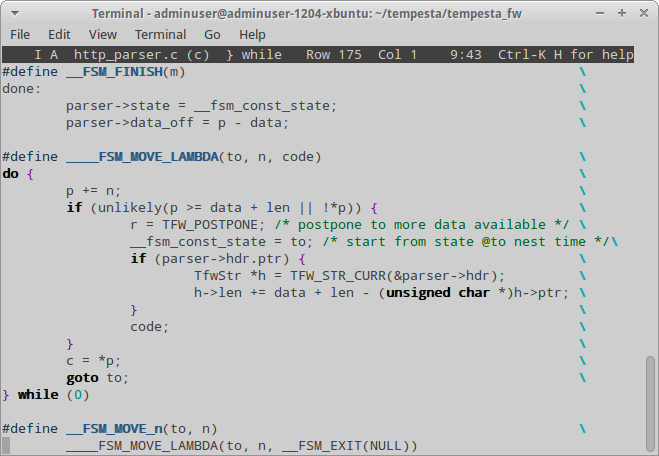
Нормализация и классификация
Как уже упоминалось, существуют методы обхода HTTP IDS/IPS, основанные на разнице интерпретации запросов HTTP самой системой зашиты и сервером. Поскольку существует вероятность некорректного поведения веб-приложения, прокси-серверы, как правило, не изменяют HTTP-запросы. Конечно же, это может привести к возникновению уязвимостей, но при нормальных обстоятельствах и при должном подходе к разработке веб-приложения это допустимо. Для Tempesta это непервоочередная задача, поэтому вместо рабочего кода в нем пока что написаны заглушки. Но уже по ним можно судить, что разработчики планируют возможность нормализации заголовка URI и сообщений POST.
Для классификации трафика предусмотрены несколько механизмов — например, Tempesta предоставляет возможность регистрации обработчиков для использования в модулях-классификаторах:
- classify_ipv4()/classify_ipv6() — вызывается для каждого полученного IP-пакета;
- classify_tcp() — вызывается для пакетов TCP;
- classify_conn_estab()/classify_conn_close() — вызываются во время установления и закрытия TCP-соединения соответственно;
- classify_tcp_timer_retrans() — должен вызываться при пересылке TCP-пакетов клиентам; на деле же код для этого не реализован — вместо него стоит заглушка;
- classify_tcp_timer_keepalive() — должен вызываться при отправке TCP keep-alive пакетов; опять же вместо него стоит заглушка;
- classify_tcp_window() — должен вызываться, когда Tempesta выбирает размер «окна» TCP; заглушка;
- classify_tcp_zwp() — должен вызываться, если клиент послал TCP-пакет с нулевым размером «окна» (в этом случае сервер должен посылать зондирующие пакеты); заглушка.
Как можно заметить, большая часть хуков на момент написания статьи не реализована.
В случае с HTTP-трафиком хуков для его классификации не существует — вместо них должны использоваться хуки GFSM. О последнем стоит поговорить отдельно. GFSM — обобщенный конечный автомат. В отличие от обычного конечного автомата (на основе которого построено подавляющее большинство HTTP-серверов), обобщенный конечный автомат позволяет менять описание процесса обработки во время выполнения. В обычном автомате это описание жестко зашито в код. Так вот, для классификации HTTP-трафика в обобщенном конечном автомате, отвечающем за обработку HTTP-запросов, предусмотрены хуки для отдельных стадий обработки.
Колбэки могут возвращать следующие константы:
- Pass — пакет нормальный, его нужно пропустить в бэкенд;
- BLOCK — пакет выглядит вредоносным, его (как и все последующие пакеты от данного клиента) нужно заблокировать;
- POSTPONE — для окончательного решения данного пакета недостаточно, его нужно отложить, обработать и (в случае положительного решения) отправить в бэкенд.
В настоящий момент в Tempesta присутствует всего один модуль-классификатор, который использует только часть хуков (что естественно, ибо остальные не реализованы). Данный модуль анализирует количество HTTP-запросов, число одновременных подключений, а также количество новых подключений за определенный период от конкретного клиента. Первые два ограничения действуют аналогично модулю лимитирования в nginx. Если клиент превысит хотя бы один лимит, он будет заблокирован.
Кеширование
Как уже упоминалось выше, одна из основных целей Tempesta (если вообще не основная) — предоставление защиты от DDoS-атак. Поскольку данные атаки могут проводиться сотнями (а то и тысячами) ботов, любой прокси, использующий дисковый кеш, попросту задохнется из-за жутчайшего падения производительности. Данное падение производительности происходит по причине архитектурных особенностей обращения к ФС — таких как синхронизация с жестким диском, операции поиска (оптимизированные под файлы и каталоги и не подходящие для поиска внутри определенных файлов).
В противовес этому Tempesta использует легковесную in-memory БД, поддерживающую персистентность объектов кеша, статического контента и правил фильтра. Эта БД может быть использована также для хранения результатов резолвера, событий, логов и дампов трафика.
Поскольку кеш Tempesta хранится в памяти, операций ввода-вывода при взаимодействии с клиентами не производится. HTTP-ответы от бэкендов сохраняются в памяти после их отправки клиентам для ускорения дальнейшей работы — причем сохраняются они целиком, включая заголовок, в буферы, которые напрямую используются в очереди отправки сокетов.
Все файлы кеша отображаются в память и блокируются в ней для минимизации доступа к диску. Персистентность обеспечивается стандартными механизмами диспетчера виртуальной памяти, которые сбрасывают «грязные» страницы памяти на диск. Кроме того, были введены два вспомогательных потока: первый поток выполняет сброс старых и редко элементов кеша, второй же поток сканирует каталог с кешем, используя для этого интерфейс inotify для обнаружения новых или модифицированных файлов. Для их загрузки поток читает данные файлы по частям в специальную область памяти. Затем эти части индексируются БД и могут быть сразу же отправлены клиенту. Это, с одной стороны, означает, что база данных вместо «сырых» данных использует данные, уже подготовленные к отправке. С другой же — для добавления файлов не требуется никаких манипуляций, все происходит во время работы программы.
Заключение
Проект, в общем и целом, достаточно перспективный — тем более что в мире свободного ПО он пока что не имеет аналогов. Но, как всегда, есть у него и недостатки.
Основной недостаток, пожалуй, необходимость патчить ядро. Это, конечно, нивелируется небольшим размером патча, но тем не менее — в случае изменения внутреннего API ядра патч (а следовательно, и сами модули Tempesta) работать не будет. Во-вторых, за примерно полгода уже можно было реализовать хотя бы часть функций, для которых сейчас написаны заглушки. В-третьих, HTTP в режиме ядра как-то не способствует появлению чувства безопасности, во всяком случае, пока проект находится в состоянии альфа-версии. Ну и в-четвертых — проектом занимается малоизвестная российская компания, которая постоянно ищет новых сотрудников, — конечно, это ни о чем не говорит, но лично я предпочел бы увидеть подобную разработку от того же Яндекса.
С другой стороны, исследования показали, что проект из-за использования синхронных сокетов уже сейчас работает гораздо быстрее аналогов пользовательского режима. Правда, результаты его неплохо бы перепроверить, однако факт остается фактом.
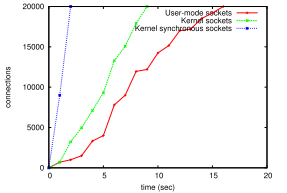
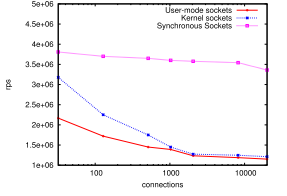
Фреймворк Tempesta пока не готов к промышленному использованию. Однако, поскольку это опенсорс, ты можешь присоединиться к его разработке прямо сейчас. Дерзай!