

Содержание статьи
Часто возникает задача периодически парсить какой-нибудь сайт на наличие новой информации. Например, если ты пишешь агрегатор контента с новостного сайта или форума, в котором нет поддержки RSS. Проще всего написать скрепер на Питоне и разобрать полученный HTML через beautifulsoup или регулярками. Однако есть более элегантный способ — самому сделать недостающие API для сайта и получать ответы в привычном JSON, как будто бы у сайта есть нативный API.
Не будем далеко ходить за примером и напишем парсер контента с «Хакера». Как ты знаешь, сайт нашего журнала сейчас не предоставляет никакого API для программного получения статей, кроме RSS. Однако RSS не всегда удобен, да и выдает далеко не всю нужную информацию. Исправим это!
Постановка задачи
Итак, наша задача: сделать API вида GET /posts, который бы отдавал десять последних статей с «Хакера» в JSON. Также нам нужно иметь возможность задавать сдвиг, то есть раз за разом получать следующие десять постов.
GET /postsОтвет должен быть таким:
{
"posts": [
{
title: "Американская компания захватила командный сервер хакеров из Ирана",
excerpt: "Компания Palo Alto Networks сумела вывести из строя командные серверы, которые в течение девяти лет использовала группа хакеров из Ирана.",
date: "2 часа назад"
url: "https://xakep.ru/2016/06/30/iran-sinkhole/",
image: "https://xakep.ru/wp-content/uploads/2016/06/Ahmadinejad-visit-to-Natanz-w-computers-712x400.jpg"
},
{
title: "Американская компания захватила командный сервер хакеров из Ирана",
excerpt: "",
date: ""
url: "",
image: ""
},
...
]
}Также нужно иметь возможность получать следующие десять постов — со второй страницы, третьей и так далее. Это делается через GET-параметр вида GET /posts?page=2. Если page в запросе не указан, считаем его равным 1 и отдаем посты с первой страницы «Хакера». В общем, задача ясна, переходим к решению.
Фреймворк для веба
WrapAPI — это довольно новый (пара месяцев от роду) сервис для построения мощных кастомных парсеров веба и предоставления к ним доступа по API. Не пугайся, если ничего не понял, сейчас поясню на пальцах. Работает так:
- Указываешь WrapAPI страницу, которую нужно парсить (в нашем случае главную «Хакера» — https://xakep.ru/).
- Говоришь, с какими параметрами обращаться к серверу, каким HTTP-методом (GET или POST), какие query-параметры передавать, какие POST-параметры в body, куки, хедеры. Короче, все, что нужно, чтобы сервер вернул тебе нормальную страничку и ничего не заподозрил.
- Указываешь WrapAPI, где на полученной странице ценный контент, который надо вытащить, в каком виде его представлять.
- Получаешь готовый URL для API вида
GET /posts, который вернет тебе все выдранные с главной «Хакера» посты в удобном JSON!
Немного о приватности запросов
Ты наверняка уже задумался о том, насколько безопасно использовать чужой сервис и передавать ему параметры своих запросов с приватными данными. Тем более что по умолчанию для каждого нового API-проекта будет создаваться публичный репозиторий и запускать API из него сможет любой желающий. Не все так плохо:
- Каждый API-репозиторий (а соответственно, и все API-запросы в нем) можно сделать приватным. Они не будут показываться в общем списке уже созданных API на платформе WrapAPI. Просто выбери достаточно сложное имя репозитория, и шанс, что на него кто-то забредет случайно, сведется к минимуму.
- Любой запрос к WrapAPI требует специального токена, который нужно получить в своей учетке WrapAPI. То есть просто так узнать URL к твоему репозиторию и таскать через него данные не получится. Токены подразделяются на два типа: серверные и клиентские, для использования прямо на веб-страничке через JavaScript. Для последних нужно указать домен, с которого будут поступать запросы.
- Ну и наконец, в скором времени разработчик обещает выпустить self-hosted версию WrapAPI, которую ты сможешь поставить на свой сервер и забыть о проблеме утечек данных (конечно, при условии, что в коде WrapAPI не будет бэкдоров).
Приготовления
Несколько простых шагов перед началом.
- Идем на сайт WrapAPI, создаем новую учетку и логинимся в нее.
- Устанавливаем расширение для Chrome (подойдет любой Chromium-based браузер), открываем консоль разработчика и видим новую вкладку
WrapAPI. - Переходим на нее и логинимся.
Это расширение нам понадобится для того, чтобы перехватывать запросы, которые мы собираемся эмулировать, и быстро направлять их в WrapAPI для дальнейшей работы. По логике работы это расширение очень похоже на связку Burp Proxy + Burp Intruder.

Xakep #210. Краткий экскурс в Ethereum
Отлавливаем запросы
Теперь нужно указать WrapAPI, какой HTTP-запрос мы будем использовать для построения нашего API. Идем на сайт «Хакера» и открываем консоль разработчика, переключившись на вкладку WrapAPI.
Для получения постов я предлагаю использовать запрос пагинации, он доступен без авторизации и может отдавать по десять постов для любой страницы «Хакера», возвращая HTML в объекте JSON (см. ниже).
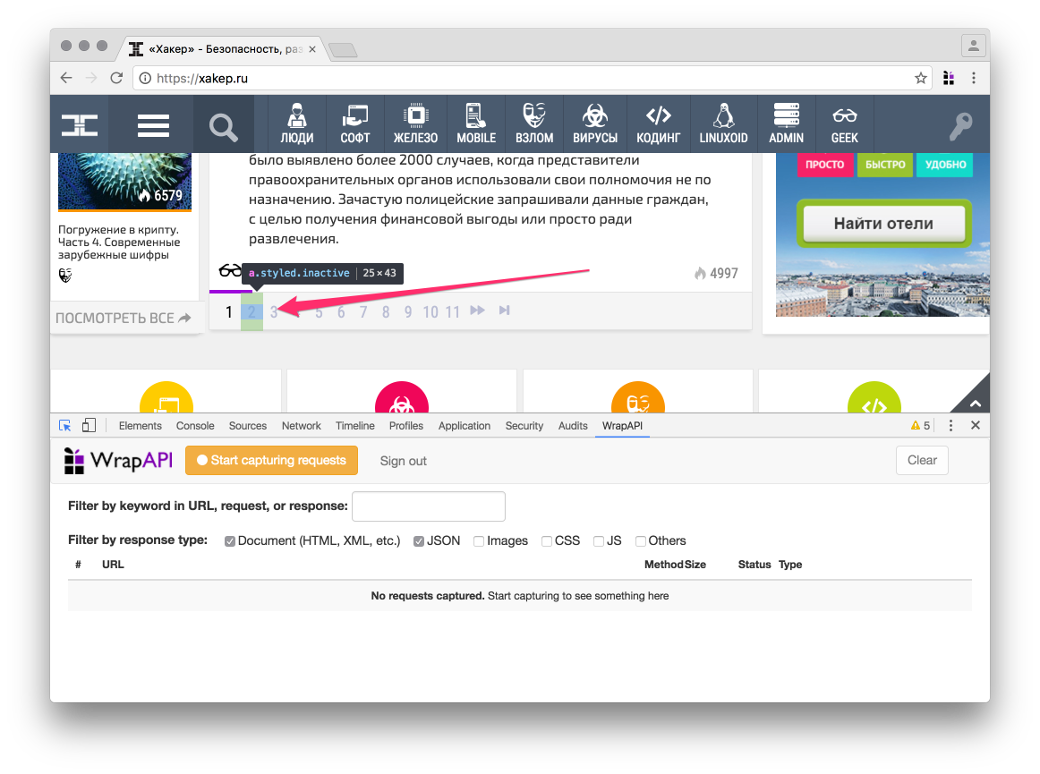
Чтобы WrapAPI начал перехватывать запросы, нажми Start capturing requests и после этого выполни целевой запрос (на пагинацию). Плагин поймает POST-запрос к странице https://xakep.ru/wp-admin/admin-ajax.php с кучей form/urlencoded-параметров в теле, в том числе и номером страницы. Ответом на запрос будет JSON-объект с параметром content, содержащий закешированный HTML-код с новыми постами. Собственно, этот блок и нужно парсить WrapAPI.
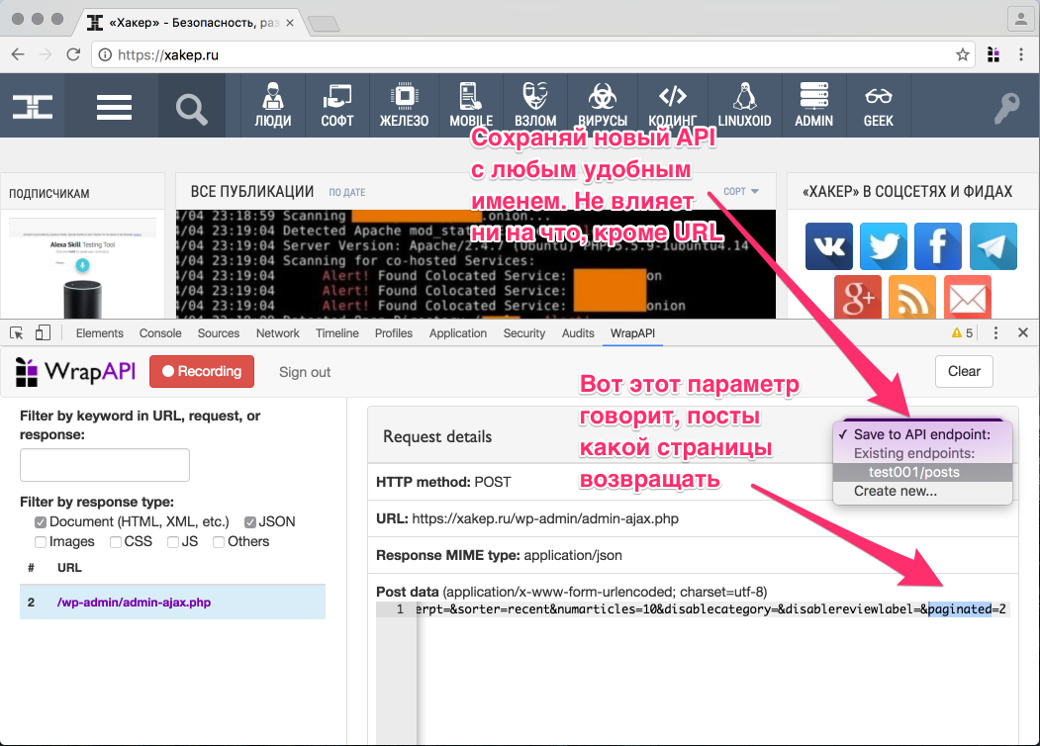
Конфигурируем WrapAPI
После того как ты выбрал нужное имя для твоего репозитория (я взял test001 и endpoint posts) и сохранил его на сервер WrapAPI через расширение для Chrome, иди на сайт WrapAPI и открывай репозиторий. Самое время настраивать наш API.
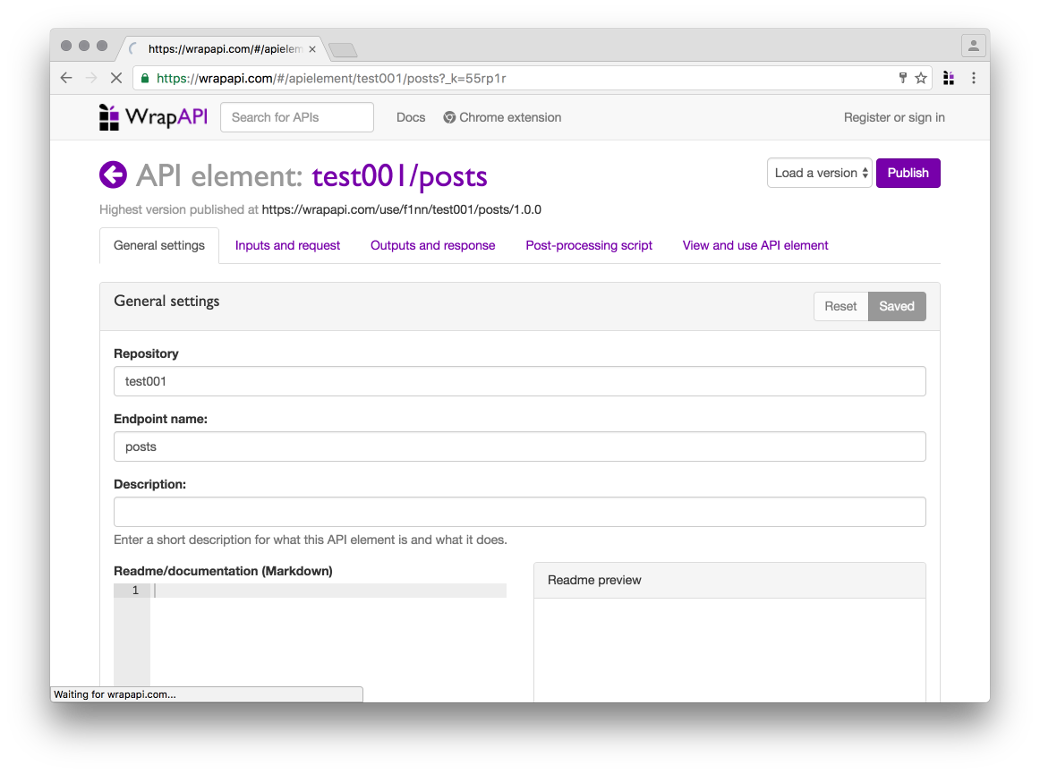
Переходи на вкладку Inputs and request. Здесь нам понадобится указать, с какими параметрами WrapAPI должен парсить запрашиваемую страницу, чтобы сервер отдал ему валидный ответ.
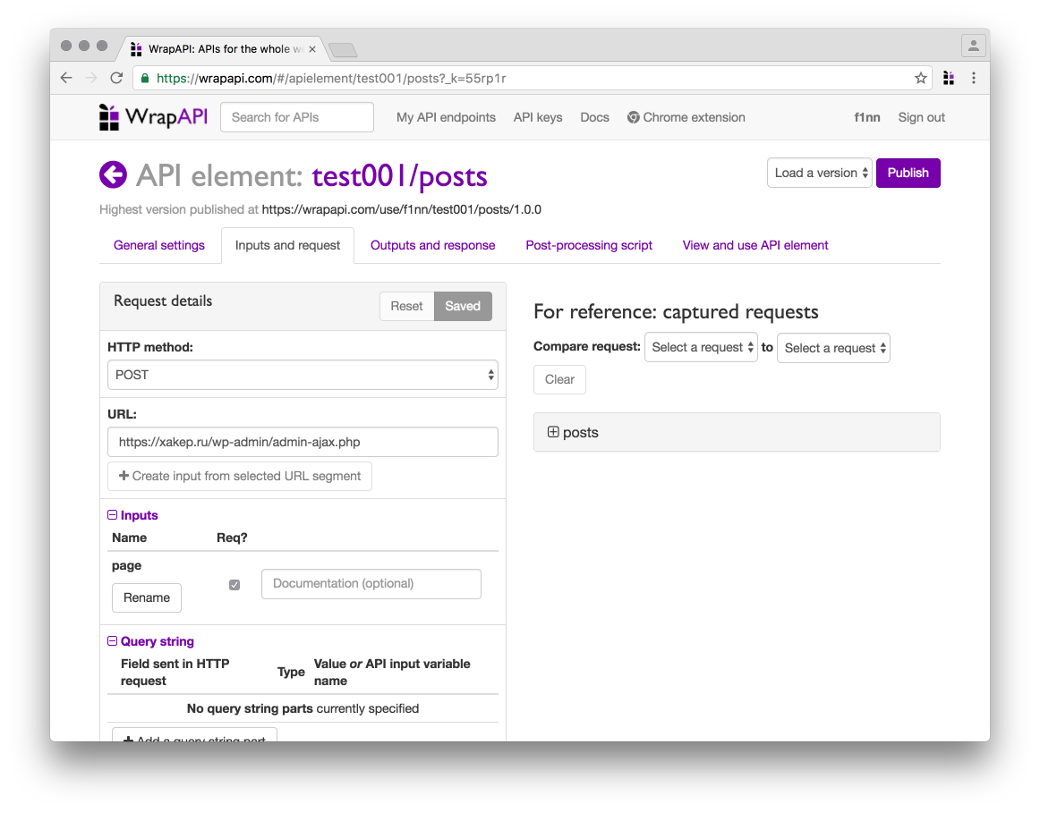
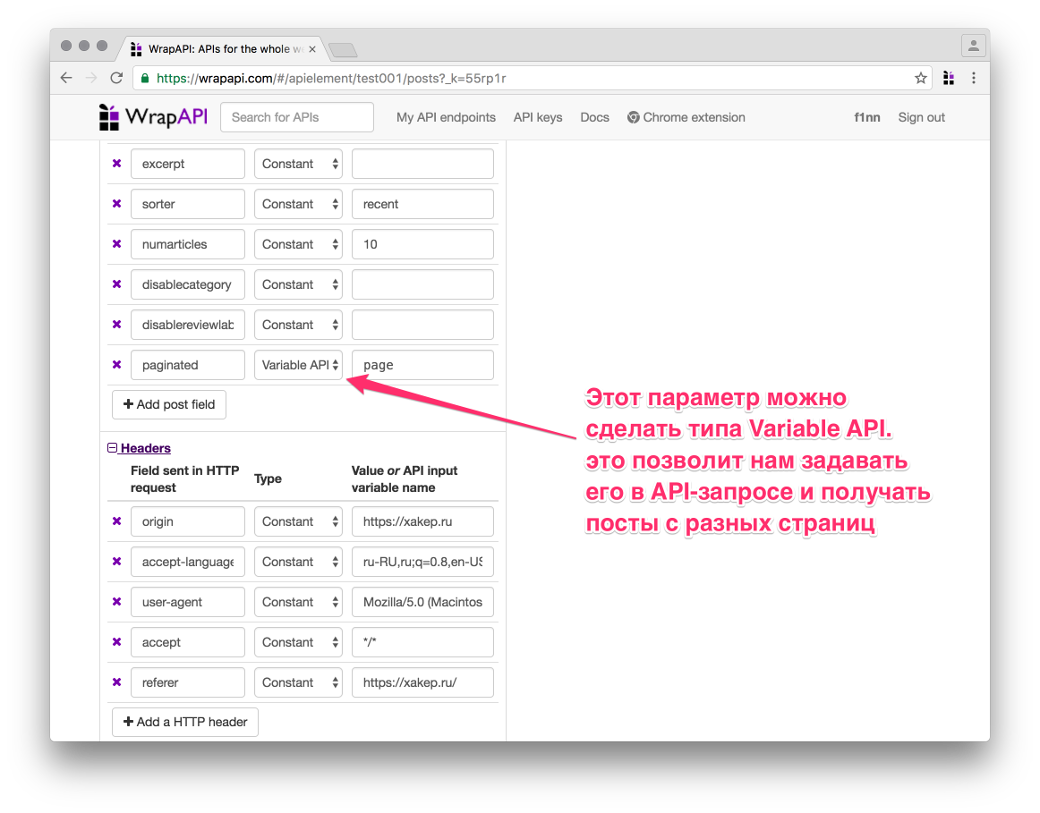
Аккуратно перебей все параметры из пойманной WrapAPI полезной нагрузки (POST body payload) в поле слева. Для всех параметров, кроме paginated, выставь тип Constant. Это означает, что в запросы к серверу будут поставляться предопределенные значения, управлять которыми мы не сможем (нам это и не нужно). А вот для paginated выставляй Variable API, указав имя page. Это позволит нам потом обращаться к нашему API по URL вида GET /posts?page=5 (с query-параметром page), а на сервер уже будет уходить полноценный POST со всеми перечисленными параметрами.
Заголовки запроса ниже можно не трогать, я использовал стандартные из Chromium. Если парсишь не «Хакер», а данные с какого-нибудь закрытого сервера, можешь подставить туда нужные куки, хедеры, basic-auth и все, что нужно. Одним словом, ты сможешь настроить свой запрос так, чтобы сервер безо всяких подозрений отдал тебе контент.
Учим WrapAPI недостающим фичам
Теперь нужно указать WrapAPI, как обрабатывать полученный результат и в каком виде его представлять. Переходи на следующую вкладку — Outputs and response.
INFO
Небольшой глоссарий, прежде чем идти дальше:
- Output — фильтр-постпроцессор контента, который принимает на входе сырой ответ сервера, а возвращает уже модифицированный по заданным правилам. Они бывают нескольких типов. Самые часто используемые:
- JSON выбирает содержимое указанного атрибута, который подан на вход JSON-объекта, и возвращает его значение как строку;
- CSS выбирает элементы DOM по указанному CSS-селектору (например, ID или классу) и возвращает их значение, атрибут или весь HTML-тег целиком. Может вернуть как одну строку, так и массив найденных вхождений;
- Regular expression выбирает вхождения по регулярному выражению, в остальном то же, что и предыдущий output;
- HTTP Header выбирает значение HTTP-заголовка ответа сервера и возвращает его строкой;
- Cookie выбирает значение Cookie, полученной в ответе от сервера, и возвращает его строкой.
- Output Scenario — набор аутпутов, которые объединены в одну или несколько параллельных цепочек. По сути — почти весь набор препроцессоров, которые превращают серверный ответ в нужный нам формат.
- Test case — сохраненный ответ сервера, на котором тестируются обработчики и подбирается нужная цепочка аутпутов.
Создай новый test case, сохрани его под именем page1. Теперь посмотри, что вернул сервер. Это должен быть объект JSON, одно из полей которого содержит кусок HTTP-разметки с перечислением запрошенных постов.
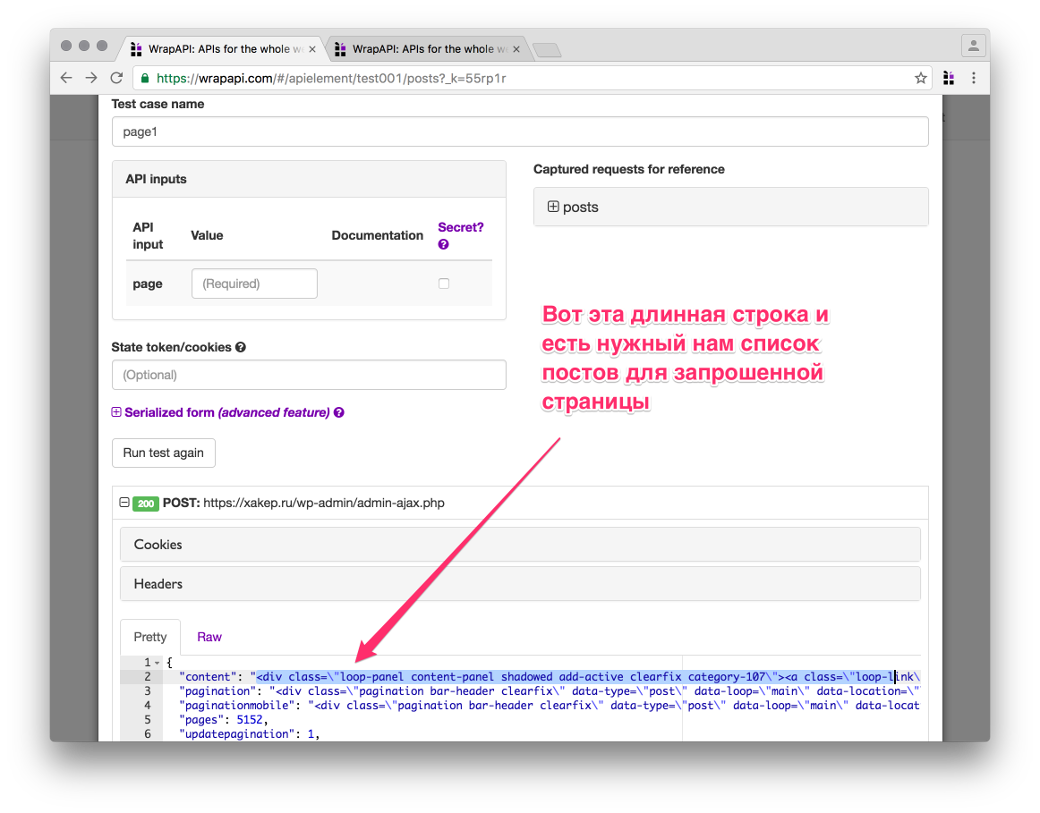
JSON output
Первым делом нужно вытащить из объекта JSON значение атрибута content. Создавай новый output типа JSON и в появившемся модальном окне указывай имя параметра content. Сразу же под текстовым полем WrapAPI подсветит найденное значение выходной строки. То, что нам нужно. Сохраняем output и идем дальше.
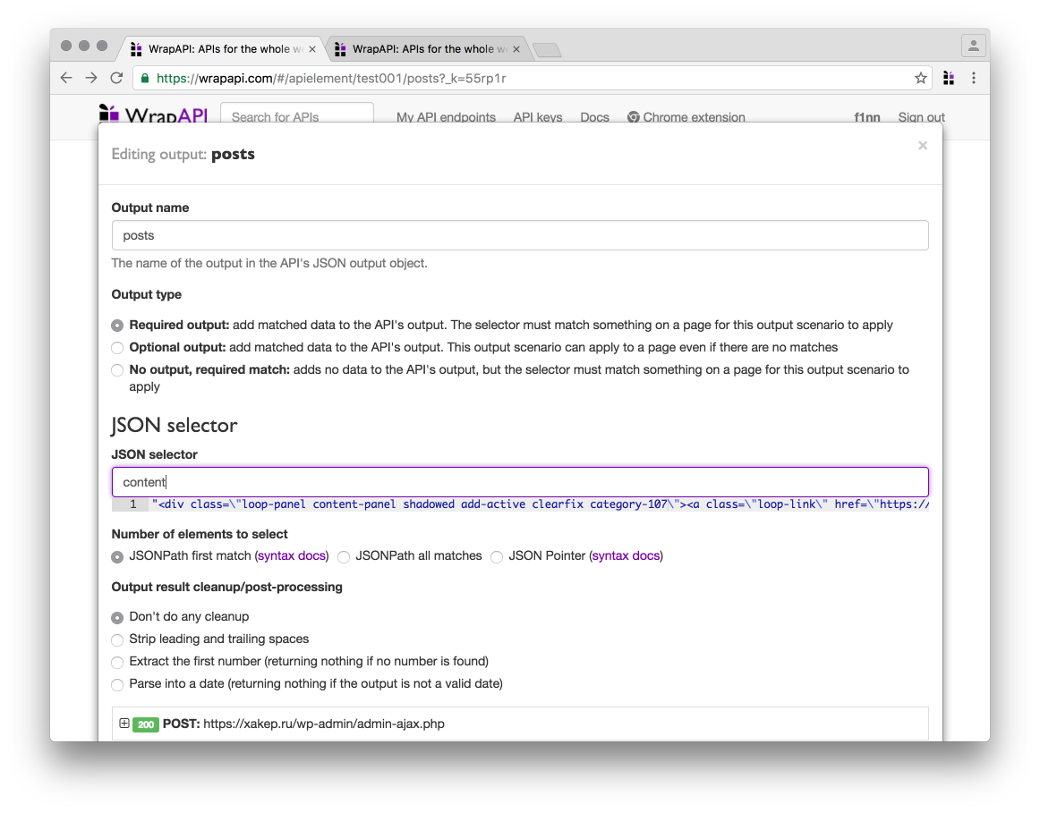
CSS output
Следующий шаг — вытащить нужные нам поля постов из полученной с сервера верстки, а именно title, excerpt, image, date и id.
Во WrapAPI можно создавать дочерние аутпуты. Нажав на + около существующего output, ты создашь дочерний output, который будет принимать на выход значение предыдущего. Не перепутай! Если просто выбрать пункт Add new output, то будет создан новый root-селектор, который на вход получит голый ответ сервера.
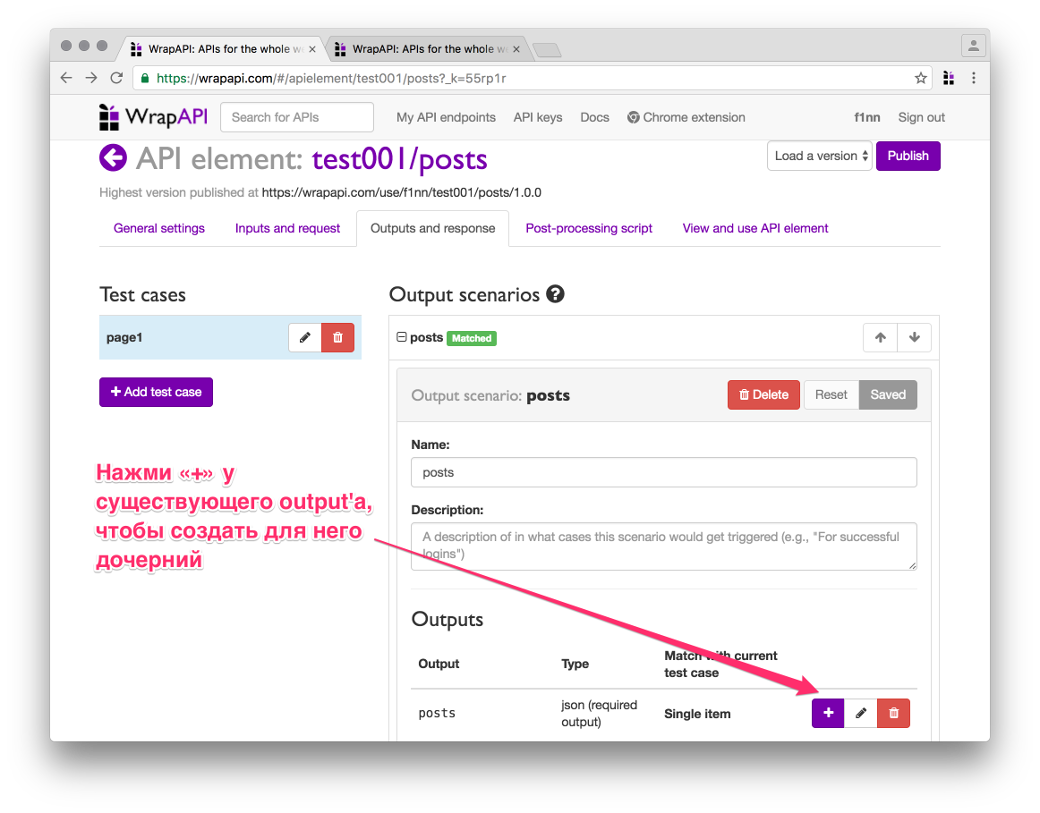
В появившемся окне вводим название класса заголовка .title-text. Внимание: обязательно отметь опцию Select all into an array, иначе будет выбран только первый заголовок, а нам нужно получить все десять по количеству постов в одном ответе сервера.

На выходе в ключе titles у нас окажется массив заголовков, которые вернул CSS output. Согласись, уже неплохо, и все это — без единой строки кода!

Как получить остальные параметры
Как ты помнишь, кроме title, для каждого поста нам нужно получить еще excerpt, image, date и id. Тут все не так здорово: WrapAPI имеет два ограничения:
- он не позволяет создавать цепочки из более чем одного уровня вложенности дочерних outputs;
- он не позволяет задавать несколько селекторов для CSS output’a. То есть CSS output может вытащить только
title, толькоdateи так далее.
Признаться, мне пришлось немного поломать голову, чтобы обойти эти ограничения. Я сделал много дочерних по отношению к JSON аутпутов CSS — по одному на каждый из параметров. Они выводят мне в итоговый результат несколько массивов: один с заголовками, один с превью статьи, один с датами и так далее.
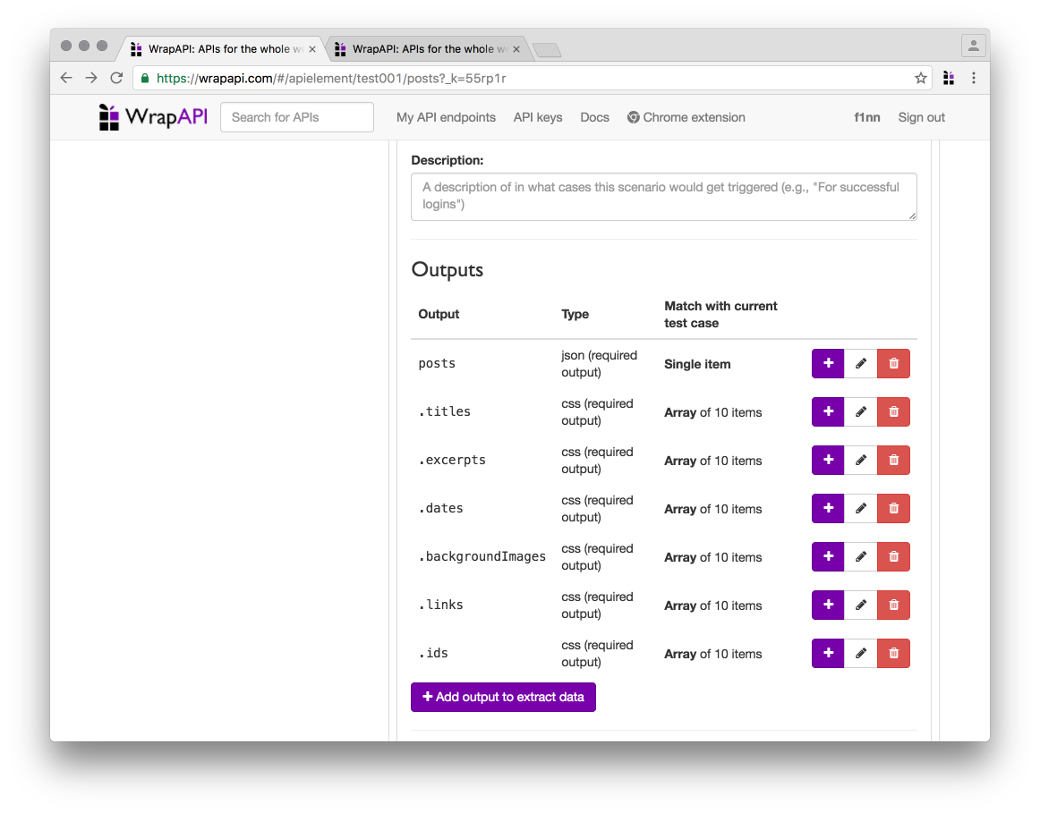
В итоге у меня получился вот такой массив данных:
{
"posts": {
"titles": [
"Android N и борьба за безопасность. Колонка Евгения Зобнина",
"Wine наоборот: потрошим Windows Subsystem for Linux",
...
],
"excerpts": [
"Одним из самых интересных на Google I/O было выступление Адриана Людвига, отвечающего за безопасность платформы Android. За сорок минут он успел рассказать и о новшествах Android M в плане безопасности, и о грядущем Android N. Так как о security-фичах шестой версии системы мы уже писали, я остановлюсь лишь на том, что инженеры Гугла успели добавить в седьмую. Поехали.",
"Никогда прежде корпорация Microsoft не обращала столь пристального внимания на Linux, как в последние полгода. Конкретно сборка Microsoft Windows 10 Build 14316 для разработчиков (developer release) совместно с Canonical (!) включает подсистему Linux. Это не эмулятор и не виртуальная машина, а полноценный терминал Linux, работающий внутри Windows 10!",
...
],
"dates": [
"4 минуты назад",
"3 часа назад",
...
],
"backgroundImages": [
"background-image:url(https://xakep.ru/wp-content/uploads/2016/07/android-n-712x400.jpg);",
"background-image:url(https://xakep.ru/wp-content/uploads/2016/07/windows-10-bash-h-712x400.jpg);",
...
],
"links": [
"https://xakep.ru/2016/07/01/android-n-security/",
"https://xakep.ru/2016/07/01/windows-subsystem-for-linux/",
...
],
"ids": [
"96895",
"96836",
...
]
}
}Стоит отметить, что для backgroundImages нужно указать получение не текста HTML-тега, а значения атрибута style, так как URL картинки задан в свойстве inline-CSS, а не в атрибуте src тега img.
Приводим все в порядок
Сейчас наш API уже выглядит вполне читаемым, осталось решить две проблемы:
- все компоненты поста — заголовок, дата, превью — находятся в разных массивах;
- в
backgroundImagesпопал кусок CSS, а не чистый URL.
Решить эти проблемы нам поможет следующая вкладка — Post-processing script. Она позволяет написать небольшой синхронный скрипт на JavaScript, который может сделать что-то с нашим контентом перед тем, как он отправится на выход.
Скрипт должен содержать функцию postProcess(), которая принимает один аргумент — текущие результаты парсинга. То, что она вернет, и будет конечным ответом нашего API.
Я набросал небольшой скрипт, который быстро собрал все компоненты в единый массив постов, а также почистил URL картинки. Останавливаться на этом подробнее смысла нет, все, я думаю, и так предельно ясно.
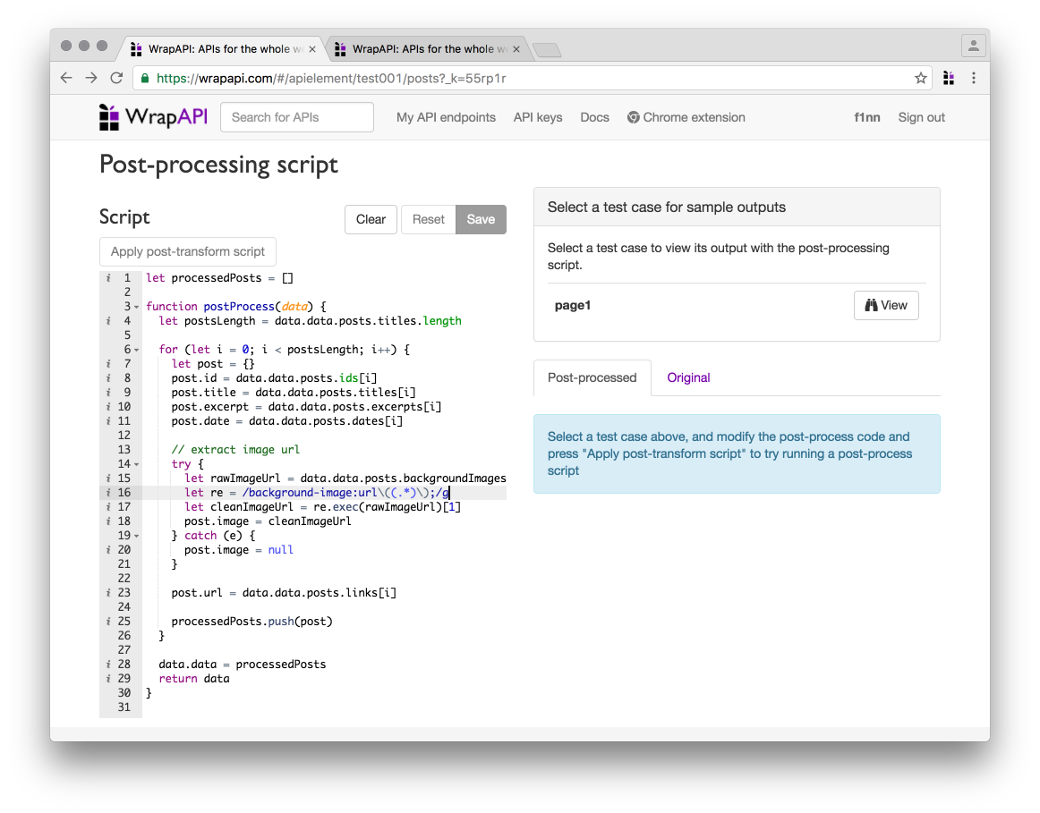
Тестируем результат
Переходим в очередную вкладку — View and use API element. Здесь нет ничего интересного, кроме стандартных вопросов перед публикацией. Скорее всего, менять ничего не придется, поэтому выбери версию API и публикуй. Мне выдали URL вида https://wrapapi.com/use/f1nn/test001/posts/1.0.0.
Перед тем как пробовать наш запрос, нужно получить API-ключ. Ключи WrapAPI бывают двух типов:
- приватные, для использования на сервере, не имеют ограничений;
- публичные, для использования на клиенте. Они имеют ограничение по домену, с которого происходит запрос.
Для теста получи новый приватный ключ и попробуй сделать запрос к своему API, поставив свой ключ в query-параметр wrapAPIKey.
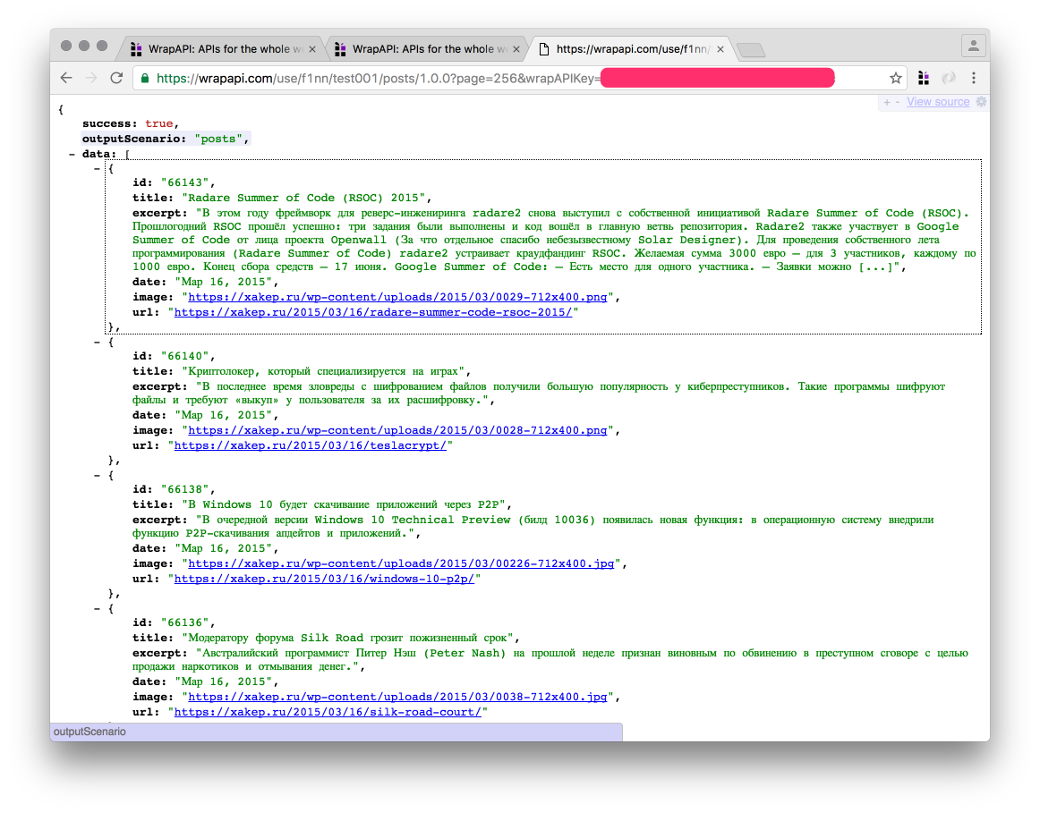
У меня вышел вот такой запрос:
https://wrapapi.com/use/f1nn/test001/posts/1.0.0?wrapAPIKey=apiKeyОтвет сервера показан на скриншоте. Победа! 🙂
Выводы
Как видишь, WrapAPI — это мощный и очень эффективный способ построения парсеров веб-контента, который помогает обойтись без программирования или почти без него. Поначалу он кажется слишком перегруженным и нелогичным, но со временем ты убедишься, что он содержит ровно столько опций, сколько действительно нужно для эффективного скрэпинга веба. Сервис имеет гибкие параметры конфигурирования запросов, а постпроцессинг полученных ответов позволяет преобразовать практически любой HTTP response в красивый API. Дерзай, строй свои парсеры!












