Содержание статьи
- Как работает WAF
- Изучаем уязвимости правил
- Модификаторы, числовые квантификаторы и позиционные указатели
- Ошибки логики
- Особенности парсеров и опечатки
- Ищем уязвимые регэкспы
- Изучаем уязвимости в WAF
- ModSecurity
- Comodo WAF
- Байпас (ReDoS) клиентского и серверного файрвола приложения
- Обход XSS Auditor в Microsoft Edge
- Ошибки, связанные с опечатками в ModSecurity и других WAF
- Полный обход ModSecurity
- Ошибки логики токенизации
- Выводы
- Почему байпасы будут жить всегда

WARNING
Вся информация предоставлена исключительно в ознакомительных целях. Ни редакция, ни автор не несут ответственности за любой возможный вред, причиненный материалами данной статьи.INFO
На момент исследования абсолютно все представленные техники обхода были зиродеями. Сейчас часть из них уже активно патчится вендорами, но тем не менее подходы к поиску байпасов остаются неизменными.Как работает WAF
Давайте рассмотрим механизмы работы WAF изнутри. Этапы обработки входящего трафика в большинстве WAF одинаковы. Условно можно выделить пять этапов:
- Парсинг HTTP-пакета, который пришел от клиента.
- Выбор правил в зависимости от типа входящего параметра.
- Нормализация данных до вида, пригодного для анализа.
- Применение правила детектирования.
- Вынесение решения о вредоносности пакета. На этом этапе WAF либо обрывает соединение, либо пропускает дальше — на уровень приложения.
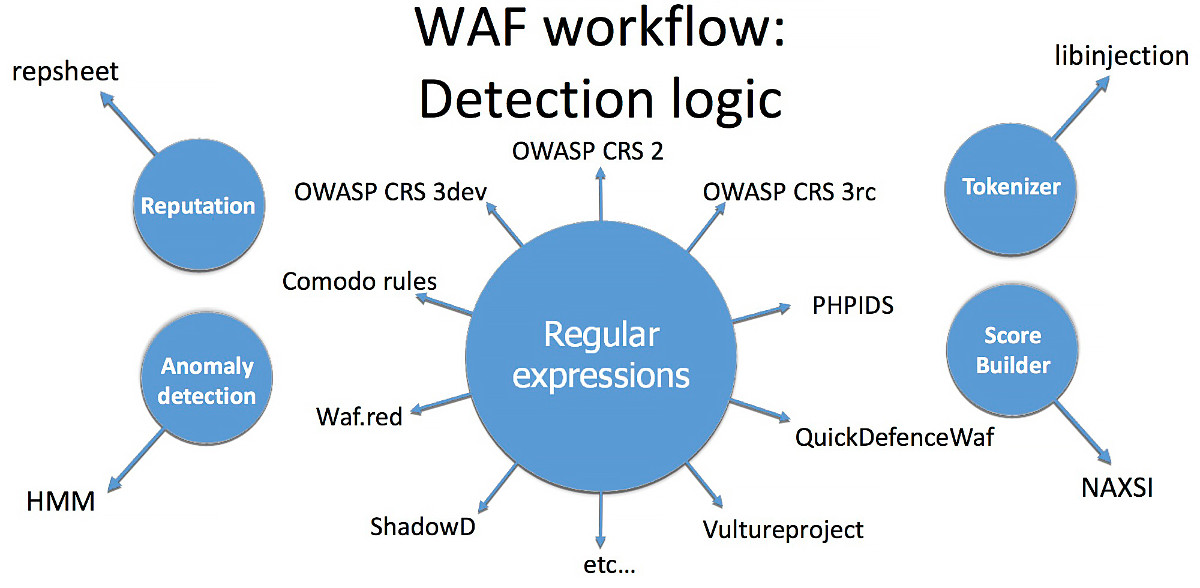
Все этапы, кроме четвертого, хорошо изучены и в большинстве файрволов одинаковы. О четвертом пункте — правилах детектирования — дальше и пойдет речь. Если проанализировать виды логик обнаружения атак в пятнадцати наиболее популярных WAF, то лидировать будут:
- регулярные выражения;
- токенайзеры, лексические анализаторы;
- репутация;
- выявление аномалий;
- score builder.
Большинство WAF используют именно механизмы регулярных выражений («регэкспы») для поиска атак. На это есть две причины. Во-первых, так исторически сложилось, ведь именно регулярные выражения использовал первый WAF, написанный в 1997 году. Вторая причина также вполне естественна — это простота подхода, используемого регулярками.
Напомню, что регулярные выражения выполняют поиск подстроки (в нашем случае — вредоносного паттерна) в тексте (в нашем случае — в HTTP-параметре). Например, вот одна из самых простых регулярок из ModSecurity:
(?i)(<script[^>]*>.*?)
Это выражение ищет HTML-инъекцию типа XSS в теле запроса. Первая часть ((?i)) делает последующую часть выражения нечувствительной к регистру, вторая (во вторых скобках) ищет открывающийся тег <script с произвольными параметрами внутри тега и произвольный текст после символа >.
INFO
Регулярные выражения очень популярны в security-продуктах. При работе с веб-приложениями ты встретишь их на всех уровнях. Самый первый и ближайший к пользователю — XSS Auditor, который встроен во все популярные браузеры (даже в IE, начиная с версии 7). Второй — это фронтендовые анализаторы, предотвращающие исполнение вредоносного кода, который может прийти с бэкенда в качестве данных. Третий уровень — бэкенд, на котором также могут использоваться регулярки для постобработки данных — проверять пользовательский ввод перед сохранением в БД, а также перед выводом пользователю.Изучаем уязвимости правил
Давай скачаем актуальные версии шести топовых бесплатных WAF и вытащим из них все правила. В результате на диске у тебя скопится порядка 500 правил, из которых около 90% защищают веб-приложение от XSS- и SQL-инъекций.

Предположим, что некоторые из исследуемых правил имеют ошибки. Найденная ошибка в таком правиле позволит использовать ее в качестве байпаса.
Разделим типы байпасов, которые мы сможем эксплуатировать, на синтаксические (ошибка в использовании синтаксиса регулярных выражений, из-за чего меняется логика правила) и непредвиденные (правила изначально не учитывают определенные случаи). Теперь нужно подобрать инструмент для анализа правил на предмет этих ошибок.
Опытный специалист, пристально посмотрев на регулярное выражение, сможет, исходя из своего опыта, дать вердикт, можно ли обойти данное правило. Однако точной методологии, по которой неопытный хакер (или скрипт) может проверить регулярное выражение на наличие обхода, не существует. Давай ее создадим.
INFO
Чтобы научиться находить обходы, необходимо разобраться в коварных хитросплетениях синтаксиса регулярных выражений.
Модификаторы, числовые квантификаторы и позиционные указатели
Возьмем для начала несложный пример. Здесь у нас простое выражение, которое защищает функцию _exec(). Регулярка пытается найти паттерн attackpayload в GET-параметре a и, если он найден, предотвратить исполнение вредоносного кода:
if( !preg_match("/^(attackpayload){1,3}$/", $_GET['a']) ) {
_exec($cmd . $_GET['a'] . $arg);
}В этом коде есть как минимум три проблемы.
- Регистр. Выражение не учитывает регистр, поэтому, если использовать нагрузку разного регистра, ее удастся обойти:
atTacKpAyloAdПофиксить это можно при помощи модификатора
(?i), благодаря которому регистр не будет учитываться. - Символы начала и конца строки (
^$). Выражение ищет вредоносную нагрузку, жестко привязываясь к позиции в строке. В большинстве языков, для которых предназначается вредоносная нагрузка (например, SQL), пробелы в начале и в конце строки не влияют на синтаксис. Таким образом, если добавить пробелы в начале и конце строки, защиту удастся обойти:attackpayloadЧтобы не допускать подобного байпаса, нужно обращать особое внимание на то, как используются явные указатели начала и конца строки. Зачастую они не нужны.
- Квантификаторы (
{1,3}). Регулярное выражение ищет количество вхождений от одного до трех. Соответственно, написав полезную нагрузку четыре или более раз, можно ее обойти:attackpayloadattackpayloadattackpayloadattackpayload...Пофиксить это можно, указав неограниченное число вхождений подстроки (
+вместо{1,3}). Квантификатора{m,n}вообще следует избегать. Например, раньше считалось, что четыре символа — это максимум для корневого домена (к примеру, .info), а сейчас появились TLD типа .university. Как следствие, регулярные выражения, в которых используется паттерн{2,4}, перестали быть валидными, и открылась возможность для байпаса.
Ошибки логики
Теперь давай рассмотрим несколько выражений посложнее.
(a+)+— это пример так называемого ReDoS, отказа в обслуживании при парсинге текста уязвимым регулярным выражением. Проблема в том, что это регулярное выражение будет обрабатываться парсером слишком долго из-за чрезмерного количества вхождений в строку. То есть если мы передадимaaaaaaa....aaaaaaaab, то в некоторых парсерах такой поиск будет выполнять 2^n операций сравнивания, что и приведет к отказу в обслуживании запущенной функции.a'\s+b— в этом случае неверно выбран квантификатор. Знак+в регулярных выражениях означает «1 или более». Соответственно, мы можем передать «a'-пробел-0-раз-b», тем самым обойдя регулярку и выполнив вредоносную нагрузку.a[\n]*b— здесь используется черный список. Всегда нужно помнить, что большинству Unicode-символов существуют эквивалентные альтернативы, которые могут быть не учтены в списке регулярки. Использовать блек-листы нужно с осторожностью. В данном случае обойти правило можно так:a\rb.
Особенности парсеров и опечатки
[A-z]— в этом примере разрешен слишком широкий скоуп. Кроме желаемых диапазонов символовA-Zиa-z, такое выражение разрешает еще и ряд спецсимволов, в числе которых\,`,[,]и так далее, что в большинстве случаев может привести к выходу за контекст.[digit]— здесь отсутствует двоеточие до и после класса digit (POSIX character set). В данном случае это просто набор из четырех символов, все остальные разрешены.a |b,a||b. В первом случае допущен лишний пробел — такое выражение будет искать не «a или b», а «а пробел, или b». Во втором случае подразумевался один оператор «или», а написано два. Такое выражение найдет все вхождения a и пустые строки (ведь после|идет пустая строка), но не b.\11 \e \q— в этом случае конструкции с бэкслешами неоднозначны, так как в разных парсерах спецсимволы могут обрабатываться по-разному в зависимости от контекста. В разных парсерах спецсимволы могут обрабатываться по-разному. В этом примере\11может быть как бэклинком с номером 11, так и символом табуляции (0x09 в восьмеричном коде);\eможет интерпретироваться как очень редко описываемый в документации wildcard (символ Esc);\q— просто экранированный символq. Казалось бы, один и тот же символ, но читается он по-разному в зависимости от условий и конкретного парсера.
Ищем уязвимые регэкспы
Задокументировав все популярные ошибки и недочеты в таблицу, я написал небольшой статический анализатор регулярных выражений, который анализирует полученные выражения и подсвечивает найденные слабые части. Отчет сохраняется в виде HTML.
Запустив инструмент на выборке из 500 регулярных выражений, найденных при сборе правил, я получил интересные результаты: программа обнаружила более 300 потенциальных байпасов. Здесь и далее символы, подсвеченные желтым, — это потенциально уязвимые места в регулярных выражениях.
В первой строке регулярка уязвима к ReDoS.
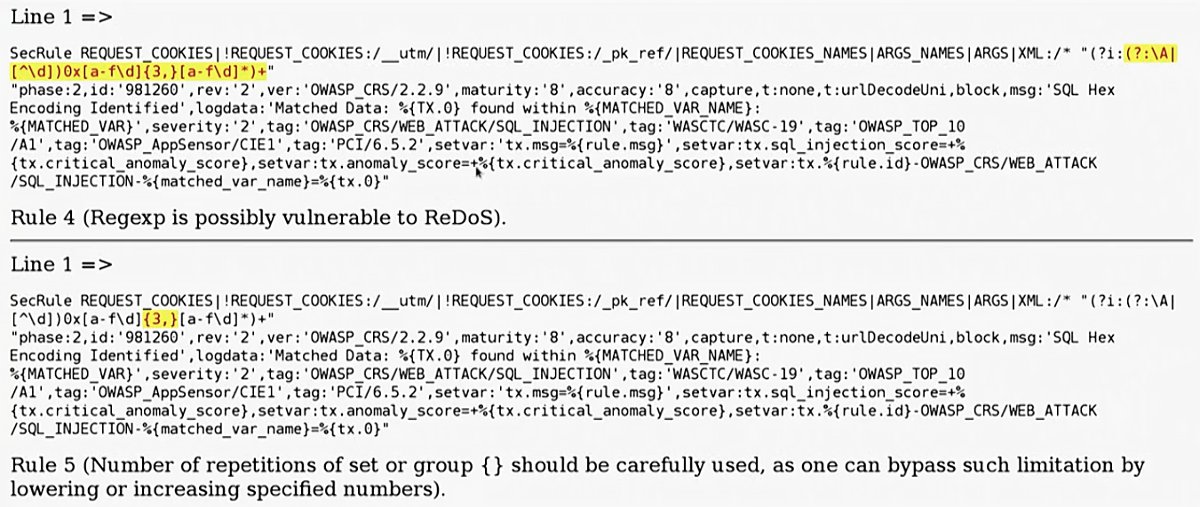
Еще один пример — некорректно выбранная длина строки в запросе union select. Очевидно, что ограничение можно обойти, просто вставив 101 символ и больше.

Теперь давай потестируем тулкит на более свежей базе. В качестве примера скачаем последний билд WordPress и при помощи grep вытащим из его исходного кода все регулярные выражения в файл regexp.txt.

Запустим наш анализатор и взглянем на сгенерированный отчет. В файле wp-includes/class-phpmailer.php обнаружилось выражение [A-z] с описанной выше уязвимостью (вхождение непредназначенных символов). Вот лишь малый список open source CMS, в которых он используется: WordPress, Drupal, 1CRM, SugarCRM, Yii, Joomla.
Изучаем уязвимости в WAF
Теперь, когда мы поняли основные проблемы с регулярными выражениями и освоили методики поиска уязвимостей, давай рассмотрим примеры байпасов в реальных современных WAF.
ModSecurity
ModSecurity — это бесплатный application-level WAF, который давно и широко используется в связке с Apache, nginx и другими серверами. На сайте ModSecurity есть страница, которая позволяет проверить параметр (строку в запросе) на наличие вредоносной нагрузки в соответствии с правилами ModSecurity. Если в переданной строке обнаружена атака, то сайт ModSecurity возвращает список правил, которые задетектили эту атаку.
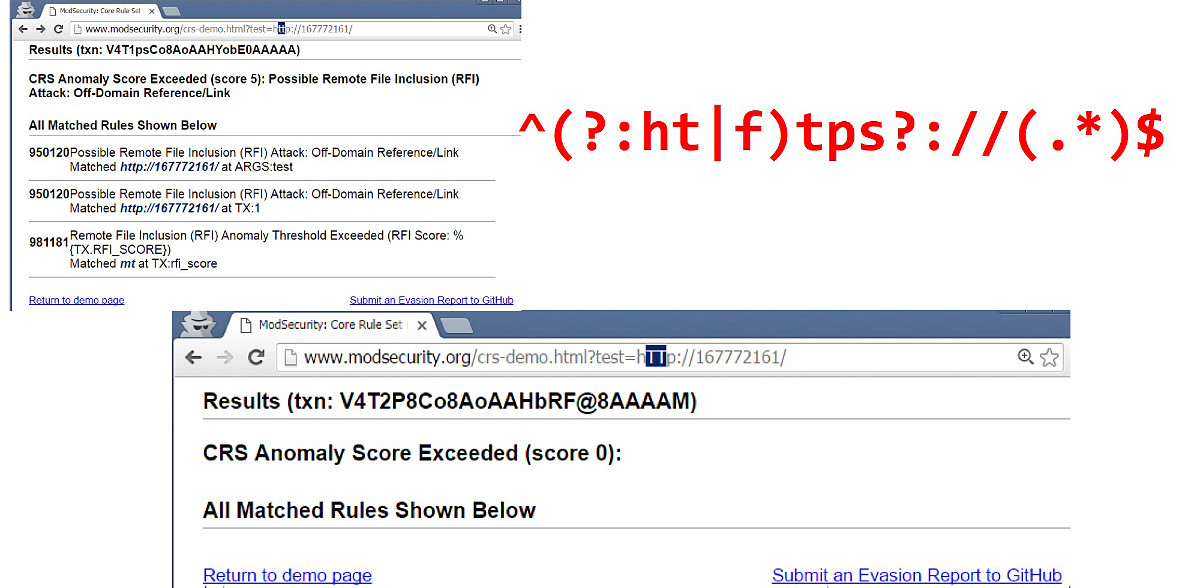
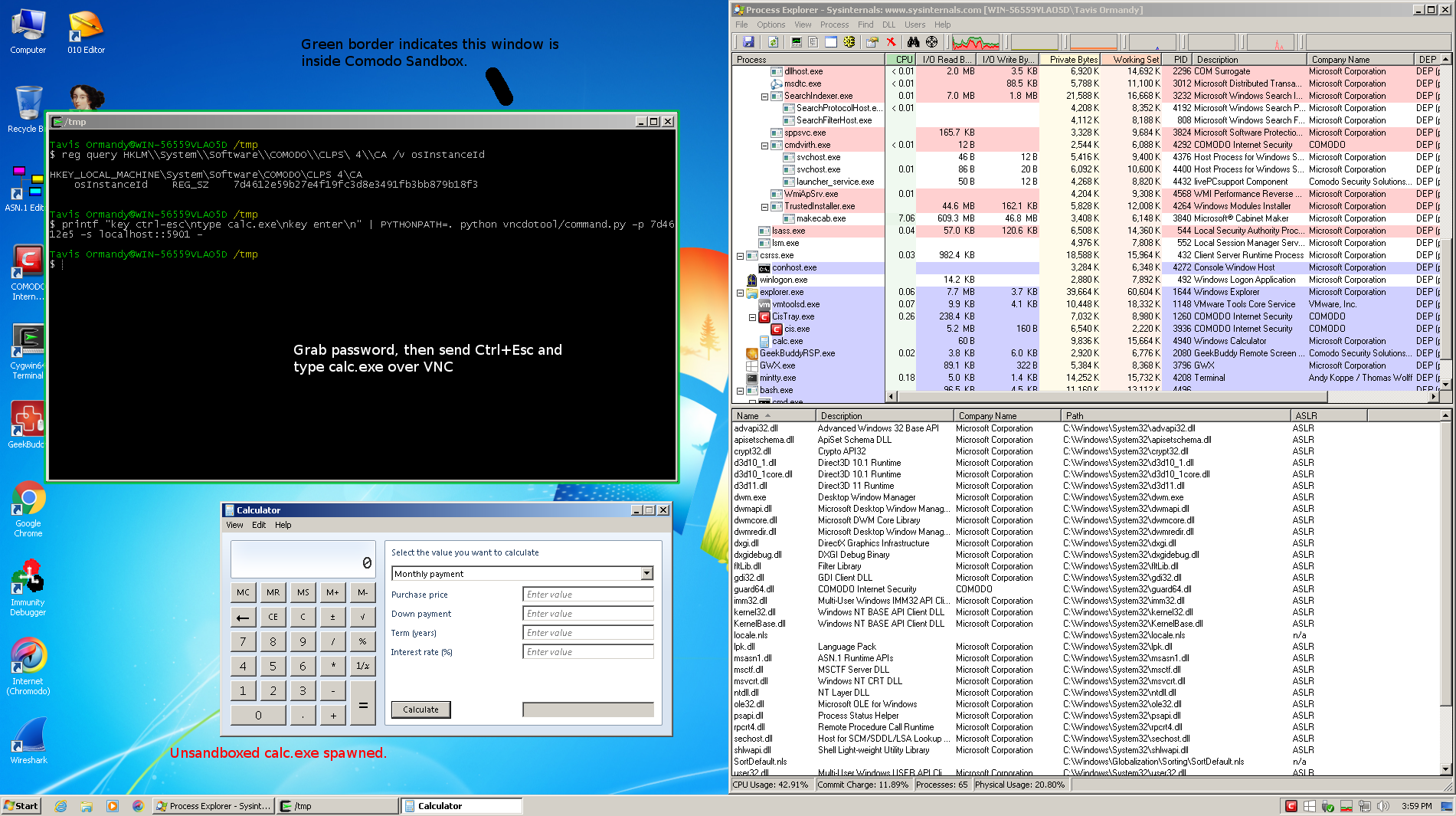
На первом скриншоте слева я отправил URI-схему, и ModSecurity определил это как атаку Remote File Inclusion. Однако если взглянуть на исходное регулярное выражение, которое детектит эту атаку (выделено красным на скриншоте), мы увидим, что регулярка не учитывает регистр. Можно просто поменять регистр, скажем заменив буквы tt на заглавные, и тем самым обойти файрвол.
Comodo WAF
Компания Comodo, один из крупнейших поставщиков SSL-сертификатов, с недавнего времени выпускает правила для ModSecurity-совместимого продукта Comodo WAF. Однако вместо того, чтобы писать свои правила фильтрации и регулярные выражения, судя по всему, разработчики решили просто накачать регулярок из других WAF и использовать их в своем продукте. А чтобы не прилетел иск за использование чужого кода, Comodo просто поменяла некоторые «незначительные» детали в правилах.
Что конкретно сделали в Comodo? Эти умельцы начали заменять символы в чужих регулярках их альтернативами, которые, на первый взгляд, идентичны по смыслу. Например, квантификатор + они заменяли на {1,}. Вроде бы такой подход выглядит нечестным, но безопасным.
Однако если рассмотреть другой пример замены, видно, что разработчики Comodo WAF зачем-то решили экранировать символ открывающей квадратной скобки. В примере ниже изначальное правило было верное: оно искало on{event}, где {event} — JavaScript-событие onLoad, onMouseOver, onError, etc.
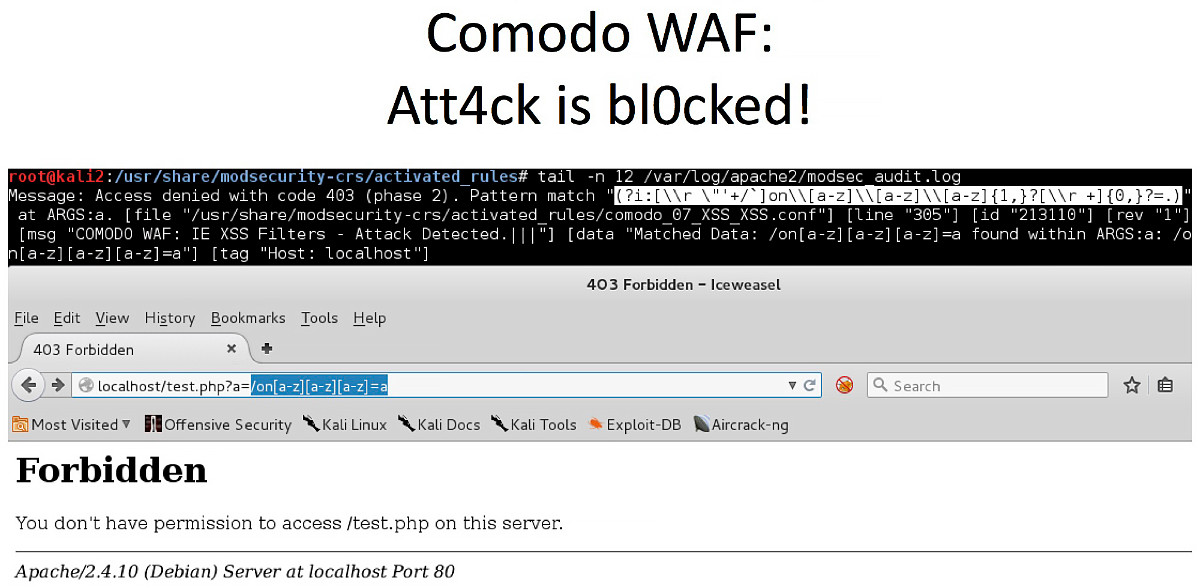
После того как выражение «поправили», вместо on-события ищется паттерн \[a-z]. Это привело к тому, что обычный невредоносный запрос ?a=/on[a-z][a-z][a-z]=a расценивается как атака. Но при этом легитимное событие onLoad= файрвол пропускает!
Байпас (ReDoS) клиентского и серверного файрвола приложения
Следующее регулярное выражение попалось мне во время анализа одного очень защищенного реального приложения. В клиентском коде на JavaScript была функция валидации email:
function check_email (e) {
var filter = /^([a-zA-Z0-9_.-])+@(([a-zA-Z0-9])+.)+([a-zA-Z0-9]{2,4})+$/;
return filter.test(e);
}Как несложно догадаться, все, что идет после символа @, уязвимо к атаке типа ReDoS. Соответственно, если сконструировать специально подготовленную строку email, то регулярка будет очень долго работать в поисках совпадений и в итоге повесит браузер клиента.
Но покрашить клиентский браузер — достижение невеликое, поэтому я стал копать дальше. Я предположил, что разработчики бэкенда не ограничились валидацией email только на клиентской стороне и проверяют user input еще и на сервере. И скорее всего, на бэкенде для проверки email используется аналогичная конструкция. Я отправил специально сконструированный email из предыдущего примера через форму несколько раз, и вскоре сервер начал отдавать 504-ю ошибку. Наша «бомба из регулярки» успешно его «загрузила».

Обход XSS Auditor в Microsoft Edge
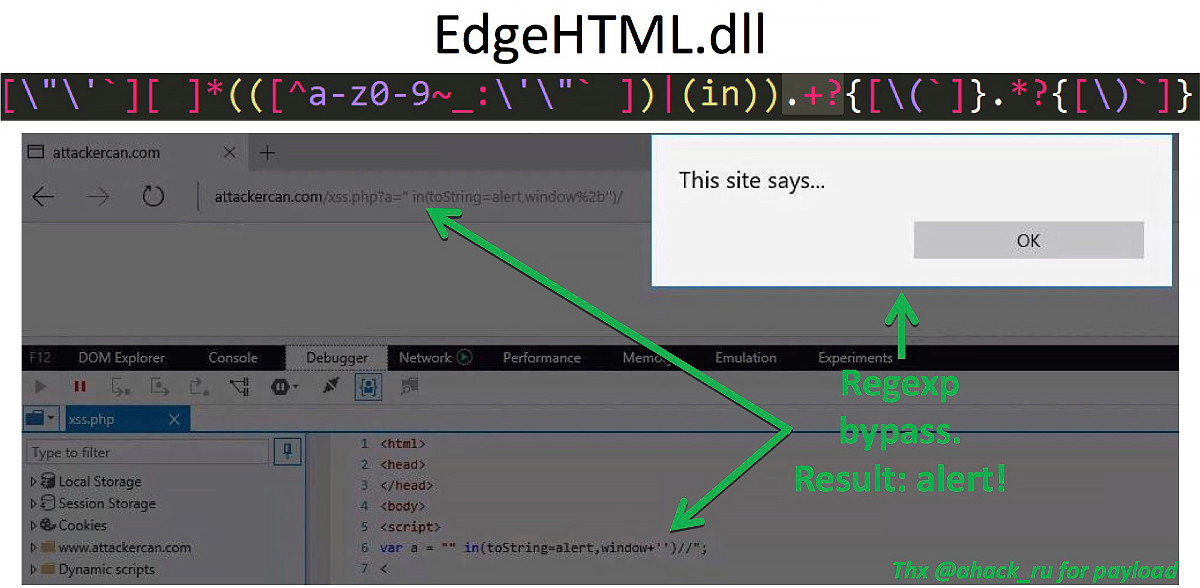
Перед тобой регулярка, которая используется в последней версии браузера Microsoft Edge в библиотеке EdgeHTML.dll. Это выражение отвечает за работу XSS Audior — встроенного в браузер механизма, который предотвращает эксплуатацию XSS-инъекций на стороне клиента. Взгляни на нее внимательно.
[\"\'`][ ]*(([^a-z0-9~_:\'\"` ])|(in)).+?{[\(`]}.*?{[\)`]}
По задумке разработчика, в случае получения строки, которая удовлетворит этому выражению, опасные символы заменятся на #. Если мы внимательно посмотрим, то заметим, что это регулярное выражение ищет слово in, затем один или больше символов, и затем открывающую скобку. Проблема кроется в квантификаторе +, который, как нам уже известно, ищет «один или более» символов. Если мы передадим ноль символов между словом in и открывающей скобкой, мы получим байпас.
Ошибки, связанные с опечатками в ModSecurity и других WAF
Следующее регулярное выражение взято из ModSecurity и содержит явную ошибку:
(?:div|like|between|and|not )\s+\w)
Это регулярное выражение должно искать:
div, один и больше пробелов, какую-то букву;like, один или больше пробелов, какую-то букву;- ...
not, ДВА или больше пробелов, какую-то букву.
Очевидна проблема в опечатке перед закрывающей скобкой — туда затесался лишний пробел. В результате секция регулярного выражения с not и последней частью (\s+\w) ищет два пробела между not и буквой: один после not, один в качестве произвольного пробельного символа.
Это «неправильное» регулярное выражение я встречал в коде ModSecurity несколько раз, в комбинации с разными ключевыми словами. Затем случайно наткнулся на него в коде PHPIDS. Выяснилось, что оригинальный коммит, с которым внесли ошибку, был сделан в 2008 году. То есть уязвимость существовала почти восемь лет. Невольно закрадываются подозрения, что это может быть и умышленный бэкдор.
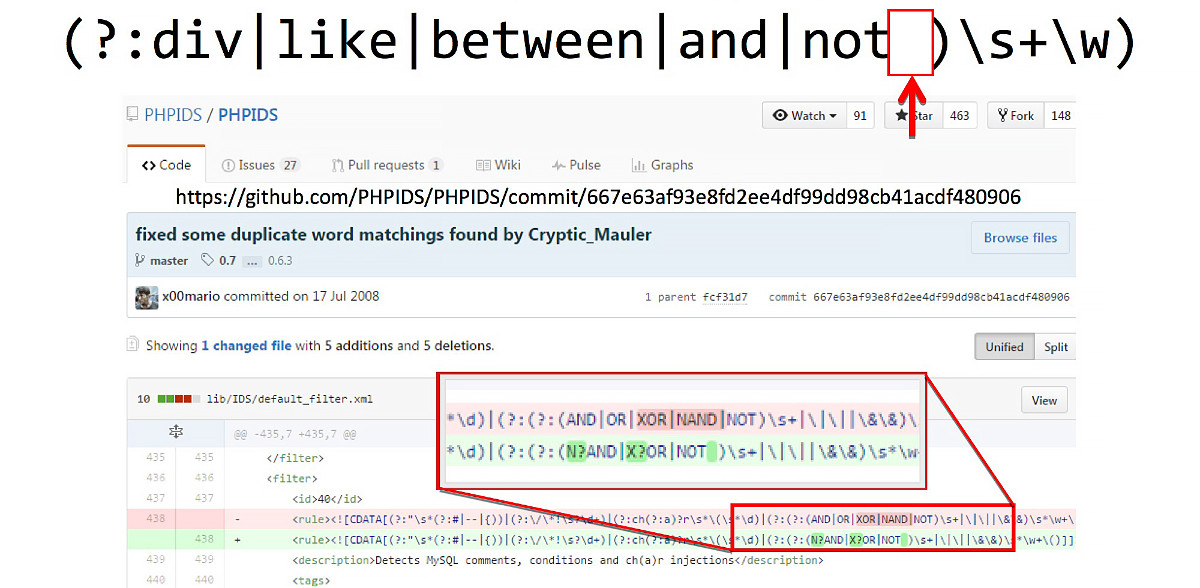
Добавь к этому тот факт, что разработчики часто копируют чужие регулярные выражения и правила из популярных продуктов, так что можно представить, сколько еще WAF скопировали это регулярное выражение из кода ModSecurity.
Полный обход ModSecurity
Давай подведем промежуточный итог. В данный момент инструментарий помог нам создать множество байпасов из множества правил. Имея эти данные, можно попытаться сконструировать универсальный байпас под произвольную инъекцию.
Возьмем простейшую инъекцию в параметр:
mysql_query( "SELECT * FROM `test` WHERE id = ' " . $_GET['a'] . "'" );Все правила, основанные на регулярных выражениях, в последней версии ModSecurity можно обойти следующим запросом:
-1'OR#foo
id=IF#foo
(ASCII#foo
((SELECT-version()/1.))<250,1,0) #Таким образом, мы смогли эффективно обойти произвольный WAF при наличии произвольной инъекции.
INFO
По ошибкам регулярных выражений можно с высокой точностью определить WAF (или семейство WAF), который используется в приложении, а также его версию. А затем уже открыть его исходные коды и работать с регэкспами методом white-box.
Ошибки логики токенизации
Работая с байпасом регулярок, зачастую можно подобрать вектор, который будет обходить все регэкспы, однако в современных WAF есть другая преграда. В последней версии ModSecurity, кроме регулярных выражений, есть еще и отдельная библиотека libinjection. Она защищает от SQL injection в случаях, когда атакующему удалось обойти регулярки. Эта библиотека была представлена на Black Hat в 2012 году и быстро стала популярной из-за высокой точности и скорости работы.
Libinjection может представить любую строку в виде пяти токенов. Токен — это некоторый символ (идентификатор), обозначающий класс той или иной подстроки.

В примере выше libinjection присваивает каждой части строки свой класс — string, operator, name, number и comment. По наличию в строке тех или иных классов (токенов) библиотека делает вывод о наличии вредоносной нагрузки. В результате она передает запрос приложению или блокирует его, тем самым предотвращая атаку.
Автор libinjection собирал примеры вредоносных нагрузок из множества источников: шпаргалок по SQL-инъекциям, правил WAF, пейлоадов с хакерских форумов и так далее. В результате для получившегося набора были посчитаны комбинации токенов, которые составляют основу блек-листа libinjection. На момент написания статьи в базе библиотеки находится более 9000 токенов.
Предположив, что в базе блек-листа есть не все токены с валидным SQL-синтаксисом, мы можем попробовать найти такие SQL-выражения, которые будут считаться валидными запросами, и в то же время токен для таких запросов не будет в черном списке libinjection. Для этого я написал небольшой SQL-фаззер.
В качестве входных данных cpp-sql-fuzzer получает маску SQL-строки. Дальше нужно указать, что конкретно фаззить и каким алфавитом. После этого фаззер начнет работу и будет записывать все валидные запросы в одну таблицу, а все остальные (те, что не вызывают MySQL syntax error) — во вторую. Вторая таблица нужна для случая, когда sql-fuzzer нафаззит какую-нибудь конструкцию с функцией, которая будет требовать, например, два параметра, а не один, мы увидим это в логах и сможем вручную добавить второй параметр.
Фаззер лучше всего развернуть в облаке, например в Google Cloud Engine. На конфигурации с восьмью ядрами и примерно 50 Гбайт памяти 21 миллион запросов мне удалось профаззить за десять минут, то есть скорость составила примерно 35 тысяч запросов в секунду (хотя для MySQL это, судя по документации, не предел).
В качестве примера составим список разрешенных символов между ключевым словом SELECT и строковым параметром 1. Для этого отдадим фаззеру следующее выражение:
SELECT[XXX]1 FROM tbl1И начнем фаззинг. В составе libinjection есть бинарник, который вычисляет токен по заданной строке, им и воспользуемся.
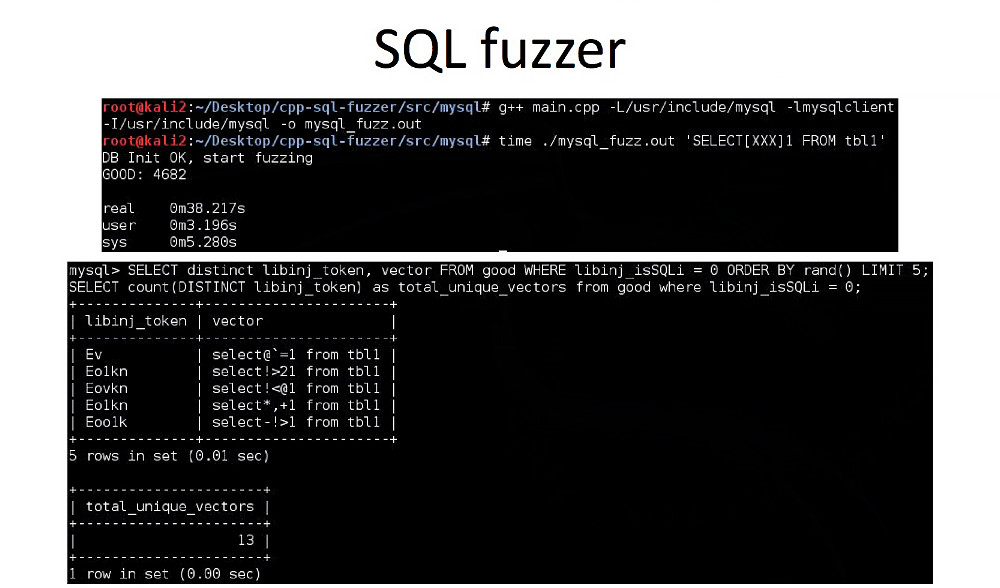
Как видишь по скрину, за тридцать секунд нашлось тринадцать уникальных векторов, которые ранее не были учтены в блек-листе библиотеки, то есть обходят libinjection. Разберем один из них.

Если первый вектор (SELECT 1 FROM...) очевидно вредоносный, то второй (SELECT!<1 FROM) оказался рабочим и не блокируется. Соответственно, !<1 — наш токен-брейкер для libinjection.
Если вставить эту конструкцию в любую часть SQL-запроса, то все, что идет после нее, не будет детектировано. Например, мы сможем вызвать произвольную функцию или передать любую вредоносную нагрузку. При этом фингерпринт (токен) не изменится, а значит, WAF не сможет детектировать атаку.
Чтобы сократить время читателя на фаззинг, я провел описанные выше манипуляции на популярных базах данных в популярных точках входа. Теперь, если, к примеру, тебе встретится инъекция в MySQL и WAF будет фильтровать все очевидные символы между -1 и UNION, просто воспользуйся моими результатами для подстановки неочевидных и притом валидных SQL-значений.
Готовые результаты в виде оформленной таблицы можно найти здесь.
Выводы
Как мы видим, обход WAF — это вполне посильная задача. Очень важно не просто фаззить insertion point’ы, а разбираться в самой причине возникновения байпаса. Иногда для этого надо прочитать исходники и проанализировать большое количество правил. Зачастую в таких исследованиях находится не один, а целая пачка байпасов. Все инструменты из этой статьи доступны в открытом доступе на Гитхабе. Если хочешь, присоединяйся к разработке нашего тулкита, и вместе мы найдем еще больше векторов!
Почему байпасы будут жить всегда
Возможности обойти WAF обычно ищут две стороны, но ирония состоит в том, что в качественном исправлении обходов никто не заинтересован.
Первая сторона — это атакующие, они проводят black box testing и ищут дыры в веб-приложении. Когда они обнаруживают, что приложение защищено при помощи WAF, то стараются перебрать все известные им варианты обхода. Это могут быть техники, описанные в публичных статьях, собственные наработки или фаззинг. В последнем случае атакующий фаззит огромное количество пользовательского ввода, чтобы найти тот символ, который будет обходить правило WAF. В случае успешного обхода атакующий не будет отправлять вендору отчет об уязвимости, и, скорее всего, она не будет исправлена.
Вторая сторона — это защитники (например, безопасники в компании), они обычно пользуются продуктами, которые создала сторонняя фирма. Реальность такова, что и они редко разбираются в отчетах, которые генерирует WAF, и почти никогда не отправляют отчет об уязвимости разработчикам.
За опенсорсными проектами WAF обычно стоит небольшая команда, которая мейнтейнит правила на добровольных началах. Даже если подробный отчет о найденных обходах достигнет внимания такой команды, выпуск патча может затянуться из-за банальной незаинтересованности.