Содержание статьи
Скорость работы приложений в продакшене — всегда горячая тема. Как, не нагружая сервер на все сто процентов и не мешая работе пользователей, узнать, насколько быстро или медленно все работает? Запустив легкий профилировщик, мы легко получим ответы на эти вопросы.
Когда цена за гигабайт памяти составляет копейки (~0,026 доллара за час в облаке от Amazone), а современные процессоры работают все быстрее с каждым месяцем, производительность ПО во многих случаях оставляет желать лучшего. Ведь часто докупить оперативки и/или процессор оказывается дешевле, чем тратить многие человеко-месяцы на тестирование и исправление проблем с производительностью. Но бывает и наоборот — стоит исправить буквально две строчки кода, как все начинает просто летать. Главное — найти эти самые две строчки кода. Здесь все как в старом анекдоте: «взял один доллар за то, что забил гвоздь, и 99 долларов за то, что знал, куда его забить».
Профилирование vs тестирование производительности
Итак, как нам найти узкие места в нашем софте? Существуют всего два способа (вариант «пользователи не жалуются — значит, все хорошо» я не беру в расчет): performance-тестирование и профилирование (англ. profiling). Тестировать производительность можно, например, с целью проверить, что твое приложение будет работать под определенной нагрузкой, или понять, насколько быстрее новая версия по сравнению с предыдущей.
К сожалению, перформанс-тестирование не всегда дает нужные результаты. Как правило, тестирование производительности выполняется до момента запуска ПО в продакшен. А это значит, что оно основывается (или как минимум должно основываться) на нефункциональных требованиях к разрабатываемому софту. Но мир далек от совершенства, и часто после релиза твою программу/сервис/веб-приложение начинают использовать не так, как ты этого ожидал. Правило Парето еще никто не отменял, и если ты оптимизировал не те 20% своего кода, то тебе придется начинать все по новой. Но теперь уже с учетом того, что будут делать пользователи.
В отличие от перформанс-тестов, цель профилирования — собрать характеристики работы программы для дальнейшей оптимизации.
Как видишь, цели разнятся достаточно сильно. Но это и неудивительно — для каждой задачи должен быть свой инструмент, и швейцарский нож не всегда подходит.
Профилирование интересно еще и тем, что его часто, хотя и не всегда (зависит от типа конкретного профайлера), можно применять прямо на боевом сервере, так как профайлеры практически не влияют на производительность — потерять 1–2% производительности сервера не так страшно, как проиметь >50–70% ресурсов на перформанс-тесты. Тем более что такие компании, как Dropbox, успешно это делают. Из плюсов такого подхода можно отметить следующее:
- профилирование будет работать именно в том окружении, которым будут пользоваться клиенты и/или юзеры, — нет проблемы «у меня оно и так быстро работает»;
- тебе не нужно придумывать сценарии тестирования производительности — пользователи сами это сделают, поэтому тебе сразу станет понятно, какие 20% своего кода нужно исправить сейчас, а какие можно отложить.
Оговорюсь сразу, что на производительность ПО влияет уж очень много факторов, поэтому полагаться исключительно на цифры не стоит. Я рекомендую все же вычислять какие-то средние значения — так будет более объективно. Иначе разброс цифр получится очень большой.
Например, на производительность веб-приложения могут влиять как неоптимальный запрос к БД, так и настройки кеширования в файловой системе. И это если отбросить то, что даже на одинаковых на первый взгляд серверах скорость работы HDD/SSD/RAM может отличаться. Да, это будут какие-то миллисекунды, но в масштабах десятка тысяч посетителей в день/час/минуту это может оказаться более чем существенно. Я уже не говорю про настройку СУБД, веб-серверов, сети и прочее — это потянет на отдельную статью.
Итак, вернемся к нашей проблеме — профилированию Python-приложений в production. В качестве профилировщика я выбрал plop — простой и эффективный статистический профайлер от одного из авторов Tornado, который использует у себя в продакшене Dropbox. Профайлер настолько прост и универсален, что можно работать практически с любой программой, написанной на Python. Особо хочется отметить, что у него нет зависимостей — а это сильно расширяет возможности по его использованию. Да, в репозитории проекта есть requirements.txt с одной лишь строчкой — tornado, но это нужно только для того, чтобы просматривать отчет.
Установка plop’а
К сожалению, на момент написания статьи я не нашел публичных репозиториев с DEB- и RPM-пакетом для plop’а. Это может быть аргументом против его использования в продакшене, но он отлично работает в virtualenv, и всегда можно найти компромисс с администратором и/или devops-инженером, ответственным за установку ПО на сервер.
Особенности работы статистического профайлера
Принцип работы любого статистического профайлера, в том числе и plop’а, выглядит примерно так.
Раз в N-й отрезок времени профайлер смотрит, какая функция программы работает в данный момент, и записывает эту информацию. В идеале информацию профайлер должен собирать как можно дольше, иначе данные будут очень неточными. Также статистические профайлеры могут не успевать логировать данные в функциях, которые не работают значительно быстрее N; для этого следует собирать данные о работе программы как можно дольше и, при возможности, выполнять одно и то же действие несколько раз. Таким образом, статистический профайлер может показать не всю информацию о работе исследуемой программы, но проблемные места он обязательно выявит.
Продукт еще сыроват, но автор достаточно быстро принимает патчи с помощью pull-request’ов на GitHub. Я бы сказал, что plop прекрасно справляется со своей первоначальной задачей — сбором метрики, а вот над обработкой данных нужно еще поработать — в итоговом отчете очень много лишней информации. Таким образом, мы не только получаем отчет о своей программе, но и видим, что и сколько раз вызывается во всех библиотеках, которые используются. Но plop может генерировать данные в JSON, а как его обрабатывать — это уже задача не профайлера. Некоторые могут назвать недостатком то, что у plop’а нет документации. Но для читателей Х это не должно быть проблемой: во-первых, там есть минимально необходимая документация по использованию и запуску, а во-вторых, разобраться в нескольких сотнях строчек кода не составит труда даже начинающему Python-программисту.
Принцип работы plop’а
При дефолтных настройках plop работает следующим образом.
На протяжении 30 с (duration) создается таймер, который каждые 10 мс останавливает выполнение программы, записывает ее текущие stack trace с помощью функции sys._current_frames(). Параметр duration при запуске plop’а из командной строки по умолчанию будет равен не 30, а целых 3600 с, то есть час! Разница в 120 раз может влиять на точность вычисления, нужно об этом помнить и быть осторожным. То, что профайлер работает не всегда, а только в определенный отрезок времени, очень хорошо сказывается на производительности и позволяет использовать его в продакшене: например, на таком достаточно большом веб-приложении, как OpenStack Cinder API, потеря скорости была всего overhead was 3.27297403843e-05 per sample (0,00327297403843%).
После работы профайлера можно сгенерировать HTML-страницу и посмотреть прямо в браузере красивый отчет, созданный с помощью библиотеки D3.js.

Xakep #198. Случайностей не бывает
Сигналы и таймеры
Вся работа plop’а построена на обработке сигналов по таймеру: грубо говоря, каждые X миллисекунд приложение будет получать сигнал Y, по которому оно остановится и запишет данные, необходимые для профайлинга.
Всего в *nix-системах существует три типа таймеров (man setitimer), которые нам доступны. Управляются они следующими сигналами:
signal.ITIMER_REAL— уменьшает таймер реального времени;signal.ITIMER_VIRTUAL— уменьшает интервальный таймер только тогда, когда выполняется наш процесс;signal.ITIMER_PROF— то же самое, что и предыдущий, только считается и системное время.
В plop’е по умолчанию используется virtual mode, это означает, что вычисляется только время исполнения питоновского кода. Этот параметр устанавливается или параметром --mode (при запуске из командной строки), или соответствующим аргументом mode в конструкторе класса Collector.
Запуск!
Есть два способа запустить профайлер. Первый способ более общий и позволяет запустить профайлер с любой программой, написанной на Python’е, а второй требует небольшого изменения кода. Рассмотрим оба подробнее.
Запускаем plop без модификации исходников
Тут все очень просто. Мы запускаем на выполнение модуль plop.collector и в качестве аргументов указываем нашу программу:
python -m plop.collector <имя нашей программы>Все. Теперь после завершения программы будет сгенерирован файл с данными профайлера. По умолчанию он называется /tmp/plop.out. Также plop напишет, сколько времени потратилось на профайлер.
Продвинутый способ запустить профайлер
В предыдущем способе запуска есть один недостаток — профайлер будет работать всегда. Пусть он и не сильно влияет на производительность, но на очень загруженной системе, когда каждая миллисекунда на счету, это может быть ключевым доводом против использования профайлера. Решить эту проблему можно, интегрировав plop в свой проект. Просто добавляем в зависимости строку plop, а далее в коде мы уже сами можем выбирать, когда и как включать и выключать профайлер. Разберем такой вариант подробнее.
Этот способ удобен тем, что его можно включать и выключать в процессе работы приложения без даунтайма, — достаточно всего лишь реализовать нужные REST API. Хотя есть и более удобный способ: так как профайлер, как правило, запускает кто-либо с админскими правами, то нам не надо давать для этого REST API, пусть даже только админу, — нужно только реализовать поддержку сигнала SIGHUP и менять значение в конфиге. При получении сигнала SIGHUP приложения, как правило, перечитывают свои конфиги без перезагрузки. Этот способ будет работать только при условии, что есть доступ к консоли сервера, на котором крутится наше приложение.
Вся «магия» профайлера собрана в классе Collector. Как несложно догадаться, для запуска профайлера нам надо вызвать метод start и, соответственно, метод stop для остановки. Поэтому вам необходимо всего лишь создать экземпляр класса Collector и в нужное время включить и/или выключить его. После чего сохранить собранные данные в специально отведенном для этого месте — и можно смотреть на результаты профайлера.
В мире кругов
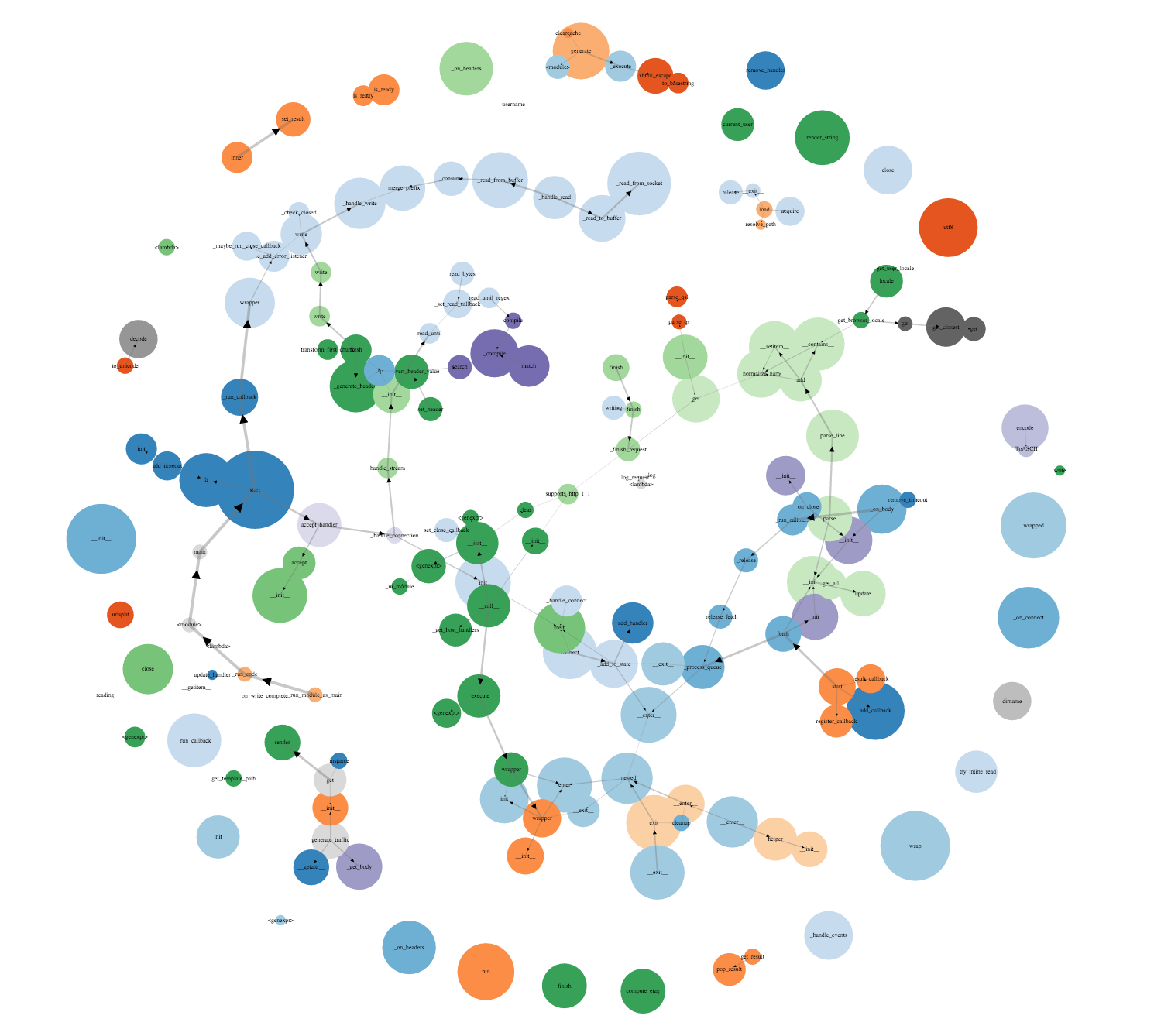
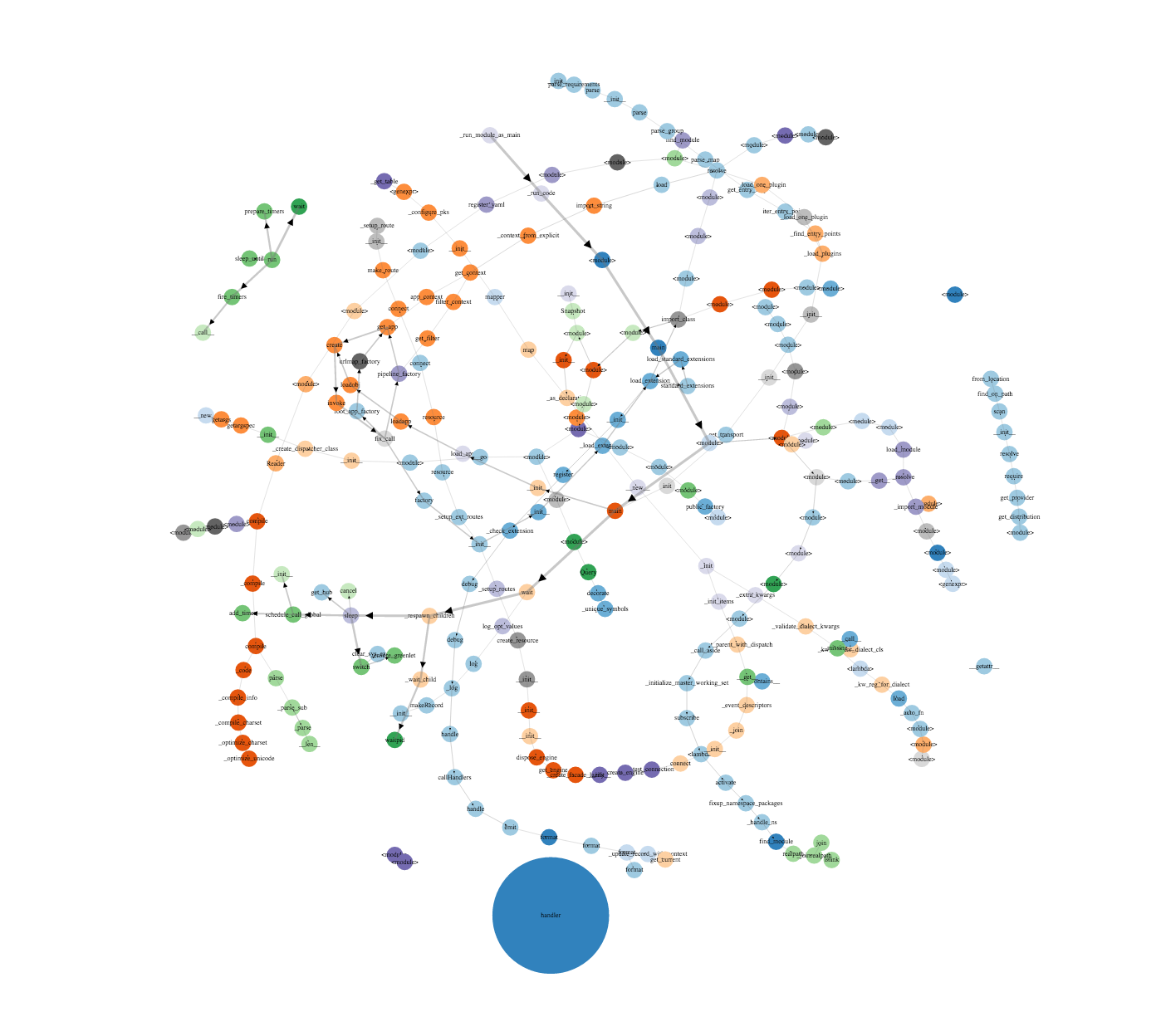
Итак, с конфигурацией и запуском мы разобрались, осталось разобраться, как работать с данными профайлера. И если в результатах работы профайлера простого приложения все легко и понятно, то стоит только подключить его к чему-нибудь, содержащему что-то вроде Flask или Django... В общем, сначала выдача кажется грандиозной, но потом ты внезапно осознаешь, что ничего в ней не понимаешь.
Plop строит дерево вызовов всех функций, включая импортирование модулей. Размер кругов показывает, как много времени было потрачено на функцию, а чем толще стрелка, тем чаще ее вызывали. Стоит отметить, что на графике самый большой круг и, соответственно, самое большое время будет занимать сам профайлер, но на практике это число очень маленькое.
Визуализация очень хорошо показывает, сколько (не)нужных импортов у нас выполняется при работе программы (см. рис. 2). Очень много данных будет поступать от использованных фреймворков (SQLAlchemy, Django и так далее), поэтому имеет смысл с помощью plop viewer’а получить нужные данные в формате JSON и обработать их, удалив записи о профайлинге, например SQLAchemy. Делается это так:
var nodes=[];
for (var i=0; i<data.nodes.length; i++){
if (data.nodes[i].id[0].indexOf('cinder') > 0){
nodes.push(data.nodes[i]);
}
}Такой нехитрый JavaScript покажет нам исключительно данные по нужным нам файлам, но при этом ломает дерево вызовов (рис. 3).
В случае же нехватки данных мы не увидим разницу в выполнении методов и функций на диаграмме (рис. 4).
Подводя итоги
Если говорить кратко, то профилирование приложений с использованием статистического профайлера дает не слишком детальную картину происходящего, но практически не влияет на производительность. Смотреть на результаты такого профайлера нужно внимательно, и будь готов к тому, что результаты могут оказаться неточными, а для их сбора может понадобиться немало времени. У каждого инструмента есть свои плюсы и минусы и, самое главное, сфера применения. Поэтому выбирай инструмент, который подходит конкретно для поставленной задачи. Хорошего профайлинга и быстрого софта!