Часто при аудите веб-приложений требуется проанализировать ответ веб-сервера и на основе его анализа сделать какие-то выводы (желательно в сводную таблицу результатов). Burp Intruder — популярный инструмент для комбинированных атак на параметры HTTP-запроса. Но кроме извлечения данных из HTML-ответов по простейшей регулярке, он не умеет никак их анализировать. Исправим это и прикрутим к Intruder свой кастомный процессинг ответов сервера на Python.
Задача
Для демонстрации подхода возьмем простую задачу: есть форум, который по URL вида http://forum.local/groups/<ID>/users/ выдает список юзеров из группы с ID =
GET /groups/1/users/ HTTP/1.1
Host: forum.local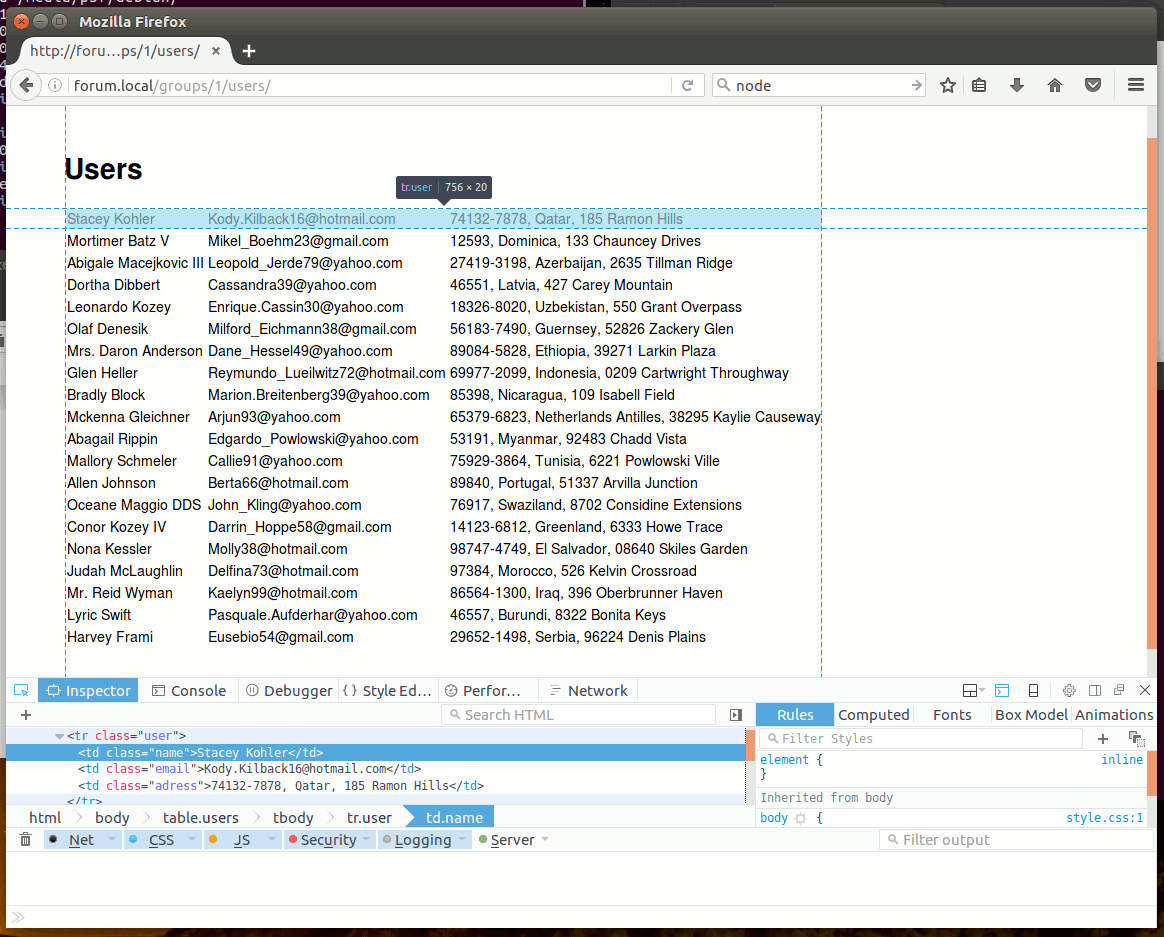

Ответ сервера:
...
<table class="users">
<tbody>
<tr class="user">
<td class="name">Etha Marquardt</td>
<td class="email">Cyrus.Kemmer@yahoo.com</td>
<td class="adress">22579-1558, Macedonia, 528 Heathcote Mount</td>
</tr>
<tr class="user">
<td class="name">Alexzander Ritchie I</td>
<td class="email">Alejandra.Frami86@yahoo.com</td>
<td class="adress">62299, Cuba, 147 Hudson Plains</td>
</tr>
...
</tbody>
</table>
...Очевидно, нам нужно распарсить HTML-страничку и подсчитать количество <tr class="user">, а затем вывести это значение в таблицу результатов. Burp не предоставляет возможностей стороннего постпроцессинга ответов. Научим его!
Решение
Идея состоит в том, чтобы:
- Похукать момент получения ответа сервера.
- Обработать его своим кодом.
- Добавить результат вычислений в тот же самый ответ в специальном формате и отправить «дальше».
- Дальше грепнуть это значение по регулярке штатными средствами Burp Intruder.
Чтобы реализовать этот трюк, нужно написать расширение для Burp Suite. Расширения для Burp пишутся на Java, Ruby или Python. Мы напишем на Python.
Для начала нужно установить Jython. Скачай его, разархивируй в любую папку и укажи Бурпу путь к бинарнику во вкладке Extender => Options => Python environment.
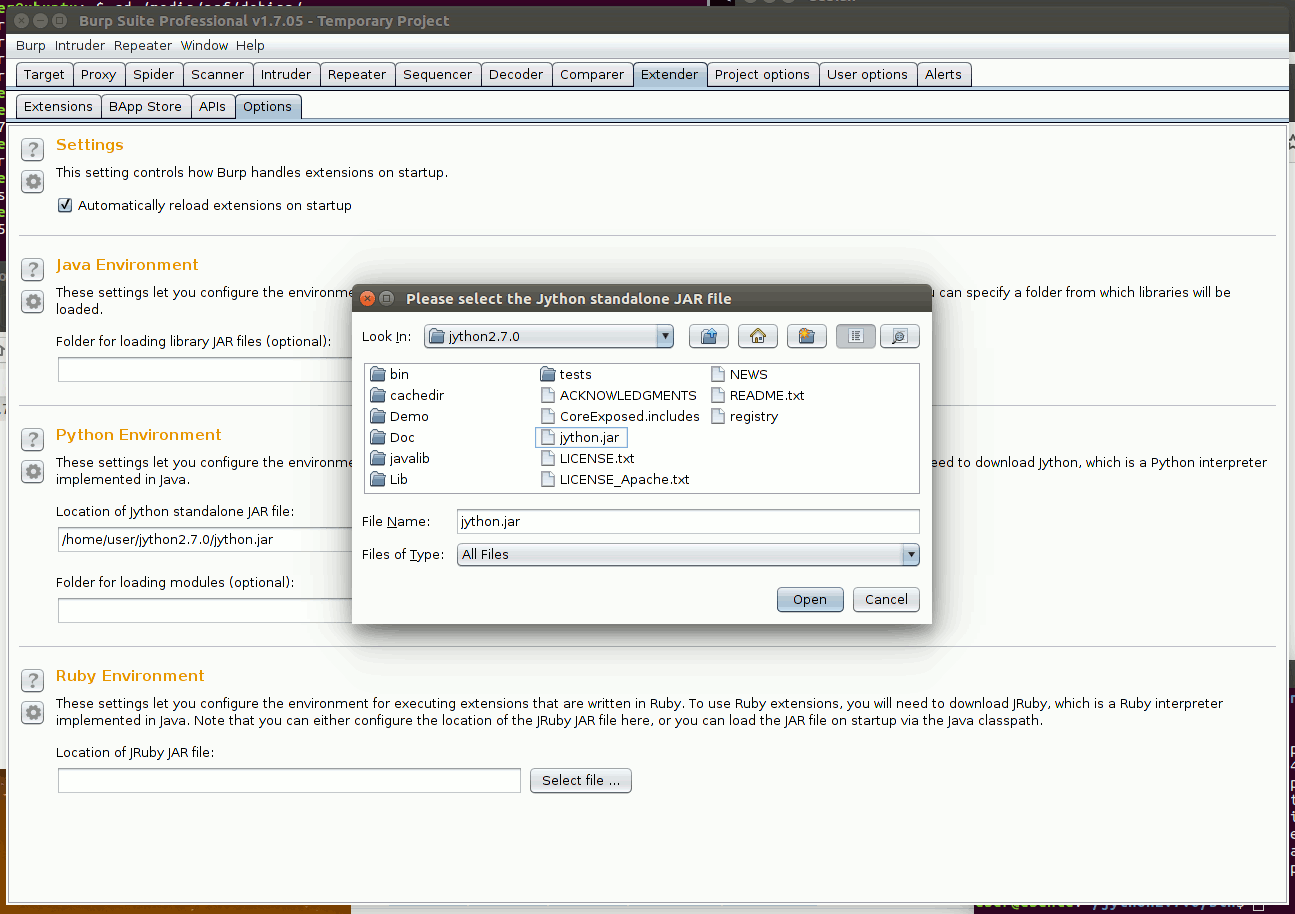
Для разбора HTML нужно поставить HTML-парсер. Я буду использовать Beautiful Soup. Ставь через pip, но учти, что нужно пользоваться не системным pip’ом, а jython’овским, который лежит в директории бинарника jython (см. предыдущий скрин):
user@localhost:~/jython2.7.0/bin$ ./pip install beautifulsoup4
...После этого создавай файл response_processor.py и добавляй следующий код:
from burp import IBurpExtender
from burp import IHttpListener
from burp import IHttpRequestResponse
from burp import IResponseInfo
from bs4 import BeautifulSoup
class BurpExtender(IBurpExtender, IHttpListener):
def registerExtenderCallbacks(self, callbacks):
self._callbacks = callbacks
self._helpers = callbacks.getHelpers()
self._callbacks.setExtensionName("Count recipies")
callbacks.registerHttpListener(self)
def processHttpMessage(self, toolFlag, messageIsRequest, messageInfo):
if not messageIsRequest: # only handle responses
response = messageInfo.getResponse() # get Response from IHttpRequestResponse instance
responseStr = self._callbacks.getHelpers().bytesToString(response)
responseParsed = self._helpers.analyzeResponse(response)
# body
body = responseStr[responseParsed.getBodyOffset():]
soup = BeautifulSoup(body, 'html.parser')
users = soup.findAll("tr", { "class" : "user" })
body += '\n<!--USERS:%s-->' % len(users)
# headers
headers = responseParsed.getHeaders()
headers.add('X-Custom-Users: %s' % len(users))
# combine
httpResponse = self._callbacks.getHelpers().buildHttpMessage(headers, body)
# set
messageInfo.setResponse(httpResponse)
returnКратко:
- Получаем body.
- Парсим его содержимое.
- Считаем количество tr’ов класса
user. - Добавляем к body строчку
!--USERS:N-->', где N — количество юзеров.
Также в блоке есть пример модификации заголовков HTTP-ответа. Правильнее передавать небольшие значения через X-заголовки, но для демонстрации сойдет и так. Больше комментариев у автора оригинального скрипта на Гитхабе.
Загружаем наше расширение в Burp в соответствующей вкладке.
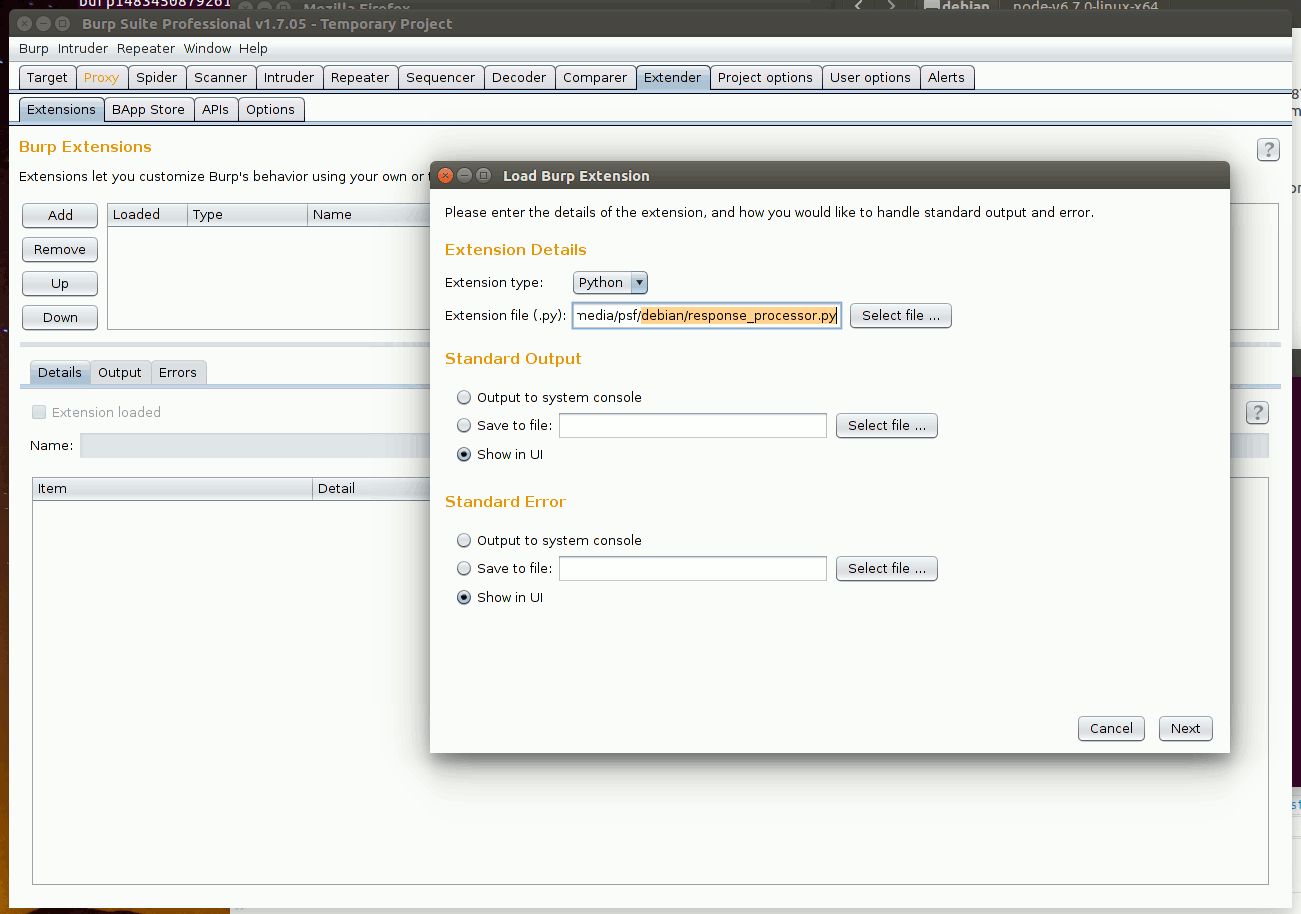
Пробуем запустить Intruder с ним и видим, что теперь в body и headers дописываются нужные данные.
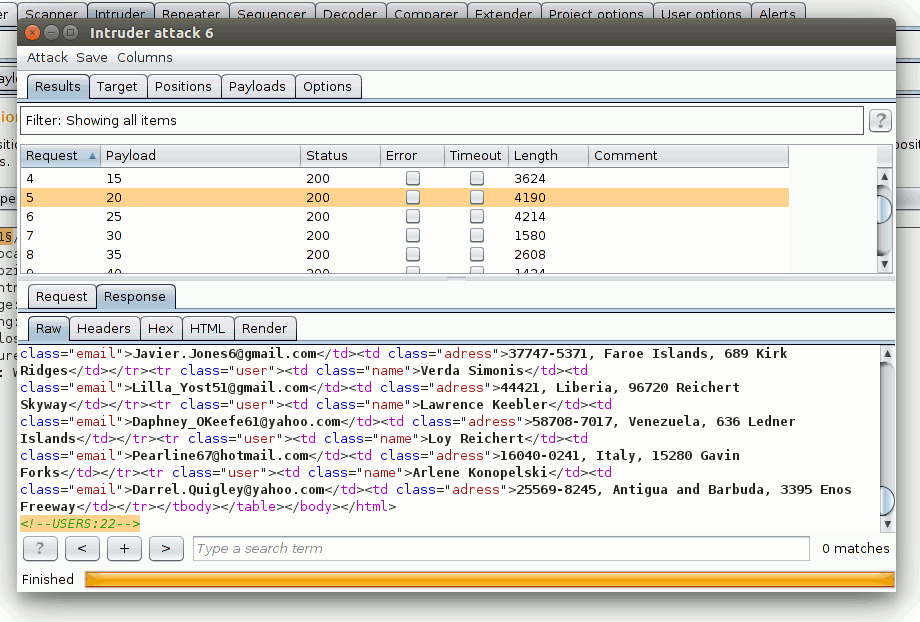
Теперь остается только грепнуть это значение по простейшей регулярке, и вуаля! Обрати внимание, что результаты грепаются как строка, это будет влиять на сортировку.
Разумеется, пример с подсчетом DOM-элементов чисто умозрительный. В реальности ты можешь проводить абсолютно любой постпроцессинг данных с использованием всей мощи Python и пробрасывать данные в таблицу результатов таким нехитрым трюком. Главное, экранируй большие данные, иначе регулярки могут неправильно сработать.
Кстати, перед тем, как писать эту заметку, я засабмиттил тикет разработчику Burp, PortSwigger. В ответ они подтвердили, что штатными средствами или через расширение это сделать нельзя:
You’re right, there isn’t any way to do this natively within Burp. And currently, there is no way for an extension to provide additional data columns in the Intruder attack results.
Как видишь, иногда достаточно проявить немного смекалки и взглянуть на задачу с другой стороны, чтобы найти решение. Удачи 🙂